NLP作业三:用BiLSTM+CRF实现中文命名实体识别(TensorFlow入门)代码+报告
Posted vector<>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP作业三:用BiLSTM+CRF实现中文命名实体识别(TensorFlow入门)代码+报告相关的知识,希望对你有一定的参考价值。
这里是国科大自然语言处理的第三次作业,同样也是从小白的视角解读程序和代码,现在我们开始吧(今天也是花里胡哨的一天呢🤩)

1.程序与实验说明
实验要求
使用任意一种深度学习框架(推荐pytorch),利用目录 data 中的数据训练模型来完成序列标注任务(命名实体识别),识别出文本中的人名、地名和组织机构名。
数据集说明:来自于98年人民日报NER语料
评价指标:采用准确率、召回率以及F1值来进行模型评价。
程序说明
代码链接
https://download.csdn.net/download/qq_39328436/51914074
代码结构
- data_path:6个文本文件均为老师提供,读者也可以在网上下载完整的MSRA语料库。最终送入模型的是处理好的test_data和train_data。
- data_patch_save:存储的是训练好的模型,图片中展示的1638113385 是我已经训练好的模型
- venv:是我电脑上pycharm自动生成的与编译环境有关的文件夹,可以删除
- conlleval_rev.pl:是用于计算准确率的perl工具
- utils.py:与demo实现相关(其他py文件会在下文中提到)
运行步骤
🧡一些重要的说明🧡:
之前的两次nlp实验均采用的是pytorch框架,虽然这一次老师建议的也是使用pytorch,但是最后还是选择了TensorFlow,主要原因是CRF在TensorFlow中只需要一个函数就能实现,相对于pytorch更加简洁,其次是基于TensorFlow的序列标注有更多的参考博客,更加适合于新手学习。
在运行代码过程中可能会碰到的问题(例如:报错,perl不是内部命令)可以参考本篇博客的最后一个部分,或许会有帮助。
在pycharm终端依次执行:
python main.py --mode=train # 开始训练,训练好的模型会保存在项目文件夹中
python main.py --mode=test --demo_model=1638113385 # 训练好之后开始测试,1638113385是已经训练好的一个模型,可以替换成自己的
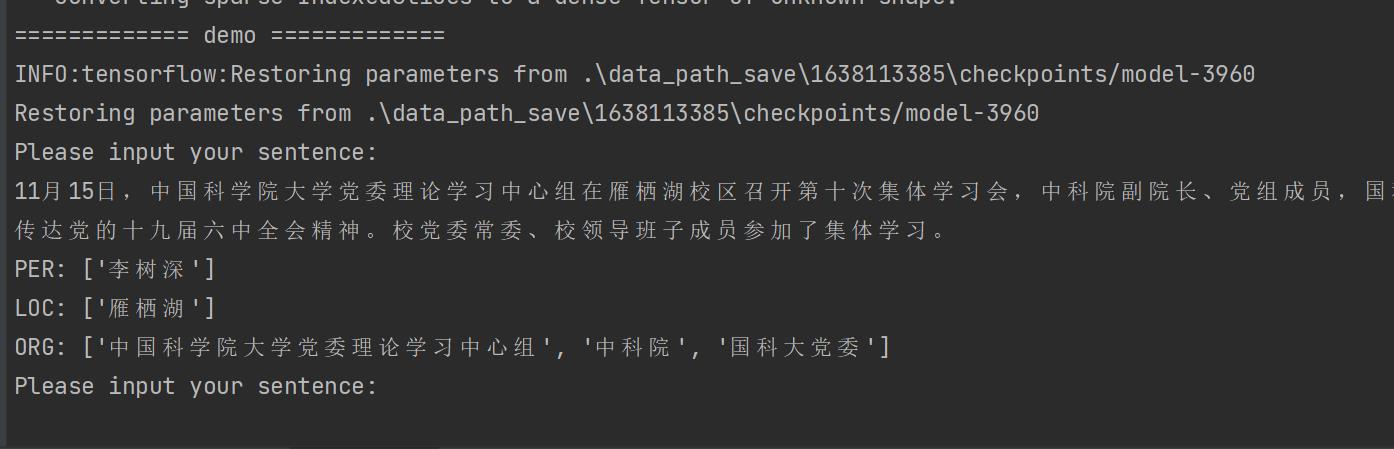
python main.py --mode=demo --demo_model=1638113385
并根据提示在控制台任意输入一句话,便可评估出这句话中的人名等
2.基础知识概述
序列标注问题
在自然语言处理任务中,有许多的任务可以转换为“将输入的语言序列转化为标注序列”来解决问题。如:命名实体识别、信息抽取、词性标注。本次实 验要完成的就是命名实体识别,简而言之就是将输入序列中的人名,机构名以及地名标注出来。解决序列标注问题有很多方法,比如说马尔科夫模型(HMM)和隐马尔可夫模型,本次实验采用的是神经网络的方法。下图是神经网络序列标注模型的架构图
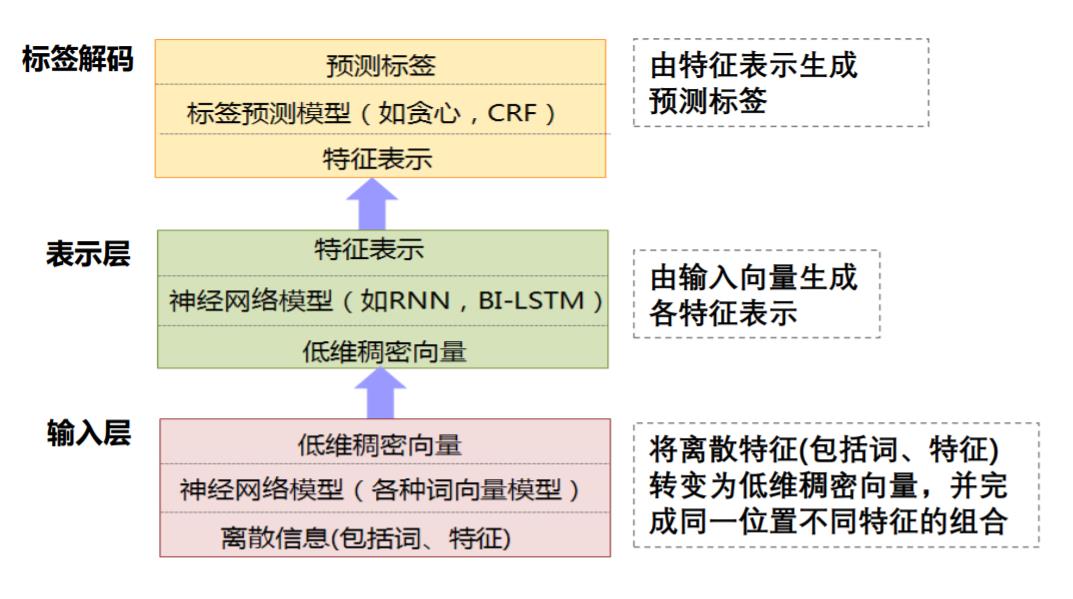
- 输入层:将离散特征转化为低纬稠密向量
- 表示层:由输入向量生成各种特征表示,本次实验选取的神经网络模型是Bi-LSTM
- 标签阶码:有特征表示生成标签预测,本次实验选取的标签预测模型是 CRF
CRF
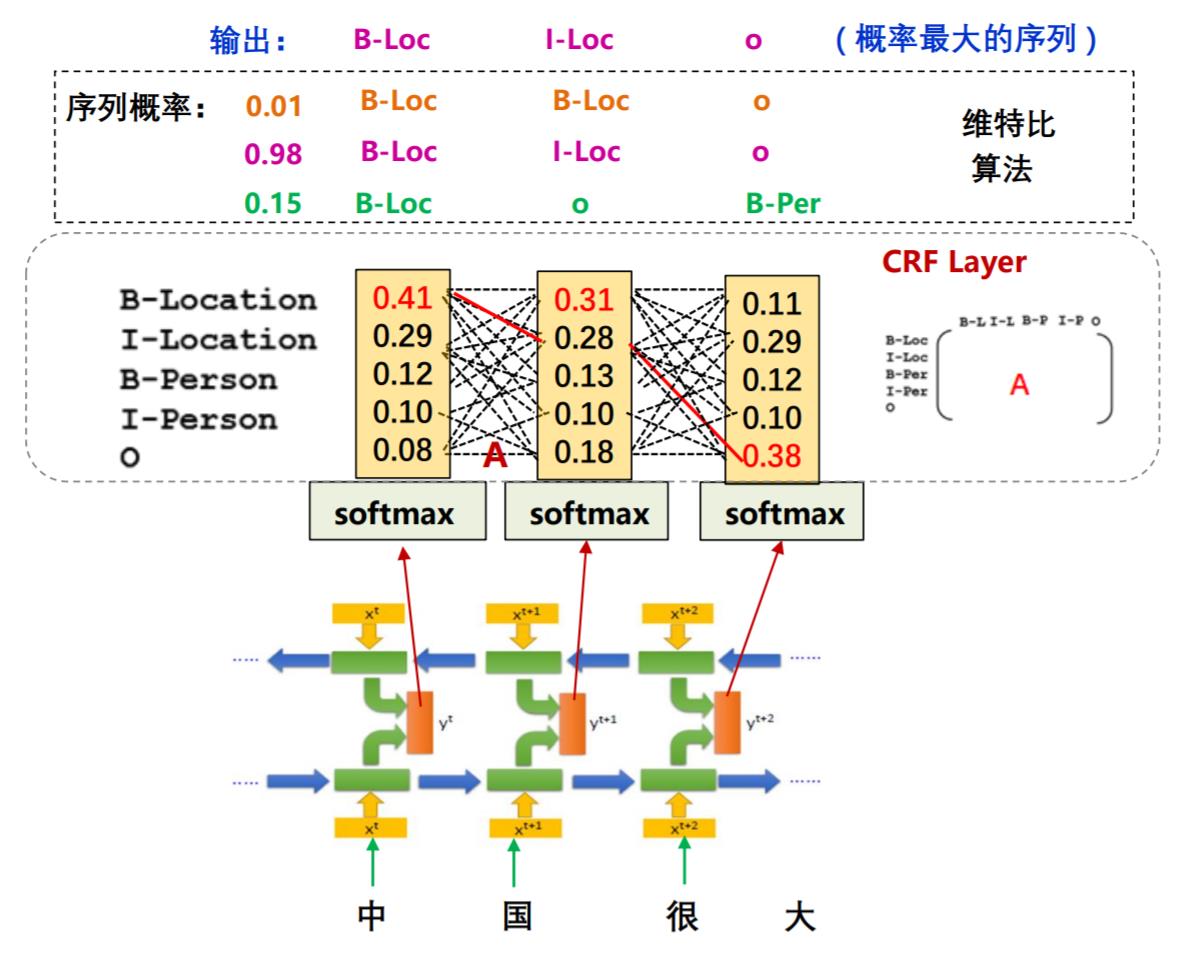
CRF是条件随机场,在网上很多关于它的公式详解,所以这一小节只讲一个问题:在序列标注问题中,Bi-LSTM+softmax的模型存在什么问题?为什么需要在这个问题中引入条件随机场?
如果不使用条件随机场,经过softmax之后,会挑选一个概率最大的标签输出,第一列最大的是0.14,那么对应“中”的标签就应该是B-Location(B代表Begin),代表地名的开始;第二列概率中最大的是0.31,其对应的标签仍然为B-Location,很显然,两个挨着的字是不可能都为地名的开始,**那么要如何解决问题这个问题呢?**这就是条件随机场的工作了
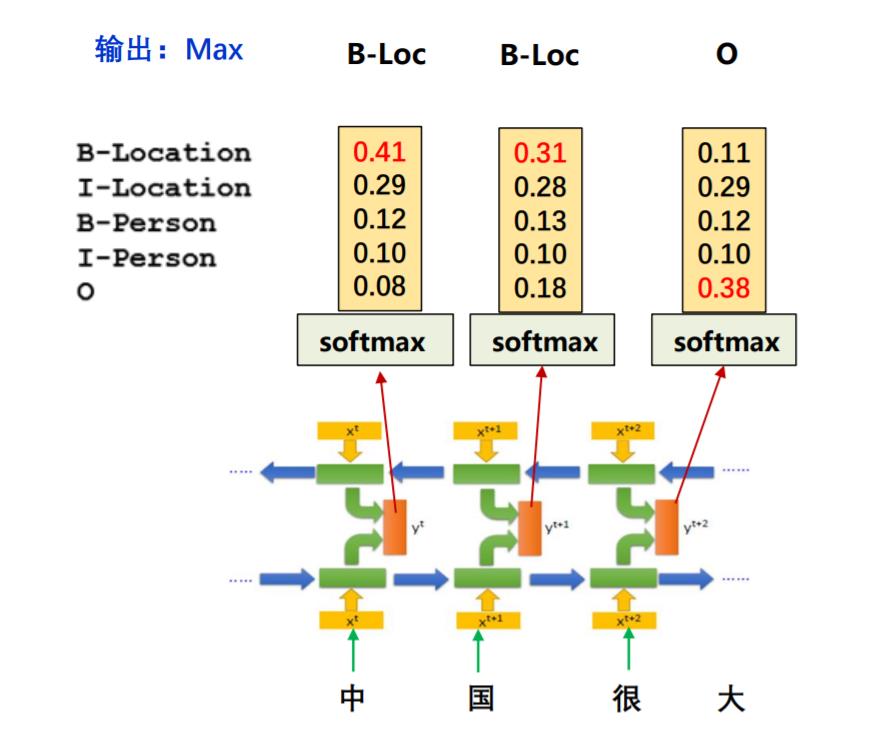
之所以会出现连续的两个B,是因为输出之间没有限制条件,应该告诉模型,如果前一个字是Begin,后一个字的标签就不能是Begin。那么 CRF是如何完成这样的限制的呢? 它是通过一个转移矩阵规定输出序列的概率做到的。
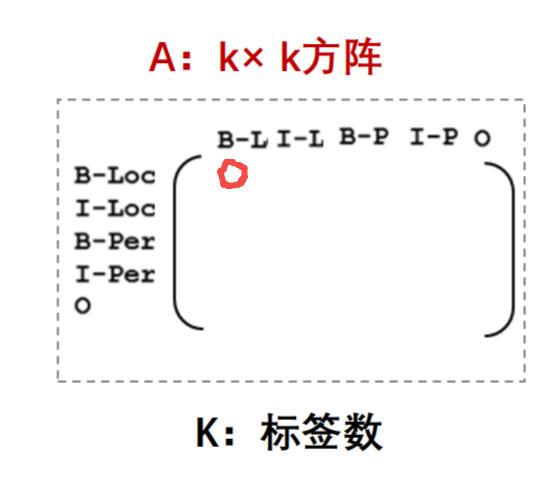
在这个矩阵中,第一行第一列代表前一个字是B-Location,后一个字是B-Location的概率,根据上文的描述,这个概率应该非常小,甚至是0。那么加入了CRF之后的模型结构就应该是下图所示:
3.数据预处理
train_corpus.txt

train_lable.txt
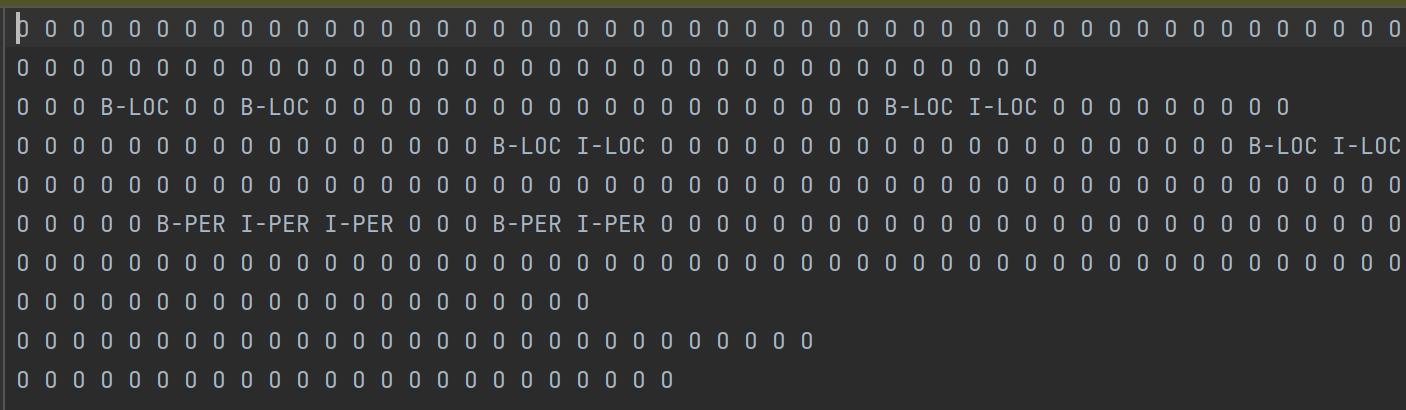
上面两个文件分别表示原始语料以及其对应的标签
便签说明: B-PER:人名开始; I-PER:人名中间 ;B-LOC:地名开始, I-LOC:地名中间; B-ORG:机构名开始 ;I-ORG:机构名中间;O:其他 如周恩来这个人名实体对应的标签B-PER, I-PER, I-PER
需要将数据处理成下面这样的格式再输入到模型中,左侧为字符,右侧为标签。
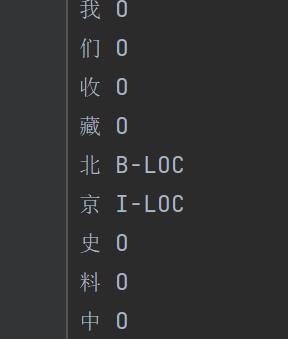
本次实验老师提供了处理好的两个txt(感谢如此仁慈可爱的老师🧡),如果读者的原始数据比较奇怪,应该想办法处理成这个样子。
4.模型结构
模型结构如下图所示,输入层最主要的是look-up层处理得到词嵌入;中间神经网络层是一个双向LSTM,输出时经过一个softmax;最后在转移矩阵A的限制下,通过CRF层得到预测标签
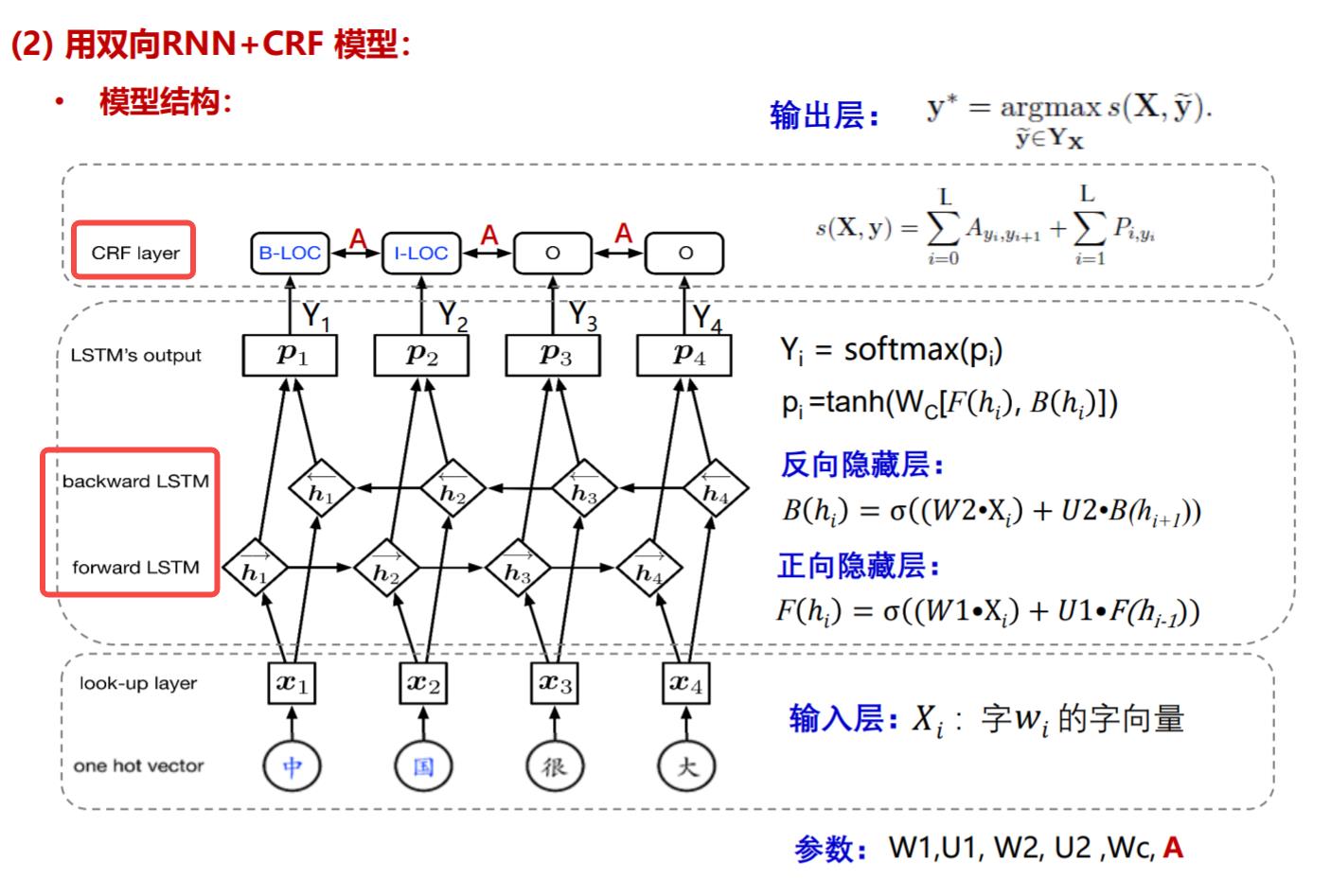
🧡一些重要的说明🧡:
源码实在是太长了,csdn上有厉害的大佬逐行解释了大部分的代码,推荐:https://blog.csdn.net/qq_41076797/article/details/99569285
本篇博文后续的篇章主要以模块的角度讲解,争取做到能够让像我这样的TensorFlow小白迅速get重重点。
5.训练
if args.mode == 'train':
# 创建模型
model = 🧡BiLSTM_CRF(args, embeddings, tag2label, word2id, paths, config=config)
# 创建节点,无返回值
🧡model.build_graph()
print("train data: ".format(len(train_data)))
# 开始训练
🧡model.train(train=train_data, dev=test_data)
-
BiLSTM_CRF创建模型
- batch_size=64
- epoch=5 源码中默认为40,考虑到训练时间,所以改成了5
- hidden_dim=300 隐藏状态的大小; 每个LSTM单元在每个时间步产生的输出数
- optimizer=Adam
- lr=0.001
-
build_graph() 创建节点
- build_graph() 中的函数依次进行初始化占位符,处理输入词嵌入,设置BiLSTM层,计算损失以及梯度,设置优化器等操作。
- 重点要提的是在loss_op()中有一个函数crf_log_likelihood(),返回值为log_likelihood以及transition_params,这里的transition_params函数就是CRF的转移矩阵。这个转移矩阵会作为sess.run的一个参数来计算logits
def build_graph(self):
self.add_placeholders() # 初始化占位符
self.lookup_layer_op() # 处理输入的词嵌入,是上文模型结构中的输入层
self.biLSTM_layer_op() # 设定BiLSTM层
self.softmax_pred_op() # 本次实验不调用
self.loss_op() # 计算损失
self.trainstep_op() # 训练操作,设置优化器,计算梯度等
self.init_op() # 初始化训练参数
- model.train 开始训练,下图是trian函数的主要的调用链(省略了其他细节)。
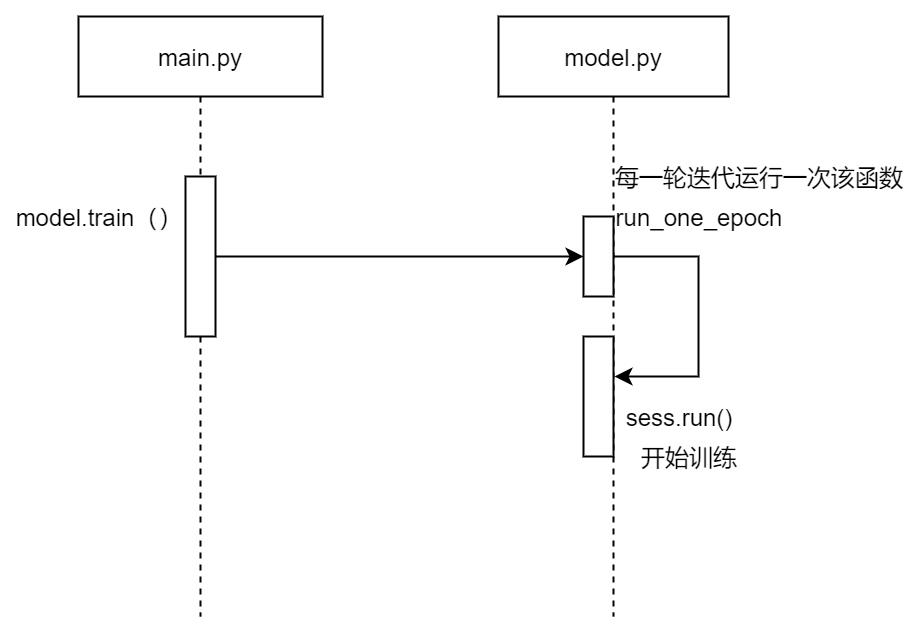
需要注意的是,本程序每训练完一个epoch时,会生成测试数据进行测试,并输出准确率。所以run_one_epoch函数中不仅有run,同时也有evaluate。

训练好的模型会被保存在…/data_path_save中
6.测试
elif args.mode == 'test':
# 加载模型
ckpt_file = tf.train.latest_checkpoint(model_path)
print(ckpt_file)
paths['model_path'] = ckpt_file
# 初始化模型
model = BiLSTM_CRF(args, embeddings, tag2label, word2id, paths, config=config)
model.build_graph()
print("test data: ".format(test_size))
#开始测试
🧡model.test(test_data)
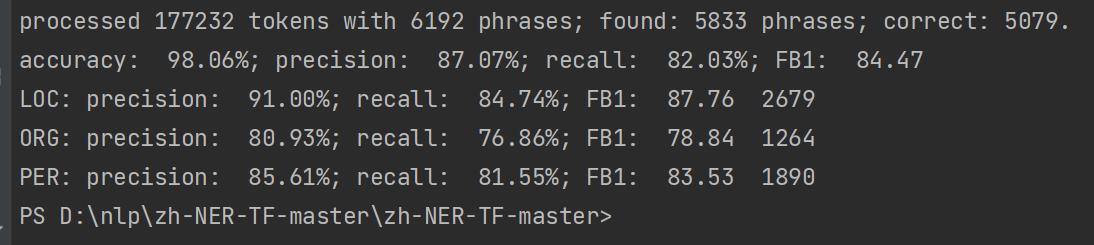
- 精度描述(测试结果会输出四个评价指标)
- accuracy准确率= 正确预测的正反例数 / 总数
- precision精确率=在被判断为真的样例中,实际为真的样例比例
- recall召回率=在实际为真的样例中,被判断为真的样例比例
- F1平衡F分数=精确率和召回率的调和平均数
测试思路比较简单,加载好训练的模型送入 model.test()函数中进行测试,下图是test()主要的调用过程:

比较特殊的是,并没有直接用python代码来计算准确率,而是利用一个基于perl(一种编程语言)的工具conlleval_rev.pl。在eval.py中执行下面这句代码就能调用conlleval_rev.pl工具。
os.system("perl < > ".format(eval_perl, label_path, metric_path))
conlleval_rev.pl存在项目文件夹中,有兴趣的同学可以研究一下源码,笔者实在是能力有限,无法对它做太多解读。此外, conlleval_rev工具在github上有基于python实现的版本,如果读者不想在电脑上安装perl工具可以下载来尝试一下。
下图是经过conlleval_rev.pl工具对测试数据进行处理之后的结果:
疑问与思考
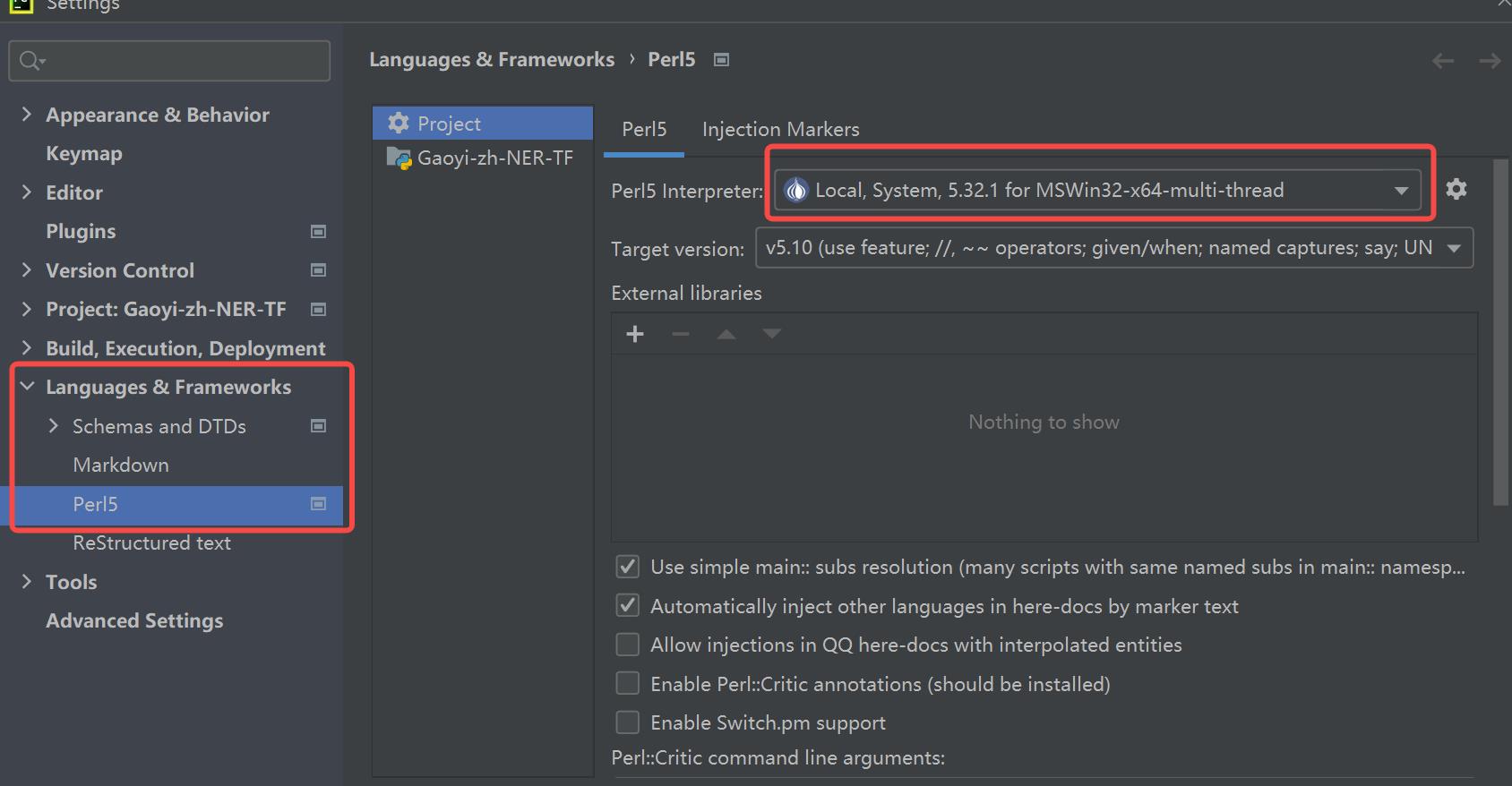
💜在pycharm中如何配置perl?
在网上查到的方法都是在pycharm中下载plugins即可,但是我安装好之后并没有用,所以找了另外的笨办法。安装好strawberry,并配置好环境变量D:\\Strawberry\\perl\\bin,在pycharm的setting中进行如下配置:(add system per)。
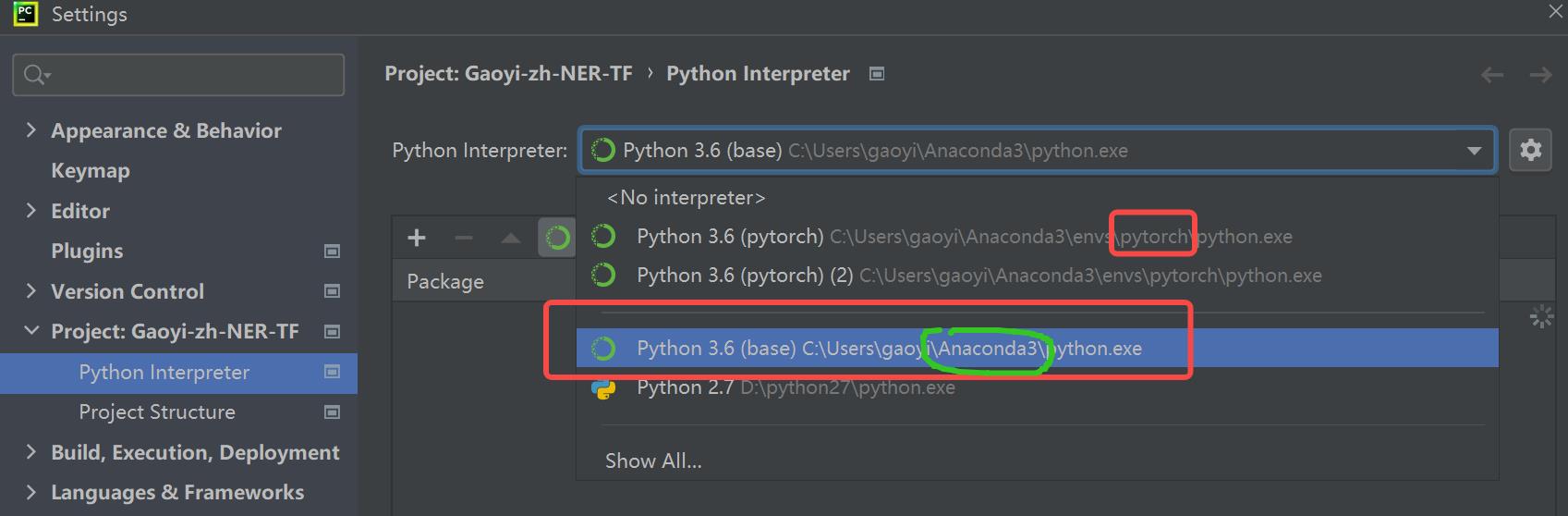
🖤已经安装了pytorch后如何安装TensorFlow?
在setting中另起一个interpreter,选择Anaconda文件夹下的python.exe,然后用pip在清华镜像安装TensorFlow即可。
🧡tensorflow中的sess.run
函数:run(fetches, feed_dict=None, options=None, run_metadata=None)当构建完图后,需要在一个session会话中启动图,第一步是创建一个Session对象。为了取回(Fetch)操作的输出内容, 可以在使用 Session 对象的 run()调用执行图时,传入一些 tensor, 这些 tensor 会帮助你取回结果。
feed_dict参数的作用是替换图中的某个tensor的值或设置graph的输入值
(1)TensorFlow与我们正常的编程思维略有不同:TensorFlow中的语句不会立即执行;而是等到开启会话session的时候,才会执行session.run()中的语句。如果run中涉及到其他的节点,也会执行到。
(2)Tesorflow模型中的所有的节点都是可以视为运算操作op或tensor
💛tensorflow中的Logits
参考:https://blog.csdn.net/a2806005024/article/details/84113190
以1000分类为例,Logits就是最后一层输出后,进入到Softmax函数之前得到的1000维向量。
以AlexNet为例进行解释,FC8层(最后一层)的输出就是Logits(1000维)。而常用的Feature确是4096维从FC6/FC7(倒数第二层)中提取。
为什么不用1000D的Logits作为Feature?一个直观理解是——这个Logits实在太“高级”太“抽象”。Logits由于离softmax太近,它的特性高度适应1000分类任务而无法用于其他任务,失去了对普遍性的视觉特性的描述,因而不能用于其他任务。更理性的分析可以从Softmax的输入/输出关系看出,Softmax仅仅是对Logits做了一个归一化。
💙tensorflow中的Placeholders
参考:https://blog.csdn.net/ltrbless/article/details/104580619
Placeholders是占位符,其实是一个比较特殊的变量,但是它只是暂时占着位置,一般在最后运行的时候才赋值。在tensorflow中通过占位符把数据输入到之前构造的计算图中。
🧡Dropout的作用
参考:https://blog.csdn.net/program_developer/article/details/80737724
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。

完结撒花✨
其实还有很多细节没有搞清楚写明白,希望大家批评指正~
以上是关于NLP作业三:用BiLSTM+CRF实现中文命名实体识别(TensorFlow入门)代码+报告的主要内容,如果未能解决你的问题,请参考以下文章