详解和对比ResNet和DenseNet和MobileNet
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解和对比ResNet和DenseNet和MobileNet相关的知识,希望对你有一定的参考价值。
经典的Backbone,如ResNet50、DenseNet121、MobileNetV2,三类框架,参考 Keras Applications :
| ResNet50 | DenseNet121 | MobileNetV2 | |
|---|---|---|---|
| 时间 | CVPR 2015 | CVPR 2017 | CVPR 2018 |
| 模型 | 98M | 33M | 14M |
| Top1(ImageNet) | 0.749 | 0.750 | 0.713 |
| 参数 | 25,636,712(约2500w) | 8,062,504(约800w) | 3,538,984(约350w) |
| 推理速度CPU | 58.20ms | 77.14ms | 25.90ms |
| 推理速度GPU | 4.55ms | 5.38ms | 3.83ms |
ResNet50
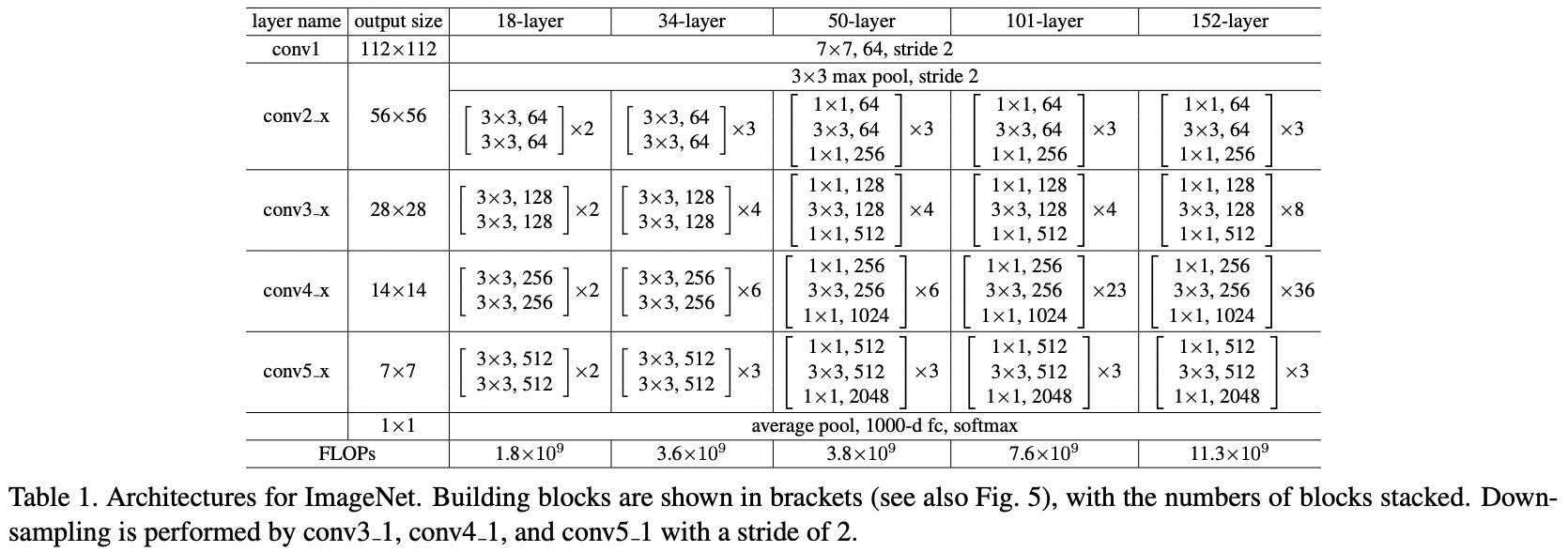
ResNet50,参考 PyTorch-ResNet 和论文 Deep Residual Learning for Image Recognition - CVPR2015:
-
ResNet模型的核心,通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),进行残差学习,这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。
-
conv1:7x7是卷积核尺寸、64通道、步长是2
-
ResNet50:
1 + 3*3 + 4*3 + 6*3 + 3*3 + 1 = 50 -
conv2_x:不执行下采样操作。
-
conv3_x:
-
4组卷积操作,第1组的第1次1x1卷积的stride是2,做下采样操作,其他次的stride是1。
-
其余组的每次都是stride为1的卷积操作。
-
每组执行一次,shortcut的残差操作,共执行3+4+6+3=16次残差操作。
-
每1层执行卷积+BN+激活操作,残差学习,在最后一层激活之前。
-
其余conv4_x和conv5_x类似。
-
-
最后,执行全局均值池化(GlobalAveragePooling2D),再加上全连接层(Dense)。
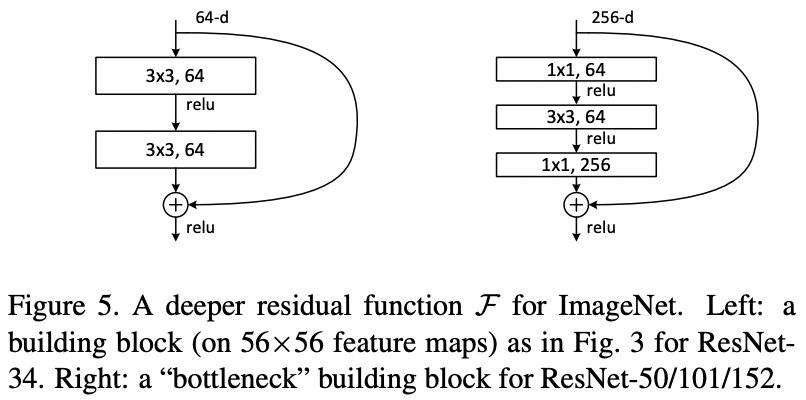
网络结构:
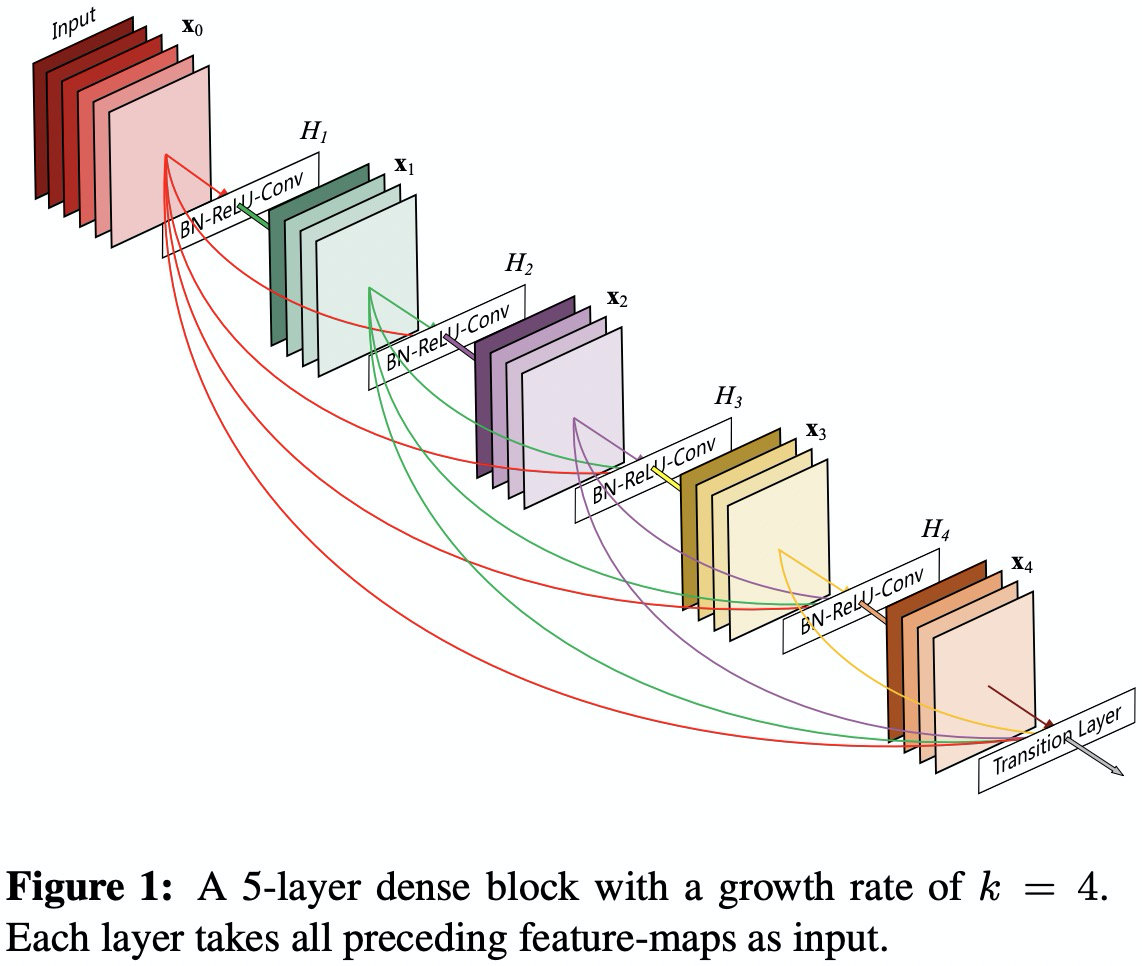
DenseNet121
DenseNet121,参考 PyTorch-DenseNet,论文 Densely Connected Convolutional Networks - CVPR2017 :
- DenseBlock(密集块)和TransitionLayer(过渡层)
- DenseNet121:
1 + 6*2 +1 + 12*2 + 1 + 24*2 + 1 + 16*2 + 1 = 121 - 起始:卷积7x7,64通道、步长是2,再进行步长为2的最大池化,输入图像由224 -> 56
growth_rate是32,DenseBlock1的通道数:64 + 6*32 = 256个- DenseBlock1:1x1卷积先扩大通道数4*32=128,3x3卷积再缩小通道数128->32,再和输入相加,即每次增加32个通道。
- TransitionLayer1:通过1x1卷积,降低一半的通道,如256降低为128,再通过stride(步长)为2的均值池化,降低一半输入尺寸。
通道数变化:
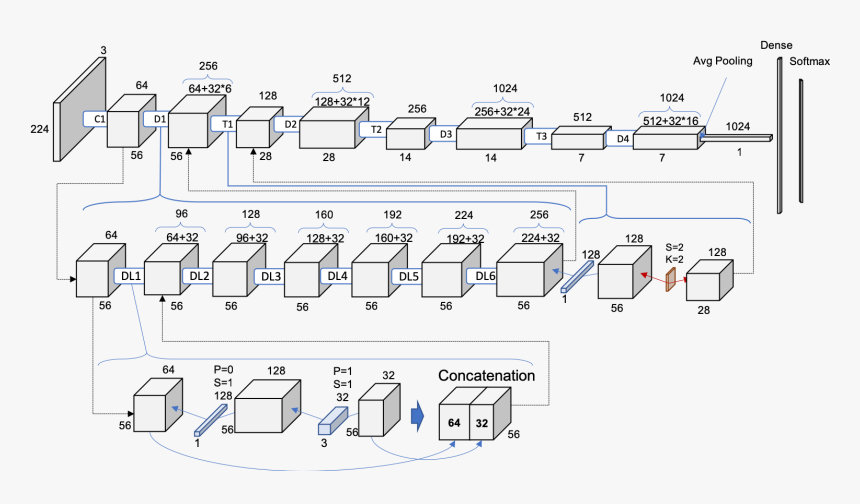
网络结构:
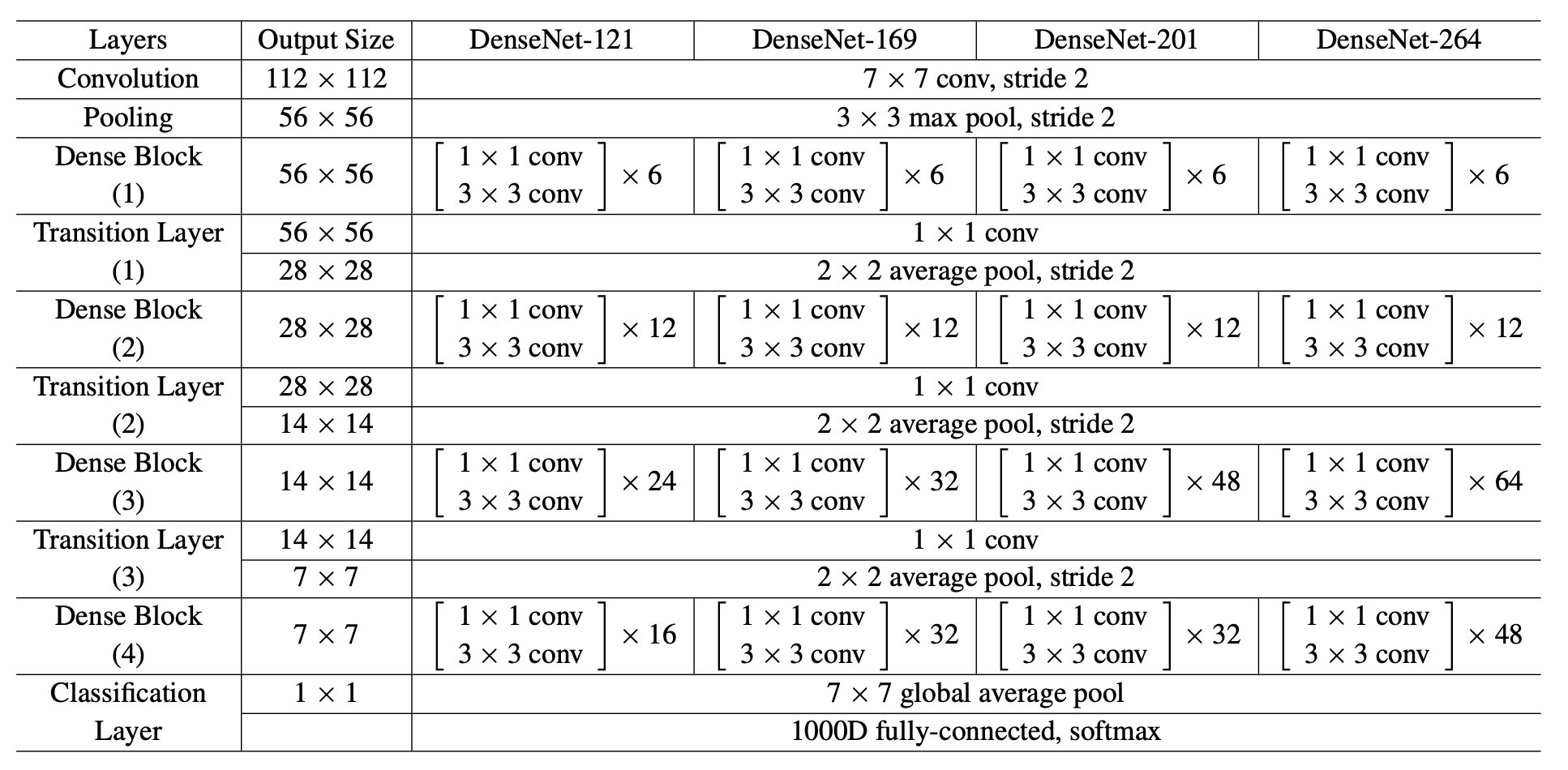
原型:
MobileNet v1、v2、v3
MobileNet v1 和 v2 和 v3的对比:
参数:
- v1: 参数4.2M,模型大小16M,
- v2,CVPR-2018: 参数3.5M(对比v1,下降17%),模型大小9.4M(对比v1,下降41%)
- v3,ICCV-2019: Large 参数5.4M,模型大小16.2M;Small 参数2.9M(对比v2,下降17%),模型大小7.9M(对比v2,下降16%)
MobileNet v1
MobileNet v1的特点是Depthwise Separable卷积:
-
Pointwise卷积 + Depthwise卷积 -> Depthwise Separable卷积,参考 深度可分离卷积
-
Depthwise Separable卷积,可以降低计算量
例如:卷积核:KxK,输入通道M,输出通道N,图像尺寸WxH,普通卷积Depthwise Separable卷积的具体计算量如下:
Depthwise Separable:M*N*W*H + K*K*M*W*H
原始:K*K*M*N*W*H
MobileNet v1中使用的Depthwise Separable Convolution是模型压缩的一个最为经典的策略,通过将跨通道的3x3卷积换成单通道的3x3卷积+跨通道的1x1卷积来达到此目的。
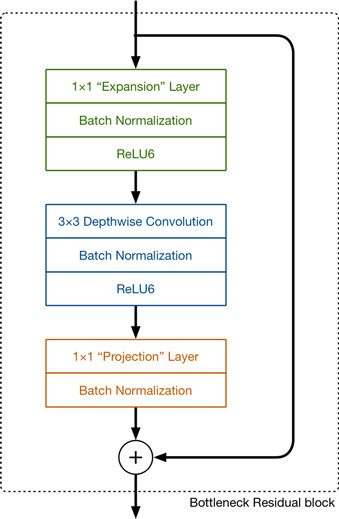
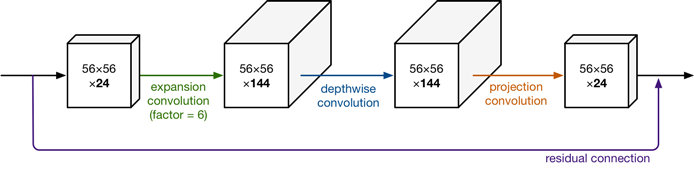
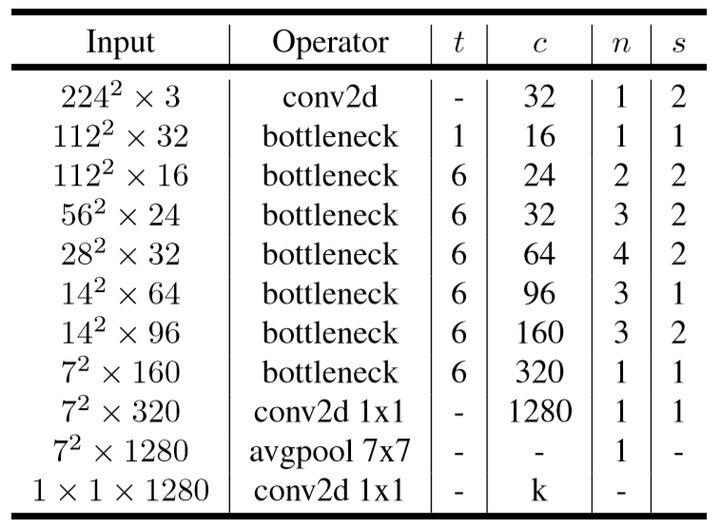
MobileNet v2
MobileNet v2的特点是Linear Bottleneck(线性瓶颈) 和 Inverted Residuals(反向残差),参考 详解MobileNetV2、MobileNet v1 和 MobileNet v2:
-
Linear Bottlenecks(参考V3) + ReLU6 + Residual
-
Inverted Residual Block,在bottleneck层使用残差结构;
-
MobileNetV2是在v1的Depthwise Separable的基础上引入了残差结构。并发现了ReLU的在通道数较少的Feature Map上有非常严重信息损失问题,由此引入了Linear Bottlenecks和Inverted Residual。
网络参考:
MobileNet v3
MobileNet v3的特点是:
- NAS(Neural Architecture Search) for block 和 NetAdapt for layer,创建网络结构;
- h-swish和ReLU混合使用,增强效果;在SE结构中,h-sigmoid代替sigmoid;速度较快;
- 堆叠bottleneck单元:瓶颈结构、SE结构、残差(Residual)结构;
- 重新设计高效的last stage
网络结构:
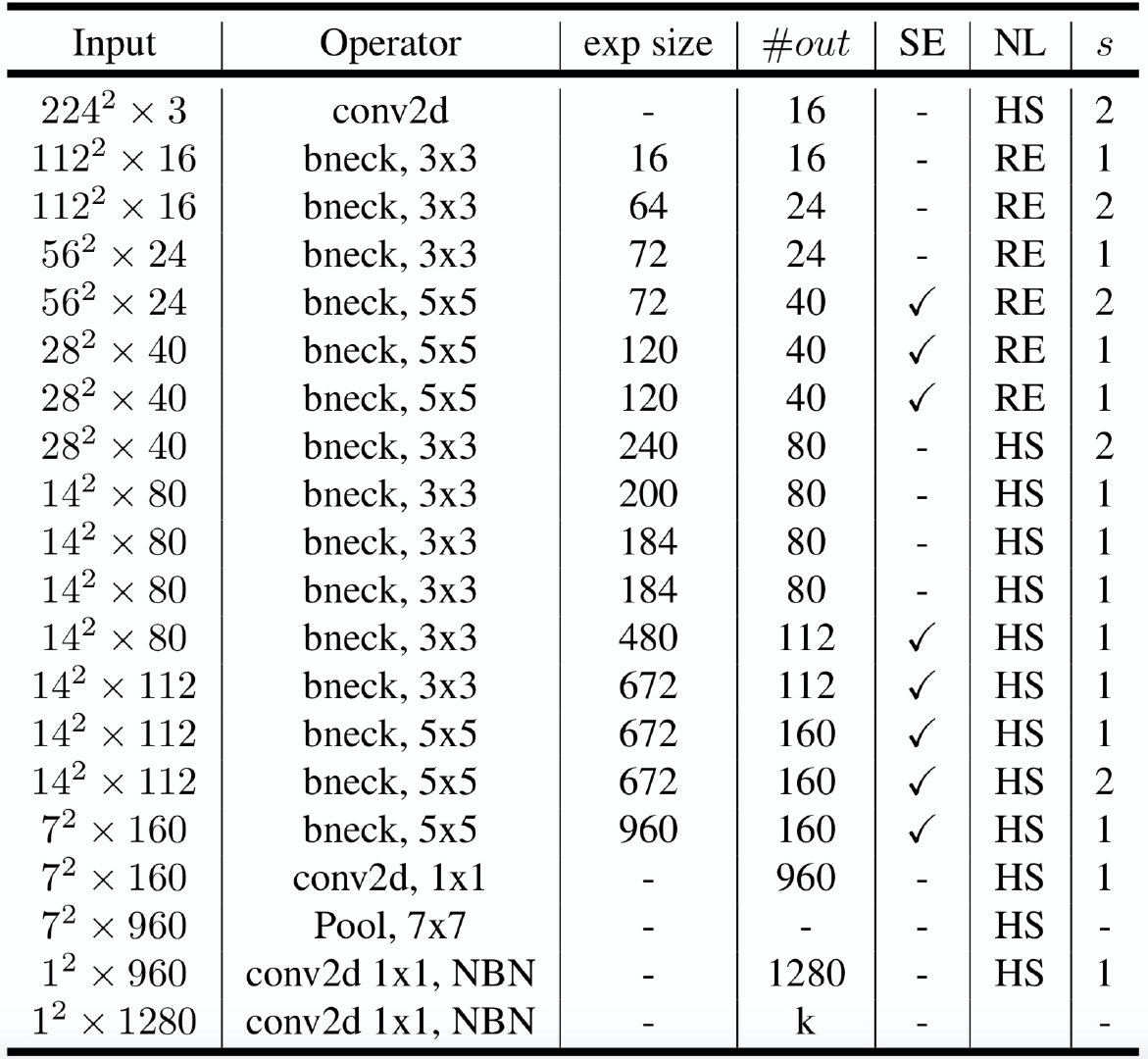
h-swish & h-sigmoid:h表示Hard
h-sigmoid = ReLU6(x+3)/6h-swish = x*(ReLU6(x+3)/6)swish = x*sigmoid(x)
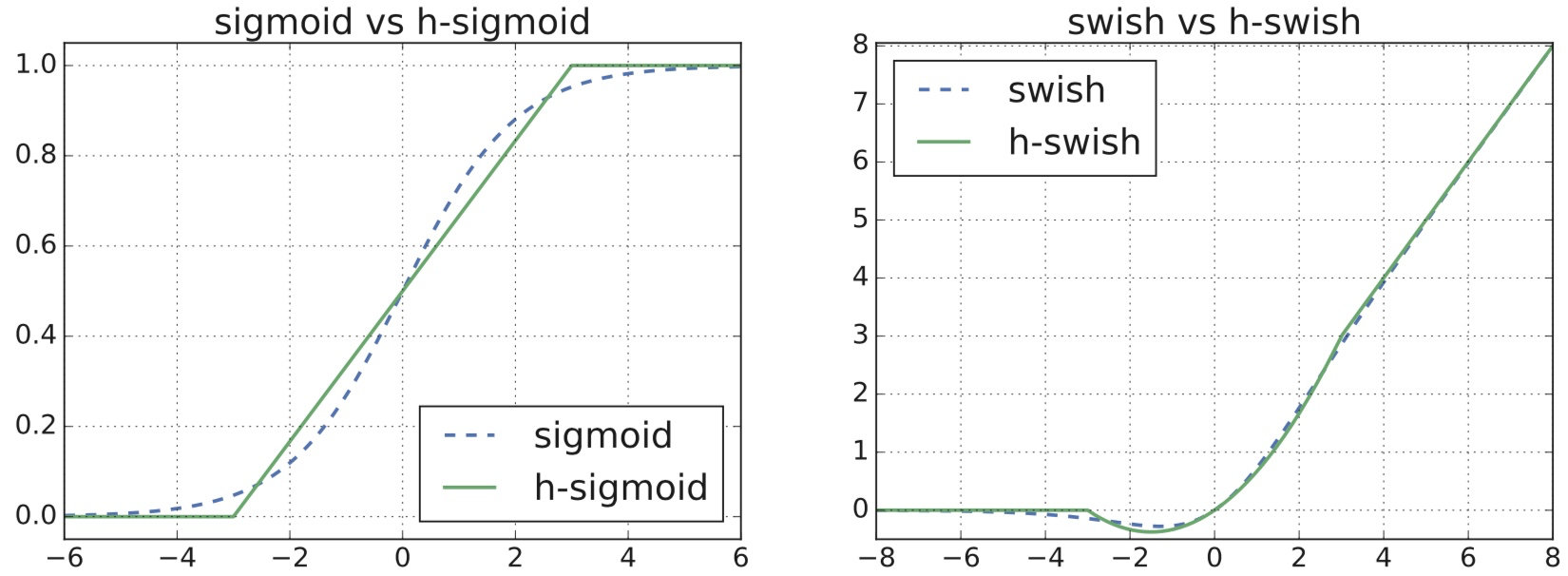
bottleneck单元:bneck:瓶颈单元;exp size:expand尺寸;
- 1x1的卷积,input通道,exp通道,stride是1;BN,激活;Pointwise卷积
- 3x3,5x5的卷积,exp通道,exp通道,stride是1或2;BN;Depthwise卷积
- 可选:SE结构:线性压缩,乘以权重;
- 1x1的卷积,exp通道,output通道,stride是1,BN,激活;
- bottleneck,stride是1,同时输入和输出相同;
Last Stage:输入是7x7x960

Old:
- 3x3的卷积,通道数960不变;
- 1x1的卷积,降低通道320;
- 1x1的卷积,提升通道1280;
- Avg Pooling池化;
- 1x1的卷积预测类别1000;
New:
- Avg Pooling池化,960;
- 1x1的卷积, 提升通道1280;
- 1x1的卷积,预测类别1000;
降低15%的计算时间,同时没有精度损失。
SE结构:
SE:Squeeze and Excite,压缩和刺激;
例如输入:16x112x112
- Avg Pooling:16x1x1,reshape为16;
- 压缩和刺激:压缩比例是4
- 压缩:16 x [16x4] = 4,
- ReLU
- 刺激:4 x [4x16] = 16,
- H-Sigmoid:ReLU6(x+3)/6
- reshape:16x1x1,权重
- 权重与源矩阵相乘:
16x112x112 * 16x1x1 = 16x112x112
class SqueezeBlock(nn.Module):
def __init__(self, exp_size, divide=4):
super(SqueezeBlock, self).__init__()
self.dense = nn.Sequential(
nn.Linear(exp_size, exp_size // divide),
nn.ReLU(inplace=True),
nn.Linear(exp_size // divide, exp_size),
h_sigmoid()
)
def forward(self, x):
batch, channels, height, width = x.size()
out = F.avg_pool2d(x, kernel_size=[height, width]).view(batch, -1)
out = self.dense(out)
out = out.view(batch, channels, 1, 1)
return out * x
卷积公式:
- 输入:MxM
- 卷积核:KxK
- 步长:S
- adding:P
- 输出:NxN
公式: N = (M - K + 2P) // S + 1
1x1 卷积的优势:
- 进行卷积核通道数的降维和升维,修改channel数量,同时,在升维和降维过程中,实现跨通道的交互和信息整合;
- 最后连接的激活函数,增加非线性激励;
- 在预测时,避免全连接层的固定参数,接受任意尺度输入;
- 用于Depthwise Separable卷积,降低计算量:Pointwise卷积 + Depthwise卷积 -> Depthwise Separable卷积。
That’s all.
以上是关于详解和对比ResNet和DenseNet和MobileNet的主要内容,如果未能解决你的问题,请参考以下文章
DenseNet——CNN经典网络模型详解(pytorch实现)
深度学习分类网络结构RESNET RESNEXT DENSENET DPN MOBILE NET SHUFFLE NET
总结近期CNN模型的发展---- ResNet [1, 2] Wide ResNet [3] ResNeXt [4] DenseNet [5] DPNet
Dual Path Networks(DPN)——一种结合了ResNet和DenseNet优势的新型卷积网络结构。深度残差网络通过残差旁支通路再利用特征,但残差通道不善于探索新特征。密集连接网络通过密