强化学习—— Actor-Critic
Posted CyrusMay
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习—— Actor-Critic相关的知识,希望对你有一定的参考价值。
强化学习(四)—— Actor-Critic
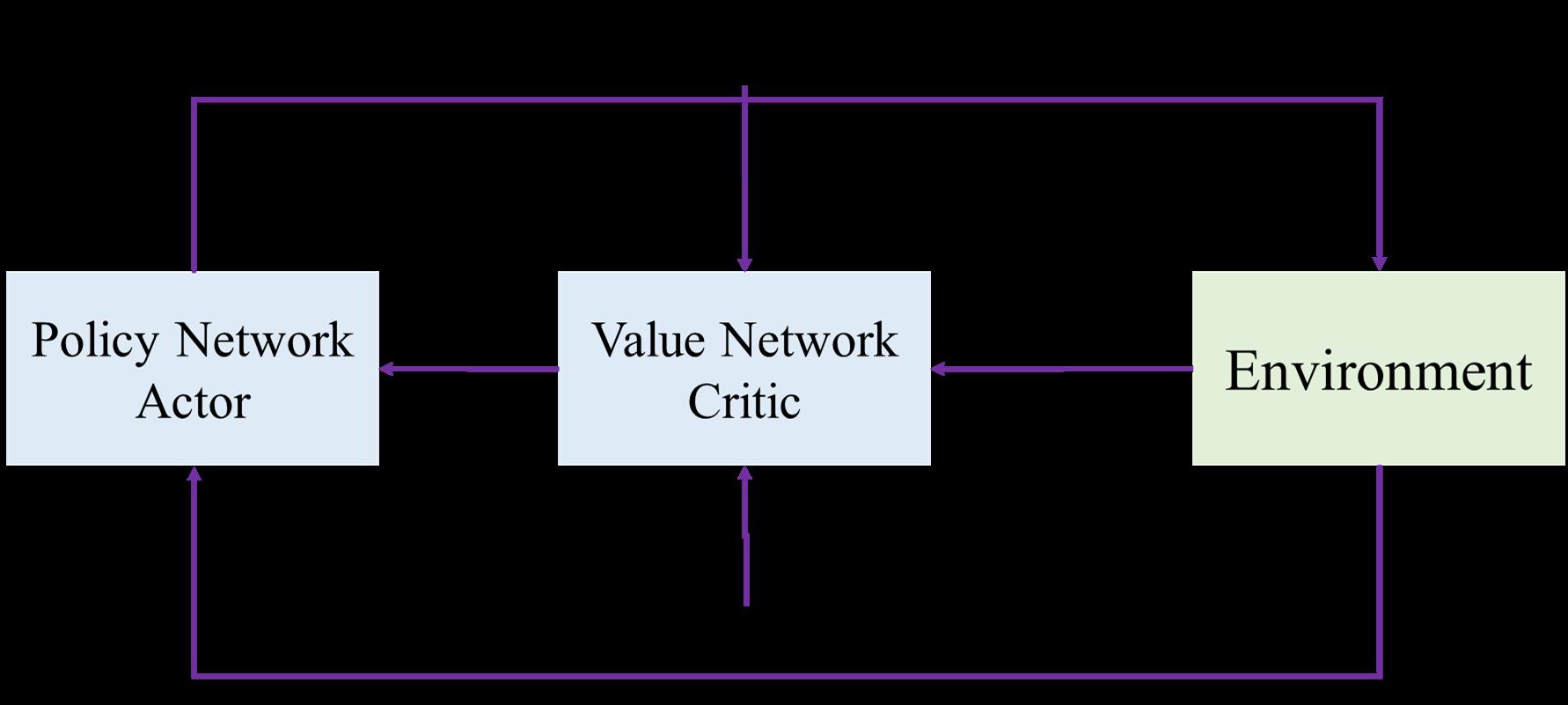
1. 网络结构
-
状态价值函数:
V π ( s t ) = ∑ a Q π ( s t , a ) ⋅ π ( a ∣ s t ) V_\\pi(s_t)=\\sum_aQ_\\pi(s_t,a)\\cdot\\pi(a|s_t) Vπ(st)=a∑Qπ(st,a)⋅π(a∣st) -
通过策略网络近似策略函数:
π ( a ∣ s ) ≈ π ( a ∣ s ; θ ) \\pi(a|s)\\approx\\pi(a|s;\\theta) π(a∣s)≈π(a∣s;θ)

-
通过价值网络近似动作价值函数:
q ( s , a ; W ) ≈ Q ( s , a ) q(s,a;W)\\approx Q(s,a) q(s,a;W)≈Q(s,a)
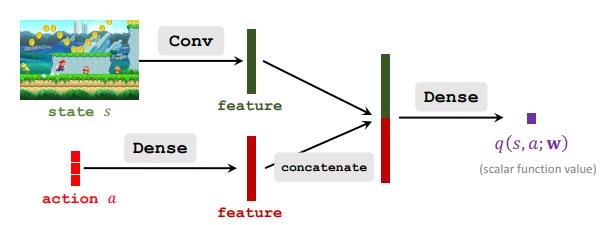
-
神经网络近似后的状态价值函数:
V ( s ; θ , W ) = ∑ a q ( s , a ; W ) ∗ π ( a ∣ s ; θ ) V(s;\\theta ,W)=\\sum_aq(s,a;W)*\\pi(a|s;\\theta) V(s;θ,W)=a∑q(s,a;W)∗π(a∣s;θ) -
通过对策略网络不断更新以增加状态价值函数值。
-
通过对价值网络不断更新来更好的预测所获得的回报。
2. 网络函数
Policy Network
- 通过策略网络近似策略函数
π ( a ∣ s t ) ≈ π ( a ∣ s t ; θ ) π(a|s_t)≈π(a|s_t;\\theta) π(a∣st)≈π(a∣st;θ) - 状态价值函数及其近似
V π ( s t ) = ∑ a π ( a ∣ s t ) Q π ( s t , a ) V_π(s_t)=\\sum_aπ(a|s_t)Q_π(s_t,a) Vπ(st)=a∑π(a∣st)Qπ(st,a)
V ( s t ; θ ) = ∑ a π ( a ∣ s t ; θ ) ⋅ Q π ( s t , a ) V(s_t;\\theta)=\\sum_aπ(a|s_t;\\theta)·Q_π(s_t,a) V(st;θ)=a∑π(a∣st;θ)⋅Qπ(st,a) - 策略学习最大化的目标函数
J ( θ ) = E S [ V ( S ; θ ) ] J(\\theta)=E_S[V(S;\\theta)] J(θ)=ES[V(S;θ)] - 依据策略梯度上升进行
θ ← θ + β ⋅ ∂ V ( s ; θ ) ∂ θ \\theta\\gets\\theta+\\beta·\\frac\\partial V(s;\\theta)\\partial \\theta θ←θ+β⋅∂θ∂V(s;θ)
3. 策略网络的更新-策略梯度
Policy Network
- 策略梯度为:
g ( a , θ ) = ∂ l n π ( a ∣ s ; θ ) ∂ θ ⋅ q ( s , a ; W ) ∂ V ( s ; θ , W ) ∂ θ = E [ g ( A , θ ) ] g(a,\\theta)=\\frac\\partial ln\\pi(a|s;\\theta)\\partial \\theta\\cdot q(s,a;W)\\\\\\frac\\partial V(s;\\theta,W)\\partial \\theta=E[g(A,\\theta)] g(a,θ)=∂θ∂lnπ(a∣s;θ)⋅q(s,a;W)∂θ∂V(s;θ,W)=E[g(A,θ)] - 可采用随机策略梯度,(无偏估计)
a ∼ π ( ⋅ ∣ s t ; θ ) θ t + 1 = θ t + β ⋅ g ( a , θ t ) a\\sim \\pi(\\cdot|s_t;\\theta)\\\\\\theta_t+1=\\theta_t+\\beta·g(a,\\theta_t) a∼π(⋅∣st;θ)θt+1=θt+β⋅g(a,θt)
4. 价值网络的更新-时序差分(TD)
- TD的目标:
y t = r t + γ q ( s t + 1 , a t + 1 ; W t ) y_t= r_t+\\gamma q(s_t+1,a_t+1;W_t) yt=rt+γq(st+1,at+1;Wt) - 损失函数为:
l o s s = 1 2 [ q ( s t , a t ; W t ) − y t ] 2 loss = \\frac12[q(s_t,a_t;W_t)-y_t]^2 loss=21[q(st,at;Wt)−yt]2 - 采用梯度下降进行更新:
W t + 1 = W t − α ⋅ ∂ l o s s ∂ W ∣ W = W t W_t+1=W_t-\\alpha\\cdot\\frac\\partial loss\\partial W|_W=W_t Wt+1=Wt−α⋅∂W∂lo论文阅读|图神经网络+Actor-Critic求解静态JSP(End-to-End DRL)《基于深度强化学习的调度规则学习》(附带源码)
深度强化学习 Actor-Critic 模型解析,附Pytorch完整代码
Actor-critic强化学习方法应用于CartPole-v1