论文阅读|图神经网络+Actor-Critic求解静态JSP(End-to-End DRL)《基于深度强化学习的调度规则学习》(附带源码)
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读|图神经网络+Actor-Critic求解静态JSP(End-to-End DRL)《基于深度强化学习的调度规则学习》(附带源码)相关的知识,希望对你有一定的参考价值。
《Learning to Dispatch for Job Shop scheduling via Deep Reinforcemnet Learning》
NeurIPS 2020
1 摘要
优先调度规则(Priority dispatching rule,PDR)广泛用于求解JSSP问题,这篇文章通过端到端的深度强化学习代理来自动学习PDR。利用JSSP的析取图表示,提出了一种基于图神经网络(Graph Neural Network,GNN)的方案来嵌入求解过程中遇到的状态。由此产生的策略网络与大小无关,有效地实现了大规模实例的泛化。实验表明,该代理能够以基本的原始特征从头开始学习高质量的PDR,并且与现有最好的PDR相比表现出很强的性能。
2 文章解读
这篇文章研究的问题为静态的JSP问题。出发点是通过研究析取图,通过图神经网络来挖掘析取图中蕴含的信息,以此来达到端到端的实现。
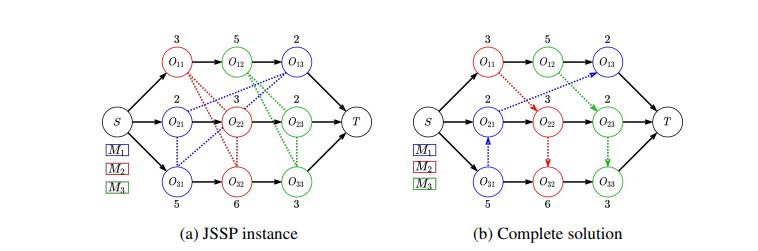
2.1 相关状态、动作、状态转移、奖励、策略的定义
2.1.1 状态(state)
状态即为解的当前析取图状态
2.1.2 动作(action)
动作集为当前可进行加工的工序集,从中选择一个最为合适的工作作为当前阶段的动作。
2.1.3 状态转移
一旦确定下一步要调度的操作,我们首先要找到在所需机器上分配的最早可行时间段。然后,我们根据当前的时间关系更新该机器的析取弧的方向,并生成一个新的析取图作为新的state。
 2.1.4 奖励
2.1.4 奖励
我们的目标是学会一步一步地进行调度,以便最大限度地减少完工时间。为此,我们将奖励函数R(st,at)设计为两个状态s(t+1)、s(t)对应的部分解之间的质量差,即R(at,st)=H(St)−H(st+1),其中H(·)是质量度量。这里我们将其定义为最大完工时间的下界,即:
2.1.5 策略
对于状态st,随机策略π(at|st)输出动作为动作集At上的分布。如果采用传统的PDR作为策略,则分布为one-hot,并且具有最高优先级的动作的概率为1。
2.2 将策略参数化
将随机策略π(at|st)参数化为具有可训练参数θ的图神经网络,即πθ(at|st),它可以学习强调度规则并泛化。
2.2.1 Graph embedding
这篇文章采用的是图同构网络(Graph Isomorphism Network,GIN),对给定图G=(V,E),GIN执行多次更新以计算每个节点v∈V的一维嵌入,并且迭代时的更新如下所示:

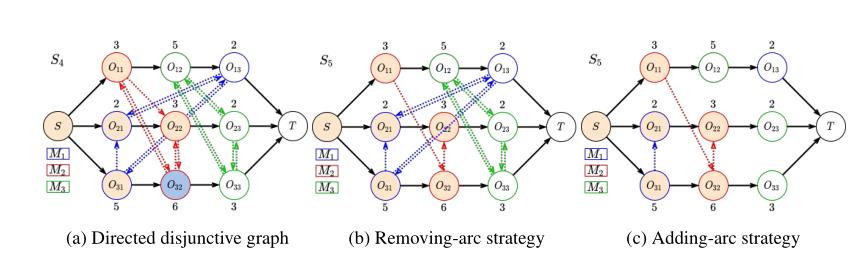
GIN最初是针对无向图提出的,然而对JSP,析取图是一个即带有向弧的混合图,用于描述机器上的优先约束和操作序列等关键特征,这里有两种解决方法:
法一:
将无向弧换为两条有向弧,这样的话在状态转移的过程中就需要去掉其余的无向图。
法二:
忽略未定向的析取弧,通过添加弧的方式来表达状态转移,这样的一个缺点就是得到的状态表示更加稀疏。
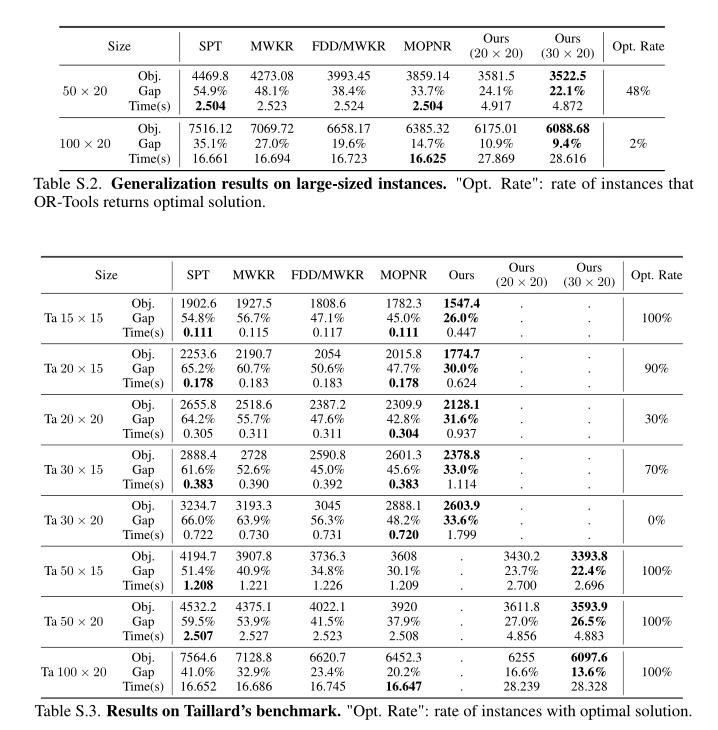
3 实验

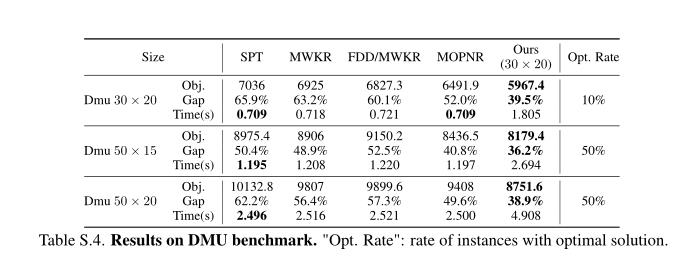
以上是关于论文阅读|图神经网络+Actor-Critic求解静态JSP(End-to-End DRL)《基于深度强化学习的调度规则学习》(附带源码)的主要内容,如果未能解决你的问题,请参考以下文章