python3下urllib.request库高级应用之ProxyHandler处理器(代理设置)
Posted 暮良文王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3下urllib.request库高级应用之ProxyHandler处理器(代理设置)相关的知识,希望对你有一定的参考价值。
1. 代理简介
很多网站都会检测某一段时间某个IP的访问次数,如果同一个IP访问过于频繁,那么该网站就会禁止来自该IP的访问,针对这种情况,可以使用代理服务器,每隔一段时间换一个马甲。“他强任他强,劳资会变翔”哈哈哈。
免费的开放代理获取无成本,我们可以收集这些免费代理,测试后如果可以用,用在爬虫上。
免费短期代理网站举例:
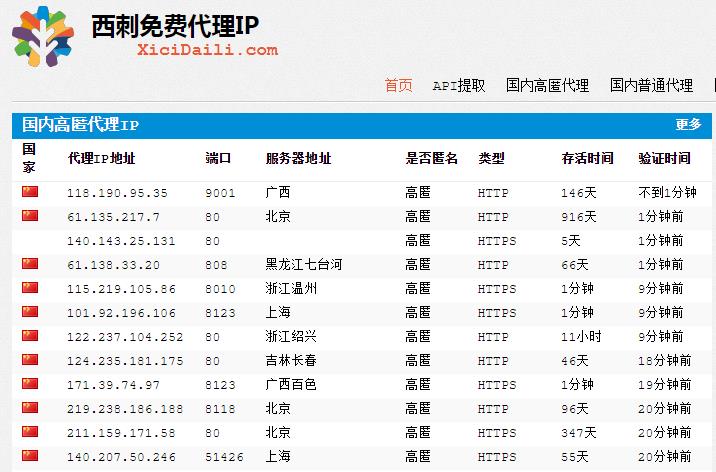
名词解释:
免费短期代理网站分高匿和透明
【高匿】:代表服务器追踪不到你原来的IP;
【透明】:代表服务器可以追踪到你的代理IP和原来的IP;
类型表示支持的类型:HTTP或者HTTPS
【存活的时间】:表示在这个期间可用
2.设置代理服务器
urllib.request中通过ProxyHandler来设置使用代理服务器,下面代码说明如何使用自定义opener来使用代理:
例子1:单个代理IP
1 import urllib.request
2
3 # 构建两个代理Handler,一个有代理IP,一个没有
4 httpproxy_handler = urllib.request.ProxyHandler({"http": "211.141.111.114:61395"})
5 nullproxy_handler = urllib.request.ProxyHandler({})
6 proxy_switch = True # 定义一个代理开关
7
8 # 通过urllib.request.build_opener() 方法创建自定义opener对象
9 # 根据代理开关是否打开,使用不同的代理模式
10 if proxy_switch:
11 opener = urllib.request.build_opener(httpproxy_handler)
12 else:
13 opener = urllib.request.build_opener(nullproxy_handler)
14
15 request = urllib.request.Request("http://www.baidu.com")
16 response = opener.open(request)
17 print(response.read())
注意:
如果程序中所有的请求都使用自定义的opener, 可以使用urllib.install_opener()将自定义的opener定义为全局opener,表示之后凡是调用urlopen,都将使用自定义的opener。
例子2:代理IP列表随机抽取
如果代理IP足够多,就可以像随机获取User-Agent一样,随机选择一个代理去访问网站。
1 import urllib.request
2 import random
3
4 proxy_list = [
5 {"http": "211.141.111.114:61395"},
6 {"http": "61.135.217.7:80"},
7 {"http": "171.39.74.97:8123"},
8 {"http": "218.59.228.18:61976"},
9 {"http": "221.224.136.211:35101"},
10 ]
11
12 # 随机选择一个代理
13 proxy = random.choice(proxy_list)
14
15 # 使用选择的代理构建代理处理器对象
16 httpproxy_handler = urllib.request.ProxyHandler(proxy)
17 opener = urllib.request.build_opener(httpproxy_handler)
18 request = urllib.request.Request("http://www.baidu.com")
19 response = opener.open(request)
20 print(response.read())
这些免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高,HTTP/HTTPS支持不稳定等缺点(免费没好货)。
所以,专业爬虫工程师或爬虫公司会使用高品质的私密代理,这些代理通常需要找专门的代理供应商购买,再通过用户名/密码授权使用。
以上是关于python3下urllib.request库高级应用之ProxyHandler处理器(代理设置)的主要内容,如果未能解决你的问题,请参考以下文章