urllib库如何设置代理&如何传递并保存cookiepython爬虫入门进阶(02-3)
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了urllib库如何设置代理&如何传递并保存cookiepython爬虫入门进阶(02-3)相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
干货满满,建议收藏,需要用到时常看看。 小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~。
前言
上一篇文章我们简单的介绍了urllib库的简单使用,这篇文章同样来简单介绍下urllib库的使用,本文主要侧重于介绍如果设置代理服务器,以及如何传递和保存cookie。
如何设置代理服务器
很多网站都会检测同一个IP的访问次数,如果访问次数过多的话,它会禁止这个IP的访问。IP被禁止了就不能爬取数据了,所以我们需要设置代理服务器,每隔一段时间就更换一个代理,就换这个IP被禁止了,也可以换个IP继续访问。
这里的代理服务器是正向代理,也就是让代理服务器帮我们发起请求。
urllib库中有个ProxyHandler处理器,可以设置代理服务器。
首先,找一个靠谱的代理服务器网站,这里我找了快代理,访问该链接,拉到网站底部,就可以看到代理IP列表了。该列表详细记录了每个代理IP支持的地址,端口,以及支持的请求类型和请求方法。
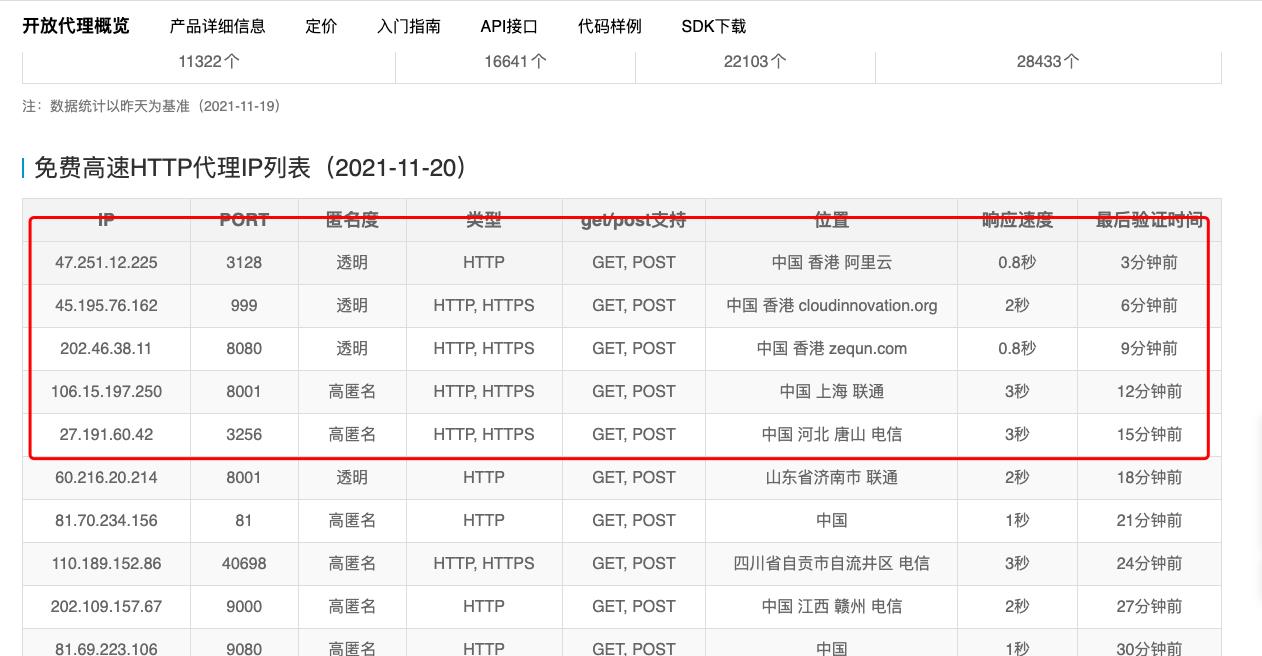
from urllib import request
handle = request.ProxyHandler('http': "111.231.86.149:7890")
ProxyHandler方法支持传入一个字典,字典的key是http或者https。字典的value是代理的IP地址以及代理的端口。
使用代理的正确方式是:
from urllib import request
url = 'http://httpbin.org/ip'
# 1. 使用ProxyHandler,传入代理构建一个handler
handle = request.ProxyHandler('http': "111.231.86.149:7890")
# 2. 使用上面创建的handler构建一个opener
opener = request.build_opener(handle)
# 3. 使用opener去发送一个请求
resp = opener.open(url)
print(resp.read())
- 使用ProxyHandler,传入代理构建一个handler
- 使用第一步创建的handler来构建一个opener。
- 使用opener去发送一个请求。
这里需要介绍一下 http://httpbin.org/ip,该网站是用于测试一个http请求和响应的服务。可以用来在线测试Http的请求。

cookie是什么
http请求是无状态的,即每次请求都是一个全新的请求。但是对于那些需要登录的接口,我们需要通过某种方式将用户的登录信息告诉服务器。cookie就是用来实现处理这种问题的方式。用户登录之后,用户的登录信息会存在浏览器的cookie中,当请求其他需要登录的接口是浏览器会将cookie中的信息放在请求头中随请求传给服务器。
下面就简单介绍下如何实现自动登录以及在请求中传递cookie。
这里以秀展网为例。
未登录的时候是这样子的:

登录之后是这样的
下面就通过爬虫的方式来实现自动登录,登录成功之后访问主页。
- 保存cookie
python中通过http.cookiejar模块来操作cookie的
该模块主要的类有CookieJar,FileCookieJar,MozillaCookieJar、LWPCookieJar 这四个类的作用分别如下: - CookieJar:管理HTTP cookie值,存储HTTP请求生成的cookie,向传出HTTP请求添加cookie的对象,整个cookie都是存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
- FileCookieJar(filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。delayload为True时支持延迟访问文件,即只有需要时才读取文件或在文件中存储数据。
- MozillaCookieJar(filename,delayload=None,policy=None): 从FileCookieJar派生而来,创建与Mozilla浏览器cookie.txt兼容的FileCookieJar实例。
- LWPCookieJar(filename,delayload=None,policy=None): 从FileCookieJar派生而来,创建与libwww-per标准的Set-Cookie3文件格式兼容的FileCookieJar实例。
# 创建CookieJar的处理器
cookiejar = CookieJar()
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
- 登录秀展网
这里的umail表示用户名,upass表示用户密码,需要替换成可用的用户名和密码。
同时这个接口的请求方式是form-data的方法。
# 登录
def login_blog():
url = 'https://www.xiuzhan365.com/userLoad/handle-user-log-in.php'
data =
'umail': '6956',
'upass': '12314132',
'remember': 1
headers =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
"Content-Type": 'application/x-www-form-urlencoded'
req = request.Request(url=url, data=parse.urlencode(data).encode('utf-8'), headers=headers)
resp = opener.open(req)
print(resp.read().decode('utf-8'))
- 访问主页
# 访问主页
def visit_home():
url = 'https://www.xiuzhan365.com/'
req = request.Request(url, headers=head)
resp = opener.open(req)
with open('xiuzhan.html', 'w') as fp:
fp.write(resp.read().decode('utf-8'))
访问主页,并将接口的响应接口保存到xiuzhan.html中。 访问xiuzhan.html页面可以看到如下信息,这就表明此时访问主页是已经是登录的状态了。

这里本质上是使用opener发送多个请求,多个请求之间共享cookie
特别需要注意:
由于https://www.xiuzhan365.com/ 是一个https的链接,如果直接运行的话会报ssl的错误。这里就需要定义一个HTTPSHandler的Handler
并且在生成opener的时候传入。就像下面这样。
import ssl
context = ssl._create_unverified_context()
# 支持https请求
https_handler = request.HTTPSHandler(context=context)
# 保存cookie
cookiejar = CookieJar()
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler, https_handler)
完整代码如下:
from urllib import request, parse
from http.cookiejar import CookieJar
import ssl
context = ssl._create_unverified_context()
# 支持https请求
https_handler = request.HTTPSHandler(context=context)
# 保存cookie
cookiejar = CookieJar()
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler, https_handler)
head =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
# 登录
def login_blog():
url = 'https://www.xiuzhan365.com/userLoad/handle-user-log-in.php'
data =
'umail': '6956',
'upass': '12314132',
'remember': 1
headers =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
"Content-Type": 'application/x-www-form-urlencoded'
req = request.Request(url=url, data=parse.urlencode(data).encode('utf-8'), headers=headers)
resp = opener.open(req)
print(resp.read().decode('utf-8'))
# 访问主页
def visit_home():
url = 'https://www.xiuzhan365.com/'
req = request.Request(url, headers=head)
resp = opener.open(req)
with open('xiuzhan.html', 'w') as fp:
fp.write(resp.read().decode('utf-8'))
if __name__ == '__main__':
login_blog()
visit_home()
保存cookie到文件中
前面说的cookieJar是将cookie信息保存到内存中,如果我们想把cookie信息保存到文件中,那么就需要使用MozillaCookieJar来操作了。
示例代码如下:
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar('cookie.txt')
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
url = 'http://httpbin.org/cookies/set?username=test'
resp = opener.open(url)
cookiejar.save(ignore_discard=True)
这里将cookie信息保存到了cookie.txt文件中,传入ignore_discard参数的话就是将 即将过期的cookie信息也保存起来。
总结
本文简单介绍了如何urllib库如何设置代理&如何传递并保存cookie。希望对读者朋友们有所帮助。
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java高频面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻
以上是关于urllib库如何设置代理&如何传递并保存cookiepython爬虫入门进阶(02-3)的主要内容,如果未能解决你的问题,请参考以下文章
python3下urllib.request库高级应用之ProxyHandler处理器(代理设置)
Python http客户端库requests & urllib2 以及ip地址处理IPy
Python爬虫技术栈 | urllib库&&urllib3库
Python爬虫技术栈 | urllib库&&urllib3库