构建数据相似系统
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了构建数据相似系统相关的知识,希望对你有一定的参考价值。
一、基于共享码片构建(难度高)
??经调研,没有开源工具可以做共享代码构建,如Bindiff可以分析两个样本之间相似阈值和代码可视化,接口可以批量对样本进行相似分析,但仍是两个样本之间关联,无法做到多样本关联。
??共享代码定义:完整的反汇编(过滤系统API汇编代码),意图只保留病毒本身汇编(跟系统和其它无关),使用算法切割(类似于Minhash这种切割)。
应用价值:
??用法一:提取不同家族共享代码,通过算法产出代码聚类和结论,关联不同组织代码共性,完善情报分析(目前很多国外情报和安全公司使用的方法之一)。
??用法二:以不同家族为主节点,通过代码片段构建共享代码相似系统(匹配搜索系统)。
??用法三:共享代码数据可以提供给算法团队(如果他们有需求),用于数据建模和数据挖掘。
?
二、基于MInhash构建(难度折中)
??先尝试PE格式,如sys,dll,exe计算不同类型的Minhash,或直接构建样本集总Minhash。
应用价值:
??用法一:设置阈值大于0.8为相似样本,借助BinDiff批量对比筛选或人工根据文件类型对比,分析共享代码,完善情报分析。
emsp;
Hellsing和APT15之间效果图(100以内样本):
- Hellsing样本集生成数据库:
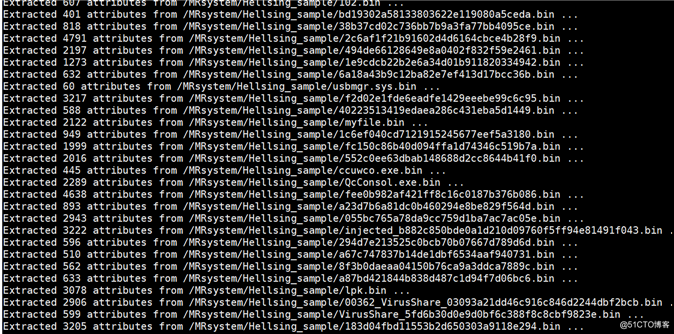
- 输入APT15样本集计算相似阈值,如果出现下述意味着没有命中:

- 以APT1为列子生成数据库,命中后如下:

#!/usr/bin/python
import argparse
import os
import murmur
import shelve
import sys
from numpy import *
from listing_5_1 import *
NUM_MINHASHES = 256
NUM_SKETCHES = 8
def wipe_database():
dbpath = "/".join(__file__.split(‘/‘)[:-1] + [‘samples.db‘])
os.system("rm -f {0}".format(dbpath))
def get_database():
dbpath = "/".join(__file__.split(‘/‘)[:-1] + [‘samples.db‘])
return shelve.open(dbpath,protocol=2,writeback=True)
def minhash(attributes):
minhashes = []
sketches = []
for i in range(NUM_MINHASHES):
minhashes.append(
min([murmur.string_hash(`attribute`,i) for attribute in attributes])
)
for i in xrange(0,NUM_MINHASHES,NUM_SKETCHES):
sketch = murmur.string_hash(`minhashes[i:i+NUM_SKETCHES]`)
sketches.append(sketch)
return array(minhashes),sketches
def store_sampledirectories(DirectPath):
for root, dirs, paths in os.walk(DirectPath):
for path in paths:
db = get_database()
attributes = getstrings(path)
minhashes,sketches = minhash(attributes)
neighbors = []
for sketch in sketches:
sketch = str(sketch)
if not sketch in db:
continue
for neighbor_path in db[sketch]:
neighbor_minhashes = db[neighbor_path][‘minhashes‘]
similarity = (neighbor_minhashes == minhashes).sum() / float(NUM_MINHASHES)
neighbors.append((neighbor_path,similarity))
neighbors = list(set(neighbors))
neighbors.sort(key=lambda entry:entry[1],reverse=True)
print ""
print "Sample name".ljust(64),"Shared code estimate"
for neighbor, similarity in neighbors:
short_neighbor = neighbor.split("/")[-1]
comments = db[neighbor][‘comments‘]
print str("[*] "+short_neighbor).ljust(64),similarity
for comment in comments:
print " [comment]",comment
def store_sample(path):
db = get_database()
attributes = getstrings(path)
minhashes,sketches = minhash(attributes)
for sketch in sketches:
sketch = str(sketch)
if not sketch in db:
db[sketch] = set([path])
else:
obj = db[sketch]
obj.add(path)
db[sketch] = obj
db[path] = {‘minhashes‘:minhashes,‘comments‘:[]}
db.sync()
print "Extracted {0} attributes from {1} ...".format(len(attributes),path)
def comment_sample(path):
db = get_database()
comment = raw_input("Enter your comment:")
if not path in db:
store_sample(path)
comments = db[path][‘comments‘]
comments.append(comment)
db[path][‘comments‘] = comments
db.sync()
print "Stored comment:",comment
def search_sample(path):
db = get_database()
attributes = getstrings(path)
minhashes,sketches = minhash(attributes)
neighbors = []
for sketch in sketches:
sketch = str(sketch)
if not sketch in db:
continue
for neighbor_path in db[sketch]:
neighbor_minhashes = db[neighbor_path][‘minhashes‘]
similarity = (neighbor_minhashes == minhashes).sum() / float(NUM_MINHASHES)
neighbors.append((neighbor_path,similarity))
neighbors = list(set(neighbors))
neighbors.sort(key=lambda entry:entry[1],reverse=True)
print ""
print "Sample name".ljust(64),"Shared code estimate"
for neighbor, similarity in neighbors:
short_neighbor = neighbor.split("/")[-1]
comments = db[neighbor][‘comments‘]
print str("[*] "+short_neighbor).ljust(64),similarity
for comment in comments:
print " [comment]",comment
if __name__ == ‘__main__‘:
parser = argparse.ArgumentParser(
description="""
Simple code-sharing search system which allows you to build up a database of malware samples (indexed by file paths) and
then search for similar samples given some new sample
"""
)
parser.add_argument(
"-l","--load",dest="load",default=None,
help="Path to directory containing malware, or individual malware file, to store in database"
)
parser.add_argument(
"-s","--search",dest="search",default=None,
help="Individual malware file to perform similarity search on"
)
parser.add_argument(
"-c","--comment",dest="comment",default=None,
help="Comment on a malware sample path"
)
parser.add_argument(
"-w","--wipe",action="store_true",default=False,
help="Wipe sample database"
)
parser.add_argument(
"-sd","--searchdir",dest="searchdir",default=None,
help="Input Other APT VirusDirectior,Filter hit"
)
args = parser.parse_args()
if len(sys.argv) == 1:
parser.print_help()
if args.load:
malware_paths = [] # where we‘ll store the malware file paths
malware_attributes = dict() # where we‘ll store the malware strings
for root, dirs, paths in os.walk(args.load):
# walk the target directory tree and store all of the file paths
for path in paths:
full_path = os.path.join(root,path)
malware_paths.append(full_path)
# filter out any paths that aren‘t PE files
malware_paths = filter(pecheck, malware_paths)
# get and store the strings for all of the malware PE files
for path in malware_paths:
store_sample(path)
if args.search:
search_sample(args.search)
if args.searchdir:
store_sampledirectories(args.searchdir)
if args.comment:
comment_sample(args.comment)
if args.wipe:
wipe_database()
?
三、基于其它”特征袋“构建(难度低-不使用)
问题(针对PE/ELF):
问题一:PE/ELF都会涉及加壳。
解决方案:压缩壳/有通用第三方脱壳工具可以调用接口脱壳,IAT加密/混淆/强壳直接丢弃(不参与Minhash计算和共享代码提取)。
问题二:MinHash算法是成熟/相对可靠,共享代码需要克服。
解决方案:自主实现,算法用成熟的python库尝试,通过优化不断提升。以上是关于构建数据相似系统的主要内容,如果未能解决你的问题,请参考以下文章