利用knn svm cnn 逻辑回归 mlp rnn等方法实现mnist数据集分类(pytorch实现)
Posted 心之所向521
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用knn svm cnn 逻辑回归 mlp rnn等方法实现mnist数据集分类(pytorch实现)相关的知识,希望对你有一定的参考价值。
电脑 配置:
python3.6*
*Pytorch 1.2.0*
*torchvision 0.4.0想学习机器学习和深度学习的同学,首先找个比较经典的案例和经典的方法自己动手试一试,分析这些方法的思想和每一行代码是一个快速入门的小技巧,今天我们谈论怎么用一些比较经典的方法实现经典数据集MNIST的识别分类问题。
废话不多说,直接上代码!!!

1.svm实现
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# arguments define
import argparse
# load torch
import torchvision
# other utilities
# import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.metrics import confusion_matrix
#%% Load the training data
def MNIST_DATASET_TRAIN(downloads, train_amount):
# Load dataset
training_data = torchvision.datasets.MNIST(
root = './mnist/',
train = True,
transform = torchvision.transforms.ToTensor(),
download = downloads
)
#Convert Training data to numpy
train_data = training_data.train_data.numpy()[:train_amount]
train_label = training_data.train_labels.numpy()[:train_amount]
# Print training data size
print('Training data size: ',train_data.shape)
print('Training data label size:',train_label.shape)
# plt.imshow(train_data[0])
# plt.show()
train_data = train_data/255.0
return train_data, train_label
#%% Load the test data
def MNIST_DATASET_TEST(downloads, test_amount):
# Load dataset
testing_data = torchvision.datasets.MNIST(
root = './mnist/',
train = False,
transform = torchvision.transforms.ToTensor(),
download = downloads
)
# Convert Testing data to numpy
test_data = testing_data.test_data.numpy()[:test_amount]
test_label = testing_data.test_labels.numpy()[:test_amount]
# Print training data size
print('test data size: ',test_data.shape)
print('test data label size:',test_label.shape)
# plt.imshow(test_data[0])
# plt.show()
test_data = test_data/255.0
return test_data, test_label
#%% Main function for MNIST dataset
if __name__=='__main__':
# Training Arguments Settings
parser = argparse.ArgumentParser(description='Saak')
parser.add_argument('--download_MNIST', default=True, metavar='DL',
help='Download MNIST (default: True)')
parser.add_argument('--train_amount', type=int, default=60000,
help='Amount of training samples')
parser.add_argument('--test_amount', type=int, default=2000,
help='Amount of testing samples')
args = parser.parse_args()
# Print Arguments
print('\\n----------Argument Values-----------')
for name, value in vars(args).items():
print('%s: %s' % (str(name), str(value)))
print('------------------------------------\\n')
# Load Training Data & Testing Data
train_data, train_label = MNIST_DATASET_TRAIN(args.download_MNIST, args.train_amount)
test_data, test_label = MNIST_DATASET_TEST(args.download_MNIST, args.test_amount)
training_features = train_data.reshape(args.train_amount,-1)
test_features = test_data.reshape(args.test_amount,-1)
# Training SVM
print('------Training and testing SVM------')
clf = svm.SVC(C=5, gamma=0.05,max_iter=10)
clf.fit(training_features, train_label)
#Test on test data
test_result = clf.predict(test_features)
precision = sum(test_result == test_label)/test_label.shape[0]
print('Test precision: ', precision)
#Test on Training data
train_result = clf.predict(training_features)
precision = sum(train_result == train_label)/train_label.shape[0]
print('Training precision: ', precision)
#Show the confusion matrix
matrix = confusion_matrix(test_label, test_result)2.cnn实现
# library
# standard library
import os
# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
plt.rc("font", family='KaiTi')
# import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 50
LR = 0.001 # learning rate
DOWNLOAD_MNIST = False
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[0])
# plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
print(cnn) # net architecture
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# following function (plot_with_labels) is for visualization, can be ignored if not interested
# from matplotlib import cm
# try: from sklearn.manifold import TSNE; HAS_SK = True
# except: HAS_SK = False; print('Please install sklearn for layer visualization')
# def plot_with_labels(lowDWeights, labels):
# plt.cla()
# X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
# for x, y, s in zip(X, Y, labels):
# c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
# plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
# plt.ion()
# training and testing
for epoch in range(EPOCH):
losses = []
acc = []
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, 'Step: ', step/50, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
losses.append(loss.data.numpy())
acc.append(accuracy)
# if HAS_SK:
# # Visualization of trained flatten layer (T-SNE)
# tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
# plot_only = 500
# low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
# labels = test_y.numpy()[:plot_only]
# plot_with_labels(low_dim_embs, labels)
# plt.ioff()
plt.figure()
f, axes = plt.subplots(1, 1)
axes.clear()
axes.plot([x for x in range(24)], losses) ###range(1,11)
axes.set_xlabel("训练步数")
axes.set_ylabel("损失值")
axes.set_title("MNIST")
axes.set_ylim((0, max(losses))) ###1
axes.set_xlim((1, 24))
row_labels = ['准确率:']
col_labels = ['数值']
value = max(acc)
table_vals = [[':.2f%'.format(value*100)]]
row_colors = ['gold']
my_table = plt.table(cellText=table_vals, colWidths=[0.1] * 5,
rowLabels=row_labels, rowColours=row_colors, loc='best')
plt.savefig("CNN" + ".png")
plt.show()
# print 10 predictions from test data
test_output, _ = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')3.knn实现
from __future__ import print_function
import os
# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import time
# import matplotlib.pyplot as plt
localtime = time.asctime( time.localtime(time.time()) )
print("本地时间为 :", localtime)
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 50
LR = 0.001 # learning rate
DOWNLOAD_MNIST = False
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[0])
# plt.show()
# pick 2000 samples to speed up testing
train_data = torchvision.datasets.MNIST(root='./mnist/', train=True)
train_x = torch.unsqueeze(train_data.train_data, dim=1).type(torch.FloatTensor)[:60000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
train_y = train_data.train_labels[:60000]
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
print(train_x.size(),train_y.size(),test_x.size(),test_y.size())
train_x = train_x.view(-1,28*28)
test_x = test_x.view(-1,28*28)
# K-Nearest Neighbor Classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn import datasets
from skimage import exposure
# import matplotlib.pyplot as plt
import numpy as np
# import imutils
# import cv2
# load the MNIST digits dataset
# mnist = datasets.load_digits()
# print(len(np.array(mnist.data)[0]))
# Training and testing split,
# 75% for training and 25% for testing
# print(len(mnist))
# (trainData, testData, trainLabels, testLabels) = train_test_split(np.array(mnist.data), mnist.target, test_size=0.25, random_state=42)
# take 10% of the training data and use that for validation
# (trainData, valData, trainLabels, valLabels) = train_test_split(trainData, trainLabels, test_size=0.1, random_state=84)
trainData = np.array(train_x)
testData = np.array(test_x)
trainLabels = np.array(train_y)
testLabels = np.array(test_y)
valData = testData
valLabels = testLabels
# Checking sizes of each data split
print("training data points: ".format(len(trainLabels)))
print("validation data points: ".format(len(valLabels)))
print("testing data points: ".format(len(testLabels)))
# initialize the values of k for our k-Nearest Neighbor classifier along with the
# list of accuracies for each value of k
kVals = range(1, 30, 2)
accuracies = []
# loop over kVals
for k in range(1, 30, 2):
# train the classifier with the current value of `k`
model = KNeighborsClassifier(n_neighbors=k)
model.fit(trainData, trainLabels)
# evaluate the model and print the accuracies list
score = model.score(valData, valLabels)
print("k=%d, accuracy=%.2f%%" % (k, score * 100))
accuracies.append(score)
localtime = time.asctime( time.localtime(time.time()) )
print("本地时间为 :", localtime)
# largest accuracy
# np.argmax returns the indices of the maximum values along an axis
i = np.argmax(accuracies)
print("k=%d achieved highest accuracy of %.2f%% on validation data" % (kVals[i],
accuracies[i] * 100))
# Now that I know the best value of k, re-train the classifier
model = KNeighborsClassifier(n_neighbors=kVals[i])
model.fit(trainData, trainLabels)
# Predict labels for the test set
predictions = model.predict(testData)
# Evaluate performance of model for each of the digits
print("EVALUATION ON TESTING DATA")
print(classification_report(testLabels, predictions))
# some indices are classified correctly 100% of the time (precision = 1)
# high accuracy (98%)
# check predictions against images
# loop over a few random digits
image = testData
j = 0
for i in np.random.randint(0, high=len(testLabels), size=(24,)):
# np.random.randint(low, high=None, size=None, dtype='l')
prediction = model.predict(image)[i]
image0 = image[i].reshape((8, 8)).astype("uint8")
image0 = exposure.rescale_intensity(image0, out_range=(0, 255))
# plt.subplot(4,6,j+1)
# plt.title(str(prediction))
# plt.imshow(image0,cmap='gray')
# plt.axis('off')
# convert the image for a 64-dim array to an 8 x 8 image compatible with OpenCV,
# then resize it to 32 x 32 pixels for better visualization
#image0 = imutils.resize(image[0], width=32, inter=cv2.INTER_CUBIC)
j = j+1
# show the prediction
# print("I think that digit is: ".format(prediction))
# print('image0 is ',image0)
# cv2.imshow("Image", image0)
# cv2.waitKey(0) # press enter to view each one!
# plt.show()4.逻辑回归实现
# library
# standard library
import os
# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
# import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 50
LR = 0.001 # learning rate
DOWNLOAD_MNIST = False
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[0])
# plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
class logisticRg(nn.Module):
def __init__(self):
super(logisticRg, self).__init__()
self.lr = nn.Sequential(
nn.Linear(28*28,10)
)
def forward(self, x):
output = self.lr(x)
return output, x # return x for visualization
lor = logisticRg()
print(lor) # net architecture
optimizer = torch.optim.Adam(lor.parameters(), lr=LR) # optimize all logistic parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# following function (plot_with_labels) is for visualization, can be ignored if not interested
# from matplotlib import cm
# try: from sklearn.manifold import TSNE; HAS_SK = True
# except: HAS_SK = False; print('Please install sklearn for layer visualization')
# def plot_with_labels(lowDWeights, labels):
# plt.cla()
# X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
# for x, y, s in zip(X, Y, labels):
# c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
# plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
# plt.ion()
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
# print(b_x.size())
b_x = b_x.view(-1, 28*28)
# print(b_x.size())
output = lor(b_x)[0] # logistic output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output, last_layer = lor(test_x.view(-1,28*28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
# if HAS_SK:
# # Visualization of trained flatten layer (T-SNE)
# tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
# plot_only = 500
# low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
# labels = test_y.numpy()[:plot_only]
# plot_with_labels(low_dim_embs, labels)
# plt.ioff()
# print 10 predictions from test data
test_output, _ = lor(test_x[:10].view(-1,28*28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')5.mlp实现
# library
# standard library
import os
# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
# import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 50
LR = 0.001 # learning rate
DOWNLOAD_MNIST = False
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[0])
# plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.mlp = nn.Sequential(
nn.Linear(28*28,28*28),
nn.Linear(28*28,10)
)
def forward(self, x):
output = self.mlp(x)
return output, x # return x for visualization
mlp = MLP()
print(mlp) # net architecture
optimizer = torch.optim.Adam(mlp.parameters(), lr=LR) # optimize all logistic parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# following function (plot_with_labels) is for visualization, can be ignored if not interested
# from matplotlib import cm
# try: from sklearn.manifold import TSNE; HAS_SK = True
# except: HAS_SK = False; print('Please install sklearn for layer visualization')
# def plot_with_labels(lowDWeights, labels):
# plt.cla()
# X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
# for x, y, s in zip(X, Y, labels):
# c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
# plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
# plt.ion()
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
# print(b_x.size())
b_x = b_x.view(-1, 28*28)
# print(b_x.size())
output = mlp(b_x)[0] # logistic output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output, last_layer = mlp(test_x.view(-1,28*28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
# if HAS_SK:
# # Visualization of trained flatten layer (T-SNE)
# tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
# plot_only = 500
# low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
# labels = test_y.numpy()[:plot_only]
# plot_with_labels(low_dim_embs, labels)
# plt.ioff()
# print 10 predictions from test data
test_output, _ = mlp(test_x[:10].view(-1,28*28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')6.rnn实现
import torch
from torch import nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
# import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 64
TIME_STEP = 28 # rnn time step / image height
INPUT_SIZE = 28 # rnn input size / image width
LR = 0.01 # learning rate
DOWNLOAD_MNIST = True # set to True if haven't download the data
# Mnist digital dataset
train_data = dsets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST, # download it if you don't have it
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
# plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.train_labels[0])
# plt.show()
# Data Loader for easy mini-batch return in training
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# convert test data into Variable, pick 2000 samples to speed up testing
test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
test_x = test_data.test_data.type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
test_y = test_data.test_labels.numpy()[:2000] # covert to numpy array
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns
input_size=INPUT_SIZE,
hidden_size=64, # rnn hidden unit
num_layers=1, # number of rnn layer
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10)
def forward(self, x):
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size)
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state
# choose r_out at the last time step
out = self.out(r_out[:, -1, :])
return out
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
b_x = b_x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
output = rnn(b_x) # rnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output = rnn(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
# print 10 predictions from test data
test_output = rnn(test_x[:10].view(-1, 28, 28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')也可以自己添加可视化效果,我这里用matplotlib工具实现的效果如示:
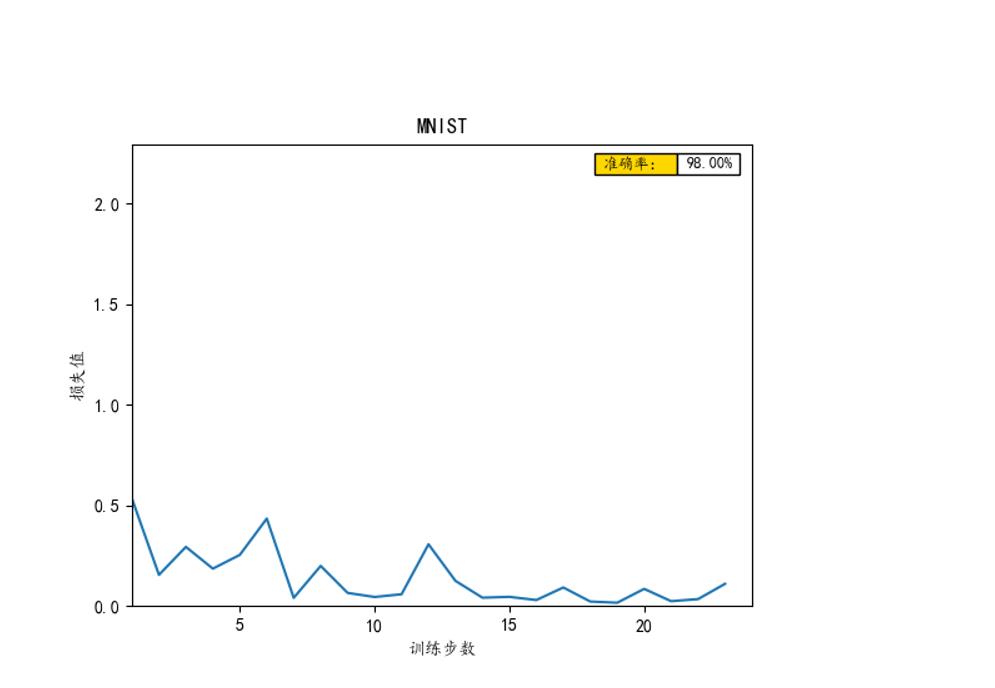
大家可以自己动手试一试!!

以上是关于利用knn svm cnn 逻辑回归 mlp rnn等方法实现mnist数据集分类(pytorch实现)的主要内容,如果未能解决你的问题,请参考以下文章