通过云服务器租用GPU进行基于YOLOV5的人体检测模型训练
Posted 学算法的小猴子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过云服务器租用GPU进行基于YOLOV5的人体检测模型训练相关的知识,希望对你有一定的参考价值。
在学习的过程中,很多同学会因为没有带GPU的电脑影响了模型训练从而影响学习;此文详细介绍如何通过云服务器租用GPU进行模型训练,得到模型权重参数。
大家在身边没有GPU服务器,或者算力不够的情况下,也可以采用这些云端算力平台进行使用。本次课程采用的算力平台主要是AutoDL AI算力云,官网链接是:AutoDL-品质GPU租用平台-租GPU就上AutoDL。

1.点击右上角的“注册”选项先进行注册。
2.注册成功后,进入算力市场。可以看到不同区域,空闲的一些GPU服务器,每台服务器的显卡和算力都不相同,大家可以根据自己的需求进行选择。

3.可以看到不同区域,空闲的一些GPU服务器,每台服务器的显卡和算力都不相同,大家可以根据自己的需求进行选择。我们也可以看到,代金券这边刚申请的话,都是10元,可以让大家免费使用,我们训练一下Yolo数据集是够用了。
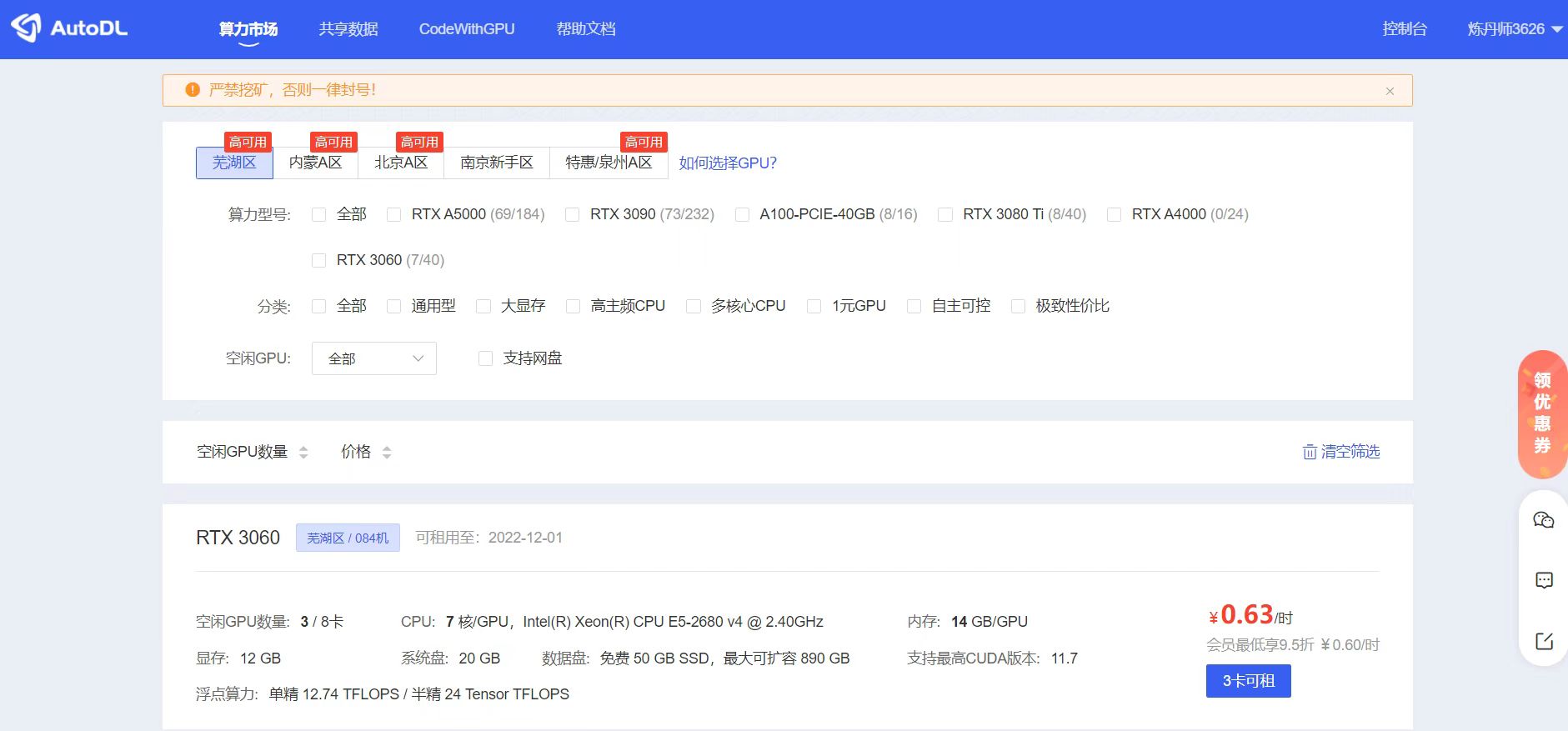
4. 查看符合条件的云网盘
因为后面训练都是在云服务器上,所以需要将数据集和代码都先上传到云服务器的网盘里面,后面就可以直接在上面操作。
不过大家在实例中可以看到,这里存在不同的地方设备。而且在云服务器网盘中,也有相应的不同地方。
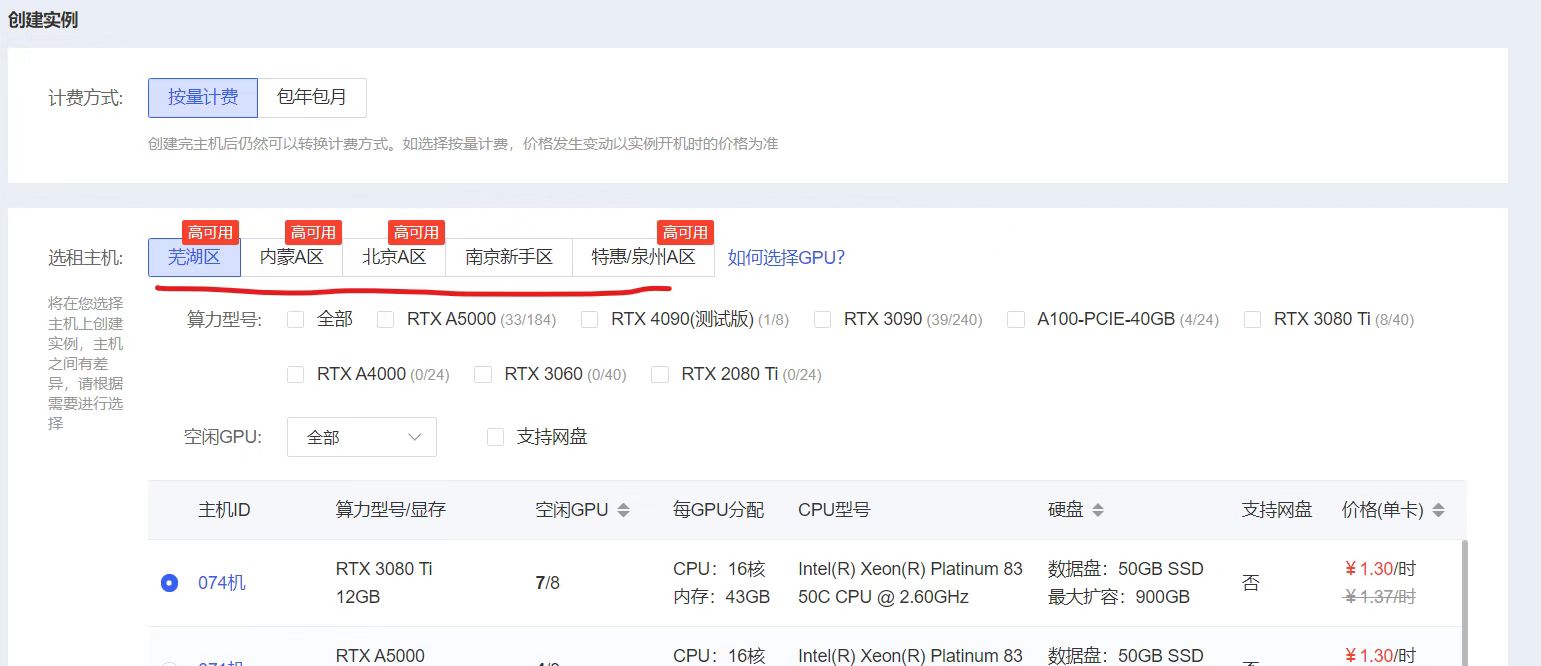
所以需要注意,我们首先查看以下实例中,哪些区域的算力设备,符合自己租赁的范围,再选择相应的地方的网盘,上传代码文件等。

比如大白这里使用的是内蒙的服务器,后面实例购买的时候,还是购买内蒙的实例,就可以在系统盘中直接找到相应的文件。如果后面再购买北京的实例,则在系统盘中,就找不到相应的数据文件。
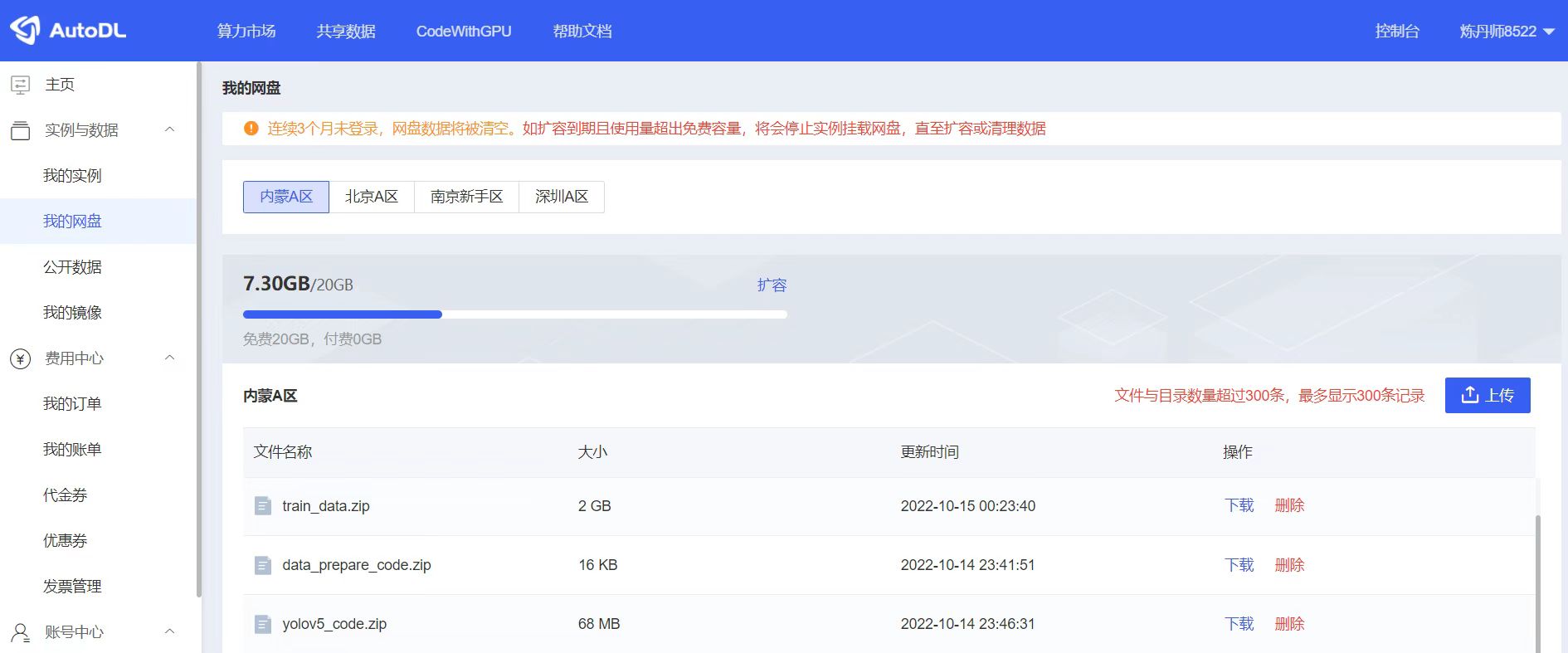
5 训练&验证集图片上传
我们再将前面的一些文件,传输到“我的网盘”里面。主要上传三个文件:
1)将train_data文件夹中的images_label_split文件夹删除,只留下刚刚划分的train和test文件夹。
为了上传方便,将train_data文件夹,压缩成一个train_data.zip。
2)数据集整理代码
将data_prepare_code文件夹,进行压缩,变成data_prepare_code.zip文件夹。
3)Yolov5训练代码
将Yolov5_code训练代码,进行压缩,变成yolov5_code.zip。
4)后台上传文件
点击AutoDL后台的我的网盘,将刚刚的三个zip文件进行上传,即以下图中的三个文件,当然可能网络原因,有的文件可以上传的会稍微慢一些。
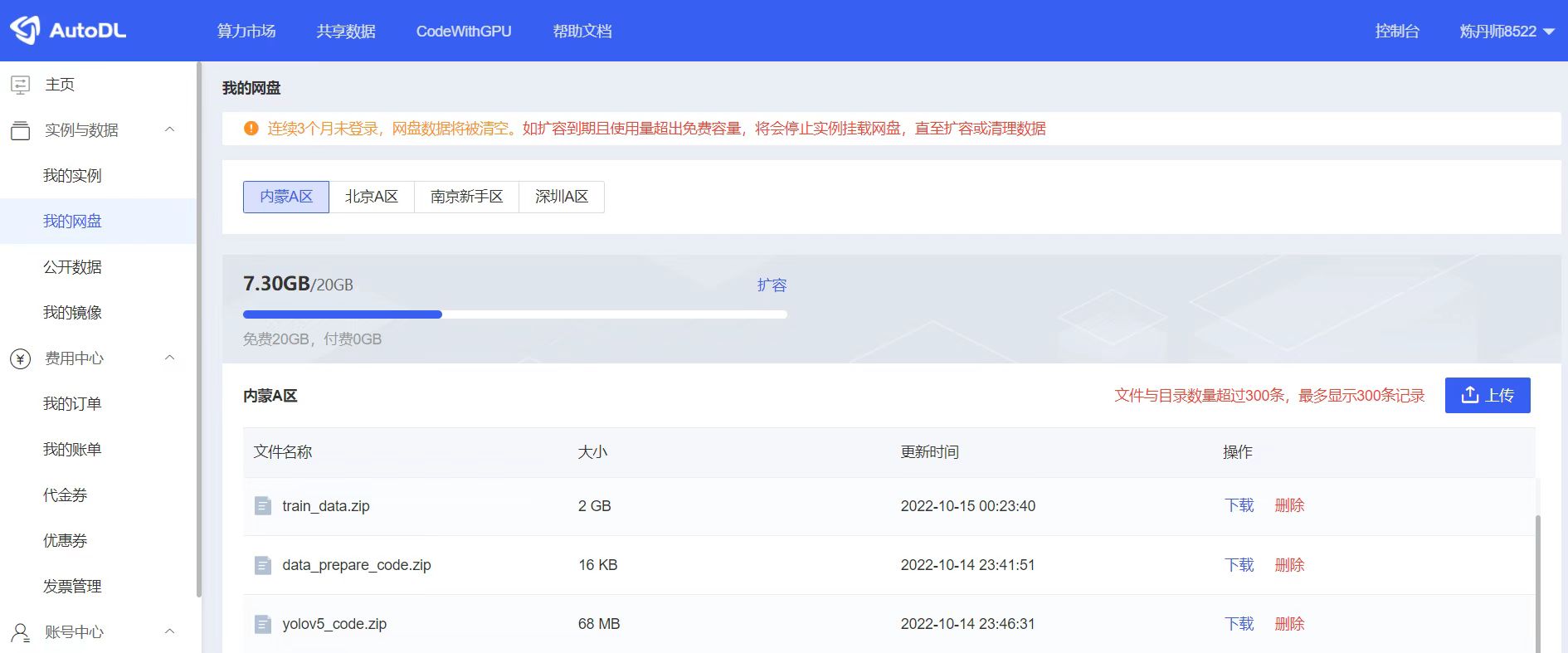
6 新建实例设备
到了这里,我们的代码、数据集都准备好了,就准备新建一个实例设备操作了。这里大白还是选择和网盘所对应的,内蒙A区的实例。
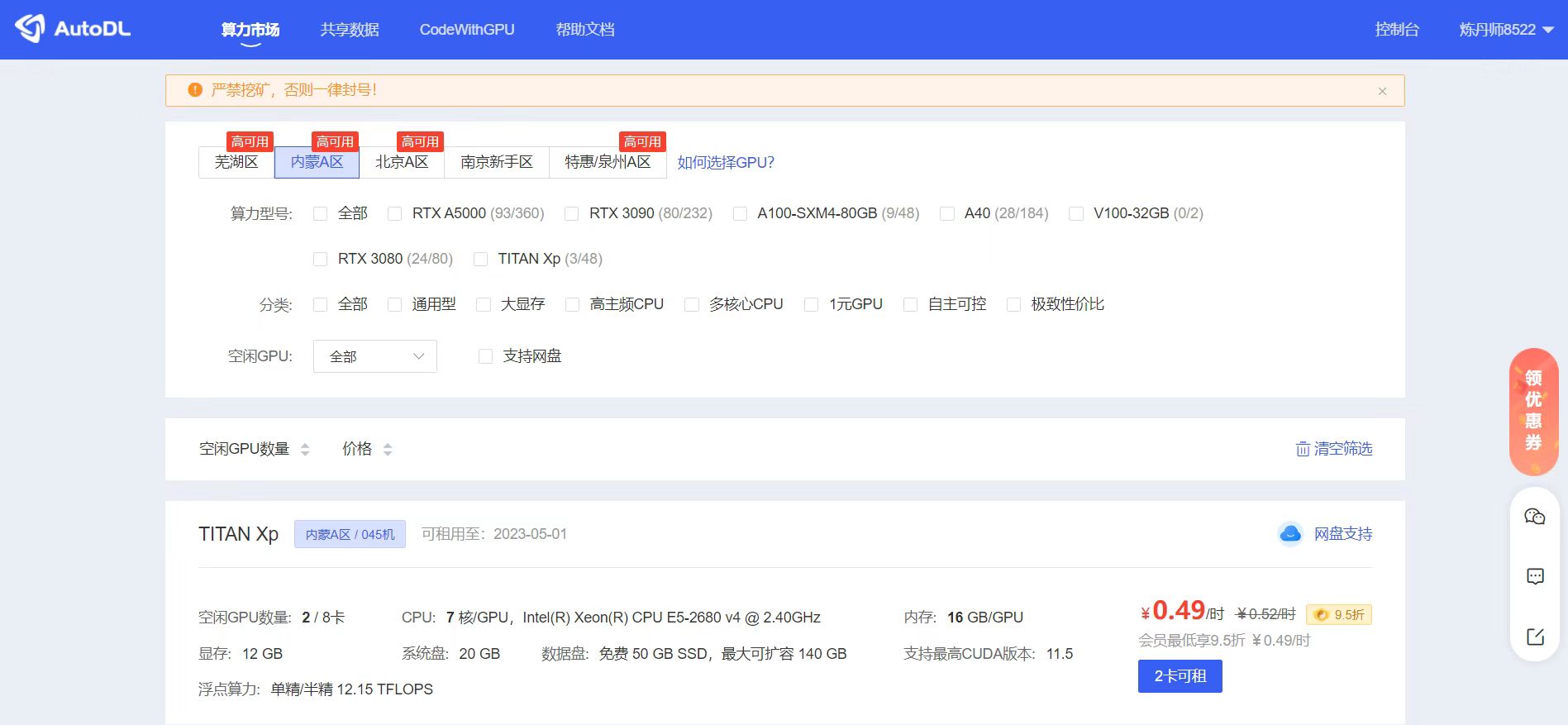
可以挑选自己选择一个GPU服务器,可以看到显示多少钱,这里展示的都是单卡的价格,有的设备必须要N卡一租的,可以看到对应的价格。

点击进入后,可以修改两个地方,一个是GPU数量,一个是新建实例的基础镜像。大白这里,GPU数量选择1,表示单卡。新建实例镜像,选择了Pytorch的版本。我们也可以看到最下方,有一个可用代金券,即表示我们可以先免费使用10元钱。
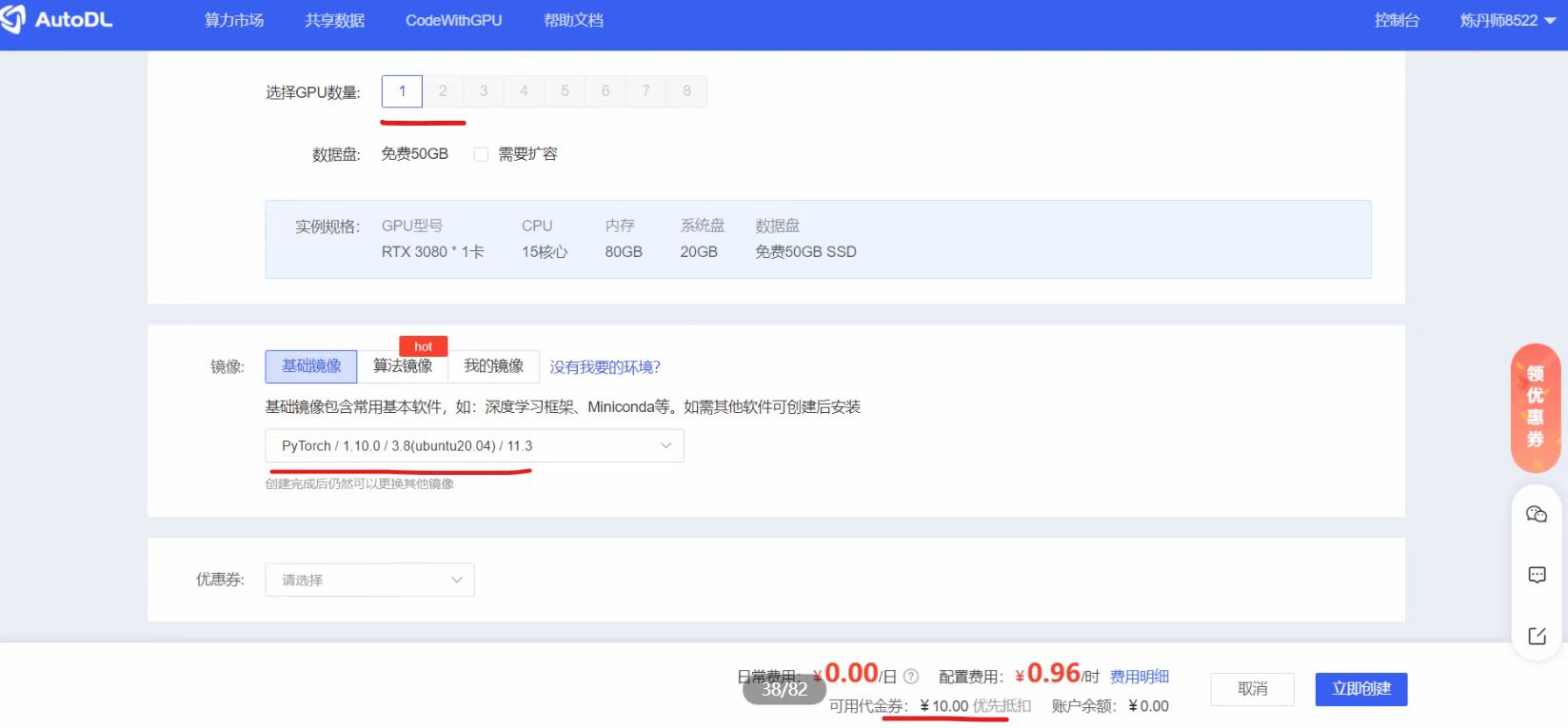
点击“立即创建”后,就可以看到创建的实例了。

点击右面的“JupyterLab”,可以进入控制台页面。可以点击下面的“终端”,打开一个终端页面,就可以进行操作了。

当然如果一个终端页面不够操作的话,可以点击左上方的“+”号,新增加几个终端页面。比如大白这里新建了4个终端页面。并且在上面,我们看到autodl-nas即我们刚刚使用的网盘。
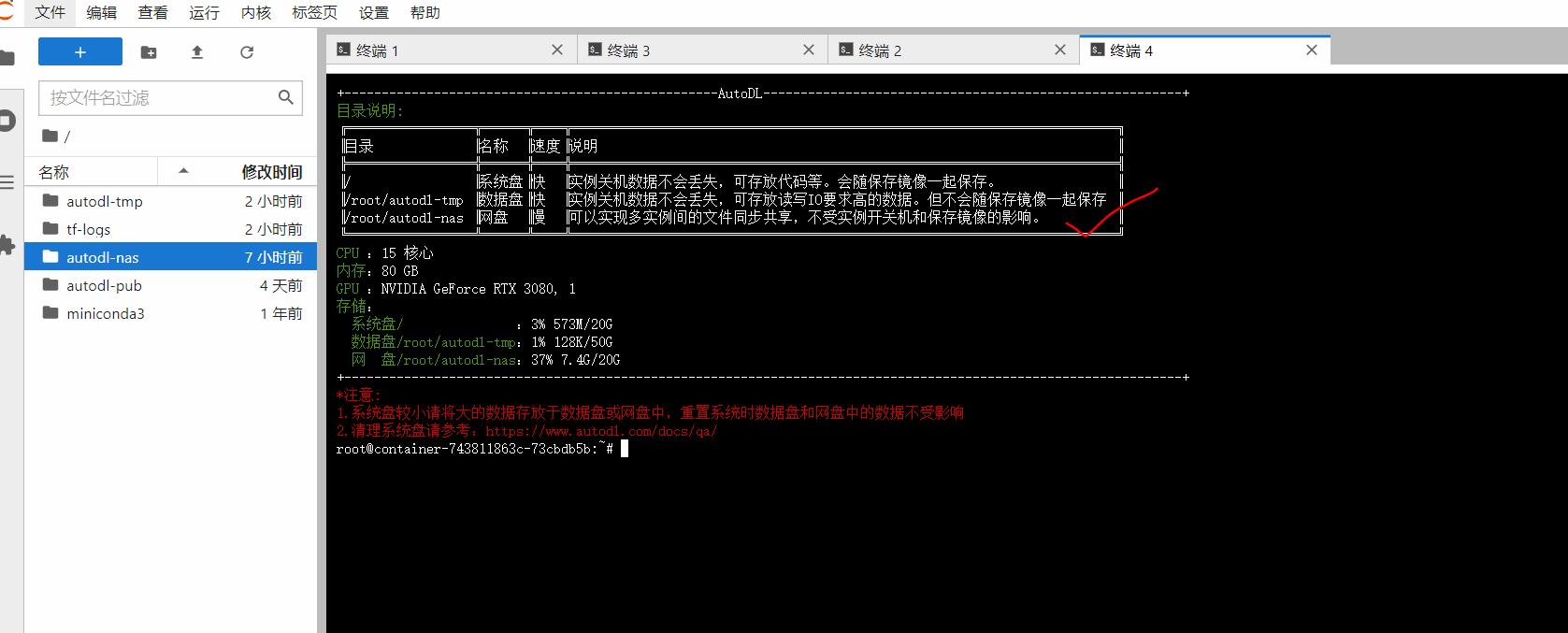
进入autodl-nas文件夹后,我们也可以看到,里面有刚刚新上传的三个zip文件。
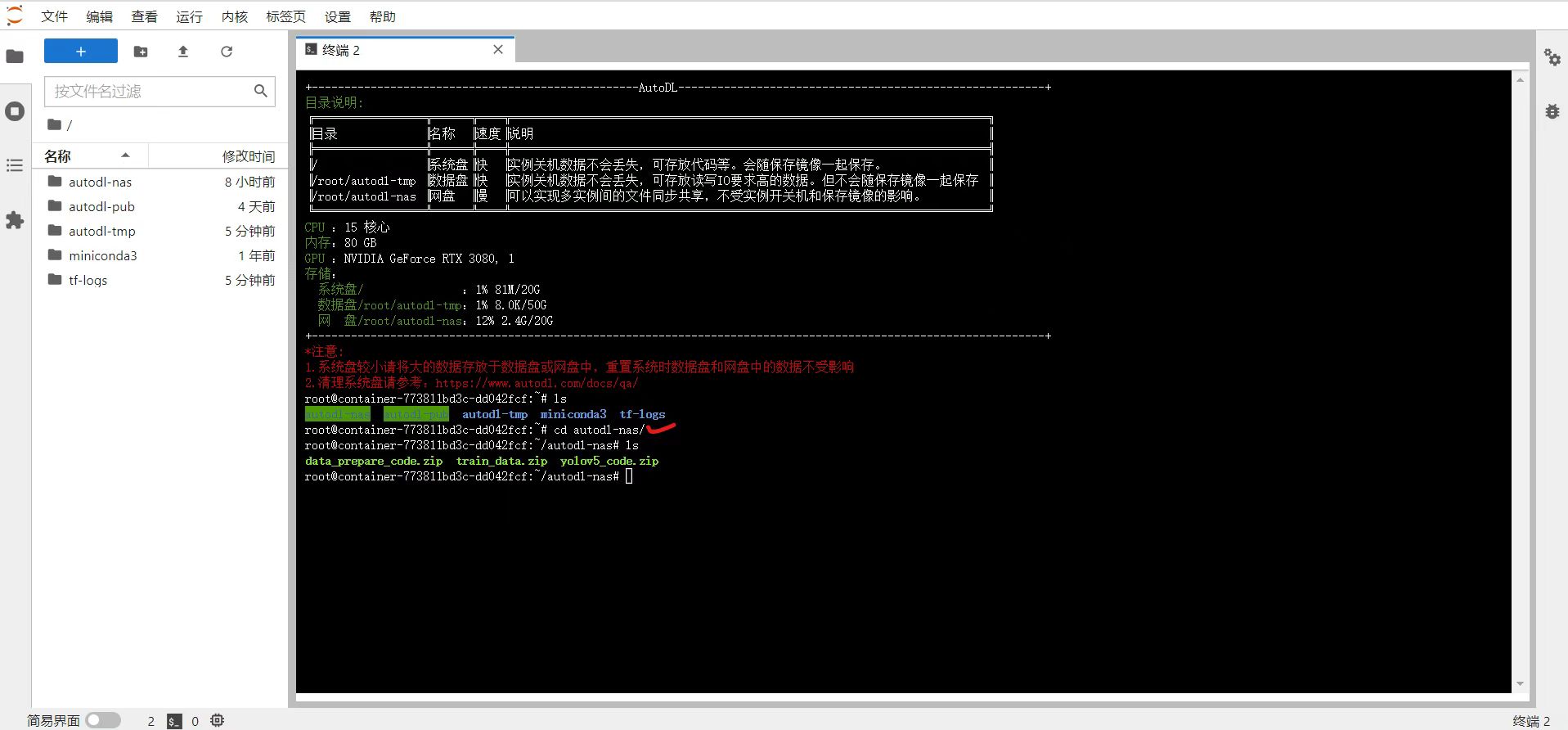
再将三个zip文件,使用unzip的方式进行解压。
最后可以看到,三个文件夹都被解压缩成功。
7.标注文件xml格式转换txt格式
先查看一下训练数据集train_data的路径,因为会涉及到转换后的txt路径,在云服务器上运行加训练。先cd train_data文件夹,再输入pwd,可以看到这时的数据集路径是:/root/autodl-nas/train_data。

然后再去修改代码中的路径,首先cd data_prepare_code文件夹里,再vim train_data_split.py,使用前面的阶段三中的代码,将标注的人体xml文件转换成txt文件。

vim train_data_split.py后,打开页面,拖到最下方,即这个部分。

按键盘上的“i”,进入代码的编辑状态,移动到路径处,修改成云服务器上对应的路径,大白这里是/root/autodl-nas/train_data,大家可以对应修改。
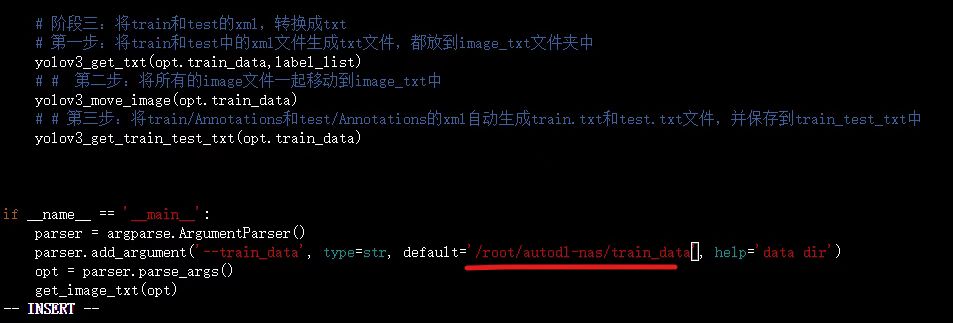
修改完成后,按键盘上的Esc键,跳出编辑状态。再输入“:”,会跳出输入框,再输入"wq!",表示对于该修改内容,保存编辑强制退出,回到原始页面。
因为云服务器我们刚刚新建实例的时候,没有安装任何安装包。所以先pip install opencv-python,安装一下。

将xml转换成txt格式进行中。

再进入train_data文件夹中,会发现多了两个文件夹,即训练时可以使用。

8.训练人体检测模型
训练人体模型,主要就用到/autodl-nas/yolov5_code文件了,不过在训练之前还要修改一下参数。
(1)新建person.yaml
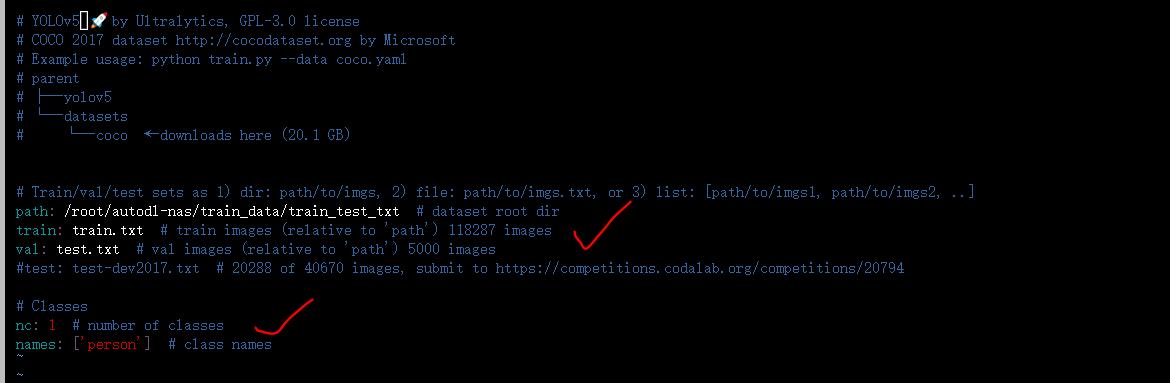
因为训练的是人体检测模型,所以在yolov5_code/data文件夹中,新增一个person.yaml。不过需要注意的是,训练集和验证集的路径都要修改一下,此外还有类别数,以及类别标签。
(2)修改train.py参数
而yolov5_code/train.py文件中,主要修改models初始化模型的路径,这里大白使用的yolov5n的模型权重。cfg即模型对应的网络结构路径,data是新增的person.yaml路径。此外还有epochs训练迭代的次数,batch-size大小,当然imgsz也可以修改,这里大白默认640。

(3)修改models/yolov5n.yaml
修改其中的类别数量,因为人体就一个类别,修改成1。
(4)训练人体检测模型
因为训练的时候,需要一系列的库文件,所以回到yolov5_code的路径下,输入 pip install -r requirements,安装一系列的库文件。
当然大家如果遇到tqdm安装的报错,可以输入pip install tqdm,看下有哪些版本,找对应的版本下载,如果没有报错,就可以直接跳过。
安装完成后,输入python train.py,就可以开始训练了。
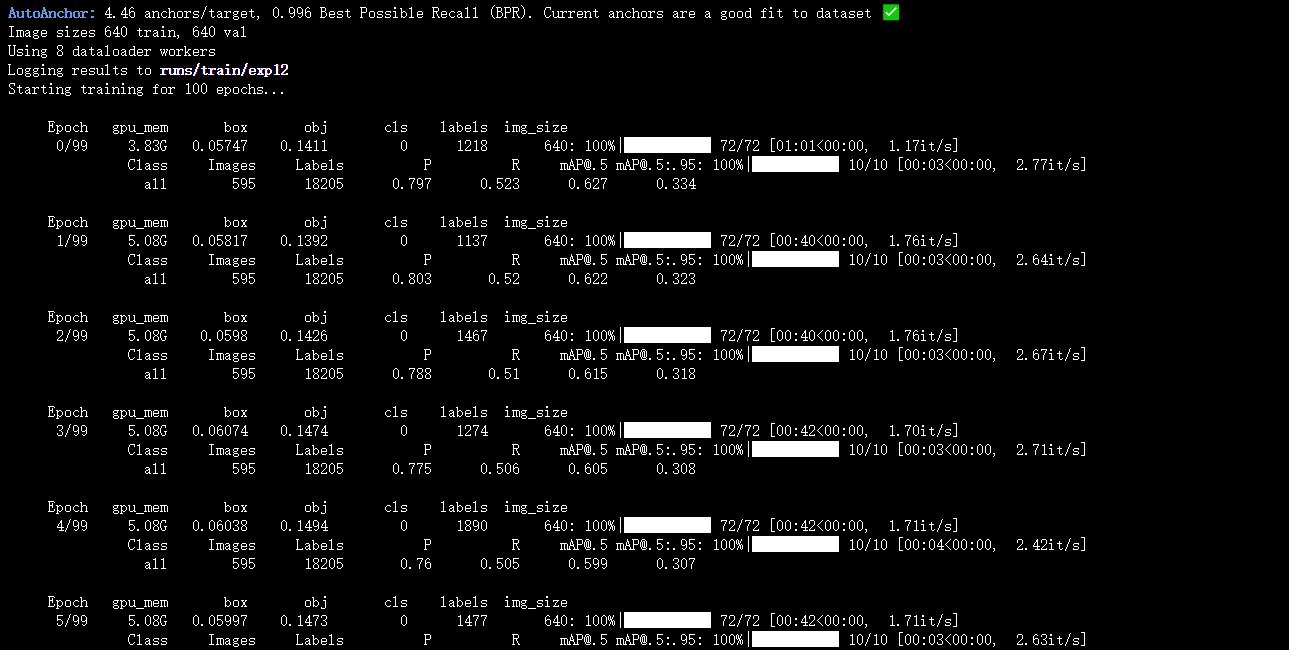
训练过程中,一般会得到两个模型,一个best.pt,即epoch迭代的过程中,map精度对比比较好保存的模型。一个是last.pt,即迭代过程中,最后一次epoch保存的模型。比如大白训练过程中,保存的这两个,在后面测试的时候,主要使用best.pt文件。

9 下载检测模型
在AutoDL的我的网盘,找到runs下面最新训练人体检测模型,路径可以参考:
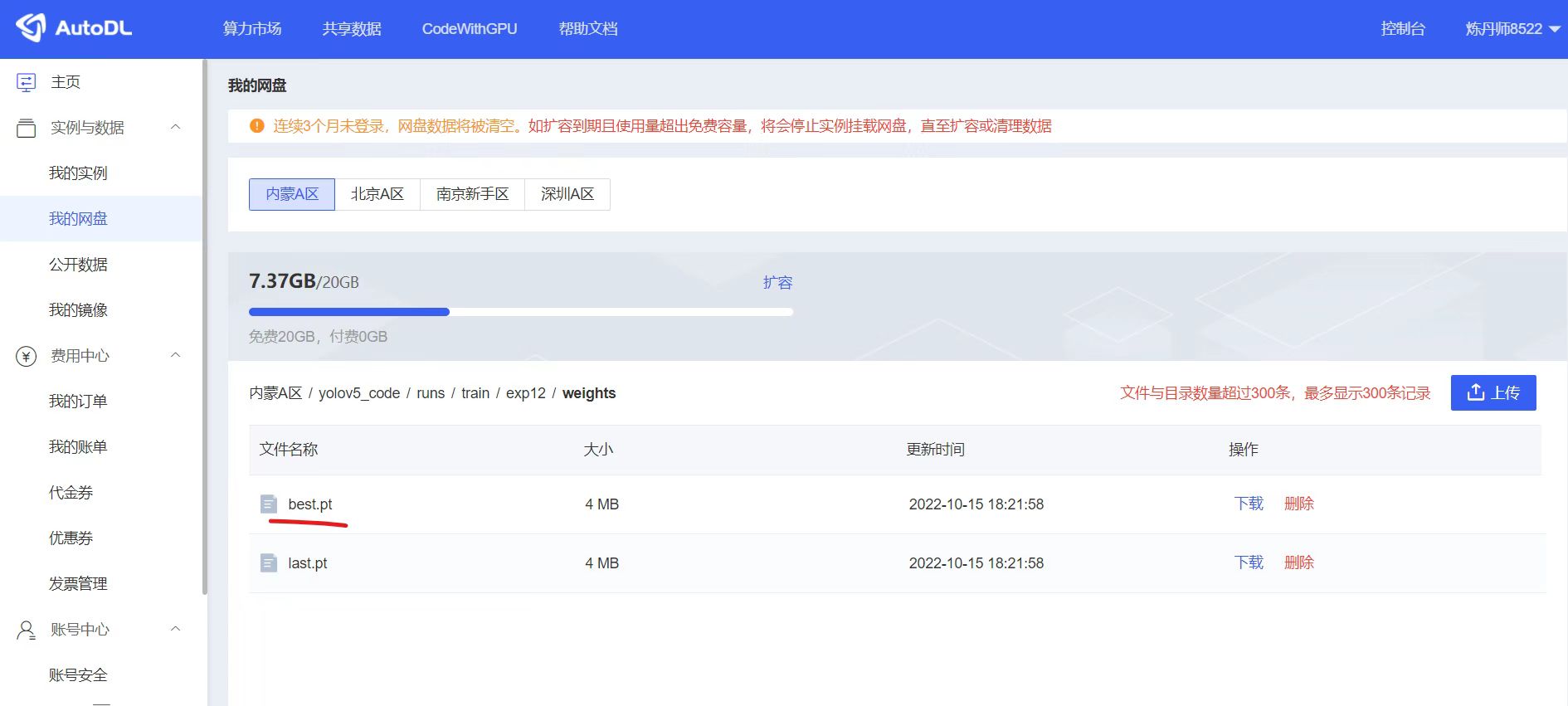
将best.pt模型下载下来,修改成yolov5n_best.pt。并放到资料包代码文件夹中。
得到训练结果以后,就可以将参数文件下载到本地中用于本地测试了。
以上是关于通过云服务器租用GPU进行基于YOLOV5的人体检测模型训练的主要内容,如果未能解决你的问题,请参考以下文章
Linux云GPU训练yolov5,conda开了一个虚拟的conda 环境,bypy使用,利用conda虚拟环境中的python