如何构建反汇编代码?
Posted 人邮异步社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何构建反汇编代码?相关的知识,希望对你有一定的参考价值。
大型的非结构化反汇编指令堆几乎不可能被分析,所以大多数反汇编工具都会以某种简单的分析方法来构造反汇编代码。在本节中,我们将会讨论通过反汇编工具恢复的通用代码和数据结构,以及这些通用代码和数据结构会如何帮助我们进行二进制分析。
6.3.1 构建代码
首先,我们来看一下构建反汇编代码的各种方法。笼统地说我将向你展示两种使得代码更易于分析的代码结构。
(1)分块:将代码分成逻辑连接的块,可以更轻松地分析每个块的功能和代码块之间的关系。
(2)揭示控制流:接下来讨论的这种代码结构不仅表达了代码自身,还很直观地表达了代码块之间的控制流转移,从而更容易快速地查看控制流如何在代码中流动,增加对代码的理解。
下面的代码结构在自动化和手动分析中都有非常重要的作用。
1.函数
在大多数高级编程语言中,如C、C++、Java、Python等,函数是用于对逻辑连接的代码进行分组的基本构建块。众所周知,结构良好且正确划分函数的程序比结构性较差的、含“意大利面条式的代码”的程序更易于理解,所以大多数反汇编工具会花费很大力气来恢复原始程序的函数结构,并对反汇编的指令按照函数进行分组,这就叫函数检测。函数检测不仅仅有助于我们的逆向工程师理解代码,并且还有助于自动化分析,如在二进制自动化分析中,函数检测使我们可以按照函数级别搜索bug或者修改代码,在每个函数的开始和结束时进行特定的安全检查。
对于具有符号信息的二进制文件,函数检测很简单,符号表指定了函数集,以及它们的名称、起始地址和大小。不幸的是,许多二进制文件的这些信息都被剥离了,这使得函数检测更具挑战性。源代码中的函数放到二进制文件里面是没有任何实际意义的,因为在编译过程中它们的边界可能变得很模糊,特定函数的代码甚至不会连续排列在二进制文件里面,函数的各种细节可能散落在代码段的各个部分,甚至可以在函数之间共享代码块,这也被称为代码块重叠。在实践中,大多数反汇编工具都假设函数是连续的,并且相互间不共享代码,在很多情况(并非所有情况)下这是成立的,但如果分析的是诸如系统固件或者嵌入式系统的代码,那么这是不成立的。
反汇编工具用于函数检测的主要策略基于函数签名,函数签名通常是在函数开始或结束时使用的指令模式。所有递归反汇编工具,包括IDA Pro都使用此策略。像objdump这样的线性反汇编工具通常不进行函数检测,除非符号可用。
通常来说,反汇编二进制文件通过基于签名的函数检测算法,来定位由call指令直接寻址的函数。对反汇编工具来说找出这些直接调用很容易,找出间接调用或者尾部调用的函数(tail-called)更具挑战性,[5]具有签名的函数检测器会查询已有的函数签名数据库来找出这些具有挑战性的函数。
函数签名模式包括已知的函数序言(用于设置函数栈帧的指令)和函数结尾(用于拆除栈帧),如许多x86编译器为未优化的函数生成的典型模式,开头的函数序言都是push ebp;mov ebp,esp,并且函数结尾是leave;ret。很多函数检测器会在二进制文件中扫描此类签名,并且用它们来识别函数的开始和结束位置。
尽管函数是构造反汇编代码最基础、有用的方法,但始终需要注意错误。在实践中,函数模式非常依赖于平台、编译器以及优化级别来创建二进制文件。优化后的函数可能完全没有已知的函数序言或者结尾,因此无法使用基于签名的方法来识别它们,导致函数检测经常发生错误,如在反汇编工具里面,经常会有20%或者更高概率出现函数起始地址错误的情况,甚至在不是函数的地方报告存在函数。
最近的研究探索了不同的函数检测方法,这些方法都不是基于签名的,而是基于代码结构的。尽管该方法可能比基于签名的方法更准确,但是检测错误依然存在。目前这种方法已经集成到Binary Ninja里面,原型研究工具可以与IDA Pro进行相互操作,所以可以尝试一番。
使用.eh_frame节进行函数检测
ELF二进制文件的函数检测有一种有趣的、基于.eh_frame节的替代方法,你可以使用它来解决函数检测遇到的问题。.eh_frame节包含与基于DWARF的调试功能有关(如栈展开)的信息,包括标识二进制文件中所有函数的函数边界信息。除非二进制文件是使用GCC的
-fno-asynchronous-unwind-tables标志编译的,否则该信息甚至存在于剥离的二进制文件中。.eh_frame主要用于C++的异常处理,当然还包括其他各种应用程序,如backtrace()、GCC内建函数__attribute__((__cleanup__(f)))及__builtin_return_address(n)。由于.eh_frame的用途广泛,因此默认情况下,不仅使用异常处理的C++二进制文件中存在.eh_frame,而且在GCC生成的所有二进制文件,包括纯C二进制文件中都存在.eh_frame。
据我所知,这种方法最初是由Ryan O’Neill(又名ElfMaster)提出的,其在网站上提供了代码,将.eh_frame节解析为一组函数地址和大小。
2.控制流图
在将反汇编后的代码分解为函数时,某些函数相当庞大,这意味着即使分析一个函数也可能是一项复杂的任务。为了组织每个函数的内部,反汇编工具和二进制分析框架使用另一种代码结构,该代码结构称为控制流图(Control-Flow Graph,CFG)。CFG可用于自动化分析和手动分析,同时还提供了方便的代码结构表示图形,使你一眼就可以轻松了解函数的内部结构。图6-5显示了使用IDA Pro反汇编函数的CFG示例。
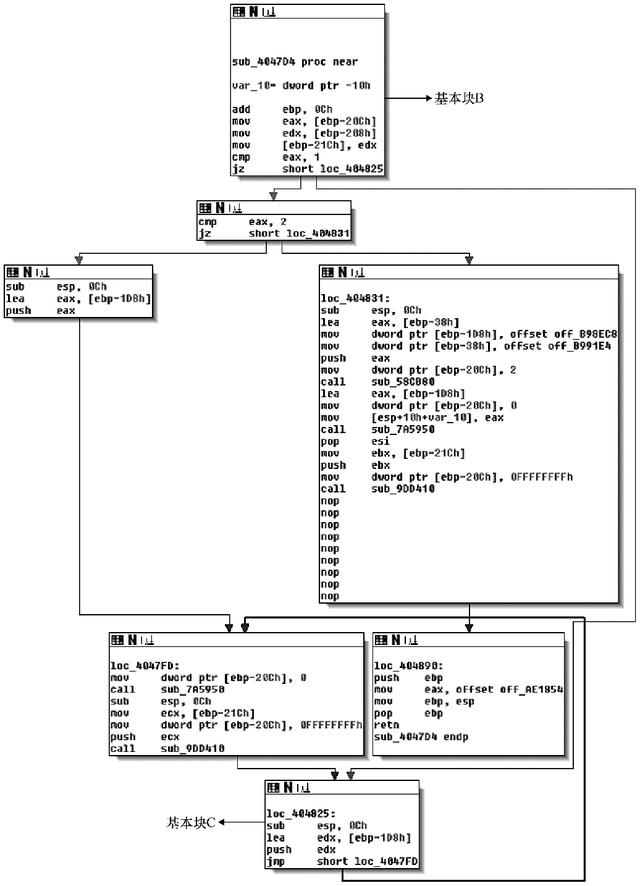
图6-5 使用IDA Pro反汇编函数的CFG示例
如图6-5所示,CFG将函数内的代码表示为一组代码块(称为基本块),这些代码块被分支边缘连接,图中用箭头表示。基本块就是一串指令序列,其中第一条指令是唯一的入口点,是二进制中必定要经过的指令,而最后一条指令则是唯一的出口点,是唯一可以跳转到其他基本块的指令。换句话说,你看不到任何一个带有箭头的基本块连接到除了第一条或最后一条指令外的其他任何指令。
在CFG中,基本块B指向基本块C的箭头意味着B中的最后一条指令可能会跳转到C的起始位置。如果B只有一个出口边缘,意味着它一定会将控制权转移到该边缘的目标代码,这就是间接跳转或者call指令后你将会看到的内容。如果B以条件跳转结束,它就会有两个出口边缘,而采用哪个出口边缘完全取决于运行时跳转条件的结果。
调用边缘不是CFG的一部分,因为它们的目标是函数外部的代码。相反,CFG只显示“fallthrough”边缘,该箭头指向函数调用完成后返回的指令。另外还有一种称为调用图的代码结构,该代码结构用箭头来表示call指令与函数之间的关系。下面我们来介绍一下调用图。
实际上,反汇编工具通常会从CFG中忽略间接调用,因为很难静态地解决此类调用的潜在目标。反汇编工具甚至还会定义全局CFG,而不是按每个函数定义CFG,这样的全局CFG称为过程间CFG(ICFG),因为实质上它是所有函数CFG的并集(过程是函数的另一种说法)。ICFG避免了易于出错的函数检测的需要,但其没有提供每个函数CFG所拥有的分隔优势。
3.调用图
调用图类似于CFG,不同之处在于调用图显示了调用地址与函数之间的关系,而不是基本块。换句话说,CFG向你展示控制流如何在函数内流动,而调用图则向你展示哪些函数可以相互调用。与 CFG 一样,因为无法根据给定的间接调用地址确定可以调用哪些函数,所以调用图通常会省略间接调用的箭头。
图6-6的左侧显示了一组函数(标记为
至
)以及它们之间的调用关系。每个函数由一些基本块(灰色圆圈)和分支边缘(箭头)组成,对应的调用图在该图的右侧。如图6-6的右侧所示,调用图包含每个函数的节点,并且箭头显示函数
可以调用
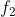
和

,函数
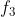
也可以调用
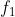
。尾部调用(实际上为跳转指令)在调用图中显示为常规调用,但是需要注意的是,从
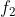
到
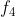
的间接调用未在调用图上显示。
IDA Pro还可以显示部分调用图,该图仅显示你所选择的特定函数的潜在调用者。对手动分析来说,部分调用图比完整调用图更有用,因为完整调用图通常包含太多消息。图6-7显示了IDA Pro中部分调用图的示例,其中显示了对函数sub_404610的引用。如图6-7所示,部分调用图显示了函数是从何处调用的,如函数sub_404610是被函数sub_4E1BD0调用的,而sub_4E1BD0又是被函数sub_4E2FA0调用的。
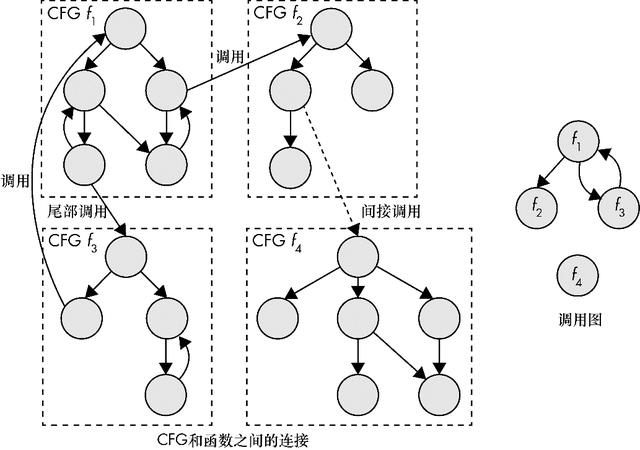
图6-6 CFG和函数之间的连接(左)与对应的调用图(右)
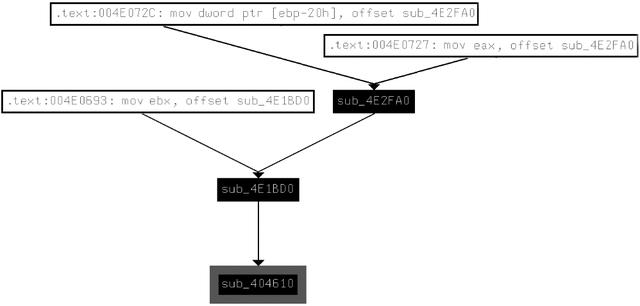
图6-7 IDA Pro中部分调用图的示例
另外,IDA Pro中部分调用图显示了将函数地址存储在某处的指令。如在.text节的地址0x4E072C处,有一条指令将函数sub_4E2FA0的地址存储在内存中,称为获取sub_4E2FA0函数的地址,而这个地址在代码中任意位置的函数称为地址获取函数(address-taken function)。
对我们来说,知道哪个函数是地址获取函数非常有用,因为即使不知道准确的函数地址,地址获取函数也会告诉你可以间接地调用它。如果某个函数的地址从来没有被获取,并且没有出现在任何数据节中,你就应该知道该函数不可能被间接调用。[6]这对某些二进制分析或者安全应用程序来说非常有用,如通过限制间接调用只能是合法的目标,来达到保护二进制文件的目的。
4.面向对象的代码
现实中你会发现许多二进制分析工具和功能齐全的反汇编工具(如IDA Pro),都是针对面向过程语言(如C)编写的程序。因为代码主要是通过使用这些语言中的函数来构造的,所以二进制分析工具和反汇编工具提供了诸如函数检测的功能,来恢复程序中的函数结构,并且通过调用图来检查函数之间的调用关系。
面向对象的语言(如C ++)是通过将连接的函数和数据逻辑分成各个类来构造代码的。面向对象语言通常还提供复杂的异常处理功能,该功能允许任何指令抛出异常,然后由处理该异常的特殊代码块来捕获异常。不幸的是,目前的二进制分析工具缺乏恢复类层次结构和异常处理结构的能力。
更糟糕的是,由于虚函数的实现,C++程序通常包含很多函数指针。虚函数允许在派生类中重写类方法(函数)。在经典实例中,你可以定义一个名为Shape的类,该类有一个名为Circle的派生类,并在Shape中定义了一个名为area的虚函数,该虚函数计算图形的面积,而Circle则通过适用于自身圆形的实现重写了该方法。
在编译C++程序时,编译器在运行时可能不知道指针到底是指向基本的Shape对象还是派生的Circle对象,因此它无法静态地确定在运行时应该使用area方法的哪种实现。为了解决此问题,编译器制定了称为vtable的函数指针表,其中包含了指向某个类的所有虚函数指针。vtable通常只保存在只读内存中,每个多态对象都有一个指向该对象类型的vtable指针(称为vptr)。为了调用虚函数,编译器会在运行时制定跟随对象vptr指针的代码,并且间接调用在vtable中的正确条目。不幸的是,所有的这些间接调用使程序的控制流变得更难跟踪。
一般来说,二进制分析工具和反汇编工具缺少对面向对象程序的支持,这意味着如果希望围绕类层次结构进行分析,就只能靠自己了。手动对C++程序进行逆向分析时,通常需要将属于不同类的函数和数据结构组合在一起,但这需要大量的工作。因为我们这里需要重点介绍关于(半)自动化二进制分析的内容,对C++逆向分析的内容不会进行过多介绍。如果对如何手动逆向分析C++代码感兴趣,建议你阅读埃勒达德·艾拉姆(Eldad Eilam)的著作《Reversing:逆向工程揭密》。
在二进制自动分析的情况下,你可以(如同大多数二进制分析工具)简单假设类不存在,并将面向对象语言的程序与面向过程语言的程序一样对待。而事实上,这种“解决方案”足以应对各种分析,除非确实有必要,否则你也不需要为实现一个特别的C++逆向支持插件而苦恼。
6.3.2 构建数据
如你所见,反汇编工具会自动识别各种类型的代码结构,帮助你进一步分析。不幸的是,数据结构却不能被自动识别,因为被剥离的二进制文件中的数据结构,想被自动化检测出来是一个众所周知的难题。除了网络上看到的一些研究[7]以外,反汇编工具基本不会去自动识别数据结构。
但是也有例外,如果将某个数据对象的引用传递给已知的函数,如库函数,类似IDA Pro的反汇编工具是可以根据库函数的规范自动推断数据类型的。图6-8显示了一个IDA Pro根据send函数的使用自动推断出数据类型的示例。
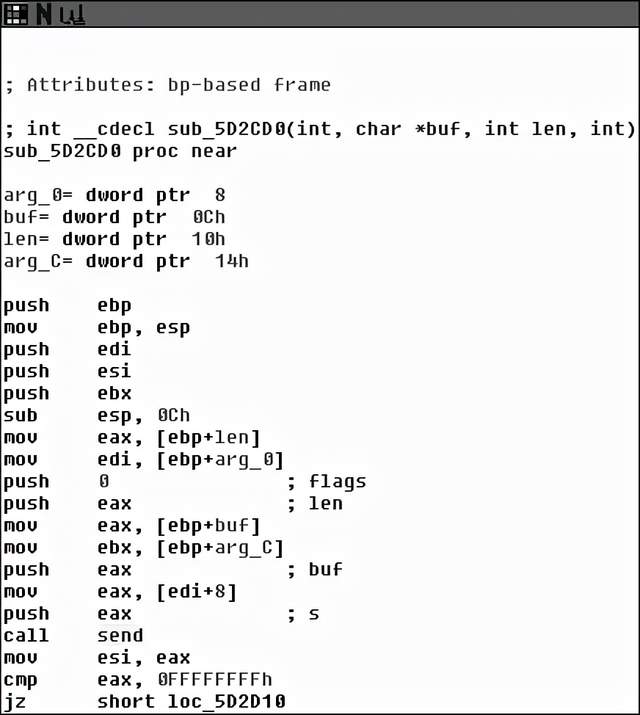
图6-8 IDA Pro根据send函数的使用自动推断出数据类型
在基本块底部附近,有一个通过网络发送消息的已知函数调用。因为IDA Pro知道send函数的参数,所以它可以标记参数名称(flags、len、buf、s),并且推断出用来加载参数的寄存器和内存对象的数据类型。
此外,原始类型可以通过保存的寄存器或处理数据的指令进行推断。如果你看到使用的是浮点寄存器或运算指令,说明这里的数据类型就是浮点型,如果你看到的是lodsb(加载字符串字节)或stosb(存储字符串字节)指令,那么这里很可能在进行字符串操作。
对于结构体或者数组之类的复合类型,所有猜测都没有用,你需要自己分析。作为解释很难自动化识别复合类型的一个示例,我们来看一下如何将下面的C代码编译为机器语言:
ccf->user = pwd->pw_uid;上面的代码来自nginx-1.8.0源代码中的一行,其中将某个结构体的整数字段分配给另一个结构体的字段。在优化级别为-O2的情况下使用GCC v5.1进行编译时,会生成以下汇编代码:
mov eax,DWORD PTR [rax+0x10]
mov DWORD PTR [rbx+0x60],eax现在我们来看下一行代码,该代码将堆分配的整数b复制到另一个数组a:
a[24] = b[4];下面是用GCC v5.1 优化级别-O2编译的结果:
mov eax,DWORD PTR [rsi+0x10]
mov DWORD PTR [rdi+0x60],eax从上面两个示例中可以看出,代码模式和结构体的分配完全相同!这表明,任何自动化分析都无法通过一系列这样的指令来判断它们的目的是数组查找、结构体访问,还是其他。这类问题的存在使得很难准确地检测复合数据类型,即使在一般情况下也几乎不可能。虽然上面的示例非常简单,但试想一下我们需要逆向一个包含结构体数组或者是嵌套的结构体,并且试图找出哪条指令索引了哪个数据结构,显然这是一项复杂的任务,需要对代码进行深入分析。由于准确识别这些非常规的数据类型的复杂度很高,所以反汇编工具根本不会对数据结构进行自动化检测。
为了便于手动构建数据,IDA Pro允许你自定义复合类型(通过逆向代码来推断),并且将它们分配给数据项。克里斯·伊格尔的《IDA Pro权威指南》(第2版)(人民邮电出版社,2012年)是使用IDA Pro手动逆向数据结构的重要资源。
6.3.3 反编译
顾名思义,反编译工具就是尝试“逆向编译过程”的工具。它们通常从反汇编代码开始,然后将其翻译成高级语言,类似于C的伪代码。在逆向大型程序的时候,反编译工具很有用,因为反编译后的代码比许多汇编指令易于阅读。但是反编译工具仅限于手动逆向,因为反编译的过程太容易出错,无法为任何自动化分析提供可靠基础。尽管我们不会在本书中用到反编译的功能,但我们还是需要了解一下反编译后的代码的样子,如清单6-6所示。
这里使用的反编译工具是IDA Pro自带的插件Hex-Rays[8],清单6-6显示了图6-5所示函数用Hex-Rays反编译后的输出。
清单6-6 函数用Hex-Rays反编译后的输出
❶ void ** __usercall sub_4047D4<eax>(int a1<ebp>)
❷ int v1; // eax@1
int v2; // ebp@1
int v3; // ecx@4
int v5; // ST10_4@6
int i; // [sp+0h] [bp-10h]@3
❸ v2 = a1 + 12;
v1 = * (_DWORD * )(v2 - 524);
* (_DWORD * )(v2 - 540) = * (_DWORD * )(v2 - 520);
❹ if ( v1 == 1 )
goto LABEL_5;
if ( v1 != 2 )
❺ for ( i = v2 - 472; ; i = v2 - 472 )
* (_DWORD * )(v2 - 524) = 0;
❻ sub_7A5950(i);
v3 = * (_DWORD * )(v2 - 540);
* (_DWORD * )(v2 - 524) = -1;
sub_9DD410(v3);
LABEL_5:
;
* (_DWORD * )(v2 - 472) = &off_B98EC8;
* (_DWORD * )(v2 - 56) = off_B991E4;
* (_DWORD * )(v2 - 524) = 2;
sub_58CB80(v2 - 56);
* (_DWORD * )(v2 - 524) = 0;
sub_7A5950(v2 - 472);
v5 = * (_DWORD * )(v2 - 540);
* (_DWORD * )(v2 - 524) = -1;
sub_9DD410(v5);
❼ return &off_AE1854;
从清单6-6中可以看出,反编译后的代码比原始汇编代码更容易阅读,反编译工具会猜测函数的签名❶和局部变量❷。此外,使用C的常规运算符❸替代汇编助记符可以更直观地表示算术和逻辑运算。反编译工具还会尝试重建控制流的构造,如if/else的分支❹、循环❺、函数调用❻,以及C风格的return语句,从而更轻松地得知函数的最终结果❼。
尽管上述所有这些功能都很有用,但是请记住,反编译只不过是帮助你理解程序正在做什么的一款工具,反编译后的代码可能与原始代码相差甚远,甚至有明显错误,并且受到底层反汇编不准确和反编译过程本身不准确的影响。因此,在反编译的基础上进行更高级的分析通常不是一个好主意。
6.3.4 中间语言
诸如x86和ARM之类的指令集包含许多具有复杂语义的不同指令。在x86上,看似简单的指令(如add)也会产生副作用,如在eflags寄存器中设置状态标志,大量的指令及其产生的副作用使得二进制程序很难实现自动化分析。我们会在第10章~第13章看到,动态污点分析和符号执行引擎必须实现显式处理程序,以捕获其分析的所有指令的数据流语义,而准确地实现所有这些处理程序是一项艰巨的任务。
中间表示(Intermediate Representation,IR),又名中间语言,旨在减轻由此带来的负担。IR是一种简单的语言,可以作为x86和ARM等底层机器语言的抽象。目前流行的IR包括逆向工程中间语言(Reverse Engineering Intermediate Language,REIL)和VEX IR(在valgrind工具框架中使用的IR),还有一个名为McSema的工具,它可以将二进制文件转换为LLVM位码(也称为LLVM IR)。
IR语言将真实的机器码(如x86代码)自动转换为IR,该IR可以捕获所有机器码的语义,分析起来会简单很多。为了比较,REIL仅包含17条不同的指令,而x86则包含数百条指令,而且,诸如REIL、VEX和LLVM IR之类的语言可以明确表达所有指令操作,而不会产生明显的指令副作用。
从低级机器码到IR代码的转换需要大量工作,但是一旦完成,在转换后的代码上进行二进制分析就会简单很多。通常只需使用IR实现一次代码转换,而不必为每个二进制分析编写特定指令的处理程序。此外,你可以为许多ISA(如x86、ARM及MIPS)编写转换器,并将它们全部映射到同一IR,这样在该IR上运行的任何二进制分析工具都会自动继承该IR对所有ISA的支持。
之所以将复杂的指令集(如x86)转换为简单的语言如REIL、VEX或者LLVM IR,是因为 IR 语言远比复杂指令集要简洁得多,这是用有限数量的简单指令表达复杂操作(包括所有副作用)的固有结果。对自动化分析(的计算机)而言,IR的理解通常不会有什么问题,但对个人来说,IR确实令人难以理解。这里为了让大家对IR有比较直观的认识,我们来看清单6-7,其显示了如何将x86-64指令add rax,rdx转换为VEX IR。
清单6-7 将x86-64指令add rax,rdx转换为VEX IR
❶ IRSB
❷ t0:Ity_I64 t1:Ity_I64 t2:Ity_I64 t3:Ity_I64
❸ 00 | ------ IMark(0x40339f, 3, 0) ------
❹ 01 | t2 = GET:I64(rax)
02 | t1 = GET:I64(rdx)
❺ 03 | t0 = Add64(t2,t1)
❻ 04 | PUT(cc_op) = 0x0000000000000004
05 | PUT(cc_dep1) = t2
06 | PUT(cc_dep2) = t1
❼ 07 | PUT(rax) = t0
❽ 08 | PUT(pc) = 0x00000000004033a2
09 | t3 = GET:I64(pc)
❾ NEXT: PUT(rip) = t3; Ijk_Boring
如清单6-7所示,单条add指令就生成了10条VEX指令和一些元数据。首先,有些元数据可能是IR超级块(IR SuperBlock,IRSB)❶,它们对应着单条机器指令。IRSB包含4个标记为t0~t3的临时值,并且它们的类型均为Ity_I64(64位整数)❷。然后是IMark❸,该元数据表示机器指令的地址和长度。
接下来是对add指令进行建模的实际IR指令。首先,有两条GET指令从rax和rdx分别提取64位值,并临时存储到t2和t1中❹。需要注意,这里的rax和rdx只是这些寄存器在VEX状态建模的符号名称,VEX指令不会从真实的rax或者rdx寄存器中获取数据,而是从这些寄存器的VEX镜像状态中获取数据。为了执行实际的加法运算,IR使用VEX的Add64指令,将两个64位整数t2和t1相加,并将结果存储在t0中❺。
加法运算后,会有一些PUT指令模拟add指令的副作用,如更新x86状态标志位❻。然后,另一条PUT指令将相加后的结果存储到代表rax❼寄存器的VEX状态。最后,VEX IR模型将程序计数器(PC)更新为下一条指令❽。Ijk_Boring(jump kind boring)❾是一种控制流提示,表示add指令不会以任何有趣的方式影响控制流;因为add操作不属于任何分支,所以控制流只会“掉入”内存中的下一条指令;相反,分支指令可以使用诸如Ijk_Call或Ijk_Ret之类的提示标记,来通知分析正在发生调用或返回。
在现有二进制分析框架上实现工具时,通常来说无须处理IR,框架会在内部处理所有与IR相关的内容。然而,如果你打算自己实现二进制分析框架,或者修改现有的二进制分析框架,那么了解IR是很有必要的。
本文摘自《二进制分析实战》

如今,读者可以找到许多关于汇编的书籍,甚至可以找到更多有关ELF和PE二进制格式的说明。关于信息流跟踪和符号执行也有大量的文章。但是,没有哪本书可以向读者展示从理解基本汇编知识到进行高级二进制分析的全过程。也没有哪本书可以向读者展示如何插桩二进制程序、如何使用动态污点分析来跟踪程序执行过程中的数据或使用符号执行来自动生成漏洞利用程序。换句话说,直到现在,没有一本书可以教你二进制分析所需的技术、工具和思维方式。
以上是关于如何构建反汇编代码?的主要内容,如果未能解决你的问题,请参考以下文章