重学Springboot系列之整合数据库开发框架---下
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重学Springboot系列之整合数据库开发框架---下相关的知识,希望对你有一定的参考价值。
重学Springboot系列之整合数据库开发框架---下
mybatis+atomikos实现分布式事务
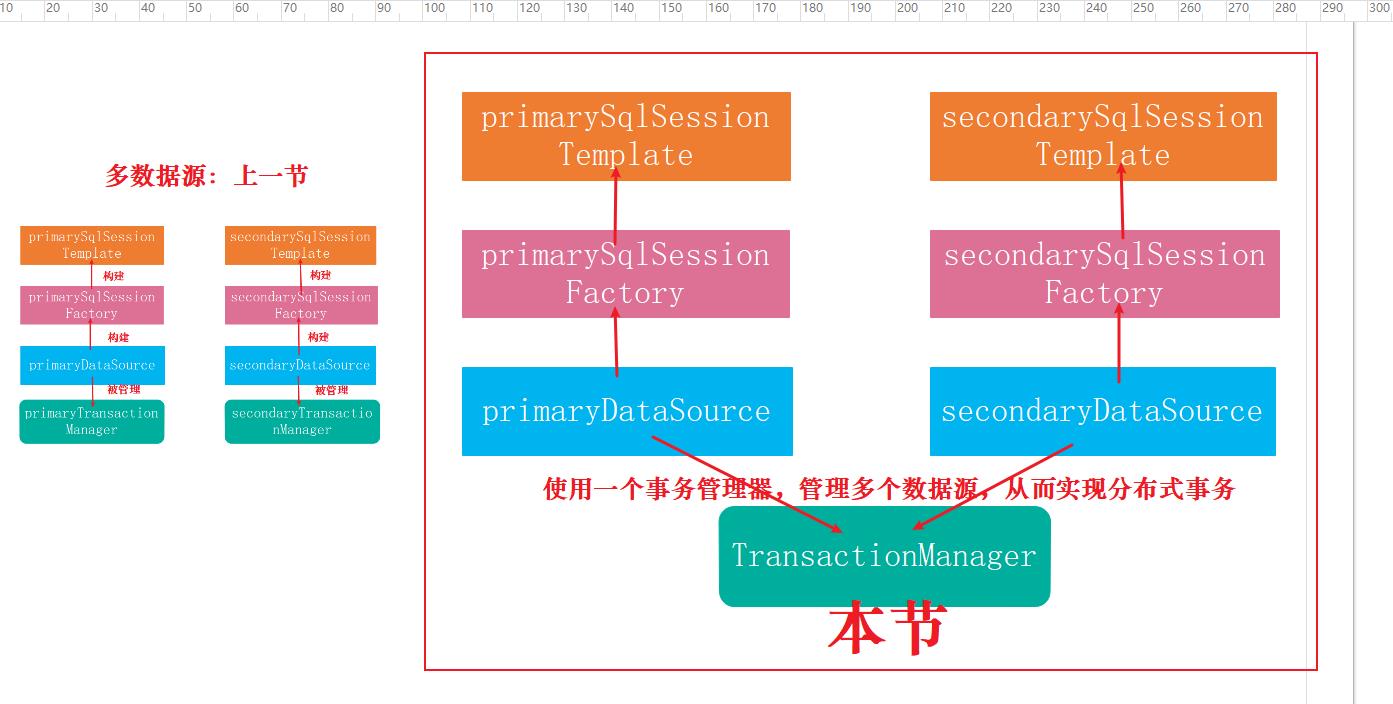
整合jta-atomikos
首先需要引入jta的依赖包,注意是JTA(事务管理),不是JPA。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
双数据源配置。删掉原有其他的数据库连接配置.两个数据源的名称分别是:primary和secondary。分别访问testdb和testdb2数据库。另外注意:驱动类是mysqlXADataSource(支持分布式事务),而不是MysqlDataSource。
primarydb:
uniqueResourceName: primary
xaDataSourceClassName: com.mysql.cj.jdbc.MysqlXADataSource
xaProperties:
url: jdbc:mysql://192.168.161.3:3306/testdb?useUnicode=true&characterEncoding=utf-8&useSSL=false
user: test
password: 4rfv$RFV
exclusiveConnectionMode: true
minPoolSize: 3
maxPoolSize: 10
testQuery: SELECT 1 from dual #由于采用HikiriCP,用于检测数据库连接是否存活。
secondarydb:
uniqueResourceName: secondary
xaDataSourceClassName: com.mysql.cj.jdbc.MysqlXADataSource
xaProperties:
url: jdbc:mysql://192.168.161.3:3306/testdb2?useUnicode=true&characterEncoding=utf-8&useSSL=false
user: test
password: 4rfv$RFV
exclusiveConnectionMode: true
minPoolSize: 3
maxPoolSize: 10
testQuery: SELECT 1 from dual #由于采用HikiriCP,用于检测数据库连接是否存活。
配置多数据源
数据源DataSource、SqlSessionFactory、SqlSessionTemplate、扫描路径,对于primarydb和secondarydb都是自己一套,需要分别配置。
数据源一:primarydb,只需要在上一节的代码基础上做如下修改即可
- 读取primarydb配置,构建数据源
- 构建的是AtomikosDataSourceBean数据源,不是普通的DataSource。普通的DataSource不支持分布式事务
- 将primaryTransactionManager和secondaryTransactionManager事务管理器去掉,后文换成一个统一的事务管理器。

上图中代码如下:
@Configuration
//数据源primary-testdb库接口存放目录
@MapperScan(basePackages = "com.zimug.boot.launch.generator.testdb",
sqlSessionTemplateRef = "primarySqlSessionTemplate")
public class PrimaryDataSourceConfig
@Bean(name = "primaryDataSource")
@ConfigurationProperties(prefix = "primarydb") //数据源primary配置
@Primary
public DataSource primaryDataSource()
return new AtomikosDataSourceBean();
@Bean(name = "primarySqlSessionFactory")
@Primary
public SqlSessionFactory primarySqlSessionFactory(
@Qualifier("primaryDataSource") DataSource dataSource)
throws Exception
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
//设置XML文件存放位置
bean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath:generator/testdb/*.xml")); //注意这里testdb目录
return bean.getObject();
@Bean(name = "primarySqlSessionTemplate")
@Primary
public SqlSessionTemplate primarySqlSessionTemplate(
@Qualifier("primarySqlSessionFactory") SqlSessionFactory sqlSessionFactory)
throws Exception
return new SqlSessionTemplate(sqlSessionFactory);
数据源二:secondarydb。参照数据源一,将primary修改为secondary再配置一组。
@Configuration
@MapperScan(basePackages = "com.zimug.boot.launch.generator.testdb2", //注意这里testdb2目录
sqlSessionTemplateRef = "secondarySqlSessionTemplate")
public class SecondaryDataSourceConfig
@Bean(name = "secondaryDataSource")
@ConfigurationProperties(prefix = "secondarydb") //注意这里secondary配置
public DataSource secondaryDataSource()
return new AtomikosDataSourceBean();
@Bean(name = "secondarySqlSessionFactory")
public SqlSessionFactory secondarySqlSessionFactory(
@Qualifier("secondaryDataSource") DataSource dataSource)
throws Exception
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
//设置XML文件存放位置
bean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath:generator/testdb2/*.xml")); //注意这里testdb2目录
return bean.getObject();
@Bean(name = "secondarySqlSessionTemplate")
public SqlSessionTemplate secondarySqlSessionTemplate(
@Qualifier("secondarySqlSessionFactory") SqlSessionFactory sqlSessionFactory)
throws Exception
return new SqlSessionTemplate(sqlSessionFactory);
统一事务管理器
虽然我们将数据源及其相关配置分成了两组,但这两组数据源使用的事务管理器必须是同一个,这样才能实现分布式事务。下面是事务管理器的配置。固定代码,一点不用改,不要纠结。不需要问张三为什么叫张三,因为他爸爸就是这么给他起名的。
@Configuration
@EnableTransactionManagement
public class XATransactionManagerConfig
//User事务
@Bean(name = "userTransaction")
public UserTransaction userTransaction() throws Throwable
UserTransactionImp userTransactionImp = new UserTransactionImp();
userTransactionImp.setTransactionTimeout(10000);
return userTransactionImp;
//分布式事务
@Bean(name = "atomikosTransactionManager", initMethod = "init", destroyMethod = "close")
public TransactionManager atomikosTransactionManager() throws Throwable
UserTransactionManager userTransactionManager = new UserTransactionManager();
userTransactionManager.setForceShutdown(false);
return userTransactionManager;
//事务管理器
@Bean(name = "transactionManager")
@DependsOn( "userTransaction", "atomikosTransactionManager" )
public PlatformTransactionManager transactionManager() throws Throwable
return new JtaTransactionManager(userTransaction(),atomikosTransactionManager());
service层测试
将自动生成的代码,分别存放于testdb和testdb2两个文件夹
在Service层模拟异常
@Override
@Transactional
public ArticleVO saveArticle(ArticleVO article)
Article articlePO = dozerMapper.map(article,Article.class);
articleMapper.insert(articlePO);
Message message = new Message();
message.setName("kobe");
message.setContent("退役啦");
messageMapper.insert(message);
int a = 2/0; //认为制造被除数为0的异常
return article;
正常情况下,2组数据分别插入到testdb的article表和testdb2的message表。如果我们人为制造一个异常(如上面代码),事务回滚,二者均无法插入数据。
mybatisplus+atomikos实现分布式事务
遗留问题
前面介绍的多数据源的实现方式不适用于Mybatis plus Mapper。我们该如何实现Mybatis plus Mapper的多数据源以及分布式事务?
方案一:采用Mybatis Plus官网上实现的基于AOP以及注解的动态数据源切换方案。基于AOP以及注解的动态数据源切换方案。这个方案的优点是:数据源灵活切换。但缺点也同样明显:
- 需要为每一个类或者持久层方法指定数据源,如果编码人员素质一般,很容易错误的使用数据源。
- 动态切换数据源,也就意味着“从使用的角度”出错的概率变大。从而导致错误的配置使用分布式事务。版本兼容问题有可能此起彼伏。
方案二:我们仍然采用最简的实现方式。就是将不同的数据库操作Mapper分包存放,分包注入使用不同的数据源。这种方式实现逻辑简单,万变不离其宗,是“约定大于配置”思想的体现,约定好了该放哪就放哪。虽然不灵活,但是使用方便,也不容易出错。即使出错,也容易发现(在package层面发现问题,比到代码里面去找Bug要容易的多)。
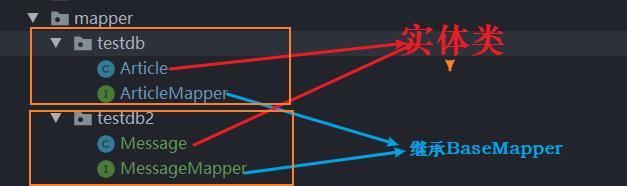
如上图:把操作testdb数据库的mapper,放在testdb目录下。把操作testdb2数据库的mapper,放在testdb2目录下。实体类其实放在哪里,并不重要。为了看上去整洁,我们把它和Mapper放在一起。
需要注意的是,我们本节调整之后的实现方法既适用于手写的Mybatis Mapper(以及XMl),也适用于mybatis generator生成的代码,也适用于Mybatis Plus集成BaseMapper。全都适用!
整合jta-atomikos
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
配置多数据源(调整)
配置多数据源,实现方法和上面几乎一模一样。
唯一的区别在于:前面章节我们使用的是SqlSessionFactoryBean,这里必须使用MybatisSqlSessionFactoryBean。
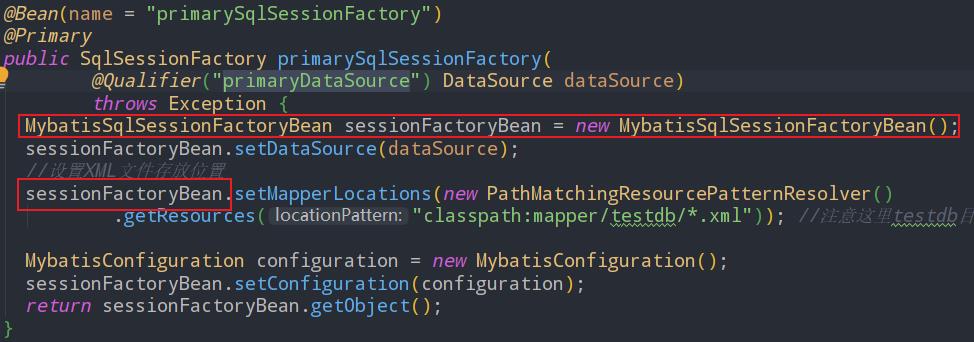
同样DataSource、SQLSessionFactory、SqlSessionTemplate配置多组(多数据源)。
统一事务管理器,和mybaits实现方法一模一样。
Spring事务与分布式事务
事务的具体定义
事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败(出现异常),都将导致整个事务的回滚。简单地说,事务提供一种“要么什么都不做,要么做全套(All or Nothing)”机制。
明白上面的这几句话,ACID就不用看了,ACID就是对这句话的一个解释。
-
原子性(Atomicity):一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚。 -
一致性(Consistency):数据库总是从一个一致性的状态转换到另一个一致性的状态。在事务开始前后,数据库的完整性约束没有被破坏。例如违反了唯一性,必须撤销事务,返回初始状态。 -
隔离性(Isolation):每个读写事务的对象对其他事务的操作对象能相互分离,即:事务提交前的数据对其他事务是不可见的,通常内部加锁实现。不同的隔离级别加不同的锁。 -
持久性(Durability): 一旦事务提交,则其所做的修改会永久保存到数据库。
并发环境下的数据库事务
事务并发执行会出现的问题
我们先来看一下事务并发,数据库可能会出现的问题:
更新丢失(问题严重)
- 当有两个并发执行的事务,更新同一行数据,那么有可能一个操作会把另一个操作的更新数据覆盖掉。
脏读 (问题严重)
- 一个事务读到另一个尚未提交的事务中的数据,即读到了事务的处理过程中的数据,而不是结果数据。 该数据可能会被回滚从而失效。如果第一个事务拿着失效的数据去处理那就发生错误了。
不可重复读 (一般来说可以接受,比如你交话费,交完就查看可能没到账,过2分钟再查就到账了)
不可重复读的含义:一个事务对同一行数据读了两次,却得到了不同的结果。它具体分为如下两种情况:
- 虚读:在事务1两次读取同一记录的过程中,事务2对该记录进行了修改,从而事务1第二次读到了不一样的记录。
- 幻读:事务1在两次查询的过程中,事务2对该表进行了插入、删除操作,从而事务1第二次查询的结果数量发生了变化。
不可重复读 与 脏读 的区别?
脏读读到的是尚未提交的数据,而不可重复读读到的是已经提交的数据,只不过在两次读的过程中数据被另一个事务改过了。
如何解决并发过程中事务问题(事务隔离)
数据库一共有如下四种隔离级别:
- Read uncommitted 读未提交
在该级别下,一个事务对一行数据修改的过程中,不允许另一个事务对该行数据进行修改,但允许另一个事务对该行数据读。
因此本级别下,不会出现更新丢失,但会出现脏读、不可重复读。
- Read committed 读提交 (oracle、sqlserver默认的隔离级别)
在该级别下,未提交的写事务不允许其他事务访问该行,因此不会出现脏读;但是读取数据的事务允许其他事务的访问该行数据,因此会出现不可重复读的情况。
- Repeatable read 重复读 (mysql的默认隔离级别)
简单说就是:一个事务开始读或写数据时,不允许其他事务对该数据进行修改。在该级别下,读事务禁止写事务,但允许读事务,因此不会出现同一事务两次读到不同的数据的情况(不可重复读),且写事务禁止其他一切事务。这个级别无法解决幻读问题。
- Serializable 序列化
该级别要求所有事务都必须串行执行,因此能避免一切因并发引起的问题,但效率很低。
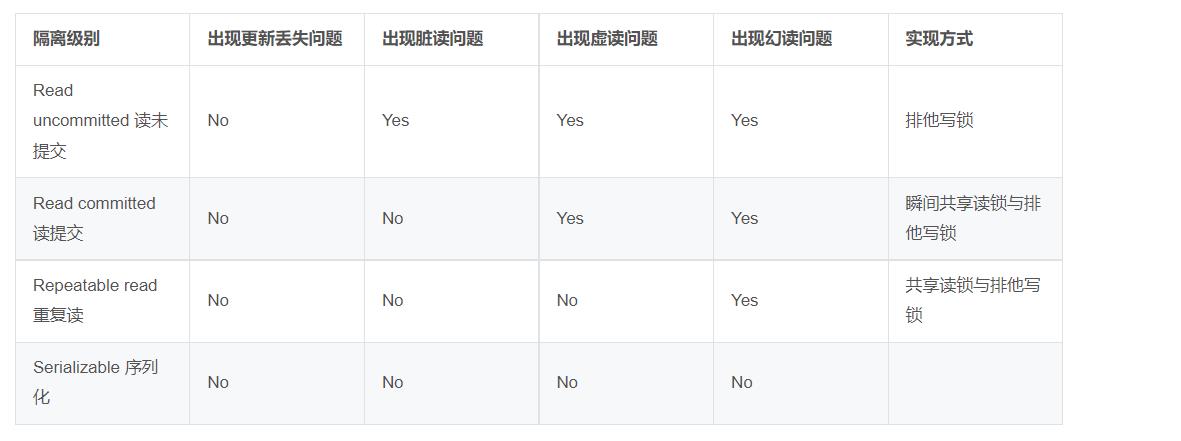
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读这些并发问题,应该由应用程序员采用悲观锁或乐观锁来控制。
Spring事务传播行为
举例说明
事务传播行为用来描述由某一个事务传播行为修饰的方法被嵌套进另一个方法的时事务如何传播。
用伪代码说明:
ServiceA
@Transactional(Propagation=XXX)
void methodA()
//其他持久层操作数据库
ServiceB.methodB();
ServiceB
@Transactional(Propagation=YYY)
void methodB()
//持久层操作数据库
代码中methodA()方法嵌套调用了methodB()方法,methodB()的事务传播行为由@Transactional(Propagation=YYY)设置决定。
Spring中七种事务传播行为

定义非常简单,也很好理解,下面我们就进入代码测试部分,验证我们的理解是否正确。
回答一个问题:当一个Service函数里面既使用Mybatis Mapper,又使用JdbcTemplate操作同一个数据库,能保证二者操作的整体事务么? 答案是可以的,因为事务控制器是在Spring的层面控制的,与持久层框架无关。
Spring @Transactional 注解
新建的Spring Boot项目中,一般都会引用spring-boot-starter或者spring-boot-starter-web,而这两个起步依赖中都已经包含了对于spring-boot-starter-jdbc或spring-boot-starter-data-jpa的依赖。 当我们使用了这两个依赖的时候,框架会自动默认分别注入DataSourceTransactionManager或JpaTransactionManager。
所以我们不需要任何额外配置就可以用@Transactional注解进行事务的管理。在spring框架内实现多个数据库持久层操作的事务,我们只需要在方法或类添加@Transactional注解即可。@Transactional注解只能应用到public可见度的方法上,可以被应用于接口定义和接口方法,方法会覆盖类上面声明的事务。
@Transactional
public int xxx()
// 增删改持久层操作一
// 增删改持久层操作二
// ……
当多个持久层操作在同一个Service层方法上时,能保证多个持久层操作要么都成功,要么都失败。

分布式事务
笔者自己将分布式事务分为两种:跨服务的分布式事务,跨库的分布式事务。
跨库的分布式事务
跨库的分布式事务:一个服务层函数,需要同时操作两个数据库。我们之前给大家讲的例子都是这一种,实际上总的思路:就是有一个“事务管理器”对象统一管理多个数据源事务的提交与回滚。事务管理器协调多数据源进行两段式提交

为了大家方便理解:我以小故事方式给大家讲一下两段式提交:
背景:以缉毒警察抓捕专案毒贩为背景,目前3位毒贩A、B、C分别住在不同的住址,目前要实施抓捕。将缉毒大队分成三个组,组A、组B、组C分别针对毒贩A、B、C,三个小组统一由“缉毒大队长”协调指挥。
- 三名毒贩住在不同的住址,体现的是“分布式”,3个数据库
- “缉毒大队长”代表的是“事务管理器”TransctionManager,负责抓捕这个事务的协调指挥工作。
- 三个抓捕小组,代表的是XAResourceManager,是XA/JTA两阶段提交规范的单一资源操作的执行者。
抓捕的要求是:把三名毒贩同时抓获,不能先抓A,如果A抓捕失败打草惊蛇,可能给B、C报信。要么就全抓到,要么就一个也别抓,免得打草惊蛇。
- 抓捕的要求和我们对于“分布式”事务的要求是一样的,多数据库操作要么都成功,要么都失败。
抓捕的步骤:
- 第一步:三个小组分别靠近毒贩A、B、C的住址,然后等待“缉毒大队长”协调指挥。“缉毒大队长”询问A小组是否完成准备抓捕工作,A小组回复:准备完毕。以此类推,“缉毒大队长”询问B、C两个抓捕小组,这三个组都准备完成了,并且没有异常情况发生,第一阶段工作完毕。即:两阶段提交的第一阶段:预提交。
- 如果任何一个小组发现异常,整个行动计划立刻取消。三个抓捕小组同时收队,这个可以认为是数据库事务回滚。
- 第二步:三个小组已经全部准备好了,“缉毒大队长”下命令:“抓捕”。三个抓捕小组同时行动,分别抓捕三名毒贩。确保全部落网,一个也跑不掉。这就好比事务两阶段提交的第二阶段:整体提交。
跨服务的分布式事务
跨服务分布式事务: 也就是说我在做一个服务A的时候,需要通过HTTP网络请求调用多个其他服务,有可能第一个服务B成功了,第二个服务C执行失败了。我们期望的结果是:服务B和服务C都成功。这种分布式单纯的依靠数据库层面就很难解决了

这种情况一般都是通过最终一致性的方式解决。比如:通过MQ消息队列,给服务B发消息,服务B执行,然后真的做持久化操作数据入库了。

给服务C发消息,如果服务C执行失败,这个消息就会存在MQ里面,依照一定的策略还会发给服务C,直到服务C成功为止。这种策略被叫做“ Exactly-once”,精确的保证成功一次并且只成功一次。这样保障操作结果的最终一致性。
一键生成数据库文档
解决什么问题
数据库文档是我们在企业项目开发中需要交付的文档,通常需要开发人员去手工编写。编写完成后,数据库发生变更又需要手动的进行修改,从而浪费了大量的人力。并且这种文档并没有什么技术含量,被安排做这个工作的程序员往往自己心里会有抵触情绪,悲观的预期自己在团队的位置,造成离职也是可能的。如下面的这种文档的内容
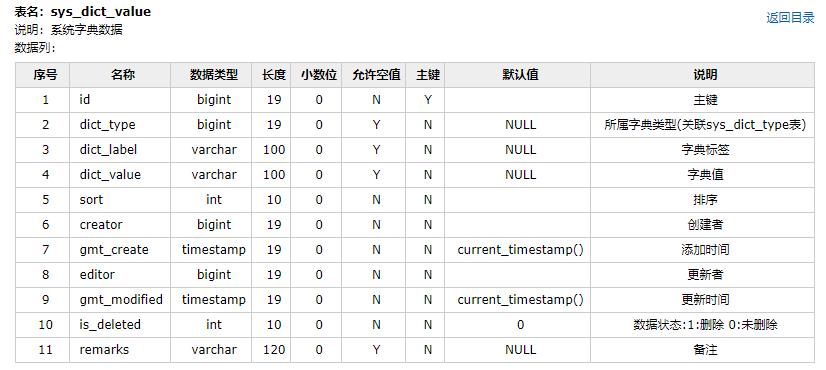
笔者最近在github上面发现一个数据库文档生成工具:screw(螺丝钉)。该工具能够通过简单地配置,快速的根据数据库表结构进行逆向工程,将数据库表结构及字段逆向生成为文档。
特点
- 简洁、轻量、设计良好
- 多数据库支持:MySQL、MariaDB、TIDB、Oracle、 SqlServer、PostgreSQL、Cache DB
- 多种格式文档: html、word、 markdwon
- 灵活扩展:支持用户自定义模板和展示样式修改(freemarker模板)
依赖库探究
mvn中央仓库查看最新版本,将如下的maven坐标引入到Spring Boot项目中去:
<dependency>
<groupId>cn.smallbun.screw</groupId>
<artifactId>screw-core</artifactId>
<version>1.0.3</version>
</dependency>
从maven仓库的编译依赖中可以看到,screw-core其实现依赖了如下的内容。重点关注freemarker,因为该项目是使用freemarker作为模板生成文档。
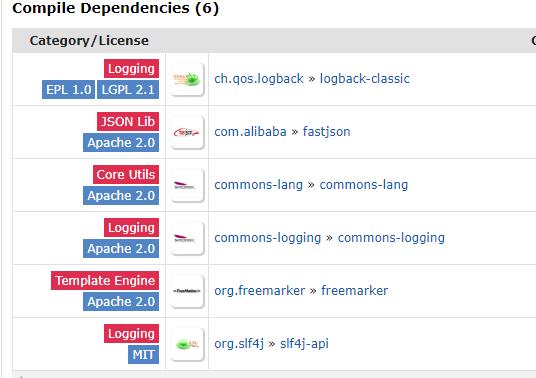
除此之外,screw使用了HikariCP作为数据库连接池,所以:
- 你的Spring Boot项目需要引入HikariCP数据库连接池。
- 根据你的数据库类型及版本,引入正确的JDBC驱动
开始
以上的工作都做好之后,我们就可以来配置文档生成参数了。实现文档生成有两种方式,一种是写代码,一种是使用maven 插件。
- 我个人还是比较喜欢使用代码的当时,写一个单元测试用例就可以了,相对独立,使用方式也灵活。
- 如果放在pom.xml的插件配置里面,让本就很冗长的pom.xml变的更加的冗长,不喜欢。
所以maven插件的这种方式我就不给大家演示了,直接把下面的代码Ctrl + C/V到你的src/test/java目录下。简单的修改配置,运行就可以了
import cn.smallbun.screw.core.Configuration;
import cn.smallbun.screw.core.engine.EngineConfig;
import cn.smallbun.screw.core.engine.EngineFileType;
import cn.smallbun.screw.core.engine.EngineTemplateType;
import cn.smallbun.screw.core.execute.DocumentationExecute;
import cn.smallbun.screw.core.process.ProcessConfig;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import org.junit.jupiter.api.Test;
import javax.sql.DataSource;
import java.util.ArrayList;
public class ScrewTest
@Test
void testScrew()
//数据源
HikariConfig hikariConfig = new HikariConfig();
hikariConfig.setDriverClassName("com.mysql.cj.jdbc.Driver");
hikariConfig.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/database");
hikariConfig.setUsername("db-username");
hikariConfig.setPassword("db-password");
//设置可以获取tables rem以上是关于重学Springboot系列之整合数据库开发框架---下的主要内容,如果未能解决你的问题,请参考以下文章