Spark StreamingSpark Day10:Spark Streaming 学习笔记
Posted Maynor的大数据奋斗之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark StreamingSpark Day10:Spark Streaming 学习笔记相关的知识,希望对你有一定的参考价值。
Spark Day10:Spark Streaming
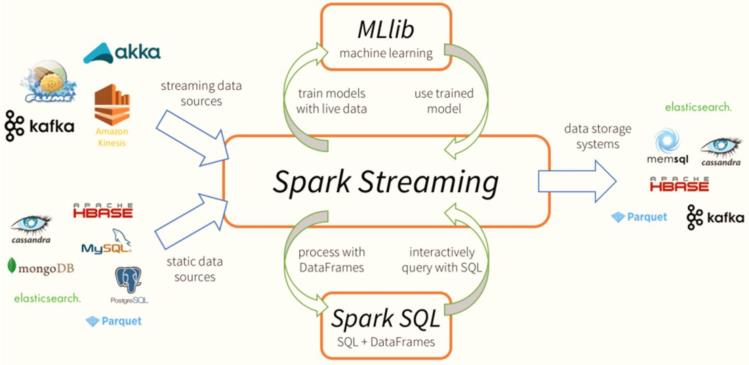
01-[了解]-昨日课程内容回顾
实战练习:以DMP广告行业背景为例,处理广告点击数据,分为2个方面【广告数据ETL转换和业务报表开发】,具体说明如下:
【前提】:使用SparkSQL完成案例练习,进行代码编写
1、广告数据ETL转换
JSON文本数据 -> DataFrame:提取IP地址,解析转换为省份和城市 -> 保存到Hive分区表中
数据源
文件系统(HDFS、LocalFS)文本文件数据:JSON格式
数据处理
ip地址,转换省份与城市
实现:使用DSL编程,可以调用类似SQL语句函数、也可以调用类似RDD转换函数,比如mapPartitions
数据终端Sink
Hive分区表
2、业务报表分析
【前提】:默认情况下,每次分析前一天数据
数据流程:
Hive分区表 -> DataFrame:依据业务进行报表分析统计 -> mysql数据库表中
【注意】:
a. 加载数据时,考虑过滤,仅仅获取前一天数据
b. 报表分析时
使用SQL编程,比较容易
可以考虑DSL编程
c. 保存数据时
不能直接使用SparkSQL提供外部数据源接口,使用原生态JDBC
dataframe.rdd.foreachPartition(iter => saveToMySQL(iter))
【扩展】:向MySQL表写入数据时,实现upsert【主键存在,就更新;不存在,就插入】功能
- 方式一:使用REPALCE 代替INSERT
replace INTO db_test.tb_wordcount (word, count) VALUES(?, ?)
此种方式,有一些限制,比如需要列举出所有列等
- 方式二:ON DUPLICATE KEY UPDATE
INSERT INTO ods_qq_group_members ( gid, uin, datadate )
VALUES (111, 1111111, '2016-11-29' )
ON DUPLICATE KEY UPDATE gid=222, uin=22222, datadate='2016-11-29'
02-[了解]-今日课程内容提纲
从今天开始,进入Spark框架中:关于流式数据分析模块讲解。
- SparkCore与SparkSQL,离线分析批处理,分析数据都是静态的,不变的
- SparkStreaming和StructuredStreaming,实时流式数据分析,分析数据是源源不断产生,一产生就进行分析
首先,学习SparkStreaming流式计算模块,以批处理思想处理流式数据,进行实时分析。
1、Streaming 流式计算概述
Streaming应用场景,目前需求非常多
Lambda 架构,离线和实时
Streaming 计算模式
SparkStreaming 计算思想
2、入门案例
官方案例运行,”词频统计“
编程实现代码:SparkStreaming入门程序编写
Streaming 工作原理
如何使用批的思想处理流式数据
3、DStream:分离、离散流
DStream是什么,DStream = Seq[RDD]
DStream Operations
函数,分为2类:转换函数、输出函数
流式应用状态
03-[了解]-Spark框架中各个模块的数据结构抽象
Spark框架是一个统一分析引擎,包含很多模块,各个模块都有数据结构封装数据。
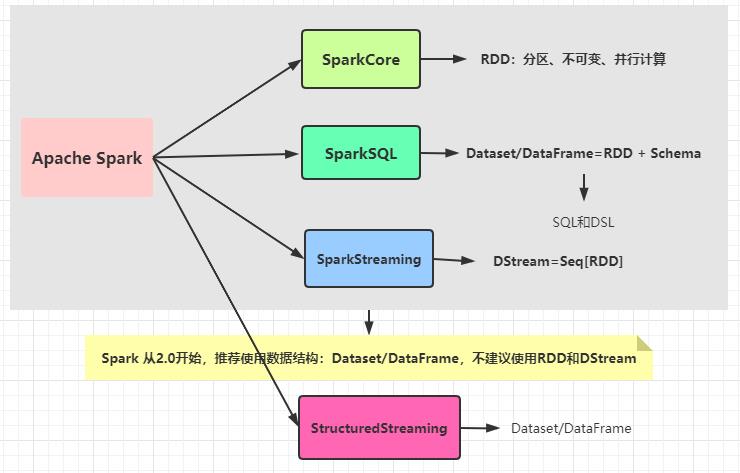
在Spark1.x时,主要三个模块,都是自己数据结构进行封装
- SparkCore:RDD
- SparkSQL:DataFrame/Dataset
- SparkStreaming:DStream
到Spark2.x时,建议使用SparkSQL对离线数据和流式数据分析
Dataset/DataFrame
出现StructuredStreaming模块,将流式数据封装到Dataset中,使用DSL和SQL分析流式数据
04-[了解]-Straming 概述之流式应用场景
- 1)、电商实时大屏:每年双十一时,淘宝和京东实时订单销售额和产品数量大屏展示

- 2)、商品推荐:京东和淘宝的商城在购物车、商品详情等地方都有商品推荐的模块
- 3)、工业大数据:现在的工场中, 设备是可以联网的, 汇报自己的运行状态, 在应用层可以针对
这些数据来分析运行状况和稳健程度, 展示工件完成情况, 运行情况等

- 4)、集群监控:一般的大型集群和平台, 都需要对其进行监控

具体来说,流式计算应用场景如下所示:

05-[掌握]-Straming 概述之Lambda架构
Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架。
- 大数据架构,仅能够进行离线数据分析,又能够进行实时数据计算。
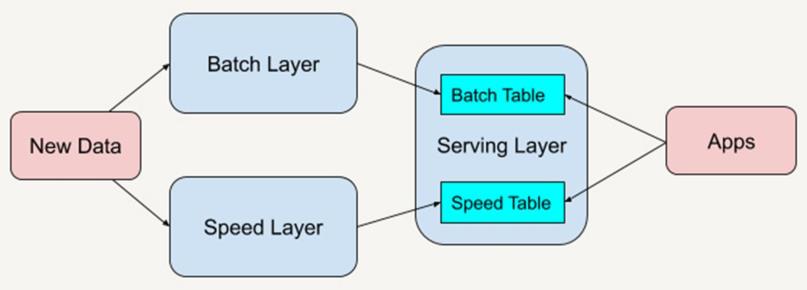
Lambda架构分为三层:
- 第一层:Batch Layer
批处理层
数据离线分析
- 第二层:Speed Layer
速度层
数据实时计算
- 第三层:ServingLayer
服务层
将离线分析和实时计算结果对外提供服务,比如可视化展示
Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
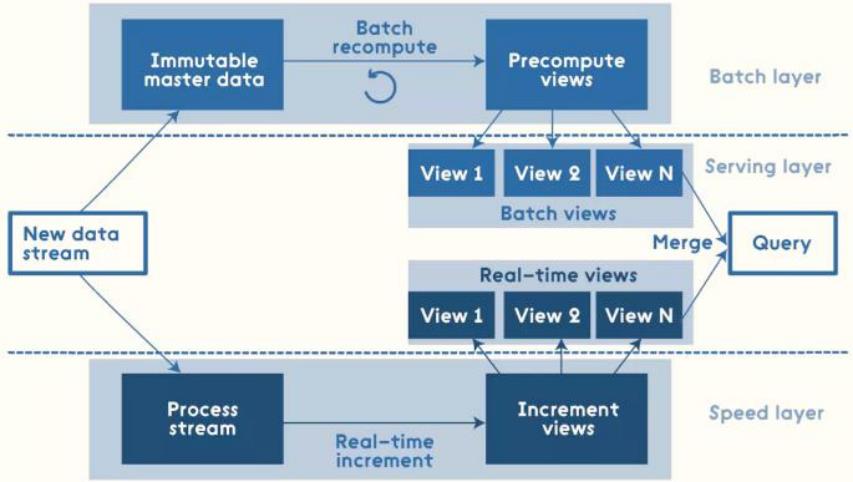
举个例子:
【每年双11狂欢购物节,当天用户交易订单数数据来说】
- 第一点:实时统计交易订单中销售额
totalAmt
最终实时在大屏展示
- 第二点:11.11以后,11.12凌晨,开始对前一天交易数据进行分析
哪个省份娘们最败家
哪个城市女性消费最优秀
无论实时计算还是离线分析,最终都需要展示
提供计算分析的数据
Lambda架构通过分解的三层架构来解决该问题:批处理层(Batch Layer),速度层(SpeedLayer)和服务层(Serving Layer)。

06-[掌握]-Straming 概述之流式数据计算模式
目前大数据框架领域有如下几种流式计算框架:
- 1)、Storm框架
- 阿里巴巴双11,前几年使用就是此框架
- 2)、Samza,领英公司开源
- 严重依赖Kafka,在国内几乎没有公司使用
- 3)、SparkStreaming
- 基于SparkCore之上流式计算框架,目前使用也不多
- 4)、Flink 框架
- 当前大数据流式计算领域最流行框架,尤其在国内,推广十分广泛,各个大厂都在使用,实时性很高,吞吐量比较大,尤其在阿里巴巴公司。
- 5)、StructuredStreaming
- SparkSQL框架中针对流式数据处理功能模块
- 从Spark2.0提出来,相对来说,比较优秀,很多公司在使用SparkSQL时,如果有流式数据需要实时处理的话,直接选择StructuredStreaming
不同的流式处理框架有不同的特点,也适应不同的场景,主要有如下两种模式。
总的来说,流式计算引擎(框架)处理流式数据有2中模式)
- 模式一:原生流处理(Native)
所有输入记录会一条接一条地被处理,上面提到的 Storm 和 Flink都是采用这种方式;

产生一条数据,处理一条数据,此类框架处理数据速度非常快的,实时性很高
- 模式二:微批处理(Batch)
将输入的数据以某一时间间隔 T,切分成多个微批量数据,然后对每个批量数据进行处理,Spark Streaming 和 StructuredStreaming采用的是这种方式

微批处理,将流式数据划分很多批次,往往按照时间间隔划分,比如1秒钟,进行处理分析
对于Spark中StructuredStreaming结构化六来说
- 默认情况下,属于微批处理模式
一批次一批次处理数据
- Spark 2.3开始,Continues Processing
持续流处理,就是原生流模式分析数据
07-[掌握]-Straming 概述之SparkStreaming计算思想
Spark Streaming是Spark生态系统当中一个重要的框架,它
建立在Spark Core之上,下图也可以看出Sparking Streaming在Spark生态系统中地位。

官方定义Spark Streaming模块:

SparkStreaming使用户构建可扩展的、具有容错语义流式应用更加容易。
SparkStreaming是一个基于SparkCore之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。

对于Spark Streaming来说,将流式数据按照时间间隔BatchInterval划分为很多部分,每一部分Batch(批次),针对每批次数据Batch当做RDD进行快速分析和处理。
- 第一点、按照时间间隔划分流式数据
batchInterval,比如1秒
- 第二点、划分数据当做批次Batch
每批次数据认为是RDD
- 第三点,处理流式数据时,仅仅处理每批次RDD即可
RDD数据分析处理
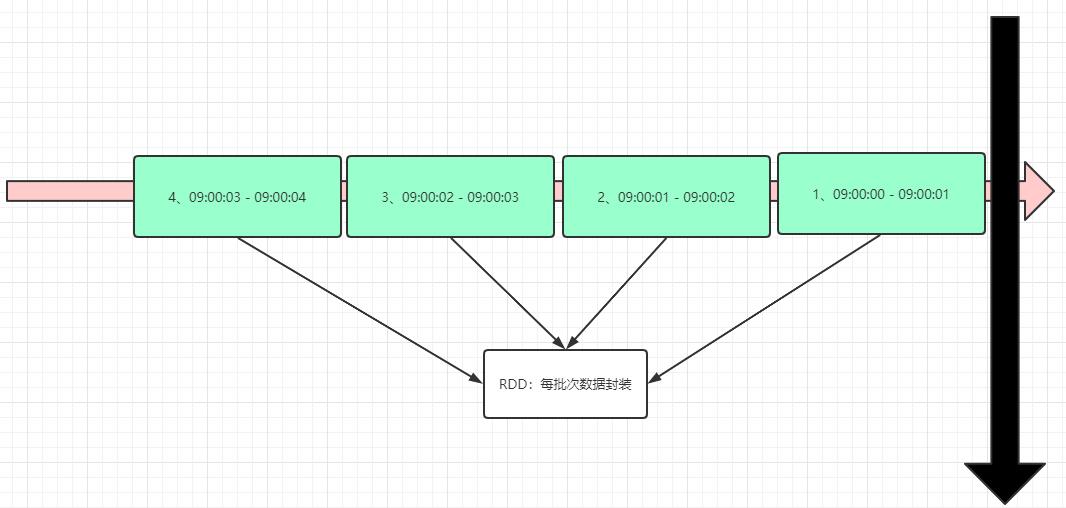
数据结构:DStream,封装流式数据
实质上一系列的RDD的集合,DStream可以按照秒、分等时间间隔将数据流进行批量的划分

将流式数据按照【X seconds】划分很多批次Batch,每个Batch数据封装到RDD中进行处理分析,最后每批次数据进行输出。

对于目前版本的Spark Streaming而言,其最小的
Batch Size的选取在0.5~5秒钟之间,所以Spark Streaming能够满足流式准实时计算场景,
08-[掌握]-入门案例之运行官方词频统计
SparkStreaming官方提供Example案例,功能描述:
从TCP Socket数据源实时消费数据,对每批次Batch数据进行词频统计WordCount,流程图如下:
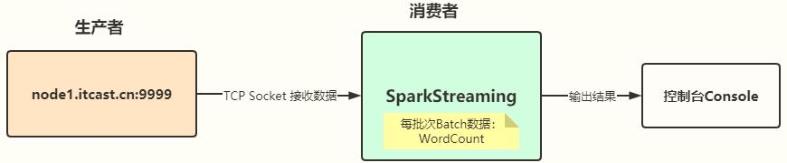
1、数据源:TCP Socket
从哪里读取实时数据,然后进行实时分析
2、数据终端:输出控制台
结果数据输出到哪里
3、功能:对每批次数据实时统计,时间间隔BatchInterval:1s
运行官方提供案例,使用【$SPARK_HOME/bin/run-example】命令运行,效果如下:
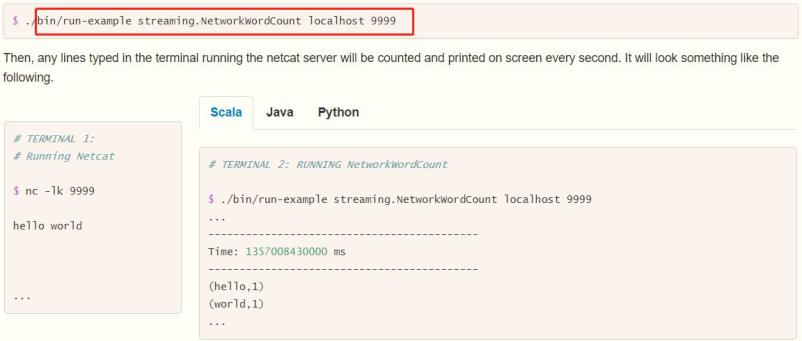
具体步骤如下:



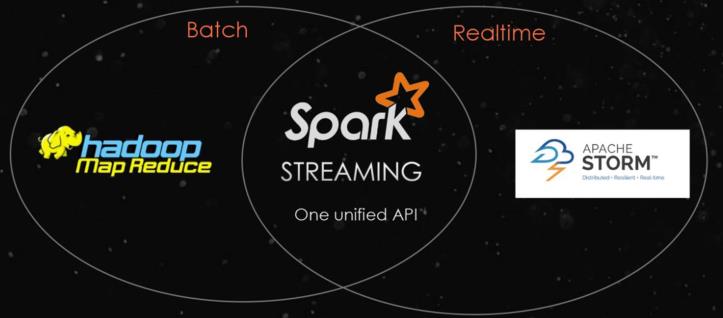
SparkStreaming模块对流式数据处理,介于Batch批处理和RealTime实时处理之间处理数据方式。
09-[掌握]-入门案例之Streaming编程模块
基于IDEA集成开发环境,编程实现:从TCP Socket实时读取流式数据,对每批次中数据进行词频统计WordCount。
在Spark框架中各个模块都有自己数据结构,也有自己的程序入口:
- SparkCore
RDD
SparkContext
- SparkSQL
DataFrame/Dataset
SparkSession/SQLContext(Spark 1.x)
- SparkStreaming
DStream
StreamingContext
参数:划分流式数据时间间隔BatchInterval:1s,5s(演示)
底层还是SparkContext,每批次数据当做RDD
从官方文档可知,提供两种方式构建StreamingContext实例对象,截图如下:
- 第一种方式:构建
SparkConf对象

- 第二种方式:构建SparkContext对象
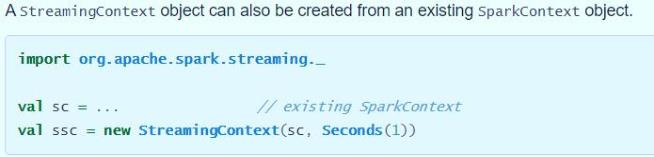
针对SparkStreaming流式应用来说,代码逻辑大致如下五个步骤:

编写SparkStreaming程序模块,构建StreamingContext流式上下文实例对象,启动流式应用等待终止
package cn.itcast.spark.start
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object _01StreamingWordCount
def main(args: Array[String]): Unit =
// TODO: 1. 构建StreamingContext实例对象,传递时间间隔BatchInterval
val ssc: StreamingContext =
// 创建SparkConf对象,设置应用属性
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// 传递sparkConf对象和时间间隔batchInterval:5秒
new StreamingContext(sparkConf, Seconds(5))
// TODO: 2. 定义数据源,获取流式数据,封装到DStream中
// TODO: 3. 依据业务需求,调用DStream中转换函数(类似RDD中转换函数)
// TODO: 4. 定义数据终端,将每批次结果数据进行输出
// TODO: 5. 启动流式应用,等待终止
ssc.start() // 启动流式应用,开始从数据源实时消费数据,处理数据和输出结果
// 流式应用只要已启动,一直运行,除非程序异常终止或者认为终止
ssc.awaitTermination()
// 当流式应用停止时,需要关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true)
10-[掌握]-入门案例之代码实现及测试运行
每个流式应用程序(无论是SparkStreaming、StructuredStreaming还是Flink),最核心有3个步骤
- 第一步、数据源Source
从哪里实时消费流式数据
- 第二步、数据转换Transformation
按照业务处理数据
调用函数
- 第三步、数据终端Sink
将处理结果数据保存到外部系统中
package cn.itcast.spark.start
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream, ReceiverInputDStream
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object _01StreamingWordCount
def main(args: Array[String]): Unit =
// TODO: 1. 构建StreamingContext实例对象,传递时间间隔BatchInterval
val ssc: StreamingContext =
// 创建SparkConf对象,设置应用属性
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// 传递sparkConf对象和时间间隔batchInterval:5秒
new StreamingContext(sparkConf, Seconds(5))
// TODO: 2. 定义数据源,获取流式数据,封装到DStream中
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node1.itcast.cn", 9999)
// TODO: 3. 依据业务需求,调用DStream中转换函数(类似RDD中转换函数)
/*
spark hive hive spark spark hadoop
*/
val resultDStream: DStream[(String, Int)] = inputDStream
// 分割单词
.flatMap(line => line.trim.split("\\\\s+"))
// 转换为二元组
.map(word => word -> 1)
// 按照单词分组,组内进行聚合
/*
(spark, 1)
(spark, 1) -> (spark, [1, 1]) (hive, [1]) -> (spark, 2) (hive, 1)
(hive, 1)
*/
.reduceByKey((tmp, itme) => tmp + itme)
// TODO: 4. 定义数据终端,将每批次结果数据进行输出
resultDStream.print()
// TODO: 5. 启动流式应用,等待终止
ssc.start() // 启动流式应用,开始从数据源实时消费数据,处理数据和输出结果
// 流式应用只要已启动,一直运行,除非程序异常终止或者认为终止
ssc.awaitTermination()
// 当流式应用停止时,需要关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true)
运行结果监控截图:

11-[掌握]-入门案例之SparkStreaming 运行工作原理
SparkStreaming处理流式数据时,按照时间间隔划分数据为微批次(Micro-Batch),每批次数据当做RDD,再进行处理分析。

以上述词频统计WordCount程序为例,讲解Streaming工作原理。
- 第一步、创建 StreamingContext
当SparkStreaming流式应用启动(streamingContext.start)时,首先创建StreamingContext流式上下文实例对象,整个流式应用环境构建,底层还是SparkContext。

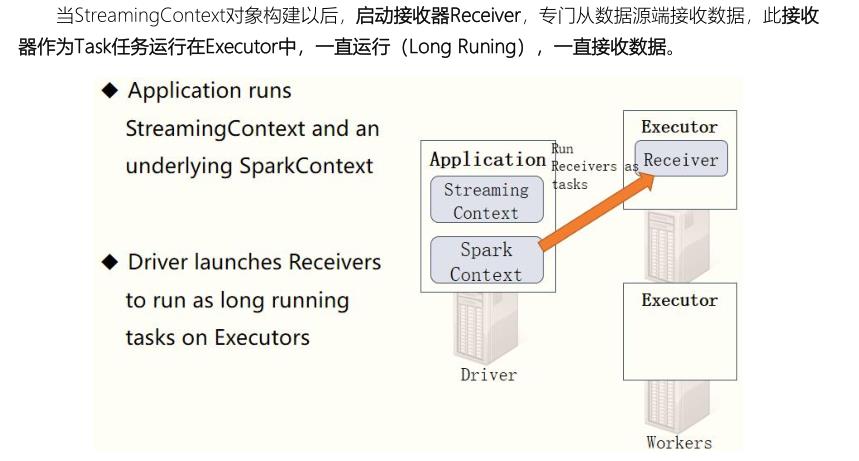
从WEB UI界面【Jobs Tab】可以看到【Job-0】是一个Receiver接收器,一直在运行,以Task方式运行,需要1Core CPU。
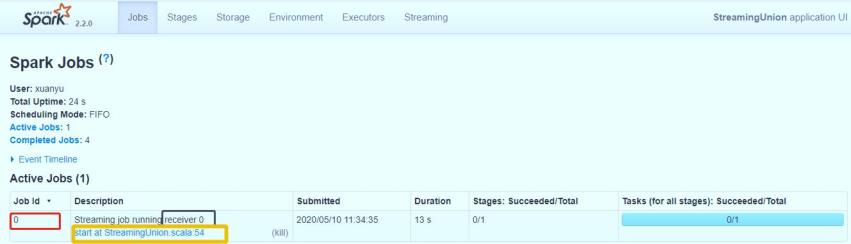
- 第二步、接收器接收数据
启动每个接收器Receiver以后,实时从数据源端接收数据(比如TCP Socket),也是
按照时间间隔将接收的流式数据划分为很多Block(块)。

接 收 器 Receiver 划 分 流 式 数 据 的 时 间 间 隔 BlockInterval , 默 认 值 为 200ms , 通 过 属 性【spark.streaming.blockInterval】设置。
假设设置Batch批次时间间隔为1s,每批次默认情况下,有几个Block呢???
1s = 1000ms = 200ms * 5
所以5个block
将该批次数据当做1个RDD,此时RDD的分区数目为5
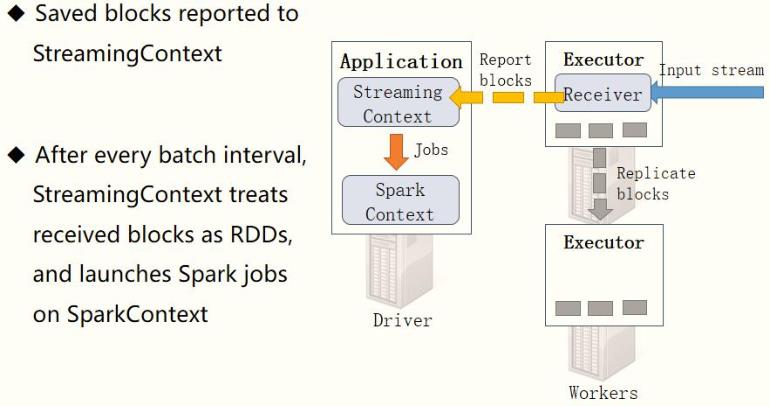
- 第3步、汇报接收Block报告
接收器Receiver将实时汇报接收的数据对应的Block信息,当BatchInterval时间达到以后,StreamingContext将对应时间范围内数据block当做RDD,加载SparkContext处理数据。
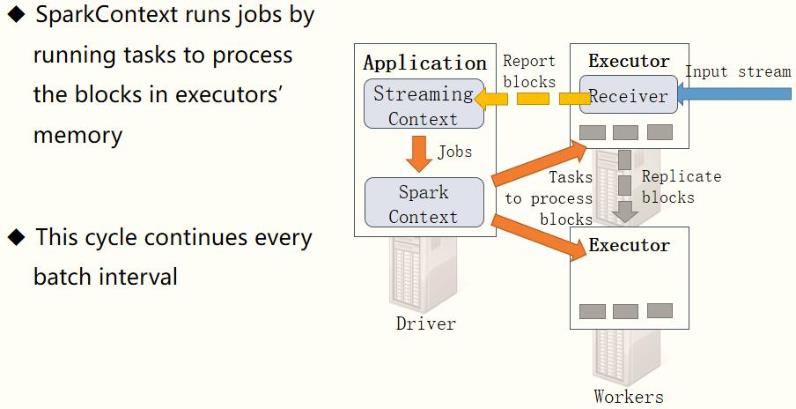
以此循环处理流式的数据,如下图所示:
12-[掌握]-DStream 是什么
SparkStreaming模块将流式数据封装的数据结构:
DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流。
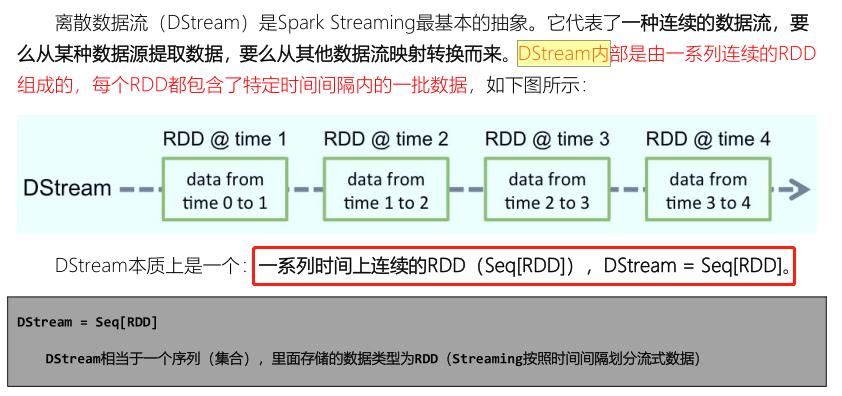
通过WEB UI界面可知,对DStream调用函数操作,底层就是对RDD进行操作,发现狠多时候DStream中函数与RDD中函数一样的。
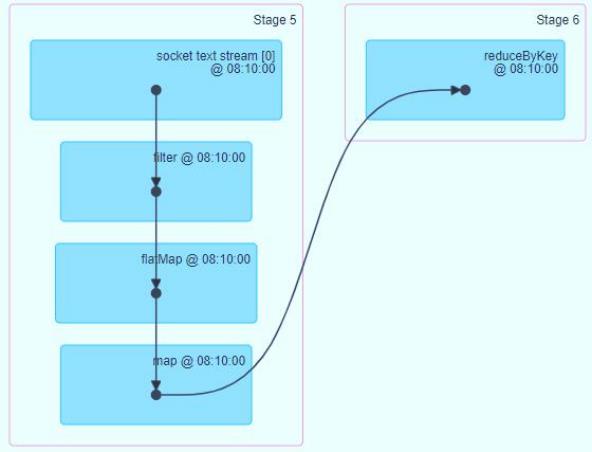
13-[了解]-DStream Operations函数概述
DStream类似RDD,里面包含很多函数,进行数据处理和输出操作,主要分为两大类:

- 其一:转换函数【Transformation函数】

在SparkStreaming中对流的转换操作,主要3种转换类型:
- 对流中数据进行转换
map、flatMpa、filter
- 对流中数据涉及到聚合统计
count
reduce
countByValue
...
- 对2个流进行聚合啊哦做
union
join
cogroup
- 其二:输出函数【Output函数】
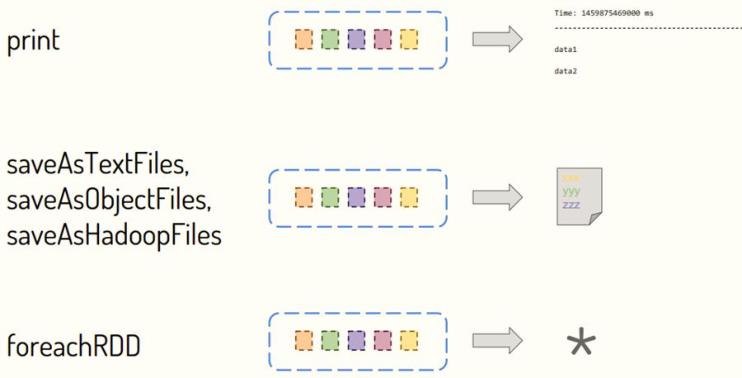
DStream中每批次结果RDD输出使用
foreachRDD函数,前面使用的foreachRDD函数,截图如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1w2D8bG6-1638081078226)(https://gitee.com/the_efforts_paid_offf/picture-blog/raw/master/img/20211128142957.png)]
在DStream中有两个重要的函数,都是针对每批次数据RDD进行操作的,更加接近底层,性能更好,强烈推荐使用:

14-[掌握]-DStream中transform函数使用
通过源码认识
transform函数,有两个方法重载,声明如下:

接下来使用transform函数,修改词频统计程序,具体代码如下:
package cn.itcast.spark.rdd
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object _03StreamingTransformRDD
def main(args: Array[String]): Unit =
// TODO: 1. 构建StreamingContext实例对象,传递时间间隔BatchInterval
val ssc: StreamingContext =
// a. 创建SparkConf对象,设置应用基本信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b. 创建实例对象,设置BatchInterval
new StreamingContext(sparkConf, Seconds(5))
// TODO: 2. 定义数据源,获取流式数据,封装到DStream中
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: DStream[String] = ssc.socketTextStream(
"node1.itcast.cn",
9999,
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// TODO: 3. 依据业务需求,调用DStream中转换函数(类似RDD中转换函数)
/*
TODO: 能对RDD操作的就不要对DStream操作,当调用DStream中某个函数在RDD中也存在,使用针对RDD操作
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// 此处rdd就是DStream中每批次RDD数据
val resultDStream: DStream[(String, Int)] = inputDStream.transformrdd =>
val resultRDD: RDD[(String, Int)] = rdd
// 按照分隔符分割单词
.flatMap(line => line.split("\\\\s+"))
// 转换单词为二元组,表示每个单词出现一次
.map(word => word -> 1)
// 按照单词分组,对组内执进行聚合reduce操作,求和
.reduceByKey((tmp, item) => tmp + item)
// 每批次RDD处理结果RDD返回
resultRDD
// TODO: 4. 定义数据终端,将每批次结果数据进行输出
resultDStream.print()
// TODO: 5. 启动流式应用,等待终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
查看WEB UI监控中每批次Batch数据执行Job的DAG图,直接显示针对RDD进行操作。

15-[掌握]-DStream中foreachRDD函数使用
foreachRDD函数属于将DStream中结果数据RDD输出的操作,类似transform函数,针对每批次RDD数据操作,源码声明如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gFQxcdhr-1638081078229)(/img/image-20210429113612287.png)]
继续修改词频统计代码,自定义输出数据,具体代码如下:
package cn.itcast.spark.output
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object _04StreamingOutputRDD
def main(args: Array[String]): Unit =
// TODO: 1. 构建StreamingContext实例对象,传递时间间隔BatchInterval
val ssc: StreamingContext =
// a. 创建SparkConf对象,设置应用基本信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// TODO:设置数据输出文件系统的算法版本为2
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
// b. 创建实例对象,设置BatchInterval
new StreamingContext(sparkConf, Seconds(5))
// TODO: 2. 定义数据源,获取流式数据,封装到DStream中
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: DStream[String] = ssc.socketTextStream(
"node1.itcast.cn",
9999,
storageLevel = StorageLevel.MEMORY_AND_DISK
)
// TODO: 3. 依据业务需求,调用DStream中转换函数(类似RDD中转换函数)
/*
TODO: 能对RDD操作的就不要对DStream操作,当调用DStream中某个函数在RDD中也存在,使用针对RDD操作
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U]
*/
// 此处rdd就是DStream中每批次RDD数据
val resultDStream: DStream[(String, Int)] = inputDStream.transform rdd =>
val resultRDD: RDD[(String, Int)] = rdd
.filter(line => null != line && line.trim.length > 0)
.flatMap(line => line.trim.split("\\\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
// 返回结果RDD
resultRDD
// TODO: 4. 定义数据终端,将每批次结果数据进行输出
//resultDStream.print()
/*
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit
rdd 表示每批次处理结果RDD
time 表示批次产生的时间,Long类型
*/
resultDStream.foreachRDD((rdd, time) =>
// 打印每批次产生的时间
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss").format(time.milliseconds)
println("-------------------------------------------")
println(s"Batch Time: $batchTime")
println("-------------------------------------------")
// TODO: 判断结果RDD是否有数据,有数据,再进行输出,否则不操作
if(!rdd.isEmpty())
// 对结果RDD进行输出时:降低分区数目、针对每个分区操作、通过连接池(sparkStreaming)获取连接
val resultRDD: RDD[(String, Int)] = rdd.coalesce(1)
resultRDD.cache()
// 将结果RDD 打印控制台
resultRDD.foreachPartition(iter => iter.foreach(println))
// 将结果RDD 保存文件中
resultRDD.saveAsTextFile(s"datas/streaming-wc-$time.milliseconds")
resultRDD.unpersist()
)
// TODO: 5. 启动流式应用,等待终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
16-[了解]-SparkStreaming流式应用三种状态
使用SparkStreaming处理实际实时应用业务时,针对不同业务需求,需要使用不同的函数。SparkStreaming流式计算框架,针对具体业务主要分为三类,使用不同函数进行处理:
- 业务一:
无状态Stateless

- 业务二:
有状态State
- 业务三:
窗口统计
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g0Xbre1z-1638081078231)(/img/image-20210429115034287.png)]
附录一、创建Maven模块
1)、Maven 工程结构
2)、POM 文件内容
Maven 工程POM文件中内容(依赖包):
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<kafka.version>2.0.0</kafka.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>$scala.version</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<!-- Spark Streaming 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>s以上是关于Spark StreamingSpark Day10:Spark Streaming 学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
Spark StreamingSpark Day10:Spark Streaming 学习笔记
Spark StreamingSpark Day10:Spark Streaming 学习笔记