技术分享 | 浅谈TensorRT
Posted 阿木实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享 | 浅谈TensorRT相关的知识,希望对你有一定的参考价值。
 Tensor是一个有助于在NVIDIA图形处理单元(GPU)上高性能推理c++库。它旨在与TesnsorFlow、Caffe、Pytorch以及MXNet等训练框架以互补的方式进行工作,专门致力于在GPU上快速有效地进行网络推理。
Tensor是一个有助于在NVIDIA图形处理单元(GPU)上高性能推理c++库。它旨在与TesnsorFlow、Caffe、Pytorch以及MXNet等训练框架以互补的方式进行工作,专门致力于在GPU上快速有效地进行网络推理。
如今现有的一些训练框架(例如TensorFlow)已经集成了TensorRT,因此可以将其用于加速框架中的推理。另外,TensorRT可以作为用户应用程序中的库,它包括用于从Caffe,ONNX或TensorFlow导入现有模型的解析器,以及用于以编程方式(C++或Python API)构建模型。
一、TensorRT的好处 在训练了神经网络之后,TensorRT可以对网络进行压缩、优化以及运行时部署,并且没有框架的开销。TensorRT通过combines layers,kernel优化选择,以及根据指定的精度执行归一化和转换成最优的matrix math方法,改善网络的延迟、吞吐量以及效率。
对于深度学习推理中,有5个用于衡量软件的关键因素:
- 吞吐量
- 效率
- 延迟性
- 准确性
- 内存使用情况
TensorRT通过结合抽象出特定硬件细节的高级API和优化推理的实现来解决这些问题,以实现高吞吐量、低延迟和低设备内存占用。
二、TensorRT适用于那些地方 通常,开发和部署一个深度学习模型的工作流程分为了3个阶段:
第一个阶段是训练模型【在该阶段一般都不会使用TensorRT训练任何模型】 第二个阶段是开发一个部署的解决方案 第三个阶段是使用开发的解决方案进行部署【即使用阶段2中的解决方案来进行部署】
阶段1:Training 在训练阶段,通常会先确定自己需要解决的问题,网络的输入输出,以及网络的损失函数,然后再设计网络结构,接下来就是根据自己的需求去整理、扩充training data,validation data and test data。在训练模型的过程中,我们一般都会通过监视模型的整个训练流程来确定自己是否需要修改网络的损失函数、训练的超参数以及数据集的增强。最后我们会使用validation data对trained model进行性能评估。需要注意的是,在该阶段一般都不会使用TensorRT训练任何模型。
阶段2:Developing A Deployment Solution 在这个阶段,我们将会通过使用trained model来创建和验证部署解决方案,该阶段分为以下几个步骤:
1、首先需要考虑清楚神经网络在系统中是如何进行工作的,根据需求中的优先事项设计出适应的解决方案。另一方面,由于不同系统之间存在多样性的原因,我们在设计和实现部署结构时需要考虑很多方面的因素。【例如,是单个网络还是多个网络,需要哪些后处理步骤等等之内的因素】
2、当设计好解决方案后,我们便可以使用TensorRT从保存的网络模型中构建一个inference engine。由于在training model期间可以选择不同的framework,因此,我们需要根据不同框架的格式,使用相应的解析器将保存的模型转换为TensorRT的格式。具体的工作流程如下图所示 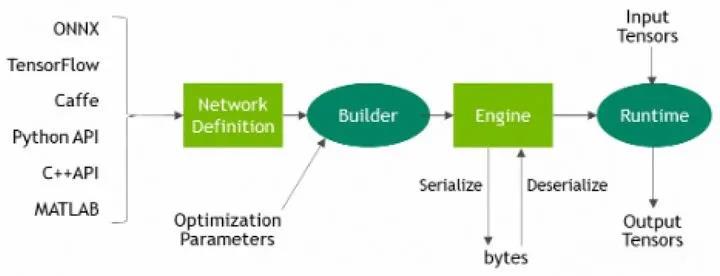
3、model解析成功后,我们需要考虑优化选项——batch size、工作空间大小、混合精度和动态形状的边界,这些选项被选择并指定为TensorRT构建步骤的一部分,在此步骤中,您将基于网络构建一个优化的推理引擎。
4、使用TensorRT创建inference engine后,我们需要验证它是否可以复现原始模型的性能评估结果。如果我们选择了FP32或FP16,那么它与原始结果非常接近。如果选择了INT8,那么它与原始的结果会有一些差距。
5、一序列化格式保存inference engine-----called plan file
阶段3:Deploying A Solution 该TensorRT库将被链接到部署应用程序,当应用程序需要一个推理结果时将会调用该库。为了初始化inference engine,应用程序首先会从plan file中反序列化为一个inference engine。另一方面,TensorRT通常是异步使用的,因此,当输入数据到达时,程序调用带有输入缓冲区和TensorRT放置结果的缓冲区的enqueue函数。
三、TensorRT是如何工作的? 为了优化模型的inference,TensorRT会根据网络的定义执行优化【包括特定平台的优化】并生成inference engine。此过程被称为构建阶段,尤其是在嵌入式平台上会消耗大量的时间,因此,一个典型的应用程序只会被构建一次engine,然后将其序列化为plane file以供后续使用。【注意:生成的plane file 不能跨平台或TensorRT 版本移植。另外,因为plane file是明确指定GPU 的model,所以我们要想使用不同的GPU来运行plane file必须得重新指定GPU】
构建阶段在layer graph上执行以下优化:
- 消除没有使用的outputs layer
- 消除等同于没有操作的operation
- convolution,bias and ReLU的融合
把具有足够相似的parameters和相同的source tensor的operation进行aggregation【例如1x1的convolution】 通过将输出层定向到正确的最终目的来合并concatenate layer
四、TensorRT提供了哪些功能? 资料链接: https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html
- End -
技术发展的日新月异,阿木实验室将紧跟技术的脚步,不断把机器人行业最新的技术和硬件推荐给大家。看到经过我们培训的学员在技术上突飞猛进,是我们培训最大的价值。如果你在机器人行业,就请关注我们的公众号,我们将持续发布机器人行业最有价值的信息和技术。 阿木实验室致力于前沿IT科技的教育和智能装备,让机器人研发更高效!
以上是关于技术分享 | 浅谈TensorRT的主要内容,如果未能解决你的问题,请参考以下文章