Spark StreamingSpark Day11:Spark Streaming 学习笔记
Posted Maynor的大数据奋斗之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark StreamingSpark Day11:Spark Streaming 学习笔记相关的知识,希望对你有一定的参考价值。
Spark Day11:Spark Streaming
01-[了解]-昨日课程内容回顾
主要讲解:Spark Streaming 模块快速入门
1、Streaming 流式计算概述
- Streaming 应用场景
实时报表RealTime Report
实时增量ETL
实时预警和监控
实时搜索推荐
等等
- 大数据架构:Lambda架构
离线分析,实时计算
分为三层:
- 批处理层,BatchLayer
- 速度层,SpeedLayer
- 服务层,ServingLayer
- 流式数据处理模式
第一种模式:原生流处理native
来一条数据,处理一条数据
第二种模式:微批处理Mirco-Batch
将流式数据划分小批次,每个小批次快速处理
- SparkStreaming 计算思想
将流式数据按照时间间隔BatchInterval划分为很多批次Batch,每批次数据当做RDD,进行处理分析
DStream = Seq[RDD/Batch]
2、快速入门:词频统计WordCount
- 需求:
使用SparkStreaming对流式数据进行分析,从TCP Socket读取数据,对每批次数据进行词频统计,打印控制台,【注意,此处词频统计不是全局的,而是每批次的(局部)】
- 官方案例
run-example
- SparkStreaming应用开发入口
StreamingContext,流式上下文实例对象
开发步骤:
数据源DStream、数据处理和输出(调用DStream中函数)、启动流式应用start、等待终止await,最后关闭资源stop
- 编程开发,类似RDD中词频统计,调用函数flatMap、map、redueByKey等
- 流式应用原理
- 运行程序时,首先创建StreamingContext对象,底层sparkContext
- ssc.start,启动接收器Receivers,每个接收器以Task方式运行在Executor中
- Receiver接收器开始从数据源接受数据,按照时间间隔BlockInterval划分数据时Block,默认200ms,将Block存储到Executor内存中,如果设置多副本,在其他Executor再进行存储,最后发送BlockReport给SSC
- 当达到BatchINterval批次时间间隔时,产生一个Batch批次,将Block分配到该批次,底层将改配中数据当做RDD进行处理分析
3、数据结构:DStream = Seq[RDD]
封装数据流,数据源源不断产生,按照时间间隔划分为很多批次Batch,DStream = Seq[RDD]
函数:2种类型
- 转换函数Transformation,类似RDD中转换函数
- 输出函数Output
2个重要函数,都是针对每批次RDD进行操作
- 转换函数:tranform(rdd => rdd)
- 输出函数:foreachRDD(rdd => Unit)
修改词频统计代码
02-[了解]-今日课程内容提纲
主要讲解三个方面内容:集成Kafka,应用案例(状态、窗口)和偏移量管理
1、集成Kafka
SparkStreaming实际项目中,基本上都是从Kafka消费数据进行实时处理
- 集成时2套API
由于Kafka Consumer API有2套,所以集成也有2套API
- 编写代码
如何从Kafka消费数据,必须掌握
- 获取每批次数据偏移量信息
offset
2、应用案例:百度搜索排行榜
进行相关初始化操作
- 工具类,创建StreamingContext对象和消费Kafka数据
- 模拟数据生气生成器,实时产生用户搜索日志数据,发送到Kafka中
- 实时ETL(无状态)
- 累加统计(有状态)
- 窗口统计
3、偏移量管理
SparkStreaming一大败笔,需要用户管理从Kafka消费数据偏移量,了解知识点即可

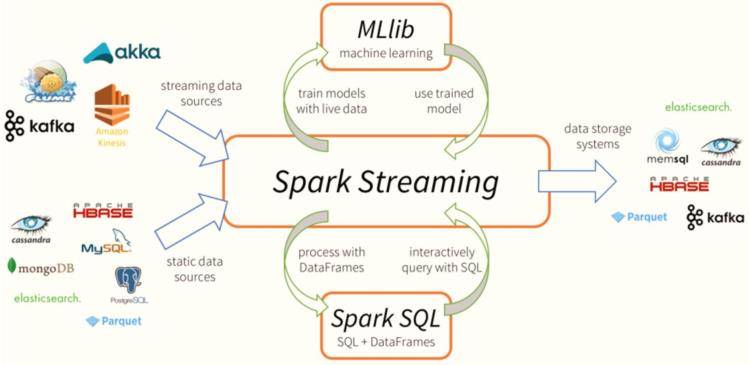
03-[理解]-流式应用技术栈
在实际项目中,无论使用Storm还是Spark Streaming与Flink,主要
从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:

- 数据源Source
分布式消息队列Kafka
flume集成Kafka
调用Producer API写入数据
Canal实时间mysql表数据同步到Kafka中,数据格式JSON字符串
.....
- 应用程序运行
目前企业中只要时流式应用程序,基本上都是运行在Hadoop YARN集群
- 数据终端
将数据写入NoSQL数据库中,比如Redis、HBase、Kafka
Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm -> Hadoop YARN -> Redis -> UI

04-[理解]-Kafka回顾及集成Kafka两套API
Apache Kafka: 最原始功能【消息队列】,缓冲数据,具有发布订阅功能(类似微信公众号)。

Kafka 框架架构图如下所示:

1、服务:Broker,每台机器启动服务
一个Kafka集群,至少3台机器
2、依赖Zookeeper
配置信息存储在ZK中
3、Producer生产者
向Kafka中写入数据
4、Consumer 消费者
从Kafka中消费数据,订阅数据
5、数据如何存储和管理
使用Topic主题,管理不同类型数据,划分为多个分区partition,采用副本机制
leader 副本:读写数据,1
follower 副本:同步数据,保证数据可靠性,1或多个
Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套,从Kafka 0.9版本开始出现New Consumer API,方便用户使用,从Kafka Topic中消费数据,到0.10版本稳定。

目前,企业中基本上都是使用Kafka New Consumer API消费Kafka中数据。
- 核心类:KafkaConsumer、ConsumerRecorder
05-[掌握]-New Consumer API方式集成编程
使用Kafka 0.10.+提供新版本Consumer API集成Streaming,实时消费Topic数据,进行处理。
- 添加相关Maven依赖:
<!-- Spark Streaming 与Kafka 0.10.0 集成依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
目前企业中基本都使用New Consumer API集成,优势如下:
- 第一、类似 Old Consumer API中Direct方式

- 第二、简单并行度1:1

工具类
KafkaUtils中createDirectStream函数API使用说明(函数声明):

官方文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html
首先启动Kafka服务,创建Topic:wc-topic
[root@node1 ~]# zookeeper-daemon.sh start
[root@node1 ~]# kafka-daemon.sh start
[root@node1 ~]# jps
2945 Kafka
# 使用KafkaTools创建Topic,设置1个副本和3个分区
kafka-console-producer.sh --topic wc-topic --broker-list node1.itcast.cn:9092
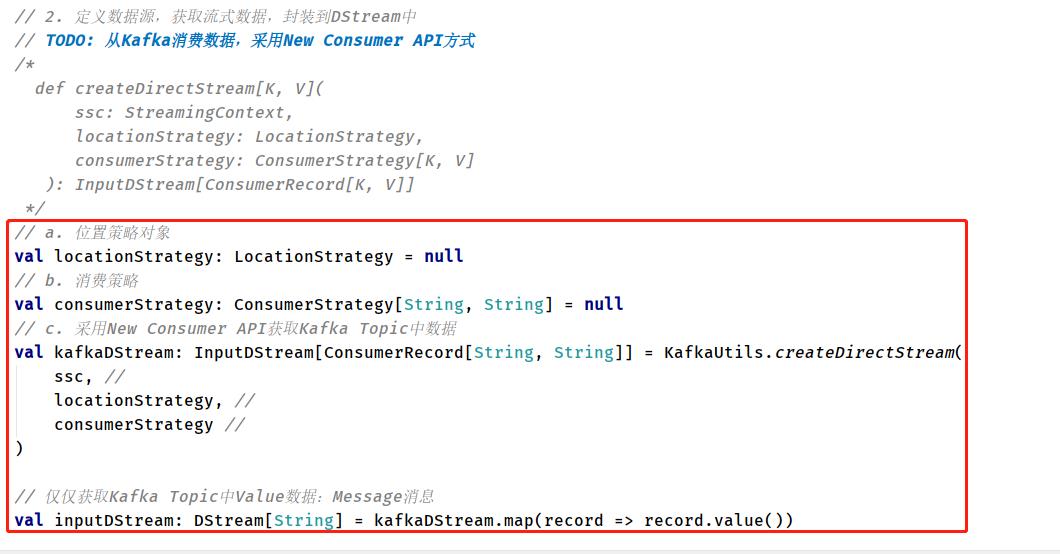
具体实现代码,其中需要创建位置策略对象和消费策略对象
package cn.itcast.spark.kafka
import java.util
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream, InputDStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies, ConsumerStrategy, KafkaUtils, LocationStrategies, LocationStrategy
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* Streaming通过Kafka New Consumer消费者API获取数据
*/
object _01StreamingSourceKafka
def main(args: Array[String]): Unit =
// 1. 构建StreamingContext实例对象,传递时间间隔BatchInterval
val ssc: StreamingContext =
// a. 创建SparkConf对象,设置应用基本信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// 设置数据输出文件系统的算法版本为2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b. 创建实例对象,设置BatchInterval
new StreamingContext(sparkConf, Seconds(5))
// 2. 定义数据源,获取流式数据,封装到DStream中
// TODO: 从Kafka消费数据,采用New Consumer API方式
/*
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]]
*/
// a. 位置策略对象
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// b. 消费策略
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "gui-1001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
Array("wc-topic"), //
kafkaParams //
)
// c. 采用New Consumer API获取Kafka Topic中数据
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, //
locationStrategy, //
consumerStrategy //
)
// 仅仅获取Kafka Topic中Value数据:Message消息
val inputDStream: DStream[String] = kafkaDStream.map(record => record.value())
// 3. 依据业务需求,调用DStream中转换函数(类似RDD中转换函数)
/*
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// 此处rdd就是DStream中每批次RDD数据
val resultDStream: DStream[(String, Int)] = inputDStream.transform rdd =>
rdd
.filter(line => null != line && line.trim.length > 0)
.flatMap(line => line.trim.split("\\\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
// 4. 定义数据终端,将每批次结果数据进行输出
/*
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
*/
resultDStream.foreachRDD((rdd, time) =>
//val xx: Time = time
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: $format.format(time.milliseconds)")
println("-------------------------------------------")
// 判断每批次结果RDD是否有数据,如果有数据,再进行输出
if(!rdd.isEmpty())
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
)
// 5. 启动流式应用,等待终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
06-[理解]-集成Kafka时获取消费偏移量信息
当 SparkStreaming 集 成 Kafka 时 , 无 论 是 Old Consumer API 中 Direct 方 式 还 是 NewConsumer API方式获取的数据,每批次的数据封装在KafkaRDD中,其中包含每条数据的元数据信息。
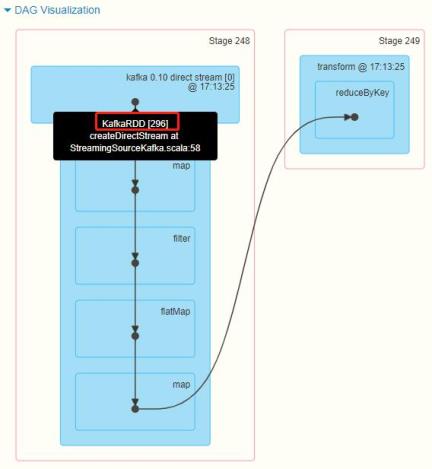
当流式应用程序运行时,在WEB UI监控界面中,可以看到每批次消费数据的偏移量范围,能否在程序中获取数据呢??
官方文档:http://spark.apache.org/docs/2.2.0/streaming-kafka-0-10-integration.html#obtaining-offsets

获取偏移量信息代码如下:

修改前面代码,获取消费Kafka数据时,每个批次中各个分区数据偏移量范围:
package cn.itcast.spark.kafka
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream, InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* Streaming通过Kafka New Consumer消费者API获取数据,获取每批次处理数据偏移量OFFSET
*/
object _02StreamingKafkaOffset
def main(args: Array[String]): Unit =
// 1. 构建StreamingContext实例对象,传递时间间隔BatchInterval
val ssc: StreamingContext =
// a. 创建SparkConf对象,设置应用基本信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// 设置数据输出文件系统的算法版本为2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b. 创建实例对象,设置BatchInterval
new StreamingContext(sparkConf, Seconds(5))
// 2. 定义数据源,获取流式数据,封装到DStream中
// TODO: 从Kafka消费数据,采用New Consumer API方式
/*
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]]
*/
// step1. 表示消费Kafka中Topic数据时,位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// step2. 表示消费Kafka中topic数据时,消费策略,封装消费配置信息
/*
def Subscribe[K, V](
topics: Iterable[jl.String],
kafkaParams: collection.Map[String, Object]
): ConsumerStrategy[K, V]
*/
val kafkaParams: collection.Map[String, Object] = Map(
"bootstrap.servers" -> "node1.itcast.cn:9092", //
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "groop_id_1001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe (
Array("wc-topic"), kafkaParams
)
// step3. 使用Kafka New Consumer API消费数据
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// TODO: 其一、定义数组,用于存储偏移量
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange] // 每个Kafka分区数据偏移量信息封装在OffsetRange对象中
// 3. 依据业务需求,调用DStream中转换函数(类似RDD中转换函数)
/*
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// 此处rdd就是DStream中每批次RDD数据
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform rdd =>
// TODO: 此时直接针对获取KafkaDStream进行转换操作,rdd属于KafkaRDD,包含相关偏移量信息
// TODO: 其二、转换KafkaRDD为HasOffsetRanges类型对象,获取偏移量范围
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
.map(record => record.value())
.filter(line => null != line && line.trim.length > 0)
.flatMap(line => line.trim.split("\\\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
// 4. 定义数据终端,将每批次结果数据进行输出
/*
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
*/
resultDStream.foreachRDD((rdd, time) =>
//val xx: Time = time
val format: FastDateFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
println("-------------------------------------------")
println(s"Time: $format.format(time.milliseconds)")
println("-------------------------------------------")
// 判断每批次结果RDD是否有数据,如果有数据,再进行输出
if(!rdd.isEmpty())
rdd.coalesce(1).foreachPartition(iter => iter.foreach(println))
// TODO: 其三、当当前批次数据处理完成以后,打印当前批次中数据偏移量信息
offsetRanges.foreachoffsetRange =>
println(s"topic: $offsetRange.topic partition: $offsetRange.partition offsets: $offsetRange.fromOffset to $offsetRange.untilOffset")
)
// 5. 启动流式应用,等待终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
07-[了解]-应用案例之业务场景和需求说明
仿【百度搜索风云榜】对用户使用百度搜索时日志进行分析:【百度搜索日志实时分析】,主要业务需求如下三个方面:

业务一:搜索日志数据存储HDFS,实时对日志数据进行ETL提取转换,存储HDFS文件系统;
业务二:百度热搜排行榜Top10,累加统计所有用户搜索词次数,获取Top10搜索词及次数;
业务三:近期时间内热搜Top10,统计最近一段时间范围(比如,最近半个小时或最近2个小时)内用户搜索词次数,获取Top10搜索词及次数;
开发Maven Project中目录结构如下所示:

08-[掌握]-应用案例之初始化环境和工具类
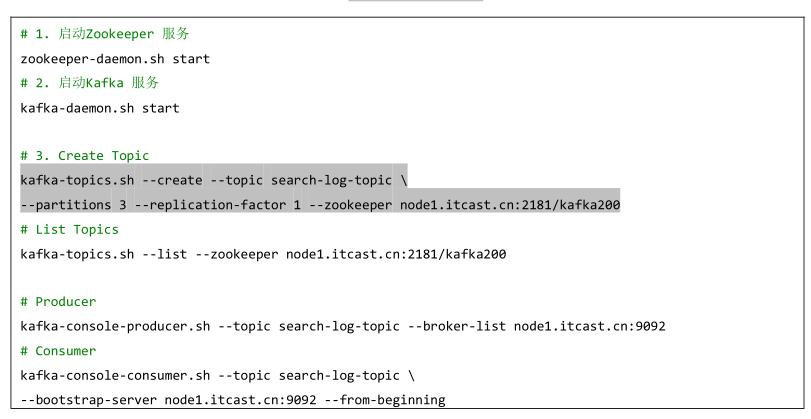
编程实现业务之前,首先编写程序模拟产生用户使用百度搜索产生日志数据和创建工具
StreamingContextUtils提供StreamingContext对象与从Kafka接收数据方法。
- 启动Kafka Broker服务,创建Topic【
search-log-topic】,命令如下所示:
- 模拟日志数据
模拟用户搜索日志数据,字段信息封装到CaseClass样例类【SearchLog】类,代码如下:
package cn.itcast.spark.app.mock
/**
* 用户百度搜索时日志数据封装样例类CaseClass
* <p>
*
* @param sessionId 会话ID
* @param ip IP地址
* @param datetime 搜索日期时间
* @param keyword 搜索关键词
*/
case class SearchLog(
sessionId: String, //
ip: String, //
datetime: String, //
keyword: String //
)
override def toString: String = s"$sessionId,$ip,$datetime,$keyword"
模拟产生搜索日志数据类【MockSearchLogs】具体代码如下:
package cn.itcast.spark.app.mock
import java.util.Properties, UUID
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.KafkaProducer, ProducerRecord
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/**
* 模拟产生用户使用百度搜索引擎时,搜索查询日志数据,包含字段为:
* uid, ip, search_datetime, search_keyword
*/
object MockSearchLogs
def main(args: Array[String]): Unit =
// 搜索关键词,直接到百度热搜榜获取即可
val keywords: Array[String] = Array(
"吴尊友提醒五一不参加大型聚集聚会", "称孩子没死就得购物导游被处罚", "刷视频刷出的双胞胎姐妹系同卵双生",
"云公民受审认罪 涉嫌受贿超4.6亿", "印度男子下跪求警察别拿走氧气瓶", "广电总局:支持查处阴阳合同等问题",
"75位一线艺人注销200家关联公司", "空间站天和核心舱发射成功", "中国海军舰艇警告驱离美舰",
"印度德里将狗用火葬场改为人用", "公安部派出工作组赴广西", "美一男子遭警察跪压5分钟死亡",
"华尔街传奇基金经理跳楼身亡", "阿波罗11号宇航员柯林斯去世", "刘嘉玲向窦骁何超莲道歉"
)
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "node1.itcast.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random: Random = new Random()
while (true)
// 随机产生一条搜索查询日志
val searchLog: SearchLog = SearchLog(
getUserId(), //
getRandomIp(), //
getCurrentDateTime(), //
keywords(random.nextInt(keywords.length)) //
)
println(searchLog.toString)
Thread.sleep(100 + random.nextInt(100))
val record = new ProducerRecord[String, String]("search-log-topic", searchLog.toString)
producer.send(record)
// 关闭连接
producer.close()
/**
* 随机生成用户SessionId
*/
def getUserId(): String =
val uuid: String = UUID.randomUUID().toString
uuid.replaceAll("-", "").substring(16)
/**
* 获取当前日期时间,格式为yyyyMMddHHmmssSSS
*/
def getCurrentDateTime(): String =
val format = FastDateFormat.getInstance("yyyyMMddHHmmssSSS")
val nowDateTime: Long = System.currentTimeMillis()
format.format(nowDateTime)
/**
* 获取随机IP地址
*/
def getRandomIp(): String =
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792,608174079Spark StreamingSpark Day10:Spark Streaming 学习笔记
Spark StreamingSpark Day10:Spark Streaming 学习笔记