MySQL 数据库数据表的基本操作(细节满满)
Posted 吞吞吐吐大魔王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 数据库数据表的基本操作(细节满满)相关的知识,希望对你有一定的参考价值。
文章目录
补充:
- 库名、表名、列名等等不能和关键字相同,如果一定要用关键字为名,则可以通过反引号把名字引起来
- 对表进行操作之前,要先选中数据库
- mysql 中支持以下几种注释:
-- 注释内容:单行注释,要注意 “–” 和注释内容之间需要有空格#注释内容:单行注释/*注释内容*/:多行注释- 补充:字段或列的注释可以用属性 comment 来添加,例如在建表语句中使用
- SQL 中单引号和双引号都能表示字符串
1. 查看当前数据库中的表
语法:
show tables;
示例: 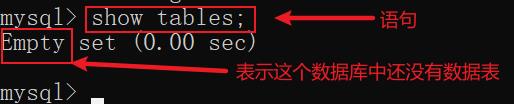
2. 创建表
语法:
create table [if not exists] 表名(列名 列类型, 列名 列类型, ..., 列名 列类型);
示例: 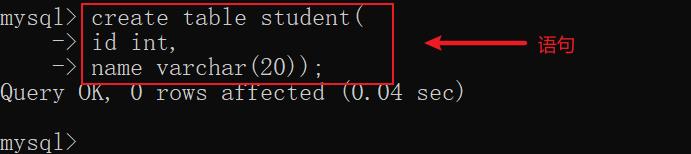
3. 查看指定表结构
语法:
desc 表名;
补充:
desc 是 describe 的缩写,也可以使用
describe 表名来查看表结构
示例: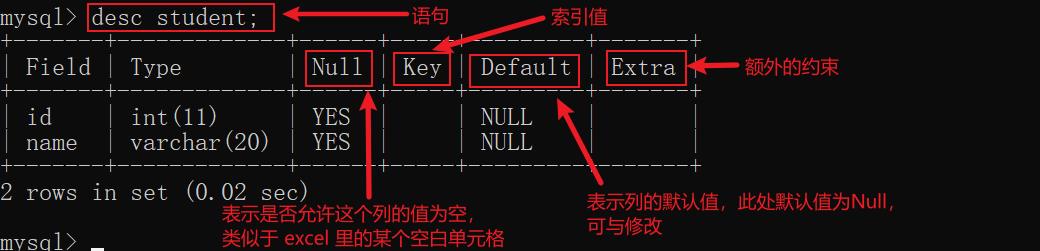
4. 删除表
语法:
drop table [if exists] 表名 [, 表名 ...];
示例: 
注意:
删表操作也是一个极具风险的操作,甚至要比删库操作还危险。因为一旦删除,程序第一时间就挂了,还能及时抢救。但是删表的话,程序不一定第一时间显示异常,那么不能及时处理则会出现更大的风险。
5. 往表中新增数据
语法:
insert [into] 表名 [(列名1, 列名2, ...,列名n)] values (第一行的:值1, 值2, ...,值n) [, ..., (第n行的:值1, 值2, ...,值n)]
补充:
- 上述语句列名不写的话就代表全列都要进行新增数据
- 每行插入的值要与每行要插入的列名的顺序一一对应
- 如果插入时,某列没有进行插入,这个列就为默认值 NULL
实例1: 全列插入一行
结果为:
id name 1 张三
示例2: 全列插入多行
结果为:
id name 1 张三 2 李四 3 王五
示例3: 指定某些列来插入
结果为:
id name 1 张三 2 李四 3 王五 4 NULL
注意: 一般认为,一条语句,一次插入多个记录,效率要比多个语句,每个语句插入一个记录高的多
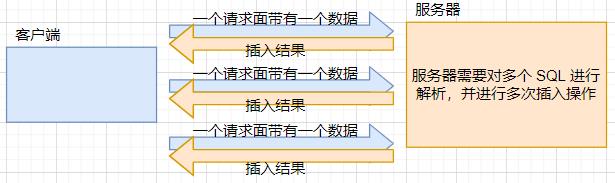
我们知道 MySQL 是一个“客户端—服务器”结构的程序。用户在客户端输入的 SQL 都会通过网络传输给服务器,然后由服务器进行具体的操作。下面我们来分析下上述两者的差别
- 一条语句,一次插入多个记录:
- 多个语句,每个语句插入一个记录:
又由于计算机对寄存器的访问速度 >>> 对内存的访问速度 >>> 对IO设备(网络上传输数据,对于计算机来讲叫做 IO 操作)的访问的速度。因此,一般认为,一条语句,一次插入多个记录,效率要比多个语句,每个语句插入一个记录高的多

6. 查找表中的数据
语法:
selstc [distinct] * | 列名1 [, ..., 列名n] from 表名 [where] [order by 列名1 [ASC | DESC] [, ...,[列名n [ASC | DESC]]] limit
补充:
- 查询结果是一个类似于“表”的结构,但这个表是一个“临时表”,仅仅是在内存中存了一下,在打印完之后就没了,不会持久化存储。
- select 不会修改磁盘数据,尤其是不会影响到服务器的原始磁盘上的数据
为了方便下面介绍示例,所以已经在数据库中创建了如下的一个数据表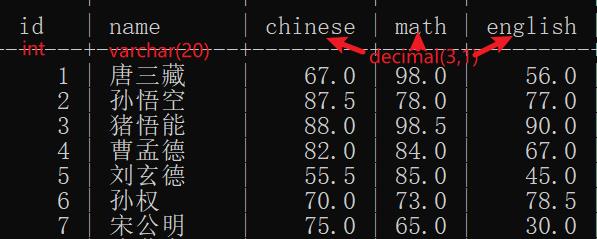
6.1 全列查询
示例: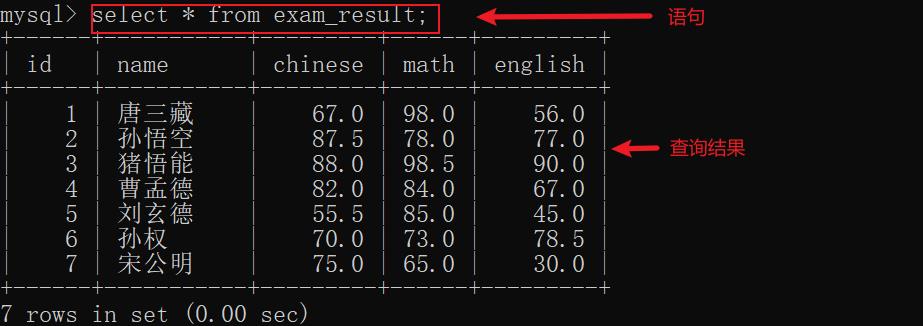
注意:
在生产环境中,谨慎使用上述语句,因为返回的数据可能超大的。如果数据很大的话,就可能把服务器的网络带宽吃满,从而导致服务器无法正常工作。
6.2 指定列查询
示例: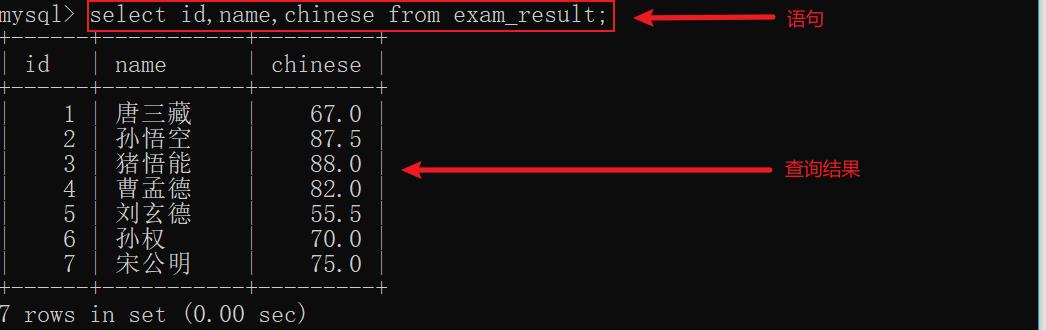
注意:
指定列的顺序不需要按照定义表时的顺序查询
6.3 查询字段为表达式
示例: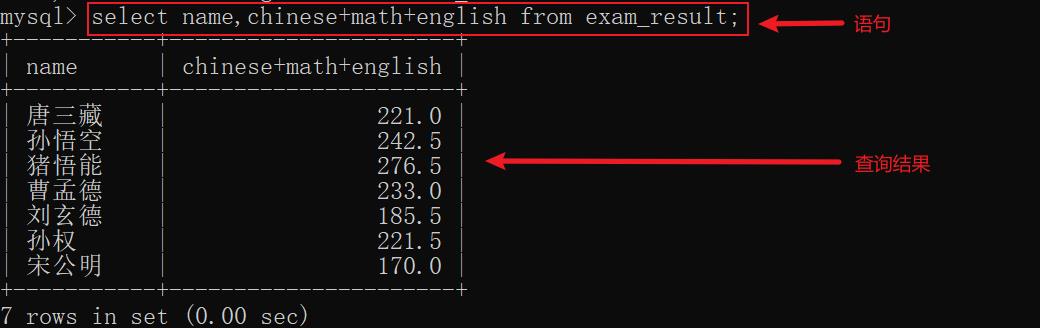
注意:
- 上述
chinese+math+english就是一个表达式,结果就是它们的值相加。但是相加的值不受原来的列的数据类型限制- 表达式是进行列与列之间的运算,与行无关
- 表达式计算不影响原来的数据,查询的结果是一个临时表
6.4 给某个列指定常量
select 时给某个列指定一个常量,此时常量就会作为一个表达式在每行中出现
示例1: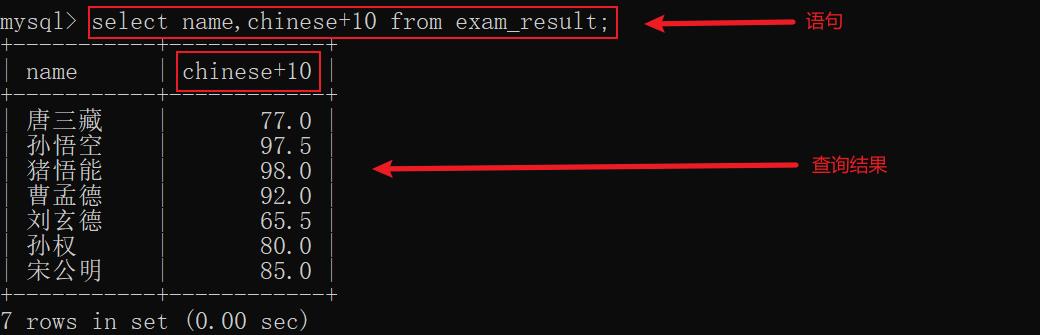
示例2: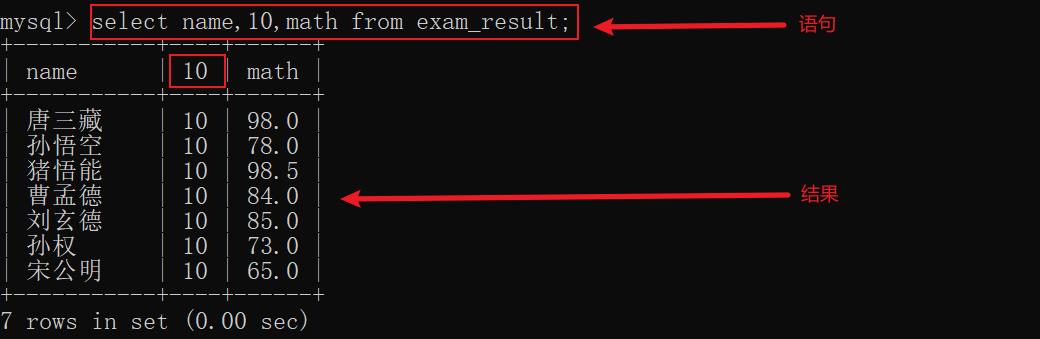
6.5 给查询的表达式指定别名(as)
示例: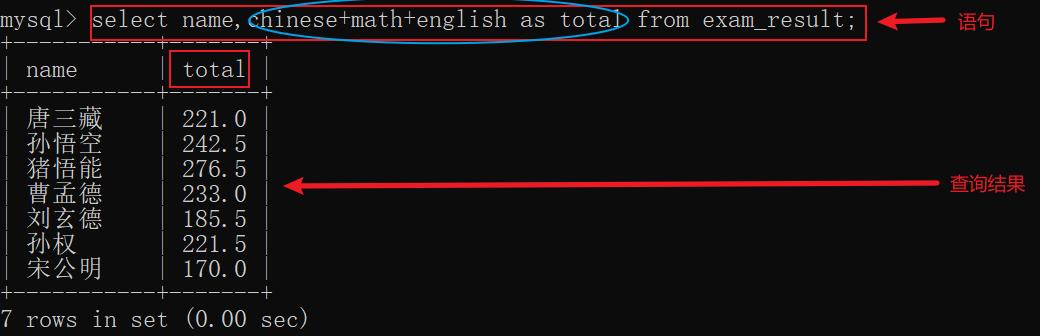
6.6 去重查询(distinct)
使用关键字 distinct 可以把某列相同的值的记录给去重
示例1: 针对某个列去重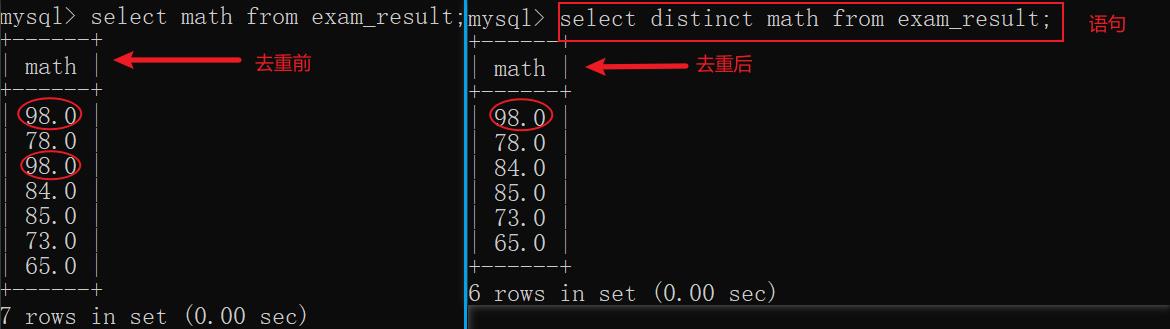
示例2: 针对多个列去重(要求: distinct 要放在所有列的前面,且当每行的每列的值都有其他行的每列的值都相同时,才视为是一个重复的记录)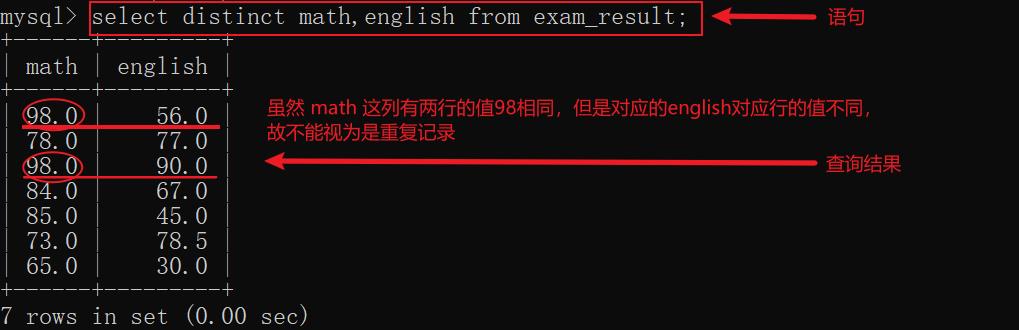
6.7 对查询结果进行排序(order by)
如果我们的查询操作没有加上 order by,此时查询出来的结果顺序是未定的。可以在查询语句的表名后面加上 order by 要排序的列名/表达式 [asc | desc] 来进行排序
补充:
- asc:表示升序(由小到大),不加具体要排序的方式,默认是 asc
- desc:表示降序(由大到小),是 descending 的缩写
- 排序时如果有的值是 NULL,则视其为最小值
- 支持对多个列进行排序,按要排序的列的顺序进行优先级排序,排序的列之间用逗号隔开
- 我们知道很多排序的算法,例如:冒泡、选择、插入、希尔、堆排、快排、归并…而这其中归并排序是最适合 MySQL 进行数据排序的,因为 MySQL 的数据是存储在硬盘上的,而对于硬盘的读写操作,开销很大,为了减少读写次数,所以要找到对于遍历次数更少的排序方法。初次之外由于数据量可能很大,内存一下不能存储完全,就可以对每一段进行排序再存入进去。因此归并排序更加适合 MySQL 对数据进行排序
示例1: 对 math 进行升序查询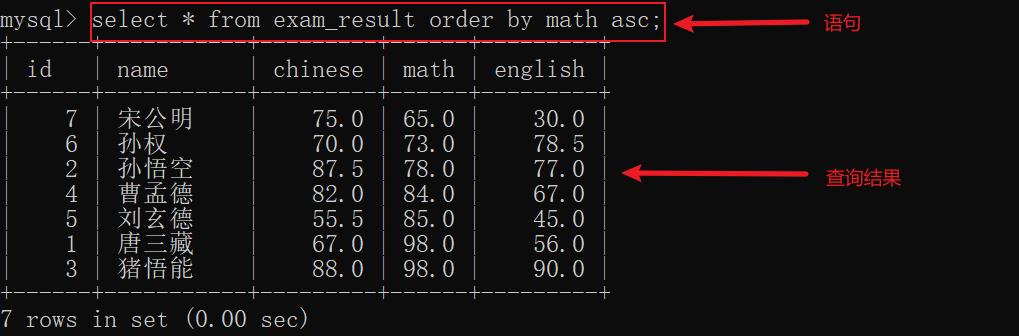
示例2: 对 math 进行降序查找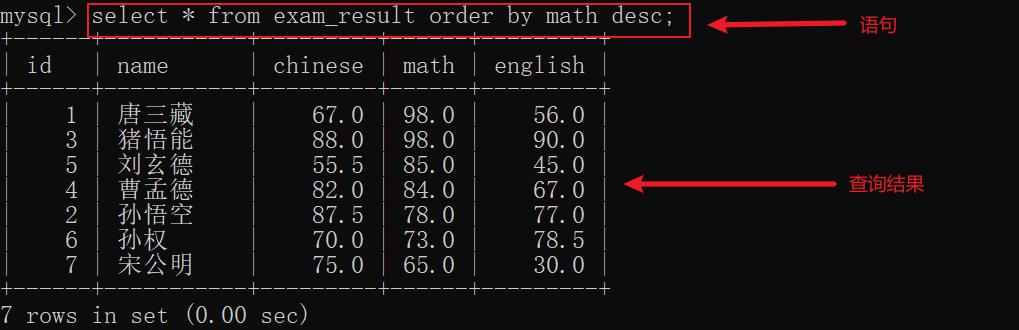
示例3: 使用表达式或者别名进行排序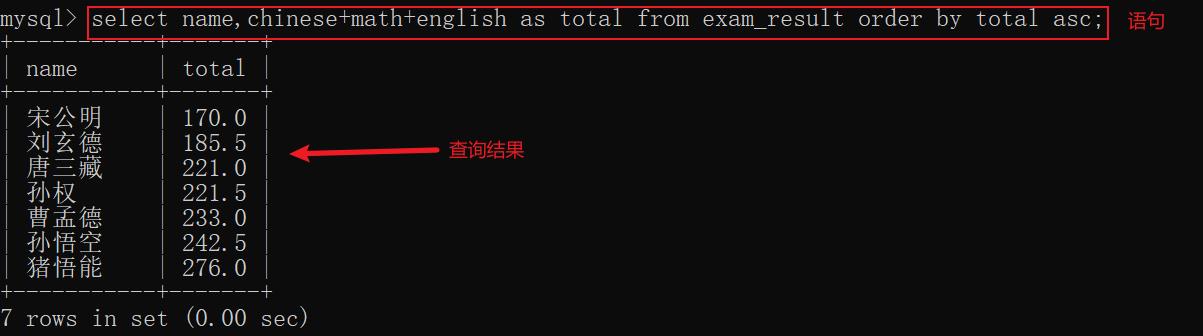
示例4: 对多个列进行综合排序,要求在 math 最高的情况下,再排 chinese 更低的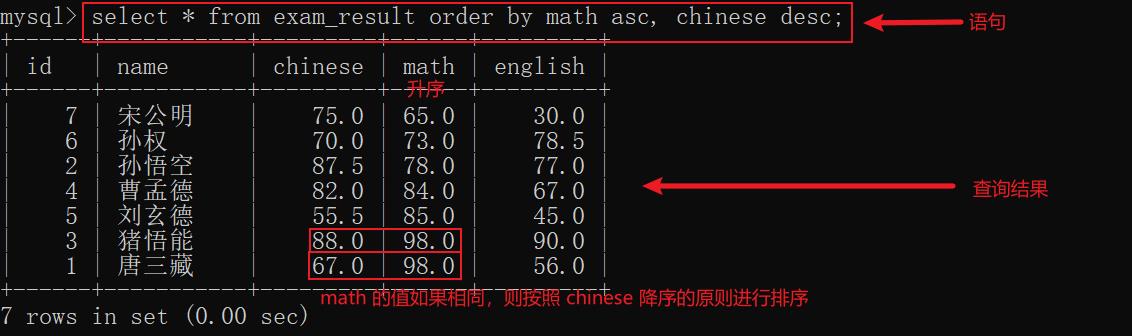
6.8 条件查询(where)
条件查询适用很广,不限于上述几种用法基础之上,例如 update、delete 等语句也可以使用。它是通过 where 条件表达式 的形式,去进行一个筛选,相当于遍历查询结果,针对每一个记录带入到条件中,将符合条件的记录保留下来,不符合的则淘汰。
条件表达式可以使用:比较运算符或者逻辑运算符
比较运算符:
| 运算符 | 说明 |
|---|---|
>、>=、<、<= | 大于、大于等于、小于、小于等于 |
= | 在 where 中表示等于,注意:NULL = NULL,结果是 NULL,相当于是 false |
<=> | 等于,注意:NULL <=> NULL,结果是 true |
!=、<> | 不等于 |
value between a0 and a1 | 如果 a0 <= value <= a1,则结果为 true |
in (option, ...) | 如果是 option 中的任意一个,则返回 true |
is null | 判断是 NULL |
is not null | 判断不是 NULL |
like | 模糊匹配。% 表示任意多个(包括0个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
and | 类似于 Java 中的 &&,多个条件都为 true 时,结果才是 true |
or | 类似于 Java 中的 ||,只要有一个条件为 true,结果就为 true |
not | 类似于 Java 当中的 ~,条件为 true,结果则为 false |
like 常搭配的通配符:
| 通配符 | 说明 |
|---|---|
% | 表示任意多个字符(包含0个) |
_ | 表示任意一个字符 |
补充:
- where 条件可以使用表达式,但不能不使用别名
- and 的优先级高于 or
- and 符号也可以实现 between 的功能,但是 between 其实就是 SQL 对这种范围匹配的一种优化
- 通配符: 即可以使用一个字符去表示其它任意的一个或多个字符,用于模糊搜索
- 模糊匹配涉及到字符串比较,所以当前列里存的字符串比较长时,性能就会大打折扣
- 模糊匹配不一定要求列为字符串类型,例如数值类型也可以,但是语句里面要将 like 后面的模糊搜索的值加引号
- SQL 中的条件相当于是“过滤器”,而不是“逻辑分支”
示例1:查询英语不及格的同学及其成绩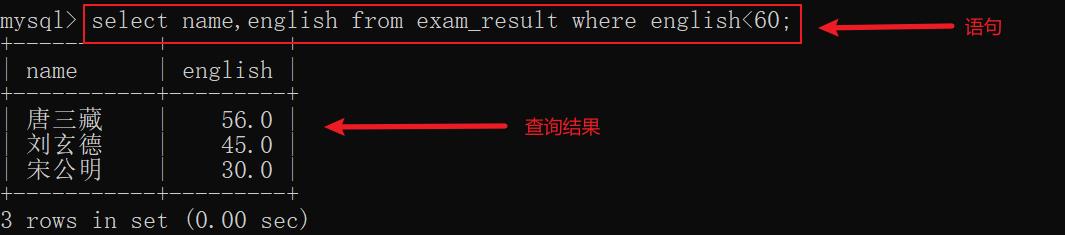
示例2: 查询总分小于200的同学及其总成绩(下述方法不包含值为 NULL)
示例3: 查询总分小于200的同学及其总成绩,且包含值为 NULL 的同学(为了方便展示,这里我主动新增了值为 null 的同学诸葛亮)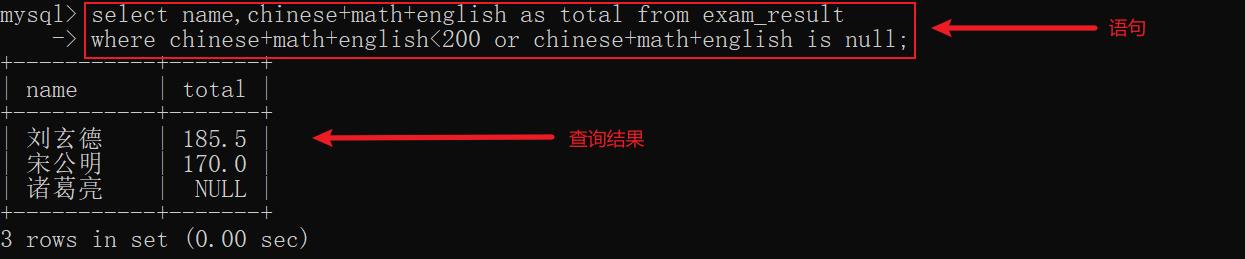
示例4: 查询语文成绩在80到90分之间的同学及其成绩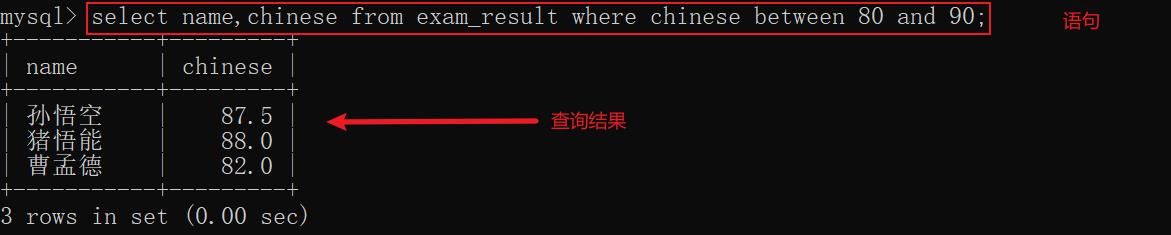
示例5: 查询数学成绩是 98、73和65的同学和成绩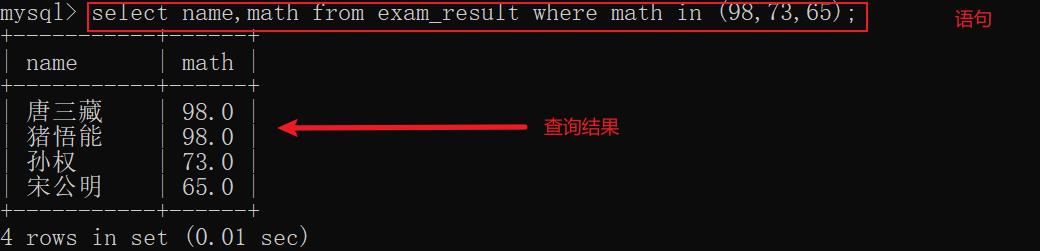
示例6: 查找所有姓孙的同学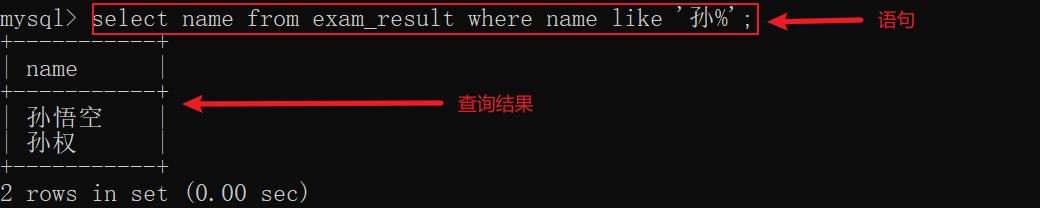
示例7: 查找所有名字以德结尾的同学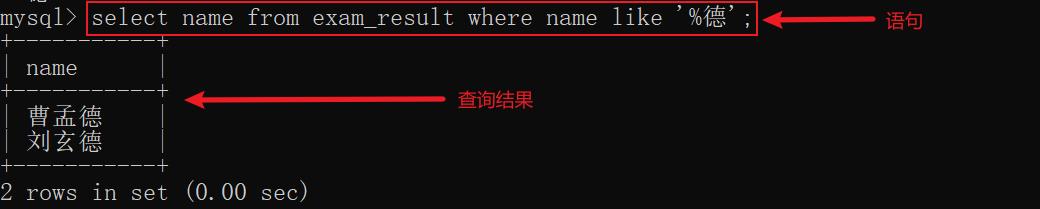
示例8: 查询名字包含悟的同学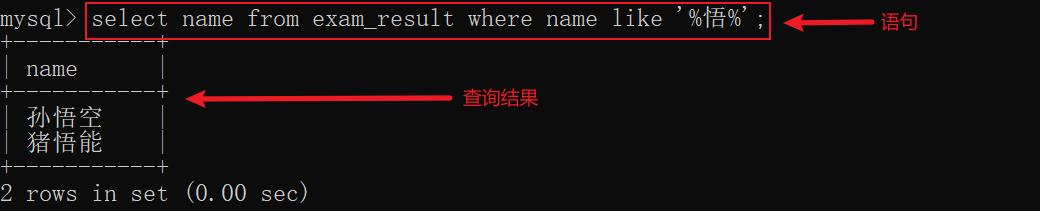
示例9: 查找所有姓孙且名字只有两个字的同学
示例10: 查询数学成绩有90几的同学及数学成绩
6.9 分页查询(limit)
当查询结果很多时,就可以将查询结果分为很多页。
应用场景: 当我们在百度某个东西时,我们发现,搜索的结果很多,为了不一下子得到这么多数据,所以就用到了分页查询
注意: 当要查询的数据量很大时,其实网络开销是很大的,包括:
- 数据库服务器磁盘 IO
- 数据库客户端到数据库服务器的网络 IO
因此通过分页查询就可以限制一次查询的结果数目,来防止较大的网络开销
示例1:limit n 返回查询不多于 n 行的结果(n 表示查询结果的最大数目,默认从行0开始)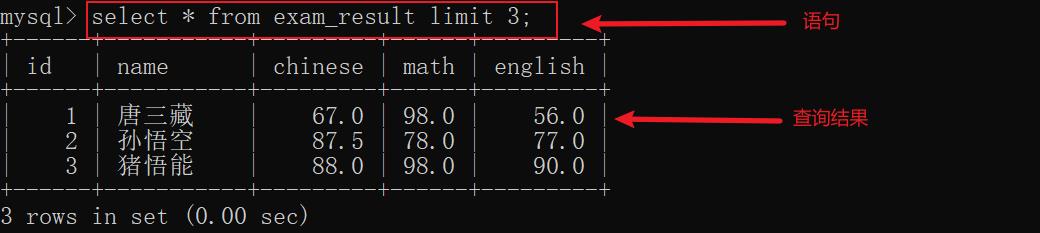
示例2:limit m, n 返回查询从行 m 开始,不多于 n 行的结果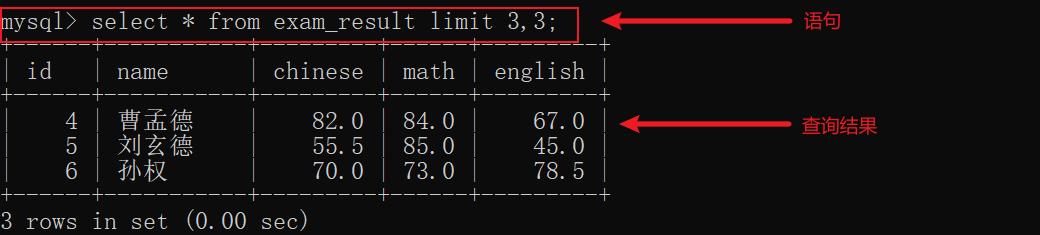
示例3:limit n offset m 返回查询从行 m 开始,不多于 n 行的结果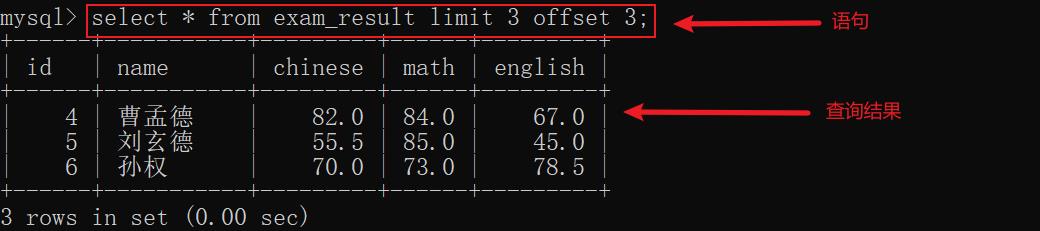
补充:
检索出来的第一行为行0,而不是行1,上述示例2和示例3中的 m,代表行 m 或者 第 m+1 行
7. 修改表中的数据
语法:
update 表名 set 列名1 = 要修改的值 [, ..., 列名n = 要修改的值] [where 条件] [order by ...] [limit...];
补充:
update 会正真修改数据库服务器硬盘的数据
update 中的 =,相当于赋值
如果数据结果为 NULL,在这个基础上进行运算,结果还是 NULL
示例1: 将孙悟空的数学成绩修改成80(修改一个列)
示例2: 将曹孟德的数学成绩改为60,语文成绩改为70(修改多个列)
示例3: 将总成绩倒数前三的3位同学的数学成绩加上10分
示例4: 将所有同学的语文成绩减10
8. 删除表中的数据
语法:
delete from 表名 [where ...] [order by ...] [limit ...]
示例1: 删除孙悟空同学的考试成绩
示例2: 删除整张表数据
注意:
- 删除操作需要很谨慎
- delete from 删表是一条一条删除的,如果数据量很大,删除的速度就很慢。相比之下,直接删表速度更快
以上是关于MySQL 数据库数据表的基本操作(细节满满)的主要内容,如果未能解决你的问题,请参考以下文章