《双城之战》口碑爆炸,却有评论说它不如国漫?Python采集好评中评差评数据,看它真有那么差吗
Posted 松鼠爱吃饼干
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《双城之战》口碑爆炸,却有评论说它不如国漫?Python采集好评中评差评数据,看它真有那么差吗相关的知识,希望对你有一定的参考价值。
前言
上次爬了《双城之战》的视频弹幕,效果很不理想,这次的目标是豆瓣的评论数据
分别把好评、一般和差评都一起爬下来
主页左侧可以免费领取【代码】【相关教程、资料】,或者对于本篇文章有疑问的同学可以私信我
知识点
- 爬虫基本流程
- requests
- 制作词云
- jieba
- imageio
- wordcloud
环境
- Python 3.8
- pycharm 2021.2
代码实现部分
- 发送请求
- 解析数据
- 保存数据
- 制作词云图
评论爬虫代码
导入模块
import requests
import parsel
请求数据
先打开开发者工具找到数据
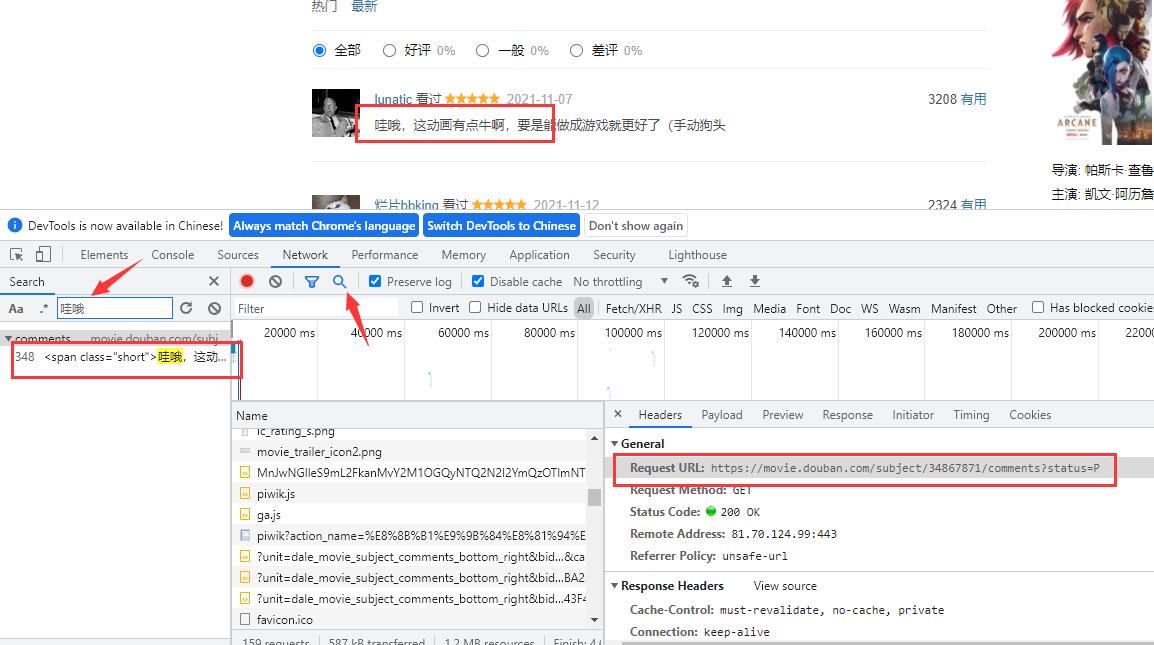
url = f'https://movie.douban.com/subject/34867871/comments?start=20&limit=20&status=P&sort=new_score'
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
response = requests.get(url=url, headers=headers)
解析数据
select = parsel.Selector(response.text)
content_list = select.css('.short::text').getall()
翻页
找到不同页数的规律,用for page进行翻页

for page in range(0, 220, 20):
url = f'https://movie.douban.com/subject/34867871/comments?start=page&limit=20&status=P&sort=new_score'
保存数据
for index in content_list:
with open('双城之战.txt', mode='a', encoding='utf-8') as f:
f.write(index)
f.write('\\n')
print(index)
实现效果

词云代码
导入模块
import jieba
import wordcloud
import imageio
导入imageio库中的imread函数,并用这个函数读取本地图片,作为词云形状图片
py = imageio.imread(r"C:\\Users\\Administrator\\Desktop\\123.png")
读取文件内容
f = open(r'C:\\Users\\Administrator\\Desktop\\双城之战.txt', encoding='utf-8')
txt = f.read()
jiabe 分词 分割词汇
txt_list = jieba.lcut(txt)
string = ' '.join(txt_list)
词云图设置
wc = wordcloud.WordCloud(
width=1000, # 图片的宽
height=700, # 图片的高
background_color='white', # 图片背景颜色
font_path='STKAITI.TTF', # 词云字体
mask=py, # 所使用的词云图片
scale=5,
)
给词云输入文字
wc.generate(string)
词云图保存图片地址
wc.to_file(r'C:\\Users\\Administrator\\Desktop\\out.png')
全部评论词云图

好评词云图

一般词云图

差评词云图

以上是关于《双城之战》口碑爆炸,却有评论说它不如国漫?Python采集好评中评差评数据,看它真有那么差吗的主要内容,如果未能解决你的问题,请参考以下文章