Seatunnel实战:hive_to_starrocks
Posted 柠檬味的鱼°
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Seatunnel实战:hive_to_starrocks相关的知识,希望对你有一定的参考价值。
一、前言
-
SeaTunnel是一个分布式、高性能、可扩展的数据同步工具,它支持多种数据源之间的数据同步,包括Hive和StarRocks。可以使用SeaTunnel的Hive源连接器从Hive读取外部数据源数据,然后使用StarRocks接收器连接器将数据发送到StarRocks。
-
通过StarRocks读取外部数据源数据。StarRocks源连接器的内部实现是从前端(FE)获得查询计划,将查询计划作为参数传递给BE节点,然后从BE节点获得数据结果。
| 名称 | 版本 |
|---|---|
| StarRocks | 2.4.2 |
| SeaTunnel | 2.3.1 |
| Spark | 3.2.1 |
| Flink | 1.16.1 |
二、安装SeaTunnel
- 安装并设置Java(Java 8 或 11,其他高于 Java 8 的版本理论上也可以使用)JAVA_HOME。
- 进入seatunnel下载页面,下载最新版本的distribute packageseatunnel--bin.tar.gz,或者可以通过终端下载(下载很慢,这边已上传至云盘,可以直接自取)
export version="2.3.1"
wget "https://archive.apache.org/dist/incubator/seatunnel/$version/apache-seatunnel-incubating-$version-bin.tar.gz"
tar -xzvf "apache-seatunnel-incubating-$version-bin.tar.gz"
链接:https://pan.baidu.com/s/1nT0BgUutW66cyiu2C_jqIg
提取码:acdy
- 安装连接器
- 从2.2.0-beta开始,二进制包默认不提供connector依赖,所以第一次使用时,我们需要执行如下命令安装connector:(当然也可以手动下载connector从(Apache Maven Repository下载,然后手动移动到connectors目录下的seatunnel子目录)。
- 指定connector的版本,执行
/bin/bash /app/apache-seatunnel-incubating-2.3.1/bin/install-plugin.sh 2.3.1
- 安装完检查connectors目录文件
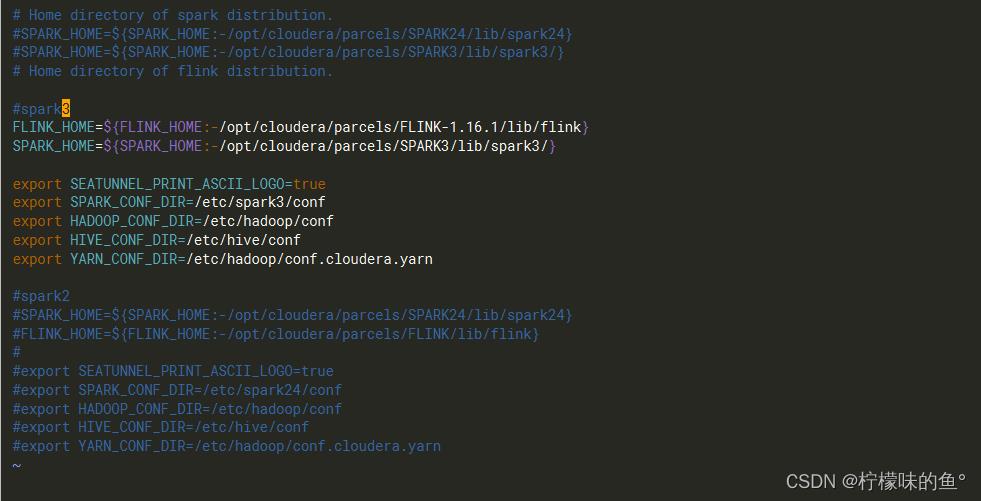
- 配置 SeaTunnel,更改设置config/seatunnel-env.sh
- 自行选择合适的spark(要求版本>=2.4.0)、flink 版本(要求版本>=1.12.0)
vim /app/apache-seatunnel-incubating-2.3.1/config/seatunnel-env.sh
- 运行SeaTunnel,查看是否部署安装成功
-- 本地模式
/app/apache-seatunnel-incubating-2.3.1/bin/start-seatunnel-spark-3-connector-v2.sh \\
-m local[*] \\
-e client \\
-c /app/apache-seatunnel-incubating-2.3.1/config/seatunnel.streaming.conf.template
-- 集群模式
/app/apache-seatunnel-incubating-2.3.1/bin/start-seatunnel-spark-3-connector-v2.sh \\
-m yarn \\
-e client \\
-c /app/apache-seatunnel-incubating-2.3.1/config/seatunnel.streaming.conf.template
- SeaTunnel 控制台会打印一些日志如下
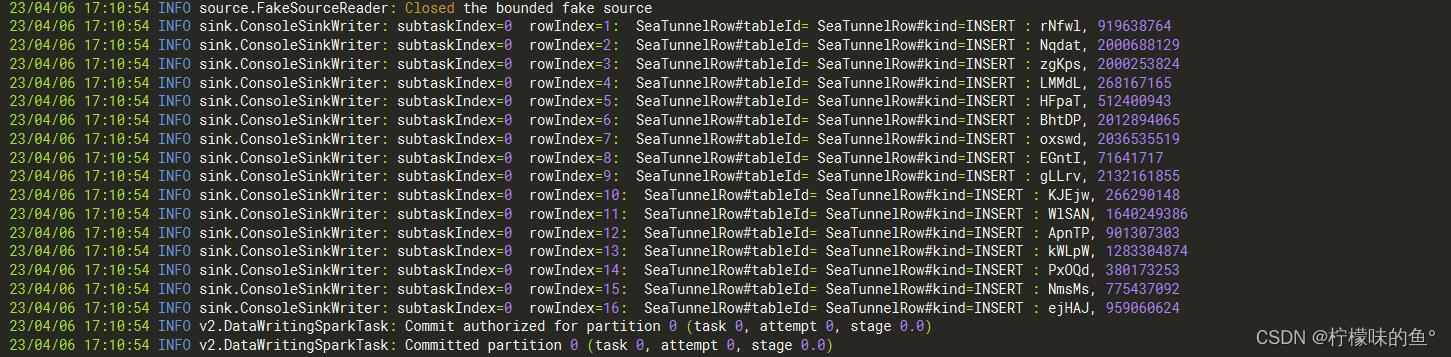
三、配置Seatunnel config
1、Hive source
- 配置 Hive源,您需要在SeaTunnel作业配置文件中指定Hive的连接信息,包括metastore_uri、table_name。更多seatunnel source hive 例如:
source
Hive
#parallelism = 6
table_name = "mid.ads_test_hive_starrocks_ds"
metastore_uri = "thrift://192.168.10.200:9083"
result_table_name = "hive_starrocks_ds"
2、Seatunnel Transform
- Transform 是指在数据迁移过程中对数据进行转换的过程。它支持多种转换插件,包括Json、NullRate、Nulltf、Replace、Split、Sql、udf和UUID等,Transform插件具有一些通用参数,可以在SeaTunnel作业配置文件中指定这些参数来控制数据转换的行为。更多seatunnel Transform 例如:
transform
Filter
source_table_name = "fake"
fields = [name]
result_table_name = "fake_name"
Filter
source_table_name = "fake"
fields = [age]
result_table_name = "fake_age"
3、StarRocks sink
- 配置 StarRocks接收器,您需要在SeaTunnel作业配置文件中指定StarRocks的连接信息,包括JDBC URL、用户名和密码。更多seatunnel sink starrocks 例如:
sink
starrocks
nodeUrls = ["192.168.10.10:8030","192.168.10.11:8030","192.168.10.12:8030"]
base-url = "jdbc:mysql://192.168.10.10:9030/"
username = root
password = "xxxxxxxxx"
database = "example_db"
table = "ads_test_hive_starrocks_ds"
batch_max_rows = 500000
batch_max_bytes = 104857600
batch_interval_ms = 30000
starrocks.config =
format = "CSV"
column_separator = "\\\\x01"
row_delimiter = "\\\\x02"
四、Run SeaTunnel hive_to_starrocks
cat /app/apache-seatunnel-incubating-2.3.1/config/hive_to_sr2.conf
env
spark.app.name = "apache-seatunnel-2.3.1_hive_to_sr"
spark.yarn.queue = "root.default"
spark.executor.instances = 2
spark.executor.cores = 4
spark.driver.memory = "3g"
spark.executor.memory = "4g"
spark.ui.port = 1300
spark.sql.catalogImplementation = "hive"
spark.hadoop.hive.exec.dynamic.partition = "true"
spark.hadoop.hive.exec.dynamic.partition.mode = "nonstrict"
spark.network.timeout = "1200s"
spark.sql.sources.partitionOverwriteMode = "dynamic"
spark.yarn.executor.memoryOverhead = 800m
spark.kryoserializer.buffer.max = 512m
spark.executor.extraJavaOptions = "-Dfile.encoding=UTF-8"
spark.driver.extraJavaOptions = "-Dfile.encoding=UTF-8"
job.name = "apache-seatunnel-2.3.1_hive_to_sr"
source
Hive
#parallelism = 6
table_name = "mid.ads_test_hive_starrocks_ds"
metastore_uri = "thrift://192.168.10.200:9083"
result_table_name = "hive_starrocks_ds_t1"
transform
sql
query ="select xxx,xxx,xxx,xxx from hive_starrocks_ds_t1 where period_sdate >= '2022-10-31'"
source_table_name = "hive_starrocks_ds_t1"
result_table_name = "hive_starrocks_ds_t2"
sink
starrocks
nodeUrls = ["192.168.10.10:8030","192.168.10.11:8030","192.168.10.12:8030"]
base-url = "jdbc:mysql://192.168.10.10:9030/"
username = root
password = "xxxxxxxxx"
database = "example_db"
table = "ads_test_hive_starrocks_ds"
batch_max_rows = 500000
batch_max_bytes = 104857600
batch_interval_ms = 30000
starrocks.config =
format = "CSV"
column_separator = "\\\\x01"
row_delimiter = "\\\\x02"
- spark3.x.x
sudo -u hive /app/apache-seatunnel-incubating-2.3.1/bin/start-seatunnel-spark-3-connector-v2.sh \\
-m yarn \\
-e client \\
-c /app/apache-seatunnel-incubating-2.3.1/config/hive_to_sr2.conf
- spark2.x.x
sudo -u hive /app/apache-seatunnel-incubating-2.3.1/bin/start-seatunnel-spark-2-connector-v2.sh \\
-m yarn \\
-e client \\
-c /app/apache-seatunnel-incubating-2.3.1/config/hive_to_sr2.conf
五、总结
1、问题总结
- A. 中文乱码问题
设置环境变量来解决中文乱码问题。可以在env中添加以下参数,这将设置Java虚拟机的编码格式为UTF-8,以便正确处理中文字符。
spark.executor.extraJavaOptions = "-Dfile.encoding=UTF-8"
spark.driver.extraJavaOptions = "-Dfile.encoding=UTF-8"
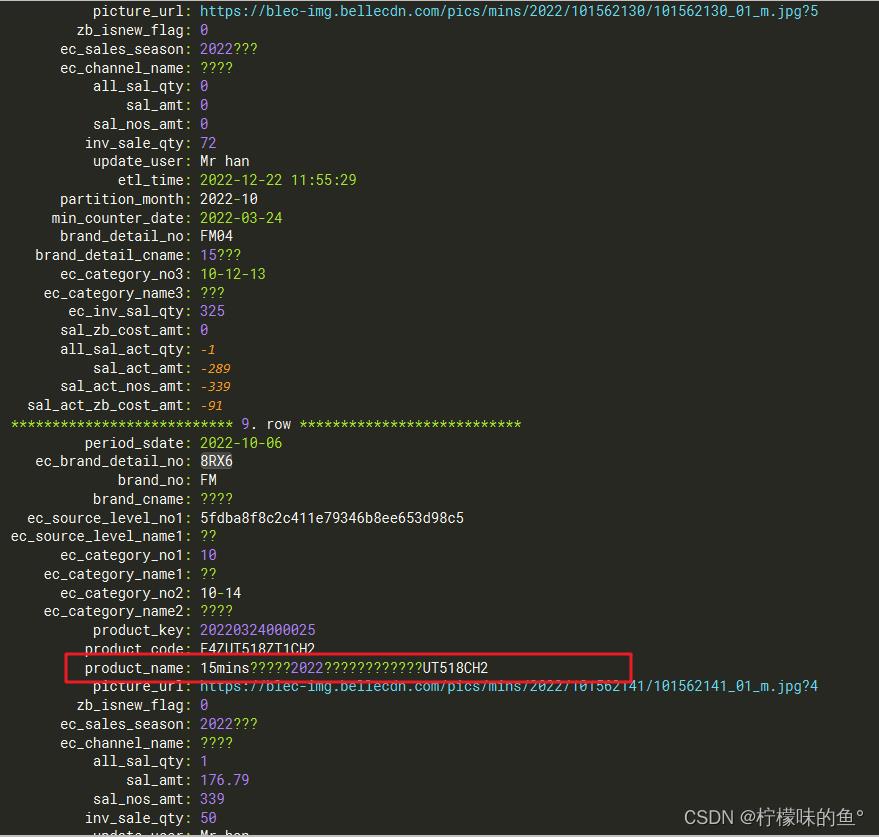
- B. 内存限制而被YARN杀死
Spark 程序在 YARN 集群上运行时,由于超出了内存限制而丢失了一个执行器。考虑增加 spark.yarn.executor.memoryOverhead 用于指定每个执行器保留的用于内部元数据、用户数据结构和其他堆外内存需求的堆外内存量。该参数的值将添加到执行器内存中,以确定每个执行器对 YARN 的完整内存请求。建议不要将此值设置得过高,因为这可能会导致过多的垃圾收集开销和性能降低。
spark.yarn.executor.memoryOverhead = 800M

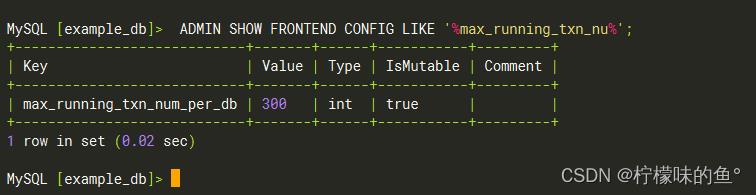
- C. db 2153532 is 100 larger than limit 100?
错误信息表明您在尝试将数据刷新到 StarRocks 时遇到了问题。在 db 2153532 上运行的事务数为 100,超过了限制 100。可以尝试减少并发事务的数量,以减轻集群的压力。另外可以调整相关参数。
-- 修改事务数
ADMIN SHOW FRONTEND CONFIG ('max_running_txn_num_per_db' = '300')
-- 查看参数是否调整
ADMIN SHOW FRONTEND CONFIG LIKE '%max_running_txn_nu%';

2、使用总结
- 本篇文章带大家了解使用Seatunnel将Hive中的数据导入到StarRocks中,除此之外,Seatunnel还有很多种数据源可以支持,也有很多种导入方式,例如DataX 、CloudCanal 等
- 将数仓中跑完的Hive的相关表每天导入到StarRocks中,可以使用以下场景:
1、不更新历史数据: 如果是分区表,我们增量导入到 StarRocks 中即可。非分区表全量导入。
2、更新历史数据: 这种情况主要存在分区表中,往往会更改前几个月数据或者时间更久的数据,这种情况下,就不得不将该表重新同步一边,使StarRocks中的数据和hive中的数据保持一致。hive中表的元数据发生变化,和StarRocks中的表结构不一致: 这种情况下,就需要我们删除重新建表或者truncate历史分区,重新同步数据。
通过apache seatunnel将mysql数据和hive同步
Flink集群部署安装
Standalone模式部署
Flink 安装部署需要准备 3 台 Linux 机器。具体要求如下:
系统环境为 CentOS 7.5 版本。
安装 Java 8(略)。
环境变量,(部署完成)
export JAVA_HOME=/bigdata/opt/jdk/jdk1.8.0_211
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
export SCALA_HOME=/bigdata/opt/s/scala/scala-2.12.17
export PATH=$SCALA_HOME/bin:$PATH
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_HOME=/usr/hdp/3.1.0.0-78/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
export SCALA_HOME=/bigdata/opt/s/scala/scala-2.12.17
export PATH=$SCALA_HOME/bin:$PATH
export FLINK_HOME=/bigdata/opt/f/flink/flink-1.13.6
export PATH=$FLINK_HOME/bin:$PATH
export HADOOP_CLASSPATH=`hadoop classpath`
export SPARK_HOME=/usr/hdp/3.1.0.0-78/spark2
export PATH=$SPARK_HO以上是关于Seatunnel实战:hive_to_starrocks的主要内容,如果未能解决你的问题,请参考以下文章