yolov5 解码使用GPU进行加速
Posted zsffuture
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov5 解码使用GPU进行加速相关的知识,希望对你有一定的参考价值。
YOLOv5原理方面这里不再过多阐述,直接从输出头开始,然后设计如编解码:
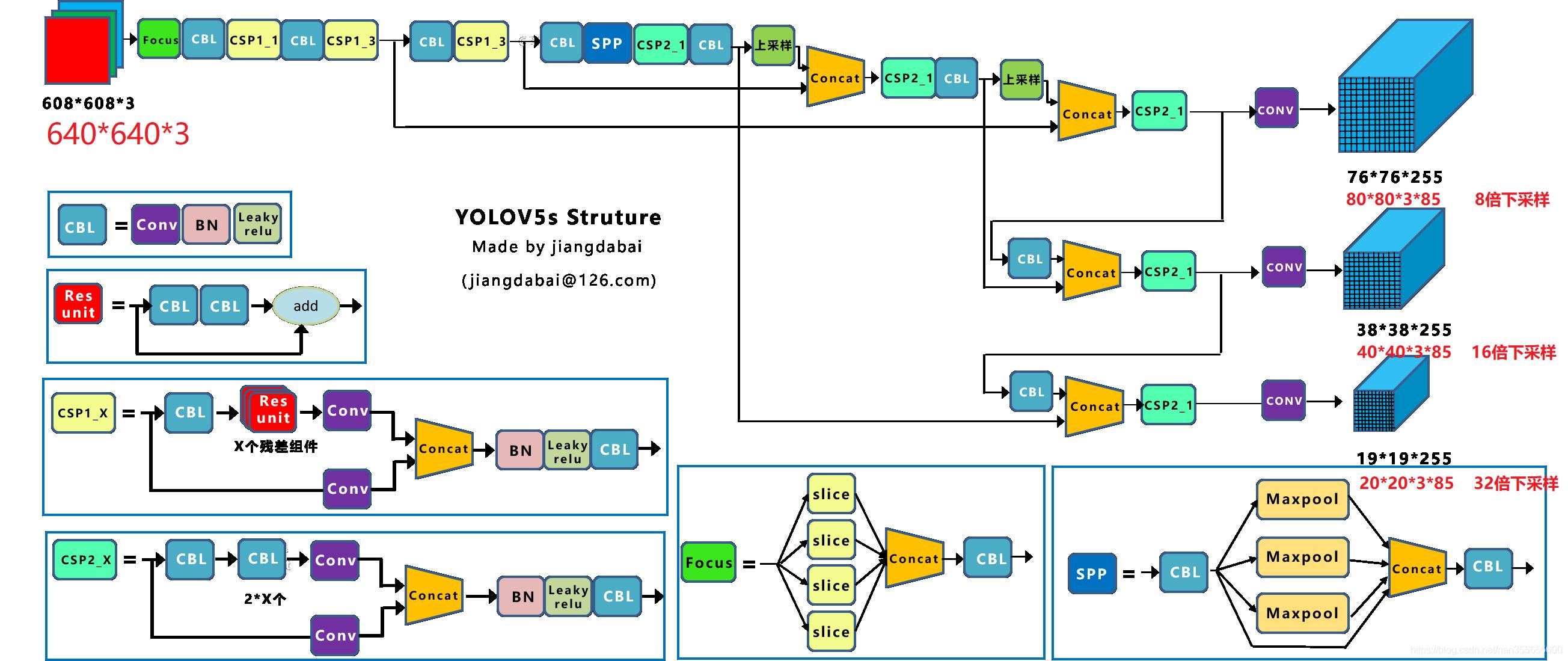
1.yolov5系列的原始输出是3个head头,上图画的是输入为608*608的分辨率的图,如果输入改为640*640分辨率的图片,那么输出的3个头分别对应三个8、16、32下采样的输出分别为80*80*255、40*40*255、20*20*255,其中对应的数字意义如上图所示。
2.那么 80*80*255、40*40*255、20*20*255数字分别代表什么意思,其中B是batch
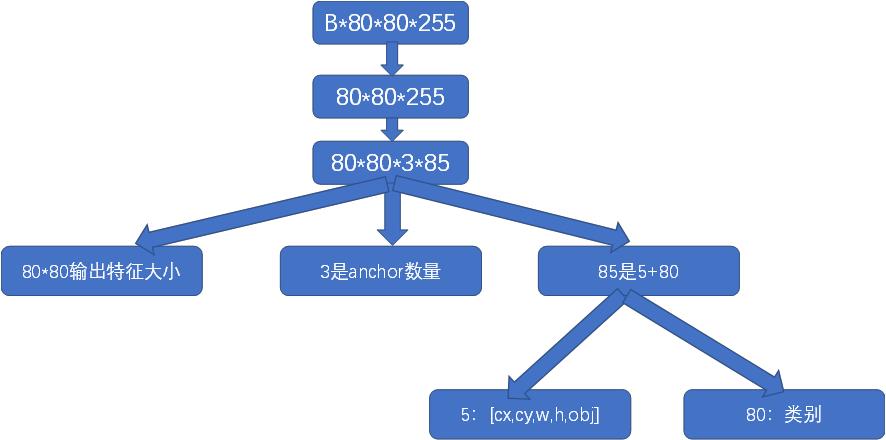
3 上图输出的3个head,并不是最终的输出,还需要做很多的工作,如果直接这样输出,后续代码解码很麻烦,因此需要进一步的处理这三个头,以此方便后面的代码进行解码操作,具体做以下工作:
3.1 需要做sigmoid激活函数
3.2 xy*2-0.5
3.3 (wh*2)**2*anchor
3.4 拿到640尺度下的框
从中可以看到需要很多种操作,很麻烦,可以让onnx来做,因此为了更好的在连续空间可以访问到,可以通过变换以下输出的通道,即原来的B*3*85*80*80,可以变换为B*3*80*80*85, 得到这样的tensor,可以很容易的进行操作,但是因为存在三个头,还是很麻烦,那么还可以继续合并,即B*19200*85,那么其他的三个头类似:

此时需要修改yolo导出的python代码使其支持onnx的导出:
其中修改python的代码在E:\\project\\c++\\yolov5-master\\models\\yolo.py
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x[i] = x[i].view(-1, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
# if self.inplace:
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)导出完成后的onnx应该为如下:
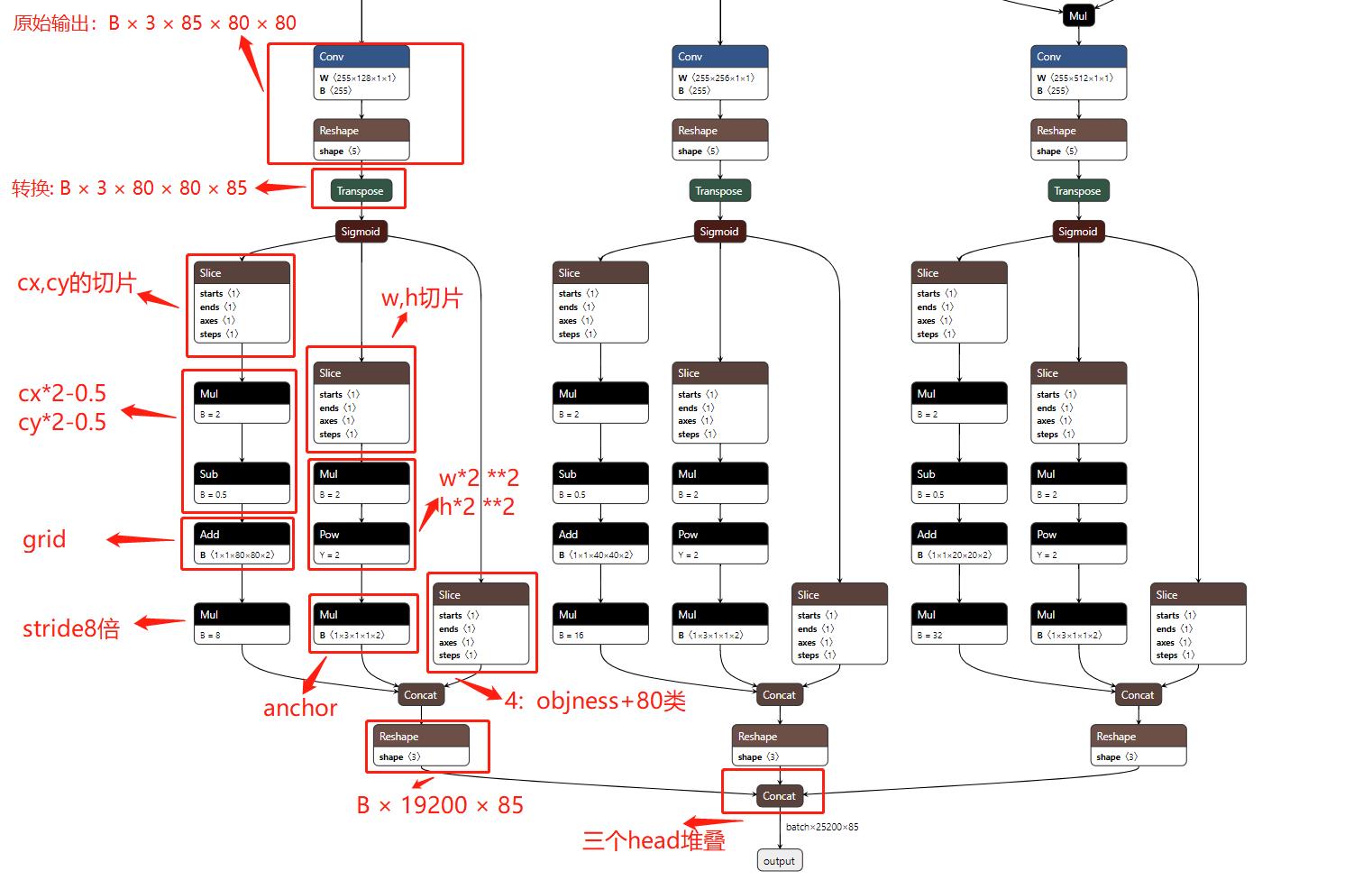
以上就是得到onnx前的工作,解码完成后应该使用tensorrt进行推理,整个代码在我的github中,
下面主要把关键的代码贴出来:
1.预处理核函数
/* 数据预处理 */
static __global__ void warp_affine_bilinear_and_normalize_plane_kernel(uint8_t* src, int src_line_size, int src_width, int src_height, float* dst, int dst_width, int dst_height,
uint8_t const_value_st, float* warp_affine_matrix_2_3, Norm norm, int edge)
/* 这里的warpaffine和python实现原理相同,不同的是这里的实现是通过cuda多线程实现,具体实现原理如下
* 这里需要确定的是这里为了尽量降低计算量,采用遍历目标图片的像素,显然目标图片的像素大小是确定的,无论输入的图片大小是多大
最后我都会变换到目标图片大小,如输入到深度学习模型的图片应该是640x640,原始图片的大小为1080x1920,显然遍历原始图片的计算很大
遍历目标的图片是固定的且不大,那么这个仿射变换如何做呢?
1. 首先输入的仿射变换矩阵是从原始图片的点--->目标图片的点,因此需要取逆变换获取到从目标图像的点--->原始图片的点
2. 当变换到原始图片的点位置时,将采用双线性变换的方法计算该点在原始位置的像素值
3. 如何计算呢?这里需要想明白,双线的本质是通过四个点的值计算一个点的值,那么变换到原始图片的点就是我们需要求的点值,
这个计算出来的值将直接赋值到目标图片对应位置,但是这四个点如何选取?其实很简单,就取相邻的四个点即可如:
(0,0) (1,0) (250,250) (251,250)
(0,1) (1,1) (250,251) (251,251)
这个四个点的选取就是变换过来的点的相邻四个点即可,如何做呢?上下取整即可如上面我举例两个点,
假如从目标的点变换到原始图片的点为(250.35,250.65),那么这个点正好在上面的四个点的范围内,计算相对位置就是(0.35,0.65)
然后通过双线性计算该点的值,把该点的值直接赋值目标待求点位置即可,理解到这一步基本就完全理解了
*/
/* 这里的理解和python版本理解类似,主要需要考虑的是CUDA的编程,集cuda的多线程代码
传入的edge就是线程的边界,即是所有任务的所需的线程
*/
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= edge) return;
/* 获取矩阵的相关参数 */
float m_x1 = warp_affine_matrix_2_3[0];
float m_y1 = warp_affine_matrix_2_3[1];
float m_z1 = warp_affine_matrix_2_3[2];
float m_x2 = warp_affine_matrix_2_3[3];
float m_y2 = warp_affine_matrix_2_3[4];
float m_z2 = warp_affine_matrix_2_3[5];
/* 因为数据的存储是一维的线性存储,因此需要通过计算获取目的图片的宽高界限 */
int dx = position % dst_width;
int dy = position / dst_width;
/* 通过目标的点计算得到在原始图片点的位置,需要对其进行源图像和目标图像几何中心的对齐。
float src_x = m_x1 * dx + m_y1 * dy + m_z1 + 0.5f;
float src_y = m_x2 * dx + m_y2 * dy + m_z2 + 0.5f;
*/
float src_x = m_x1 * dx + m_y1 * dy + m_z1;
float src_y = m_x2 * dx + m_y2 * dy + m_z2;
float c0, c1, c2;
/* 检查边缘情况,如果是边缘,直接赋常数值 */
if(src_x <= -1 || src_x >= src_width || src_y <= -1 || src_y >= src_height)
// out of range
c0 = const_value_st;
c1 = const_value_st;
c2 = const_value_st;
else
/* floorf(x) 获取不大于x的最大整数。其实这两就是取原始坐标的相邻的四个点 */
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
/* 下面就是计算插值的代码 */
uint8_t const_value[] = const_value_st, const_value_st, const_value_st;
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
uint8_t* v1 = const_value;
uint8_t* v2 = const_value;
uint8_t* v3 = const_value;
uint8_t* v4 = const_value;
if(y_low >= 0)
if (x_low >= 0)
v1 = src + y_low * src_line_size + x_low * 3;
if (x_high < src_width)
v2 = src + y_low * src_line_size + x_high * 3;
if(y_high < src_height)
if (x_low >= 0)
v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width)
v4 = src + y_high * src_line_size + x_high * 3;
/*
c0 = w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0];
c1 = w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1];
c2 = w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2];
*/
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
if(norm.channel_type == ChannelType::SwapRB)
float t = c2;
c2 = c0; c0 = t;
if(norm.type == NormType::MeanStd)
c0 = (c0 * norm.alpha - norm.mean[0]) / norm.std[0];
c1 = (c1 * norm.alpha - norm.mean[1]) / norm.std[1];
c2 = (c2 * norm.alpha - norm.mean[2]) / norm.std[2];
else if(norm.type == NormType::AlphaBeta)
c0 = c0 * norm.alpha + norm.beta;
c1 = c1 * norm.alpha + norm.beta;
c2 = c2 * norm.alpha + norm.beta;
/*
这里需要解释的是,因为传入的是float型的指针,同时因为数据的存储是一维的,这里作者把三通道进行分开存储,因此每个通道
占用的区域大小为area = dst_width * dst_height,后面就是分别把值填进去即可
*/
int area = dst_width * dst_height;
float* pdst_c0 = dst + dy * dst_width + dx;
float* pdst_c1 = pdst_c0 + area;
float* pdst_c2 = pdst_c1 + area;
*pdst_c0 = c0;
*pdst_c1 = c1;
*pdst_c2 = c2;
static void warp_affine_bilinear_and_normalize_plane(
uint8_t* src, int src_line_size, int src_width, int src_height, float* dst, int dst_width, int dst_height,
float* matrix_2_3, uint8_t const_value, const Norm& norm,
cudaStream_t stream)
/* 这里传入的jobs其实就是目标图片的宽高的乘积,目的是因为后面需要开启gpu加速,需要开启多线程,多线程的开启个数就是目的图片的宽高乘积 */
int jobs = dst_width * dst_height;
auto grid = grid_dims(jobs);
auto block = block_dims(jobs);
checkCudaKernel(warp_affine_bilinear_and_normalize_plane_kernel << <grid, block, 0, stream >> > (
src, src_line_size,
src_width, src_height, dst,
dst_width, dst_height, const_value, matrix_2_3, norm, jobs
));
2.解码核函数
const int NUM_BOX_ELEMENT = 7; // left, top, right, bottom, confidence, class, keepflag
static __device__ void affine_project(float* matrix, float x, float y, float* ox, float* oy)
*ox = matrix[0] * x + matrix[1] * y + matrix[2];
*oy = matrix[3] * x + matrix[4] * y + matrix[5];
/* 解码核函数 */
static __global__ void decode_kernel(float* predict, int num_bboxes, int num_classes, float confidence_threshold, float* invert_affine_matrix, float* parray, int max_objects)
/* 这里需要主要的是传入的参数num_bboxes就是25200, 这是3个head的输出concat的,如下:
* B × 3 × 85 × 80 × 80 --> B × 3 × 80 × 80 × 85 --> B × 19200 × 85
B × 3 × 85 × 40 × 40 --> B × 3 × 40 × 40 × 85 --> B × 4800 × 85 ----> B × 25200 × 85
B × 3 × 85 × 20 × 20 --> B × 3 × 20 × 20 × 85 --> B × 1200 × 85
由此可以看出就是我们onnx导出的输出,25200分别是3个head的concat,每一个就是特征图的点,这个一定要理解,
对应的是特征图二维的每个位置,,存储的方式是一维的,因此取数据就需要通过计算获取数据,这里B此时为1
*/
/* 开启25600个线程进行加速,但是实际只需要25200个线程进行加速处理 */
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= num_bboxes) return;
/*
这里应该很容易理解了,因为数据是 1 × 25200 × 85,在数据存储时是顺序存储的, 其中前25200个数据是开启的并行线程,也就是此时的25200是同时开始处理,
后面跟的就是对应的85个数据,但是这85个数据是进行一维数组存储的, 因此想要分别查找到对应的85就需要每个线程乘上85就可以找到
对应的起点了,好好思考
*/
float* pitem = predict + (5 + num_classes) * position;
/*
获取到每个线程对应点的85(5+80)数据起始位置后,分别进行提取对应的数据,objectness为对象obj置信度
*/
float objectness = pitem[4];
/* 如果小于设置的obj 置信度阈值,该线程返回 */
if(objectness < confidence_threshold)
return;
/* 在后面class_confidence就是类别的置信度,因为是80类,因此循环80次 */
float* class_confidence = pitem + 5;
float confidence = *class_confidence++;
int label = 0;
/* for循环的目的是获取80类中概率最大的那个类别 */
for(int i = 1; i < num_classes; ++i, ++class_confidence)
if(*class_confidence > confidence)
confidence = *class_confidence;
label = i;
/* 这个就是训练时损失有两个置信度相乘,这里也体现了一个是obj置信度另一个是类别置信度 */
confidence *= objectness;
/* 如果总的置信度还是小于阈值,直接返回 */
if(confidence < confidence_threshold)
return;
/* 反之说明该预测有效,需要保留相关数据 */
int index = atomicAdd(parray, 1);
if(index >= max_objects)
return;
/* 提取当前的85的前4个数据, 其实就是cx,cy,width,height */
float cx = *pitem++;
float cy = *pitem++;
float width = *pitem++;
float height = *pitem++;
/* 同时转换为左上角坐标点和右下角坐标点 */
float left = cx - width * 0.5f;
float top = cy - height * 0.5f;
float right = cx + width * 0.5f;
float bottom = cy + height * 0.5f;
/* 下面进行仿射反变换为原始图片下的坐标 */
affine_project(invert_affine_matrix, left, top, &left, &top);
affine_project(invert_affine_matrix, right, bottom, &right, &bottom);
/*
* NUM_BOX_ELEMENT是限制最多的bbox的大小
*/
float* pout_item = parray + 1 + index * NUM_BOX_ELEMENT;
*pout_item++ = left;
*pout_item++ = top;
*pout_item++ = right;
*pout_item++ = bottom;
*pout_item++ = confidence;
*pout_item++ = label;
*pout_item++ = 1; // 1 = keep, 0 = ignore
static __device__ float box_iou(
float aleft, float atop, float aright, float abottom,
float bleft, float btop, float bright, float bbottom
)
float cleft = max(aleft, bleft);
float ctop = max(atop, btop);
float cright = min(aright, bright);
float cbottom = min(abottom, bbottom);
float c_area = max(cright - cleft, 0.0f) * max(cbottom - ctop, 0.0f);
if(c_area == 0.0f)
return 0.0f;
float a_area = max(0.0f, aright - aleft) * max(0.0f, abottom - atop);
float b_area = max(0.0f, bright - bleft) * max(0.0f, bbottom - btop);
return c_area / (a_area + b_area - c_area);
static __global__ void fast_nms_kernel(float* bboxes, int max_objects, float threshold)
/* 开启的线程数最大为1024, 但是实际存在小于1024的情况,因此如下处理 */
int position = (blockDim.x * blockIdx.x + threadIdx.x);
/* 去线程数和实际bbox的最小值 */
int count = min((int)*bboxes, max_objects);
if (position >= count)
return;
/* 正常情况下,数组应该从0开始索引,但是因为存储时是float* pout_item = parray + 1 + index * NUM_BOX_ELEMENT;
* 因此取数据时也要这样取,先取出一组数据为pcurrent,拿这个和其他的bbox比较,
如果置信度大于当前值,就需要进行通过iou进行判定
*/
// left, top, right, bottom, confidence, class, keepflag
float* pcurrent = bboxes + 1 + position * NUM_BOX_ELEMENT;
for(int i = 0; i < count; ++i)
float* pitem = bboxes + 1 + i * NUM_BOX_ELEMENT;
/* 如果对比的是同一组数据或者不同类数据,跳过当前的bbox */
if(i == position || pcurrent[5] != pitem[5]) continue;
/* 反之处理的不是同一个bbox, 继续向下处理,如果pitem的置信度大于当前的置信度,则继续处理,反之跳过 */
if(pitem[4] >= pcurrent[4])
/* 如果置信度相同,直接跳过 */
if(pitem[4] == pcurrent[4] && i < position)
continue;
/* 如果置信度大于当前的置信度,则进一步通过iou进行处理 */
float iou = box_iou(
pcurrent[0], pcurrent[1], pcurrent[2], pcurrent[3],
pitem[0], pitem[1], pitem[2], pitem[3]
);
/* 如果计算出来的iou大于阈值,则当前的bbox失效,反之保持 */
if(iou > threshold)
pcurrent[6] = 0; // 1=keep, 0=ignore
return;
/* 最终通过bboxes[6]的状态进行确定即可 */
static void decode_kernel_invoker(float* predict, int num_bboxes, int num_classes, float confidence_threshold, float nms_threshold, float* invert_affine_matrix, float* parray, int max_objects, cudaStream_t stream)
/* 这里需要主要的是传入的参数num_bboxes就是25200, 这是3个head的输出concat的,如下:
* B × 3 × 85 × 80 × 80 --> B × 3 × 80 × 80 × 85 --> B × 19200 × 85
B × 3 × 85 × 40 × 40 --> B × 3 × 40 × 40 × 85 --> B × 4800 × 85 ----> B × 25200 × 85
B × 3 × 85 × 20 × 20 --> B × 3 × 20 × 20 × 85 --> B × 1200 × 85
由此可以看出就是我们onnx导出的输出,25200分别是3个head的concat,每一个就是特征图的点,这里需要强调因为输入的
图片是三通道的,因此是3*80*80,这个一定要理解,对应的是特征图二维的每个位置,,存储的方式是一维的,因此取数据就需要
通过计算获取数据
*/
auto grid = grid_dims(num_bboxes);
auto block = block_dims(num_bboxes);
/* 通过上面的分析可以发现,其每个位置都需要计算,因此需要开辟25200个线程 */
/* 如果核函数有波浪线,没关系,他是正常的,你只是看不顺眼罢了,下面进入解码核函数 */
checkCudaKernel(decode_kernel<<<grid, block, 0, stream>>>(predict, num_bboxes, num_classes, confidence_threshold, invert_affine_matrix, parray, max_objects));
/* 进行非极大值抑制,因为解码中最多输出1024个bbox,因此只需要开启最大的线程数为1024即可 */
grid = grid_dims(max_objects);
block = block_dims(max_objects);
checkCudaKernel(fast_nms_kernel<<<grid, block, 0, stream>>>(parray, max_objects, nms_threshold));
以上是关于yolov5 解码使用GPU进行加速的主要内容,如果未能解决你的问题,请参考以下文章
Wowza技术:使用NVIDIA CUDA硬件加速编解码时,如何在多个GPU之间实现负载均衡?
Mac Apple Silicon M1/M2 homebrew miniforge conda pytorch yolov5深度学习环境搭建并简单测试MPS GPU加速