2021年大数据HBase:Apache Phoenix 二级索引
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据HBase:Apache Phoenix 二级索引相关的知识,希望对你有一定的参考价值。
全网最详细的大数据HBase文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
系列历史文章
2021年大数据HBase(十七):HBase的360度全面调优
2021年大数据HBase(十六):HBase的协处理器(Coprocessor)
2021年大数据HBase(十五):HBase的Bulk Load批量加载操作
2021年大数据HBase(十四):HBase的原理及其相关的工作机制
2021年大数据HBase(十三):HBase读取和存储数据的流程
2021年大数据HBase(十二):Apache Phoenix 二级索引
2021年大数据HBase(十一):Apache Phoenix的视图操作
2021年大数据HBase(十):Apache Phoenix的基本入门操作
2021年大数据HBase(九):Apache Phoenix的安装
2021年大数据HBase(八):Apache Phoenix的基本介绍
2021年大数据HBase(七):Hbase的架构!【建议收藏】
2021年大数据HBase(六):HBase的高可用!【建议收藏】
2021年大数据HBase(五):HBase的相关操作-JavaAPI方式!【建议收藏】
2021年大数据HBase(四):HBase的相关操作-客户端命令式!【建议收藏】
前言
2021大数据领域优质创作博客,带你从入门到精通,该博客每天更新,逐渐完善大数据各个知识体系的文章,帮助大家更高效学习。

Apache Phoenix 二级索引
因为没有建立索引,组合条件查询效率较低,而通过使用Phoenix,我们可以非常方便地创建二级索引。Phoenix中的索引,其实底层还是表现为HBase中的表结构。这些索引表专门用来加快查询速度。
一、索引分类
- 全局索引
- 本地索引
- 覆盖索引
- 函数索引
二、索引分类_全局索引
- 全局索引适用于读多写少业务
- 全局索引绝大多数负载都发生在写入时,当构建了全局索引时,Phoenix会拦截写入(DELETE、UPSERT值和UPSERT SELECT)上的数据表更新,构建索引更新,同时更新所有相关的索引表,开销较大
- 读取时,Phoenix将选择最快能够查询出数据的索引表。默认情况下,除非使用Hint,如果SELECT查询中引用了其他非索引列,该索引是不会生效的
- 全局索引一般和覆盖索引搭配使用,读的效率很高,但写入效率会受影响
- 创建语法: CREATE INDEX 索引名称 ON 表名 (列名1, 列名2, 列名3...)
三、索引分类_本地索引
- 本地索引适合写操作频繁,读相对少的业务
- 当使用SQL查询数据时,Phoenix会自动选择是否使用本地索引查询数据
- 在本地索引中,索引数据和业务表数据存储在同一个服务器上,避免写入期间的其他网络开销
- 在Phoenix 4.8.0之前,本地索引保存在一个单独的表中,在Phoenix 4.8.1中,本地索引的数据是保存在一个影子列蔟中
- 本地索引查询即使SELECT引用了非索引中的字段,也会自动应用索引的
- 注意:创建表的时候指定了SALT_BUCKETS,是不支持本地索引的

- 创建语法: CREATE LOCAL INDEX 索引名称 ON 表名 (列名1, 列名2, 列名3...)
四、索引分类_覆盖索引
hoenix提供了覆盖的索引,可以不需要在找到索引条目后返回到主表。Phoenix可以将关心的数据捆绑在索引行中,从而节省了读取时间的开销。
例如,以下语法将在v1和v2列上创建索引,并在索引中包括v3列,也就是通过v1、v2就可以直接把数据查询出来。
CREATE INDEX my_index ON my_table (v1,v2) INCLUDE(v3)-
可以被表中任意的字段构建覆盖 索引, 建立之后, 可以在查询的时候, 不需要在去到主表查询, 可以减少查询的时间, 提升效率, 但是带来弊端, 导致数据出现冗余情况
-
注意: 无法单独使用, 必须结合全局或者本地索引
-
创建语法: create [local] index my_index on 目标表(列1,列2...) include(覆盖索引列....)
五、索引分类_函数索引
函数索引(4.3和更高版本)可以支持在列上创建索引,还可以基于任意表达式上创建索引。然后,当查询使用该表达式时,可以使用索引来检索结果,而不是数据表。例如,可以在UPPER(FIRST_NAME||‘ ’||LAST_NAME)上创建一个索引,这样将来搜索两个名字拼接在一起时,索引依然可以生效。
-- 创建索引
CREATE INDEX UPPER_NAME_IDX ON EMP (UPPER(FIRST_NAME||' '||LAST_NAME)) -- 以下查询会走索引
SELECT EMP_ID FROM EMP WHERE UPPER(FIRST_NAME||' '||LAST_NAME)='JOHN DOE'- 可以针对某一个函数的结果 构建索引, 将结果数据建好索引, 这样当我们使用这个函数时可以直接将结果返回
- 创建语法: create index 索引名称 on 表名(函数)
六、索引案例一: 创建全局索引+覆盖索引
1、需求
我们需要根据用户ID来查询订单的ID以及对应的支付金额。
例如:查询已付款的订单ID和支付金额
此时,就可以在USER_ID列上创建索引,来加快查询
2、创建索引
create index GBL_IDX_ORDER_DTL on ORDER_DTL(C1."user_id") INCLUDE("id", C1."money"); 可以在HBase shell中看到,Phoenix自动帮助我们创建了一张GBL_IDX_ORDER_DTL的表。这种表就是一张索引表
3、查询数据
select "user_id", "id", "money" from ORDER_DTL where "user_id" = '8237476';4、查询执行计划
explain select "user_id", "id", "money" from ORDER_DTL where "user_id" = '8237476';
5、删除索引
使用drop index 索引名 ON 表名
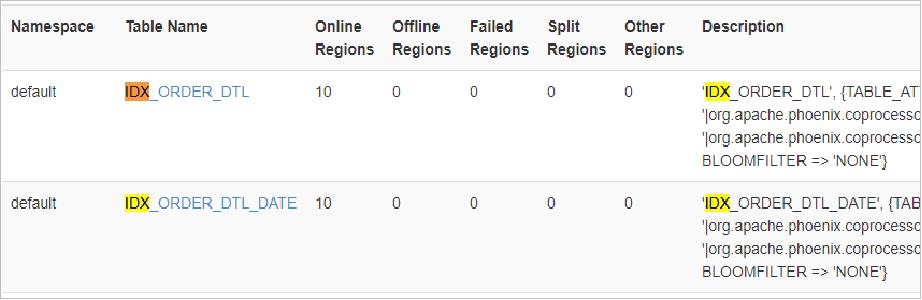
drop index IDX_ORDER_DTL_DATE on ORDER_DTL;6、查看索引
!table
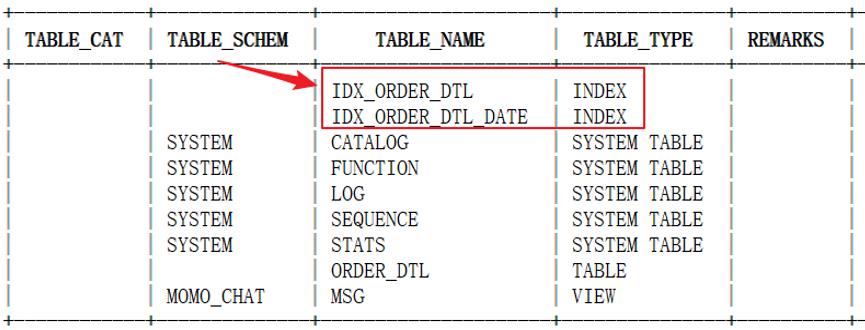
7、测试查询所有列是否会使用索引
explain select * from ORDER_DTL where "user_id" = '8237476';
8、使用Hint强制使用索引
explain select /*+ INDEX(ORDER_DTL GBL_IDX_ORDER_DTL) */ * from ORDER_DTL where USER_ID = '8237476'; 通过执行计划,我们可以观察到查看全局索引,找到ROWKEY,然后执行全表的JOIN,其实就是把对应ROWKEY去查询ORDER_DTL表。
通过执行计划,我们可以观察到查看全局索引,找到ROWKEY,然后执行全表的JOIN,其实就是把对应ROWKEY去查询ORDER_DTL表。
七、索引案例二: 创建本地索引
1、查看数据
explain select * from ORDER_DTL WHERE "status" = '已提交';
explain select * from ORDER_DTL WHERE "status" = '已提交' AND "pay_way" = 1;

通过观察上面的两个执行计划发现,两个查询都是通过RANGE SCAN来实现的。说明本地索引生效
2、删除索引
drop index LOCAL_IDX_ORDER_DTL on ORDER_DTL;八、陌陌案例二级索引构建
1、创建本地函数索引
CREATE LOCAL INDEX LOCAL_IDX_MOMO_MSG ON MOMO_CHAT.MSG(substr("msg_time", 0, 10), "sender_account", "receiver_account");
2、执行数据查询
explain select "C1"."sender_account", "C1"."receiver_account","C1"."msg_time","C1"."message" from "MOMO_CHAT"."MSG" where substr("C1"."msg_time",0,10) = '2021-01-16' and "C1"."sender_account" = '17344828999' and "C1"."receiver_account" = '18040049394';
可以看到,查询速度非常快,0.1秒就查询出来了数据。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据HBase:Apache Phoenix 二级索引的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据HBase:Apache Phoenix的安装
2021年大数据HBase:Apache Phoenix的安装
2021年大数据HBase:Apache Phoenix 二级索引
2021年大数据HBase:Apache Phoenix 二级索引