Fintech建模竞赛:现金贷用户数据分析和画像
Posted Debroon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Fintech建模竞赛:现金贷用户数据分析和画像相关的知识,希望对你有一定的参考价值。
风控历史
世界上最早的银行是,1407年在意大利威尼斯成立。
只要有银行,就会有风险控制和管理,即风控。
早期风控包括对借贷人资质审核和账户核实。
随着金融业发展,贷款流程逐渐完善:

2000-2008年后,全球逐步进入大数据时代,随着用户数据整合,诞生央行征信,公安人脸数据,芝麻信用分,同盾分,聚信立蜜罐分,百度黑中介分等参考数据。
银行、消费金融公司、小额贷公司可以利用大数据建模,利用机器智能决策代替绝大部分人工审核,缩短信贷流程,减少贷款风险,实现利润最大化。
- 用户申请 -> 用户授权 -> 黑名单过滤 -> 查征信 -> 风控强规则过滤 -> 风控模型智能决策
现代的风控部门主要分为贷前、贷中和贷后管理。
分控核心岗位:
- 模型开发
- 数据分析
本文是数据分析。以后也会更新模型开发方面的内容。
采用金融科技公司 lending club 的12万真实数据,从客户年龄、收入、工作、住房、信用额度等多个维度完成用户画像。
本文特色,除了数据分析之外,最后也添加了个人和企业风险管理的内容。
好,我们开始吧。
- 借贷俱乐部:https://www.lendingclub.com/

lending club 是 P2P 鼻祖,我们的数据就来源于这里。
P.S. 图上红色框中的翻译不对,应该是检测您的信用。
数据分析
备用数据下载地址:https://download.csdn.net/download/qq_41739364/21417988
描述性统计
拿到数据后,先做一个观察,分布是怎样的、是否有异常、缺失率高不高、知己知彼。
我们对数据做一个描述性统计,用几个关键的数字(数据量、维度、缺失率、平均数、中位数等)来描述数据集的整体情况。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data=pd.read_excel('data.xlsx') # 读取数据
numbers=data.shape[0] # 数据总量
print( data.describe() ) # 描述性统计:观察数据的范围、大小、波动趋势等等,为后面的模型选择打下基础。
missing_pct = data.apply(lambda x : (len(x)-x.count())/len(x)) # 统计各个变量缺失率
missing_pct.plot(kind='bar',fontsize=10, rot=0) # 图表可视化各个变量缺失情况
# 对所有变量画一个直方图,看看分布
data.hist(figsize=(20,15))
plt.show()
描述性统计结果:



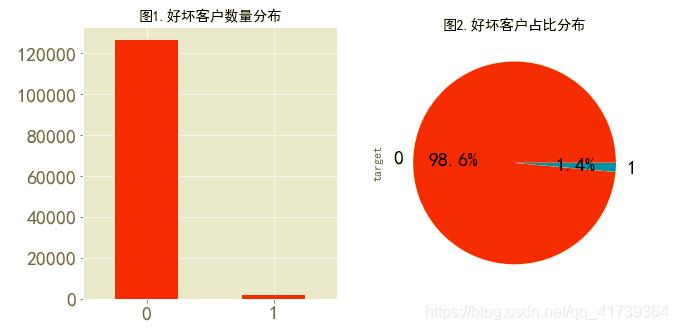
好坏客户占比情况
业务分析,建模之前需要观察是否存在好坏客户占比严重失衡的问题。
如果好坏客户比例偏差大,那训练出来的模型偏差也大。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data=pd.read_excel('data.xlsx') # 读取数据
numbers=data.shape[0] # 数据总量,numbers = 128412
print( data.describe() ) # 描述性统计:观察数据的范围、大小、波动趋势等等,为后面的模型选择打下基础。
missing_pct = data.apply(lambda x : (len(x)-x.count())/len(x)) # 统计各个变量缺失率
missing_pct.plot(kind='bar',fontsize=10, rot=0) # 图表可视化各个变量缺失情况
# 对所有变量画一个直方图,看看分布
data.hist(figsize=(20,15))
plt.show()
# 好坏客户占比情况
n_bad=data[data.target==1].shape[0] # 坏客户数量(target字段0和1组成)
n_good=data[data.target==0].shape[0] # 好客户数量(target字段0和1组成)
percentage_bad=round((n_bad/numbers)*100,2) # 好坏客户占比,小数取俩位
value_count=data['target'].value_counts() # 对好坏客户做一个计数统计
# 图表可视化
plt.style.use('ggplot')
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
value_count.plot(kind='bar',fontsize=20,rot=0,title='图1.好坏客户数量分布') # 中文可能不会显示,要额外设置一下
ax=plt.subplot(1,2,2)
value_count.plot(kind = "pie", autopct = "%0.1f%%", title= "图2.好坏客户占比分布", fontsize=20)
好客户:126584
坏客户:1828
若中文不能显示,添加:
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
变量相关性分析
相关性判断有俩种方法:皮尔森、斯皮尔曼。
当数据呈现正态分布时,用皮尔森方法更准确。
但很多数据不呈现正态分布,这时斯皮尔曼更合适。
所以,我们再测量相关性时,需要看数据分布,是否是正态分布或者俩种方法都跑一遍。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data=pd.read_excel('data.xlsx') # 读取数据
numbers=data.shape[0] # 数据总量
print( data.describe() ) # 描述性统计:观察数据的范围、大小、波动趋势等等,为后面的模型选择打下基础。
missing_pct = data.apply(lambda x : (len(x)-x.count())/len(x)) # 统计各个变量缺失率
missing_pct.plot(kind='bar',fontsize=10, rot=0) # 图表可视化各个变量缺失情况
# 对所有变量画一个直方图,看看分布
data.hist(figsize=(20,15))
plt.show()
n_bad=data[data.target==1].shape[0] # 坏客户数量(target字段0和1组成),1828人
n_good=data[data.target==0].shape[0] # 好客户数量(target字段0和1组成),126584人
percentage_bad=round((n_bad/numbers)*100,2) # 好坏客户占比,小数取俩位,1.42
value_count=data['target'].value_counts() # 对好坏客户做一个计数统计
# 图表可视化
plt.style.use('ggplot')
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
value_count.plot(kind='bar',fontsize=20,rot=0,title='图1.好坏客户数量分布')
ax=plt.subplot(1,2,2)
value_count.plot(kind = "pie", autopct = "%0.1f%%", title= "图2.好坏客户占比分布", fontsize=20)
matrix_cor=data.corr().round(2) # 相关性矩阵,展现各变量之间的相关程度,保留俩位小数
# 可视化:把相关性矩阵绘制成热力图
plt.figure(figsize=(12, 12))
sns.heatmap(matrix_cor, annot=True, linewidths = 0.05, annot_kws='size':10,'weight':'bold')
# annot是注解,annot_kws,当annot为True时,可设置各个参数,包括大小,颜色,加粗,斜体字等,linewidths热力图矩阵之间的间隔大小
# 封装一个相关性函数
def Relation(df1, method, fileName): # fileName 数据保存的文件
cor=df1.corr(method) # 生成变量的相关性矩阵
cor.to_excel("correlation_table.xlsx") # 把相关性矩阵存到 correlation_table.xlsx (相关性表)
cor.loc[:,:]=np.tril(cor,k=-1) # 对结构改变和优化
cor=cor.stack()
high_cor=cor[(cor>0.6)|(cor<-0.6)] # 挑选高相关系数,正相关0.6以上、负相关0.6以下
df_high_cor=pd.DataFrame(high_cor) # 数据呈现结构化
df_high_cor.to_excel(fileName) # 保存到(高相关性表)文件
return df_high_cor # 返回高相关性的矩阵
# 皮尔斯方法
cor_pearson=Relation(data,'pearson',"high_correlation_pearson.xlsx")
print(cor_pearson)
# 斯皮尔曼方法
cor_spearman=Relation(data,'spearman',"high_correlation_spearman.xlsx")
print(cor_spearman)
相关性矩阵变成热力图:
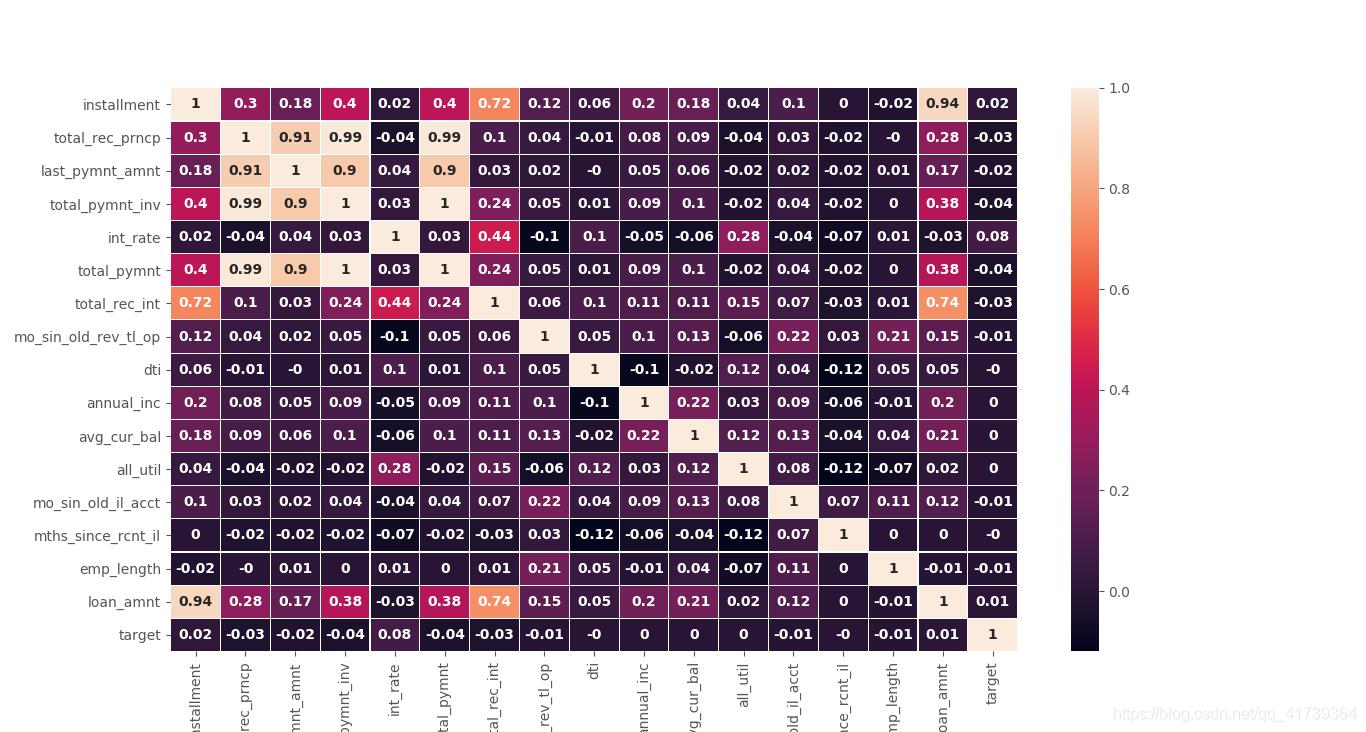
皮尔斯方法:

斯皮尔曼方法:
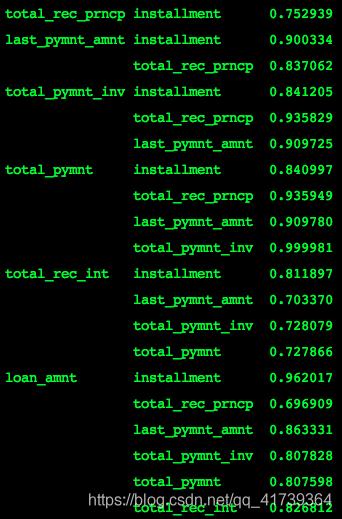
这是什么意思呢?
如斯皮尔曼方法的最后一栏第一个意思是,loan_amnt贷款总金额和installment分期付款的相关性是0.96。
贷款金额和趋势分析
贷款金额有几个重要的指标:
- installment 单笔分期金额
- loan_amnt贷款总额
loan_amnt贷款总额(估算)= installment 单笔分期金额 * 贷款期数 term。
# 分期付款金额情况,我们使用直方图可视化
data['installment'].hist()
plt.show()
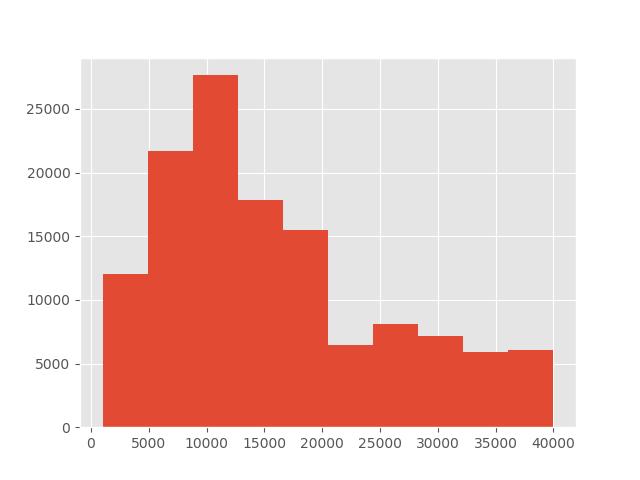
# 贷款总额情况,我们使用直方图可视化
data['loan_amnt'].hist()
plt.show()
我们也可以用Seaborn来画。
from scipy.stats import norm
sns.distplot(data.loan_amnt,kde=True,color='blue',fit=norm) # distplot核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一
sns.despine(top=True)
除了直方图,还有核密度函数、高斯分布函数。
······
通过图表分析,发现单笔分期金额在 300美元 范围内占比较多,较高金额的贷款数量较少,也间接证明了 lending club 主营小额度的贷款项目。
单笔贷款金额在 1万~2万 美元范围内占比较多,较高金额的贷款数量较少,也间接证明了lending club 主营小额度的贷款项目。
我们看一下,2018年4季度贷款笔数和贷款金额统计。
# groupby+agg 可以对groupby的结果(2018年、总金额)同时应用多个函数(计数、求和函数)
perform_data = data.groupby('issue_d')['loan_amnt'].agg(['count','sum'])
接下来,绘图。
# 绘图
f, (ax1, ax2) = plt.subplots(2, 1, sharex=True)
# DatetimeIndex(['2018-10-01', '2018-11-01', '2018-12-01'], dtype='datetime64[ns]', name='issue_d', freq=None
x = perform_data.index # 月份month
y1 = perform_data['count'] # 贷款笔数
sns.barplot(x, y1, ax=ax1)
y2 = perform_data['sum'] # 贷款金额
ax1.set_xlabel("")
ax1.set_ylabel("放款笔数")
sns.barplot(x, y2,ax=ax2)
ax2.set_ylabel("放款金额")
# 下边线隐藏
sns.despine(bottom=True)

从结果看,贷款笔数与放贷金额,都在减少,lendingclub在2018年4季度略有下滑趋势 — 业务上,年底坏账增多,放款缩紧,可以理解。
产品周期分析
贷款周期分行业看:房地产,车贷固定资产投资周期性较强。一个周期一般是一个月,借贷人也不会不还钱,因为会把房子给扣押。
贷款周期分为 36 个月与 60 个月,主要以 36 个月为主,不过 60 个月的比重也不小。
在 p2p 平台上以短期贷款为主,长期贷款也有,利率较高,但周期较长。借出人收获利息,承担风险,而借入人到期要偿还本金。贷款周期越长,对借出人来说风险越高。
在国内的环境下,借出人不仅要承担推迟还款的风险,还要担心平台跑路、本息全无的高风险;对借入人来说,因为国内缺少健全的征信体系,借款方违约及重复违约成本低。
国外的部分国家已有健全的征信体系,一旦违约还款,违约率不断上涨,个人征信也会保留记录,对后序的贷款、买房有很大的影响。
所以如果贷款周期较长,且如果没有固定的工作和固定的收入的话(即使有未定收入也不一定如期偿还),偿还本金充满变数,很有可能违约。
- 贷款期数 term
term_counts=data.term.value_counts()
term_counts.plot.pie(autopct='%.2f',figsize=(10, 10),fontsize=20,colors = ['green','lightblue'])
data.term.value_counts().plot.pie(autopct='%.2f',figsize=(10, 10),fontsize=20,colors = ['green','lightblue'])
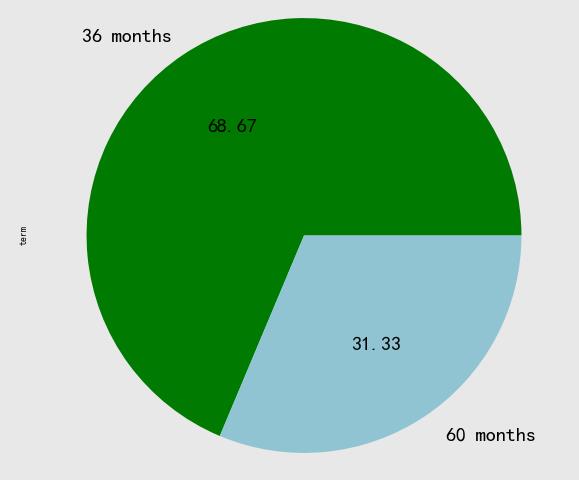
总结:小额贷 + 短周期为主
所以通过上图可以看出几个信息:
-
短期贷款(36个月)占比重较大,长期贷款(60个月)占比也不低
-
鸡蛋不放在一个篮子里,小额贷分散风险,贷款周期长,违约率高,风险大,贷款周期短,风险相对小
用户工龄分析
不同场景平台用户工龄分布差异大,医美主要为16-30岁群体,lendingclub针对工作时长高群体,这样收入会稳定一些。
data.emp_length.value_counts().plot.pie(autopct='%.2f',figsize=(10,10),fontsize=20)
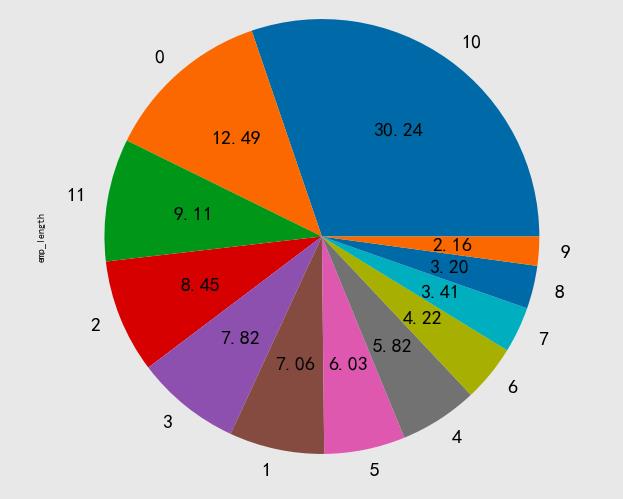
data.emp_length.value_counts().plot(kind='bar',fontsize=20,rot=0,title='用户工龄柱状图')

value_count=data["emp_length"].value_counts()
plt.style.use('ggplot')
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
value_count.plot(kind='bar',fontsize=20,rot=0,title='用户工龄数量分布')
ax=plt.subplot(1,2,2)
value_count.plot(kind='pie',fontsize=20,rot=0,title='用户工龄占比分布')
plt.show()

住房情况与贷款等级
美国有房产税,对抑制炒房有很好作用,中国房产税雨声小,雷声大,炒房非常严重。
data.home_ownership.value_counts().plot.pie(autopct='%.2f', figsize=(10, 10),fontsize=20)
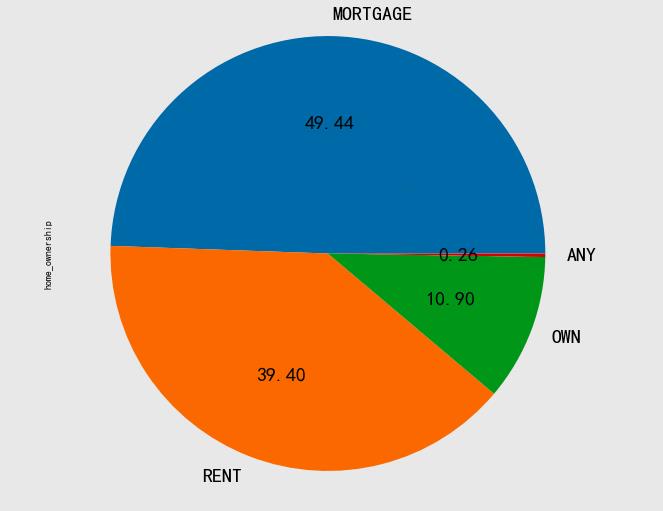
-
MORTGAME:按揭贷款
-
RENT:租房
-
OWN:自由租房
-
ANY:其他
analysis_data_home = data.groupby(['grade','home_ownership'])[['issue_d']].count().apply(lambda x:x/x.sum(level=0))
# 对需要分析的俩个字段进行分类
print(analysis_data_home)

这是堆的数据结构。
常见的数据格式化结构有俩种:
- 堆叠
- 表格

在用 pandas 进行数据重排时,经常用到 stack 和 unstack 两个函数。
stack 的意思是 “堆叠”,堆积,unstack 即 “不要堆叠”。
- stack( ):把表格数据转化为堆叠数据
- unstack( ):把堆叠数据转化为表格数据
analysis_data_home1=analysis_data_home.unstack(level=1) # 以第二列(从0开始数)的名字变成表格里面行的名称
analysis_data_home2=analysis_data_home1.stack(level=0)
analysis_data_home3=analysis_data_home2.reset_index(level=1,drop=True)
# (横向)树状图可视化
analysis_data_home3.plot.barh(figsize=(15,8)).legend(loc='center left',bbox_to_anchor=(1,0.5))
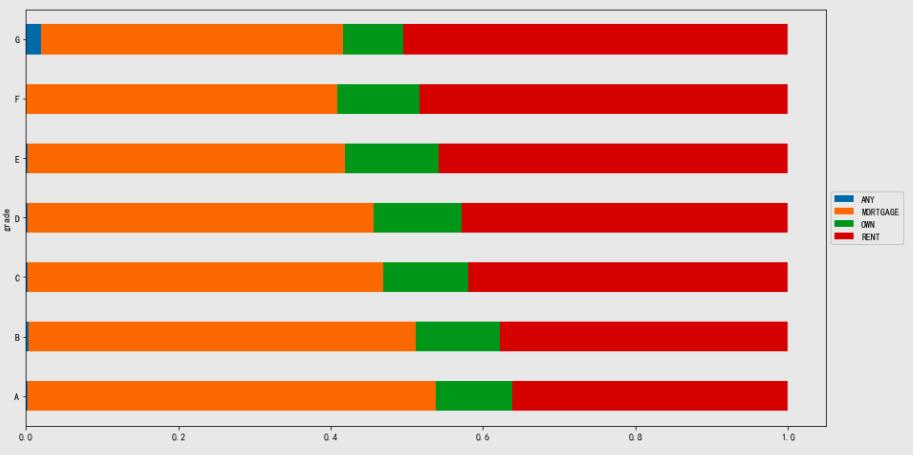
意外的发现,贷款等级越高的人群,他们的住房情况是抵押贷款的几率越高,而租房的几率越低。
而拥有完全产权的人群在各个贷款等级的人群中占比差不多。
贷款人年收入分析
income_count=data['annual_inc'].value_counts()
print(income_count) # 查看各个贷款人年收入情况
# 方法一
data['annual_inc']=np.where(data['annual_inc']<=50000,'0-50000',data['annual_inc'])
print(data['annual_inc'])
# 方法二
data = pd.read_excel('data.xlsx')
bins = [0,50000,60000,70000,80000,90000,100000,110000,120000,130000,140000,150000,160000,170000,180000,190000,200000,300000]
data['annual_inc']=pd.cut(data['annual_inc'],bins)
income_counts=data.annual_inc.value_counts()
plt.figure(figsize=(15,15))
income_counts.plot(kind='bar',fontsize=10,rot=0,title="收入数量分布")

income_counts.plot.pie(autopct='%.2f',figsize=(10,10),fontsize=20)

80% 的财富掌握在 20% 的人手里。
贷款人收入水平
之前我们分析的是单因子,我们可以多因子组合分析,以收入水平和贷款等级为例。
数据如下:

- annual_inc&#x
以上是关于Fintech建模竞赛:现金贷用户数据分析和画像的主要内容,如果未能解决你的问题,请参考以下文章