强化学习笔记:Actor-critic
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记:Actor-critic相关的知识,希望对你有一定的参考价值。
0 复习
由于actor-critic 是 policy gradient 和DQN的一个结合,所以我们先对这两个进行一个简单的复习:
0.1 policy gradient
强化学习笔记:Policy-based Approach_UQI-LIUWJ的博客-CSDN博客
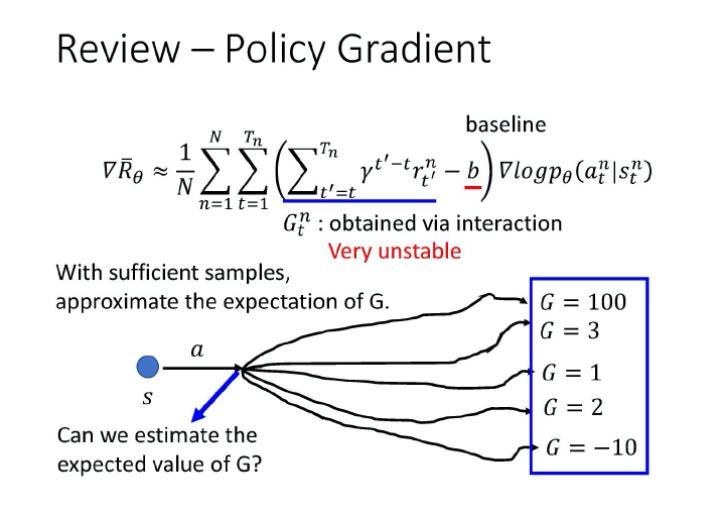
在policy network中,我们使用梯度上升的方法更新参数。梯度计算方法如下:(这里的N是采样次数,我们为了更新θ,采样N次)
这个式子是在说,我们先让 agent 去跟环境互动(采样),那我们可以计算出在某一个状态 s,采取了某一个动作 a 的概率
。
接下来,我们去计算在某一个状态 s 采取了某一个动作 a 之后,到游戏结束为止,累积奖励有多大。我们把从时间 t 到时间 T 的奖励通通加起来,并且会在前面乘一个折扣因子γ。
我们会减掉一个 baseline b,减掉这个值 b 的目的,是希望括号这里面这一项是有正有负的。如果括号里面这一项是正的,我们就要通过更新θ来增加在这个状态采取这个动作的机率;如果括号里面是负的,我们就要通过更新θ来减少在这个状态采取这个动作的机率。
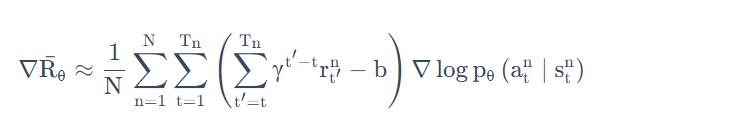
我们把用 G 来表示累积奖励。
但 G 这个值,其实是非常不稳定的。因为互动(采样)的过程本身是有随机性的,所以在某一个状态 s 采取某一个动作 a,然后计算累积奖励,每次算出来的结果都是不一样的(因为后续各状态选取action都是按照概率选取的,所以之后各个状态、各个action的路径是不一样的) 。
假设我们可以采样足够的次数,在每次更新参数之前,我们都可以采样足够的次数,那其实没有什么问题。但问题就是我们每次做 policy gradient,每次更新参数之前都要做一些采样,这个采样的次数其实是不可能太多的,我们只能够做非常少量的采样。所以会有一定的误差。这也是policy gradient的不足之处
0.2 DQN
那么针对之前所说的policy gradient的不足之处,有没有什么办法可以让整个训练过程变得稳定一些呢?
我们在状态 s 采取动作 a 的时候,直接用一个网络去估测在状态 s 采取动作 a 的时候,G 的期望值。如果这件事情是可行的,那之后训练的时候,就用期望值来代替采样的值,这样会让训练变得比较稳定。
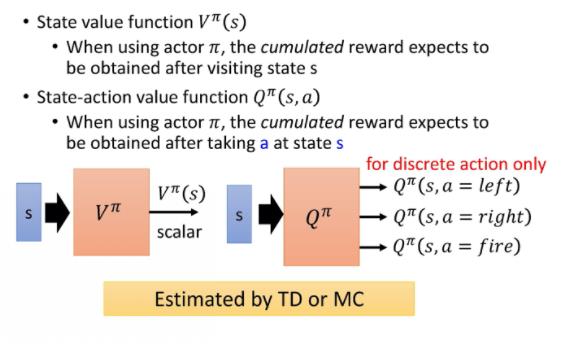
这边就需要引入基于价值的(value-based)的方法。基于价值的方法就是 Q-learning。Q-learning 有两种函数,有两种 critics:
-
第一种 critic 是
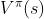 ,它的意思是说,假设 actor 是 π,拿 π 去跟环境做互动,当我们看到状态 s 的时候,接下来累积奖励 的期望值有多少。
,它的意思是说,假设 actor 是 π,拿 π 去跟环境做互动,当我们看到状态 s 的时候,接下来累积奖励 的期望值有多少。 -
还有一个 critic 是
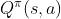 。把 s 跟 a 当作输入,它的意思是说,在状态 s 采取动作 a,接下来都用 actor π 来跟环境进行互动,累积奖励的期望值是多少。
。把 s 跟 a 当作输入,它的意思是说,在状态 s 采取动作 a,接下来都用 actor π 来跟环境进行互动,累积奖励的期望值是多少。
可以用 TD 或 MC 来估计。用 TD 比较稳定,用 MC 比较精确。
DQN 笔记 State-action Value Function(Q-function)_UQI-LIUWJ的博客-CSDN博客
1 actor-critic

随机变量 G的期望值正好就是 Q
Q-function 的定义就是在某一个状态 s,采取某一个动作 a,假设 policy 就是 π 的情况下会得到的累积奖励的期望值有多大,而这个东西就是 G 的期望值。
所以假设用
来代表
这一项的话,把 Q-function 套在这里就结束了,我们就可以把 Actor 跟 Critic 这两个方法结合起来。
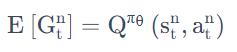
有不同的方法来表示 baseline,但一个常见的做法是用价值函数
来表示 baseline。
价值函数是说,假设 policy 是π,在某一个状态 s 一直互动到游戏结束,期望奖励(expected reward)有多大。
涉及到动作。
会有正有负,所以代换后的
这一项就会是有正有负的。合理。
所以我们就把 policy gradient 里面
2 advantage actor-critic (A2C)
2.1 大致思想

如果你这么实现的话,有一个缺点是:你要估计 2 个 网络:Q-network 和 V-network。不仅耗时,而且不确定性大。
事实上在这个 Actor-Critic 方法里面。你可以只估测 V 这个网络,你可以用 V 的值来表示 Q 的值,
可以写成
的期望值,即
你在状态 s 采取动作 a,会得到奖励 r,然后跳到状态
。但是你会得到什么样的奖励 r,跳到什么样的状态
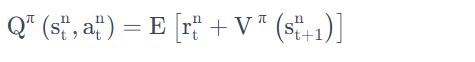
但是在A3C 论文里面,通过实验发现,把期望值直接摘掉,效果更好,于是就有:
因为
叫做
Advantage function。所以这整个方法就叫Advantage Actor-Critic。
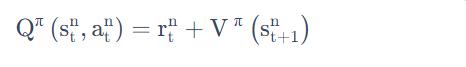
2.2 大体流程
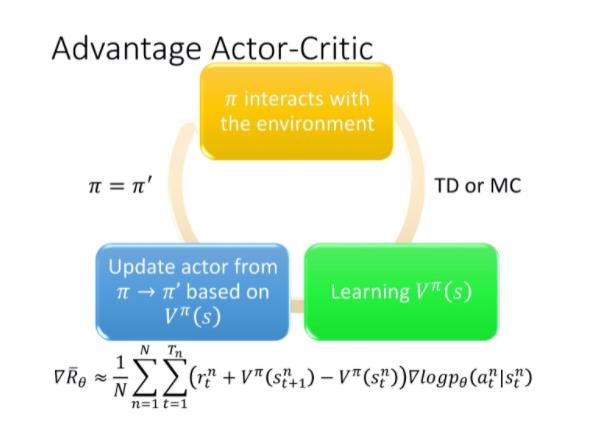
我们有一个 初始的 actor π,用他去跟环境做互动,先采样收集资料。
在 policy gradient 方法里面收集资料以后,你就要拿去通过梯度上升的方法更新 policy。
但是在 actor-critic 方法里面,你先拿这些采样得到的资料去估计价值函数V(用 TD 或 MC 来估计价值函数) 。接下来,你再基于价值函数,套用下面这个式子去更新 π,得到新的actor π'。
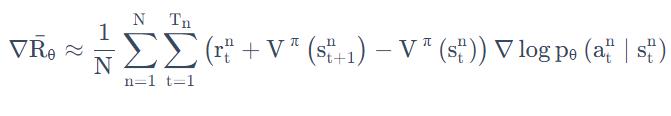
然后你有了新的 π 以后,再去跟环境互动,再收集新的资料,去估计价值函数。然后再用新的价值函数 去更新 policy,去更新 actor。
2.3 tips
2.3.1 前几层共享参数
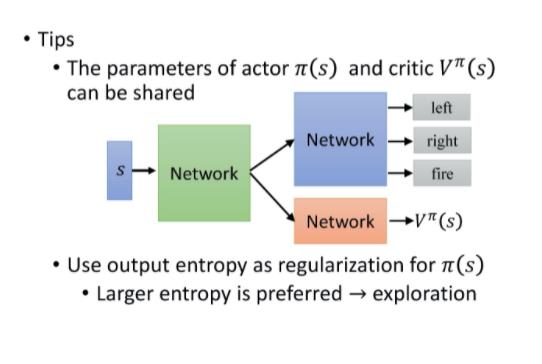
我们需要估计两个网络:V function 、 policy 的网络(也就是 actor)。
- Critic 网络
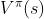 输入一个状态,输出一个标量。
输入一个状态,输出一个标量。 - Actor 网络π(s) 输入一个状态,
- 如果动作是离散的,输出就是一个动作的概率分布。
- 如果动作是连续的,输出就是一个连续的向量。
- 这两个网络,actor 和 critic 的输入都是 s,所以它们前面几个层是可以共享的。
假设你今天是玩 Atari 游戏,输入都是图像。输入的图像都非常复杂,图像很大,通常你前面都会用一些 CNN 来处理,把那些图像抽象成高级的信息。把像素级别的信息抽象成高级信息这件事情,其实对 actor 跟 critic 来说是可以共用的。所以通常你会让 actor 跟 critic 的前面几个层共用同一组参数,那这一组参数可能是 CNN 的参数。
换句话说,先把输入的像素变成比较高级的信息,然后再给 actor 去决定说它要采取什么样的行为;给 critic去计算V function。
2.3.2 探索机制exploration
在做 Actor-Critic 的时候,有一个常见的探索的方法是去约束 π 的输出的分布。
这个约束是希望这个分布的熵(entropy)不要太小,希望这个分布的熵可以大一点,也就是希望不同的动作它的被采用的概率平均一点。
这样在测试的时候,它才会多尝试各种不同的动作,才会把这个环境探索的比较好,才会得到比较好的结果。
3 A3C
3.1 大体思想(来自李宏毅教授)
强化学习有一个问题就是它很慢,那怎么增加训练的速度呢?李宏毅教授举了一个很直观的例子:
有一次鸣人说,他想要在一周之内打败晓,所以要加快修行的速度,他老师就教他一个方法:用影分身进行同样修行。两个一起修行的话,经验值累积的速度就会变成 2 倍,所以鸣人就开了 1000 个影分身来进行修行。这个其实就是
Asynchronous(异步的) Advantage Actor-Critic,也就是 A3C 这个方法的精神。
3.2 主体框架
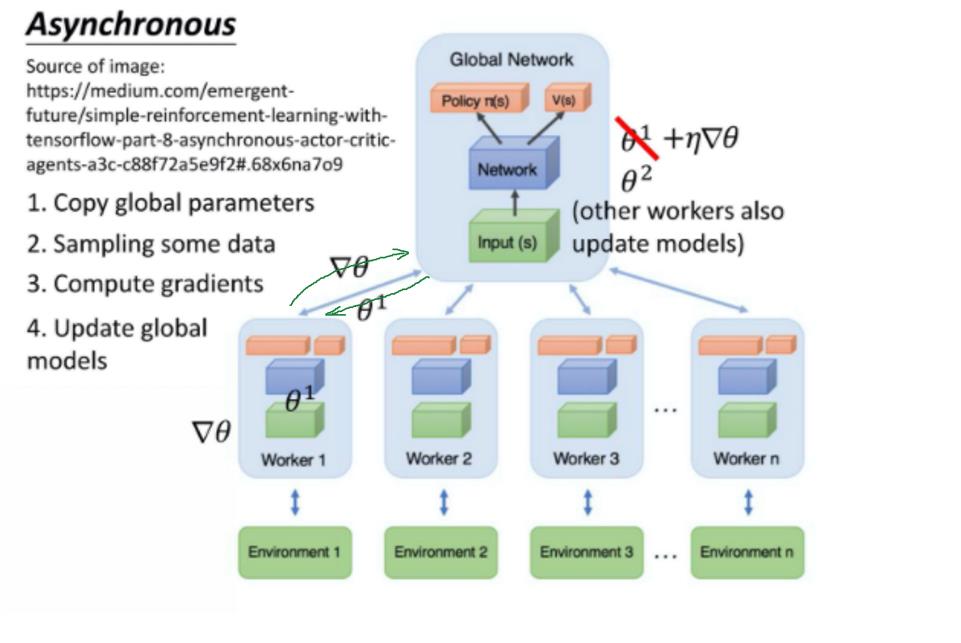
A3C 这个方法就是同时开很多个 worker,那每一个 worker 其实就是一个影分身。那最后这些影分身会把所有的经验,通通集合在一起。你如果没有很多个 CPU,可能也是不好实现的,你可以实现 A2C 就好。
- A3C 一开始有一个 global network。假设 global network 的参数是θ1,你会开很多个 worker。每一个 worker 就用一张 CPU 去跑。比如你就开 8 个 worker,那你至少 8 张 CPU。每一个 worker 工作前都会将 global network 的参数复制过来。
-
接下来你就去跟环境做互动。每一个 actor 跟环境做互动,互动完之后,你就会计算出梯度。计算出梯度以后,用你的梯度去更新 global network 的参数。(就是这个 worker 算出梯度以后,就把梯度传回给中央的控制中心,然后中央的控制中心就会拿这个梯度去更新原来的参数。)
- 下一步,这个worker将更新完的参数θ2复制回来,继续同样的过程。
注意,所有的 actor 都是平行跑的,每一个 actor 就是各做各的,不管彼此。
所以每个人都是去要了一个参数以后,做完就把参数传回去。
因此当第一个 worker 做完想要把参数传回去的时候,本来它要的参数是θ1,等它要把梯度传回去的时候。可能别人已经把原来的参数覆盖掉,变成θ2了。但是没有关系,global network 对θ2进行更新(使用worker传回的梯度)。
以上是关于强化学习笔记:Actor-critic的主要内容,如果未能解决你的问题,请参考以下文章
深度强化学习 Actor-Critic 模型解析,附Pytorch完整代码