GPT 模型到底是怎么写作文的
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPT 模型到底是怎么写作文的相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
GPT-2 这样的大规模语言模型也能学会「句法」、生成新词,然而事情真要这么简单就好了。
深度学习到底能学多深?在过去的一段时间,我们大多会用生成文本的质量来评价 GPT 等语言生成模型的表现。但与此同时,我们忽略了一个问题:那些用生成模型做的「狗屁不通文章生成器」、「满分作文生成器」到底是鹦鹉学舌(简单地记住看过的例子,并以浅显的方式重新组合),还是真的学到了复杂的语言结构?
在最近的一篇文章中,来自约翰霍普金斯大学、微软研究院等机构的研究者就提出了这样一个问题。
神经网络语言模型可以生成合乎语法的连贯文本,但文本本身并不能告诉我们它是由模型构建的还是从训练集中抄的。论文作者认为,理清这一问题非常关键,因为除了已经成为标准的质量评估外,文本生成模型的新颖性评估也很重要。
为什么新颖性如此重要?首先,从语言学的角度来看,能够以新颖的方式将熟悉的部分组合起来是衡量语言掌握能力的一个关键要素。其次,从机器学习的角度来看,模型本来就应该学到训练分布,而不仅仅是把训练集记下来。最后,从更加实用的角度来看,那些只会复制训练数据的模型可能会泄露敏感信息,或重复仇恨言论。
在这篇论文中,为了评估生成文本的新颖性,研究者提出了一套名为「RAVEN(RAting VErbal Novelty)」的分析系统。分析指标包括序列结构(n-grams)和句法结构。「RAVEN」的名字来源于爱伦 · 坡的诗《乌鸦》,在这首诗中,叙述者遇到了一只神秘的乌鸦,它不断地叫着「永不复还(Nevermore)!」叙述者不知道乌鸦只是在重复人说的话,还是在构建自己的话语。
他们将这套系统应用于 LSTM、Transformer、Transformer-XL 以及四种尺寸的 GPT-2 生成的文本。因为有很多方法可以从语言模型中生成文本,所以他们测试了 12 种生成方法和 4 种 prompt 长度。作为基线,他们还分析了来自每个模型测试集的人工生成文本。
在实验中,研究者发现,上述模型在结构分析的每个方面都表现出了新颖性:它们生成了新的 n-grams、形态组合和句法结构。例如,GPT-2 生成了几种类型的新词,包括屈折变化(如 Swissified)、派生(IKEA-ness)等;在 Transformer-XL 生成的句子中,74% 的句子具有训练句子所没有的句法结构。因此,神经语言模型并不是简单地记住训练数据,而是使用某种流程,以一种新颖的方式将熟悉的部分组合起来。
其中,在考虑小 n-grams 时,这些模型生成的文本并没有 baseline 那么新颖。例如,对于每一个模型,人类生成的基线文本的新颖 bigram 数是模型的 1.4 到 3.3 倍。对于大于 5-gram 的 n-grams,模型的新颖性要高于基线,但它们偶尔也会大量复制:GPT-2 有时会复制超过 1000 词的训练文本。

论文链接:https://arxiv.org/pdf/2111.09509.pdf
目前,该论文的代码还没有公布,但作者表示,如果能得到其中几位作者的雇主的批准,他们将尽快公布代码。
方法概览
如上所述,研究者通过 n-grams 和句法结构来评估生成文本的新颖度。如果生成文本出现在训练集或上下文(「prompt」和「语言模型已经基于 prompt 生成的文本」之间的连结)中,该文本会被判定为复制文本,否则为新颖文本。
复制未必都是不好的。例如,一些很长的 n-grams 可能是从训练集中复制的,如书名。为了分辨这种情况,研究者将模型生成的文本与来自测试集的人工生成文本进行了比较,这样他们就能知道模型训练域中大约存在多少需要复制的文本。如果模型的新颖程度至少达到了基线的水平,研究者就判定它没有过度复制。
实验一:基于序列结构(n-grams)的新颖性分析
为了进行架构之间的受控比较,该研究使用了在同一个数据集上训练的三个模型,即 Wikitext-103(Merity et al.,2017)。Wikitext-103 是在词的级别进行分词的高质量维基百科文章集合,它的训练集包含 1.03 亿个词。研究者在该训练集上比较了 LSTM(Hochreiter and Schmidhuber,1997)、Transformer(Vaswani et al.,2017)和 Transformer-XL(TXL;Dai et al.,2019)架构。采用这三种模型是因为它们给出了语言建模中两种主要的处理类型:循环(在 LSTM 中使用)和自注意力(在 Transformer 中使用),TXL 同时用到了这两种机制。
除了这些系统分析之外,该研究还分析了更大规模的 Transformer LM——GPT-2(Radford et al.,2019),选用 GPT-2 是因为在能找到训练集的众多模型中,它的训练集是最大的。与实验中的其他模型不同,GPT-2 在 WebText 语料库上进行训练,该语料库由链接到 Reddit 上的网页构建而成。
GPT-2 的分词方案也不同于实验中的其他模型:其他模型均使用词级分词(其中每个 token 都是一个完整的词),而 GPT-2 使用子词(subword)分词方案(Sennrich et al.,2016)。WebText 训练语料库包含 77 亿个词,比 Wikitext-103 大得多。
该研究首先在 n-gram 层面研究各种模型的新颖性,其中 n-gram 是 n 个词的序列。
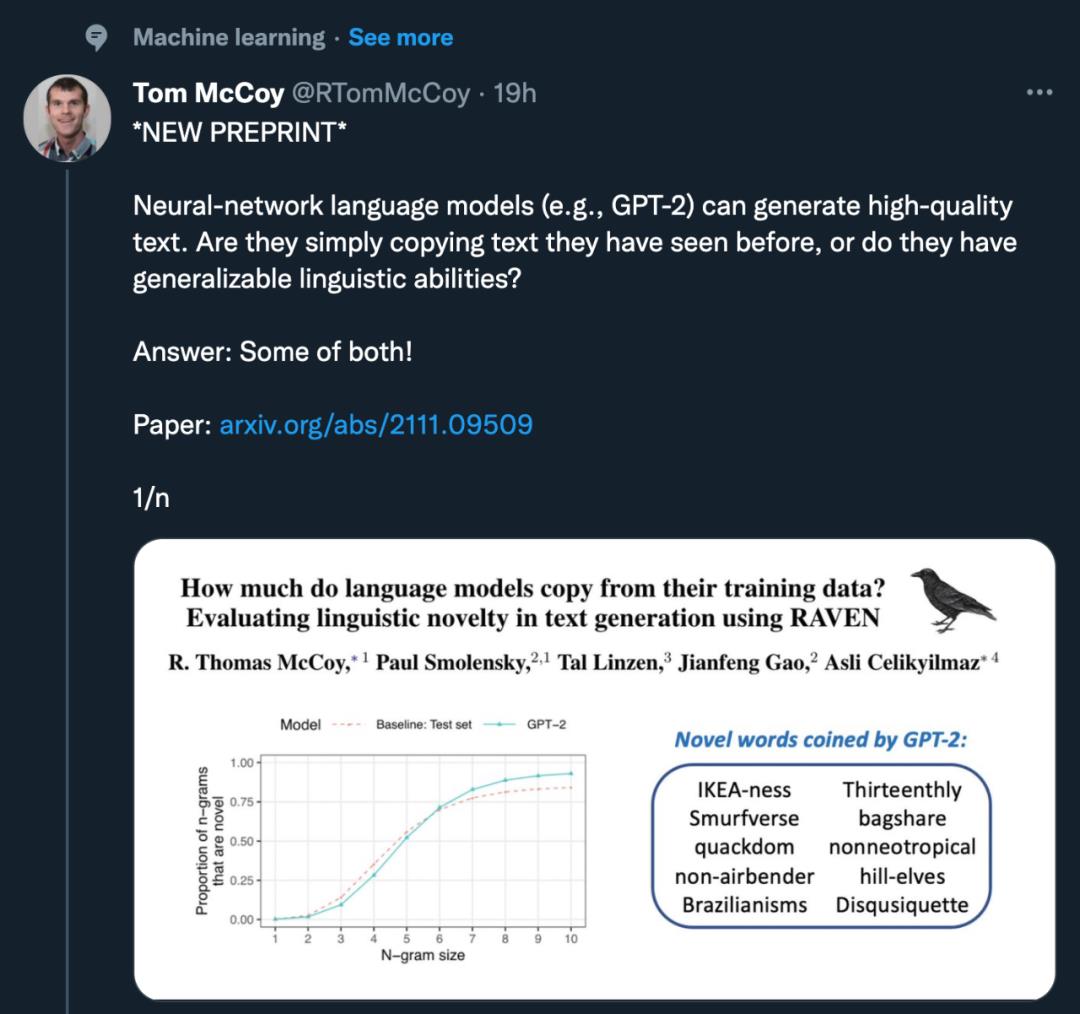
在 n 取不同的值时,模型生成文本的新颖性有何不同
该研究发现:对于较小的 n 值,LM 生成的 n-gram 很少是新颖的;而对于较大的 n 值 (n > 6),生成的 n-gram 几乎总是新颖的。
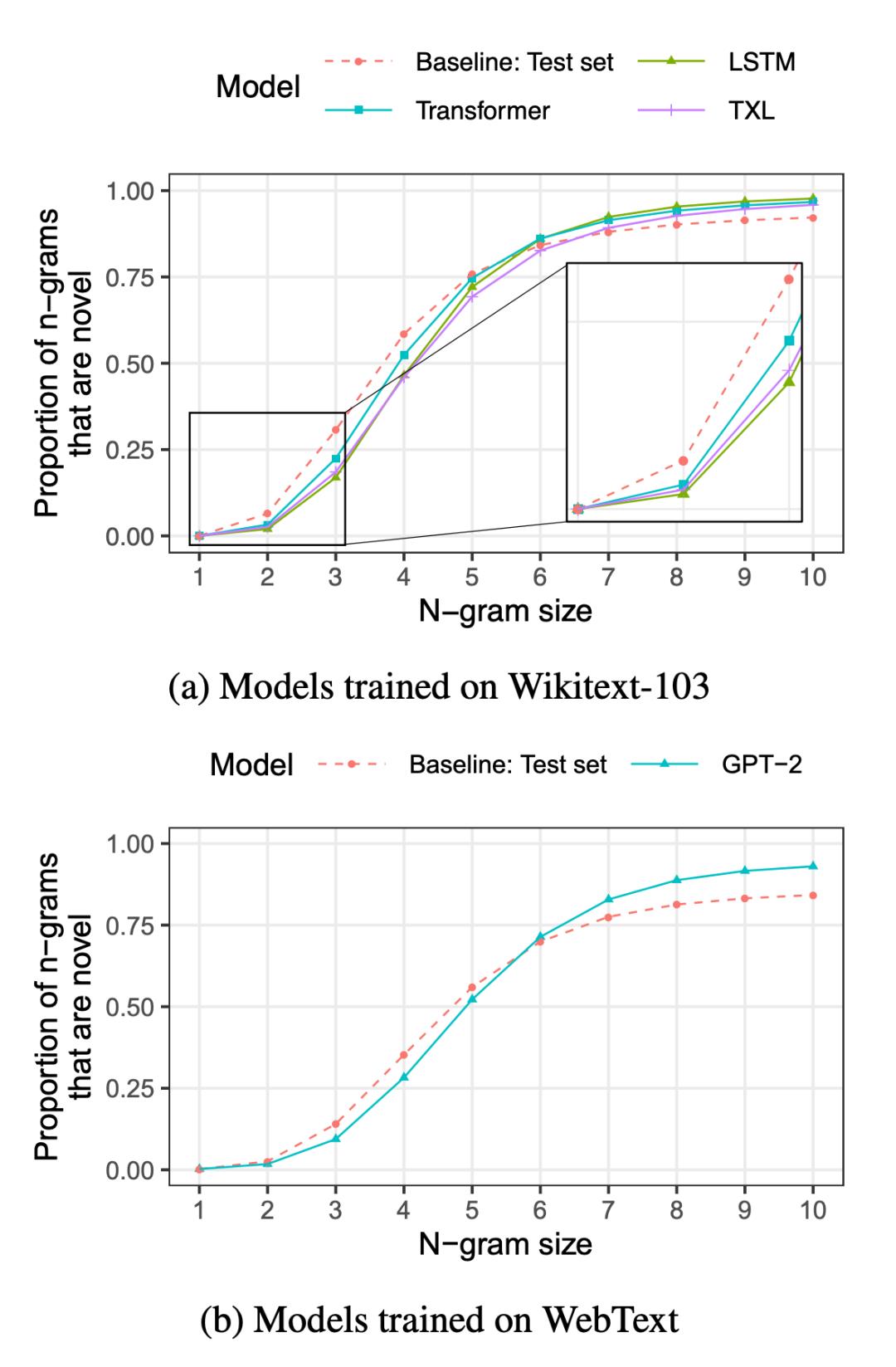
当 n 取值较大时,模型会复制文本吗?
该研究发现:所有的模型偶尔都会复制 100 词或更长的训练集段落。
具体来说,模型很少复制大于 10 个 token 的 n-gram。但是,偶尔会出现模型复制极长序列的情况。例如,在几种情况下,GPT-2 生成的文本中某个段落(超过 1000 个词)是完全复制训练集的。该研究使用「supercopying」指代这些极端复制情况(supercopying 指大小为 100 或更大的 n-gram 重复。
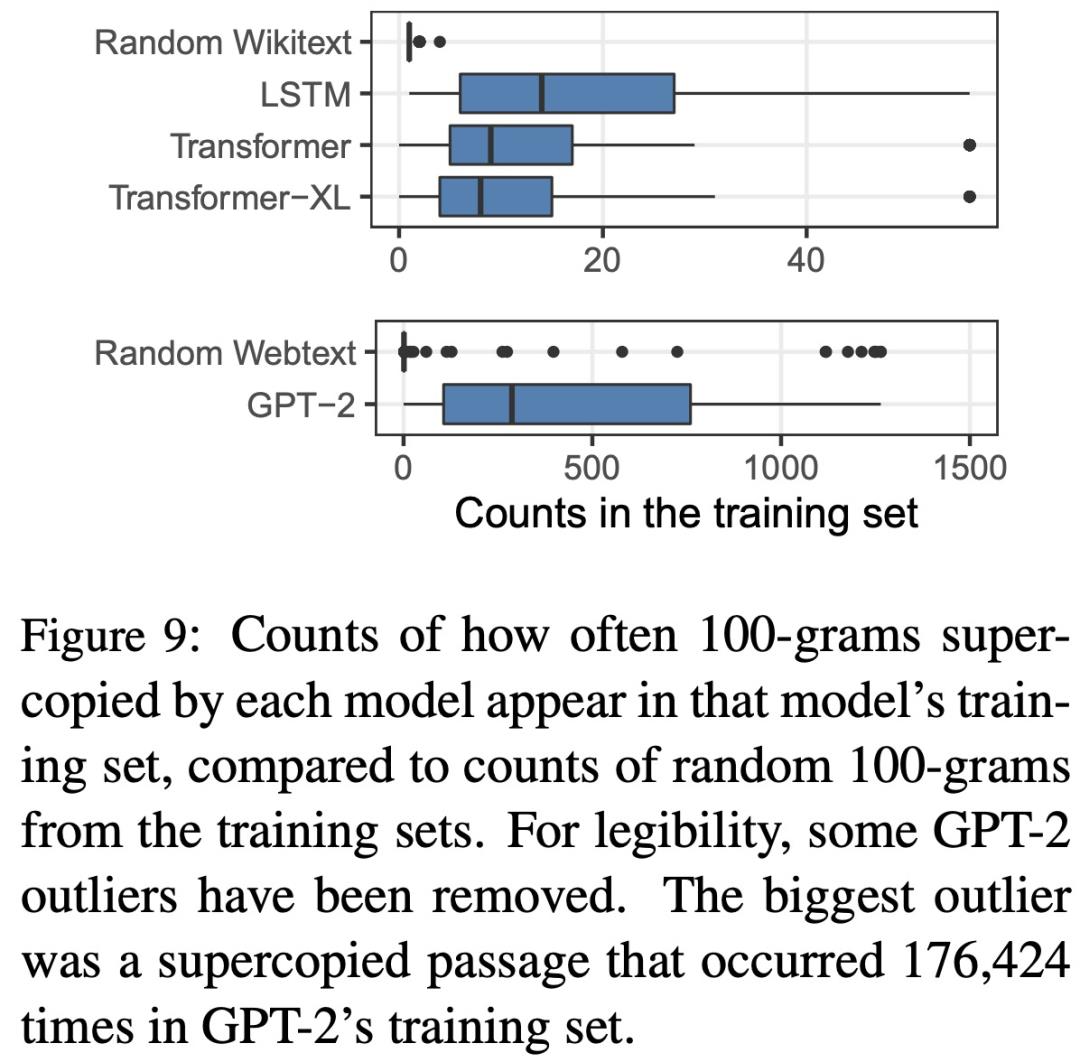
下图给出了几种模型「supercopying」训练集 100-grams 的次数统计数据。
新颖性与解码方案及生成文本的质量有何关系?
研究者发现,改变解码参数可以在很大程度上改变模型的新颖性。新颖性可以通过提高 top-p 采样中的 p、top-k 采样中的 k 或温度来提升。然而,所有提高生成文本新颖性的变动均会降低质量。

图 2:对解码方案的控制可以生成高质量的文本(例如,更低的困惑度;x 轴),但也会降低新颖性(例如,更大程度的重复; y 轴)。每个点显示不同的解码方案。
附录中提供了其他分析。研究者发现,模型大小 (附录 H) 和 prompt 长度 (附录 I) 对新颖性没有明显的影响;对于某些模型,新颖性受到生成文本中的位置的影响,但影响很小(附录 J) ;如果只考虑从训练集中复制,而不考虑从上下文和 / 或训练集中复制,那么新颖性结果不会有太大变化(附录 K)。
实验二:基于句法结构的新颖性分析
在全局句子结构层面,模型表现出了高度的句法新颖性,大多数生成的句子具备训练数据中的句子所没有的整体句法结构。对于局部结构,模型也展示出了一定程度的新颖性,但要比基线低得多。
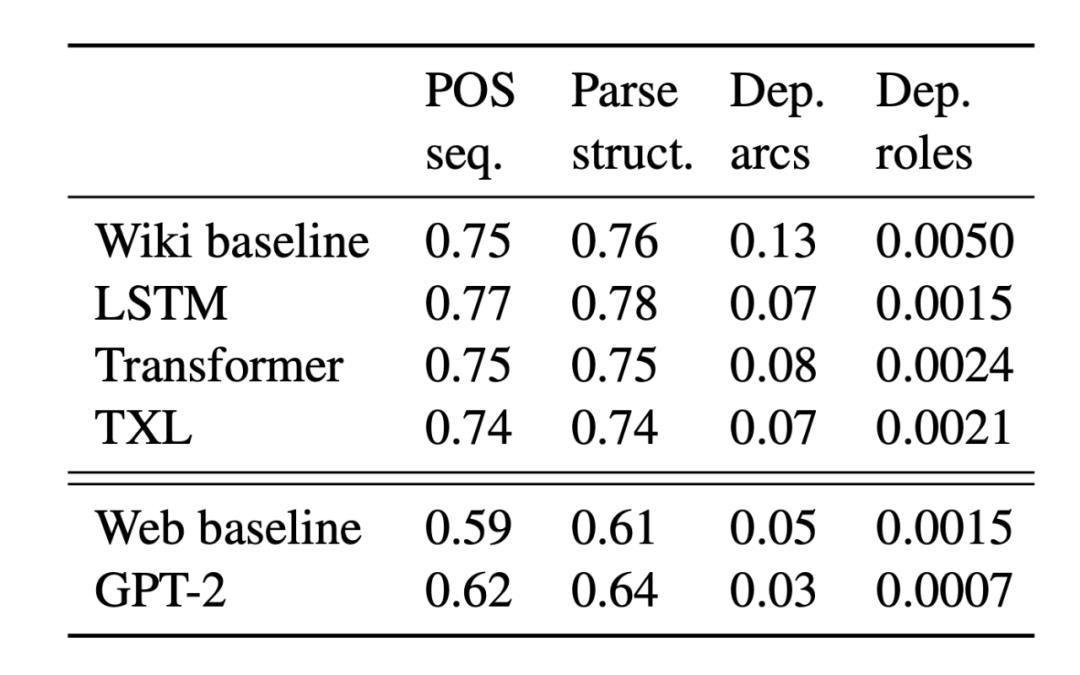
图 3: 句法新颖性。缩写分别表示: seq = sequence; dep = dependency; struct = structure
GPT-2 生成能力的手动分析
最后,研究者对新生成的文本进行了人工分析。这种分析是劳动密集型的,基于提升效率的考虑,这里主要关注了 GPT-2,因为它是性能最强的模型。在初步分析阶段,研究者只分析了 GPT-2 产生的新词语,GPT-2 使用了子词级分词,所以它可以用新的方式组合可见的子词来产生新词语。附录 O 和 P 中展示了 GPT-2 生成新词的详细分类。
GPT-2 生成新词的词法结构是否完备?
GPT-2 生成的新词绝大多数 (96%) 是词法完备的,然而这低于基线(99%)。
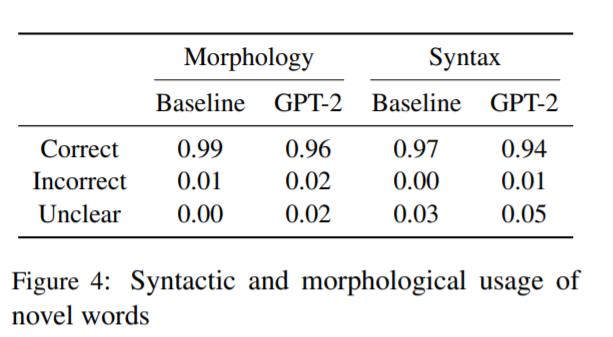
GPT-2 生成的新词是否符合上下文句法?
GPT-2 生成的新词绝大多数 (94%) 是在语法正确的上下文中使用的 ,但它确实比基线中的错误多。

GPT-2 生成的新词是否意义合理?
GPT-2 在这一领域的表现不如在词法和语法上的表现,这与语言模型只学习「形式」而不学习「意义」的说法 (Bender and Koller, 2020) 相符。
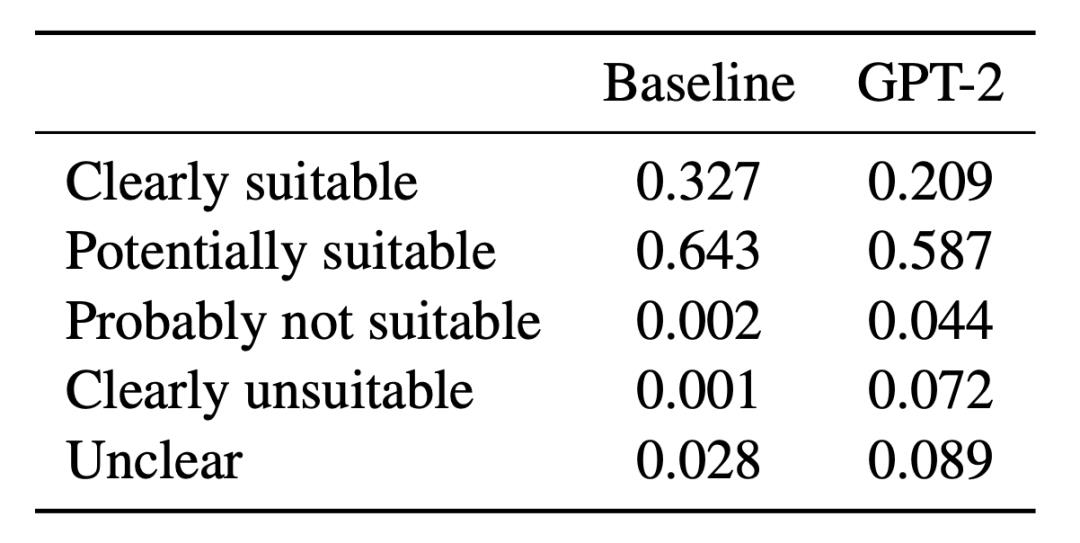
图 6:新词与其上下文的语义匹配程度。
通过使用 RAVEN 分析系统,研究者发现模型产生了许多种类的新颖性:各种大小的新颖 n-gram、新颖的句法结构和新颖的词法组合。模型属于「创作,但没有完全创作」的状态,结果也显示出许多复制的迹象:对于局部结构,模型表现大大低于基线; 此外也偶尔出现大规模的复制,例如复制超过 1000 词的训练集段落。
除了文本生成之外,研究者表示,希望这项工作能够让人们更加谨慎地考虑在 NLP 的训练集与测试集之间现存的分歧。
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于GPT 模型到底是怎么写作文的的主要内容,如果未能解决你的问题,请参考以下文章