如何实时同步数据到StarRocks
Posted csdn779343484
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何实时同步数据到StarRocks相关的知识,希望对你有一定的参考价值。
我们知道,是StarRocks基于Doris开发的,它在多表连接查询的性能方面引领OLAP市场,是一个很好用的结构化数据仓库。但是一直没有很好的工具能够实现业务数据库的数据实时同步到StarRocks分布式数据仓库集群中,本文将带领读者一起来通过flink-jobs的最佳实践来构建一个易于使用和运维的,异构数据库实时同步到StarRocks集群的方案。
阅读前提
阅读本文除了需具备StarRocks相关知识之外,还会涉及Flink、Debezium、Kafka、Zookeeper、mysql(或者PostgreSQL、Oracle、SQL Server、Db2等其中一种),最好能够自己搭建整套环境,如果不能,身边有可以利用的环境或者有朋友能帮上忙也可以。
环境准备
- 在192.168.100.1-3上安装zookeeper的,在192.168.100.4-6上安装基于zookeeper的Flink高可用集群,具体安装配置方法请查阅Flink官网。
- 在192.168.100.7-9上安装基于zookeeper的kafka集群,并配置好Debezium(也可以是Canal、Maxwell等Flink支持的其他组件),安装方法详见各自官网。
- 在192.168.100.10上安装一个MySQL数据库,也可以安装任意Debezium支持的数据库(例如PostgreSQL、Oracle、SQL Server、Db2等)。创建一个skyline数据库,在skyline中创建product表并插入数据:
-- ---------------------------- -- Table structure for product -- ---------------------------- CREATE TABLE product ( id bigint NOT NULL, name VARCHAR(255), authors VARCHAR(50), create_time DATETIME, PRIMARY KEY (id) ); -- ---------------------------- -- Records of product -- ---------------------------- INSERT INTO product VALUES (100000000000000001, 'Apache Flink', 'Apache Software Foundation', now()); INSERT INTO product VALUES (100000000000000002, 'Flink Jobs', 'June', now()); - 192.168.100.11-13上安装一个StarRocks集群,创建一个skyline数据库,并在skyline中创建product表:
-- ---------------------------- -- Table structure for product -- ---------------------------- CREATE TABLE product ( id bigint NOT NULL, name STRING, authors STRING, create_time DATETIME ) PRIMARY KEY (id) DISTRIBUTED BY HASH (id) BUCKETS 3; - 在kafka上运行命令将MySQL中的product表的变更通过CDC捕获:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" 192.168.100.7:8083/connectors/ -d ' "name": "productCDCTask", "config": "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "192.168.100.10", "database.port": "3306", "database.user": "your_user", "database.password": "your_password", "database.server.id": "184001", "database.server.name": "demo", "database.whitelist": "skyline", "database.useTimezone": "true", "database.serverTimeZone": "Asia/Shanghai", "time.precision.mode": "connect", "decimal.handling.mode": "string", "table.whitelist": "skyline.product", "database.history.kafka.bootstrap.servers": "192.168.100.7:9092,192.168.100.8:9092,192.168.100.9:9092", "database.history.kafka.topic": "dbhistory.demo" ';
创建应用
为了更快地创建自己的flink-jobs应用程序,我们直接下载flink-jobs-quickstart来开始构建我们的第一个flink-jobs应用程序:
- 下载flink-jobs-quickstart源代码,并根据自己的情况修改flink-jobs.properties配置文件(这里只需要修改Kafka和StarRocks的配置即可)。
- 在flink-jobs-quickstart目录下,使用maven打包:
mvn clean package -Dmaven.test.skip=true
运行应用
打包成功后,生成的程序包在target目录下:
- 将
flink-jobs-quickstart/target/flink-jobs-quickstart-1.1.3.jar及flink-jobs-quickstart/target/lib/*上传到flink所在服务器,例如上传到/opt/flink-jobs-quickstart/flink-jobs-quickstart-1.1.3.jar和/opt/flink-jobs-quickstart/lib/*。这里需要注意1.1.3为版本号,请根据自己下载的实际版本调整。 - 将
flink-jobs-quickstart/target/lib-provided/*包上传到$yourFlinkPath/lib目录下($yourFlinkPath为你的flink所在目录)。 - 启动flink集群,如果此前已经启动,由于
$yourFlinkPath/lib目录发生了变化,重启以确保所有依赖包被重新加载。 - 通过命令行直接运行同步任务:
$yourFlinkPath/bin/flink run /opt/flink-jobs-quickstart/flink-jobs-quickstart-1.1.3.jar "\\"operates\\":[\\"from\\":\\"kafka\\",\\"primaryKey\\":\\"id\\",\\"table\\":\\"product\\",\\"to\\":\\"starrocks\\",\\"topic\\":\\"demo.skyline.product\\",\\"type\\":\\"DataSync\\"]" - 可以尝试对MySQL中的product表进行增删改操作,新的数据将很快同步到StarRocks中。
系统集成
直接通过命令行提交flink-jobs任务并不是终点,因为它使用起来比较繁琐,且不利于管理和维护。最理想的状态应该是直接通过系统界面来进行任务的管理,包括任务配置、启动、停止、重启、监控等。
通过flink-jobs-launcher+Flink REST API可以实现这种目的。首先,利用flink-jobs-launcher提交flink-jobs应用程序会更加便捷,可以采用可读性更好的XML来配置作业,还可以将flink作业集成到现有Java系统中。其次,通过定时调度调用Flink REST API可以将Flink任务监控集成到系统中。详情请移步flink-jobs-launcher或flink-jobs-launcher-quickstart
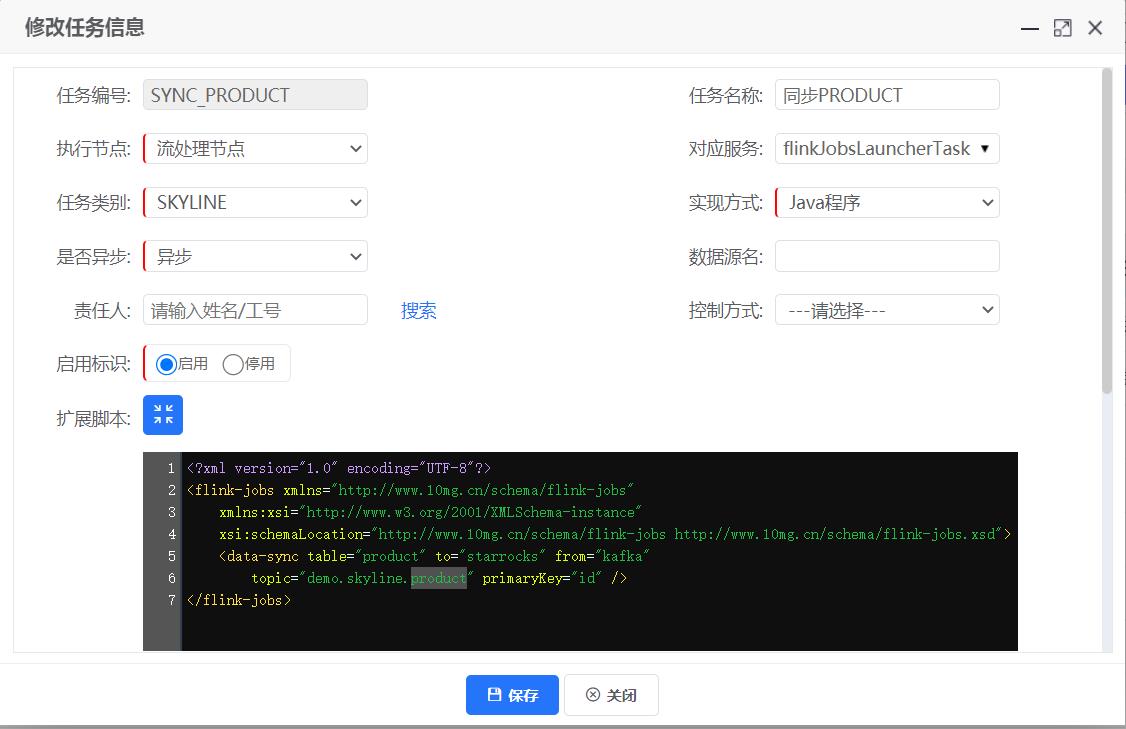
以上是关于如何实时同步数据到StarRocks的主要内容,如果未能解决你的问题,请参考以下文章
Flink系列之:Debezium采集Mysql数据库表数据到Kafka Topic,同步kafka topic数据到StarRocks数据库
EMR-StarRocks 与 Flink 在汇量实时写入场景的最佳实践