SQL优化老出错,那是你没弄明白MySQL解释计划
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL优化老出错,那是你没弄明白MySQL解释计划相关的知识,希望对你有一定的参考价值。
摘要:数据库的解释计划阐明了sql的执行过程,展示了执行的细节,只要根据数据库告诉我们的问题按图索骥的分析就可以。
本文分享自华为云社区《轻松搞懂mysql的执行计划,再也不怕sql优化了》,作者:香菜聊游戏。
近期要做一些sql优化的工作,虽然记得一些常用的sql 优化技巧,但是在工作中还是不够,所以需要借助工具的帮助,数据库的解释计划阐明了sql的执行过程,展示了执行的细节,我们只要根据数据库告诉我们的问题按图索骥的分析就好了,但是解释计划也不是那么容易看懂,所以今天就学习下解释计划的一些参数的意义。
1、准备工作
准备三张表,一张角色表,一张装备表,一张基础数据表,这里只展示一些教程中需要的字段,在游戏开发的过程中肯定不止这么几个字段,我想大家都懂的。
角色表:
CREATE TABLE `role` (
`n_role_id` int DEFAULT NULL,
`s_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;装备表:
CREATE TABLE `equip` (
`n_equip_id` int DEFAULT NULL,
`s_equip_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`n_config_id` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;装备配置表
CREATE TABLE `dict_equip` (
`n_equip_id` int DEFAULT NULL,
`s_desc` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;2、初识解释计划
有两种方式可以查看解释计划:
1、命令的方式:explain sql,或者 desc sql ,两个命令都可以,我觉得记住explain比较好,单词很直接。
2、借助工具 Navicat(其他的不熟,估计也有),点击查询窗口的解释,可以不用加关键字explain
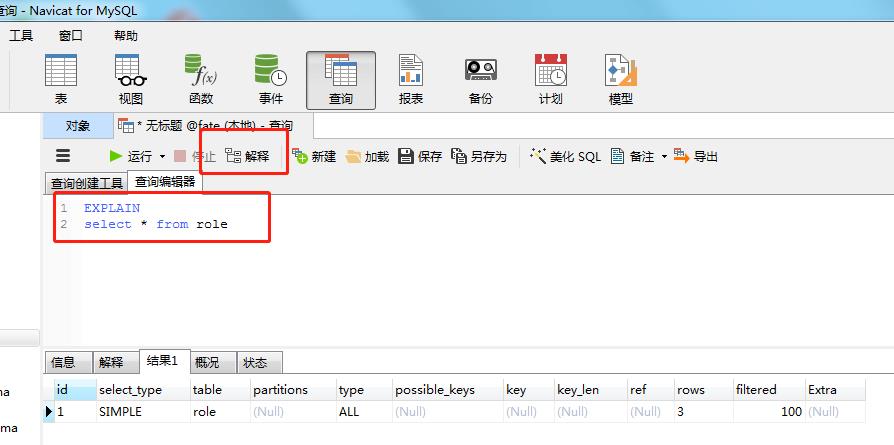
可以看到结果里面包含了很多列,有的是null 有的有值,只要我们看懂了解释计划是不是就可以有的放矢的优化sql。
3、字段详解
解释计划的字段还是蛮多的,Navicat显示了12个字段,有些字段我们需要重点关注,有些知道怎么回事就好了。
官方的文档解释:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
1、id 执行的顺序
id 是select的执行顺序,id越大优先级越高,越先被执行,id 相同时 下面的先执行.
原因是因为执行子查询时,先查内层的,再查外层
SELECT
de.*
FROM
dict_equip de
WHERE
de.n_equip_id = (
SELECT n_equip_id FROM equip e WHERE
e.n_role_id = (
SELECT n_role_id FROM role r WHERE r.s_name = '香菜' )
)
从上面的执行计划可以看到先执行了查询role表,后执行了equip ,最后执行了 dict_equip
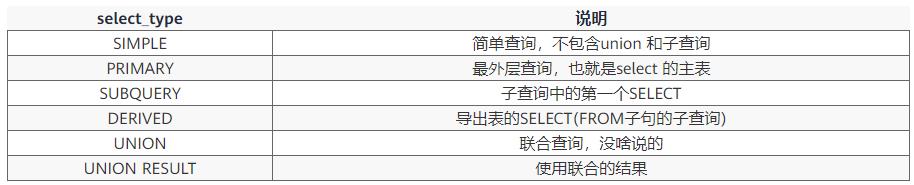
2、select_type select 的类型
3、table 查询涉及的表或衍生表
当前输出的正在使用的表,可以有下面几种:
<unionM,N> : 行数据是联合之后的数据id 处于 m和 n
<derived*N*>: 衍生表
<subqueryN>: 子查询
4、partitions 查询涉及到的分区
在使用分区表的时候才能用到,暂时没用到过这种高级功能。
5、type 查询的类型
表示mysql在表中找到所需行的方式,又称“访问类型”,常见类型如下:
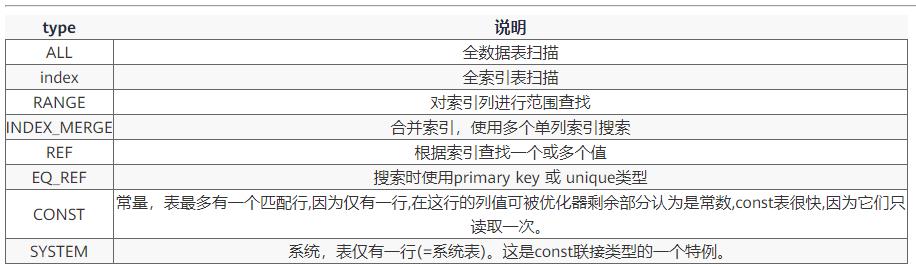
性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
由左至右,由最差到最好
在进行优化的时候如果查询出的数据量大的话可以使用全表扫描,避免使用索引。
如果只是查询很少的数据尽量使用索引。
6、possible_keys:预计可能使用的索引
在不和其他表进行关联的时候,查询表的是可能使用的索引
7、key:实际查询的过程中使用的索引
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
8、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
9、ref 显示该表的索引字段关联了哪张表的哪个字段
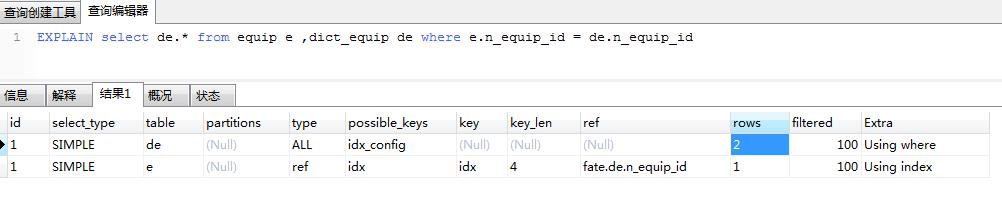
注: 我在equip 和 dict_equip 两张表都分别添加了索引,索引列是n_equip_id
通过上面的执行计划可以看出,首先使用了索引
10、rows:根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好
比如 一个列上 虽然没做索引,但是都是唯一的,这个时候查找的时候如果是全表读取,就是表里有多少数据这个值就是多少,这个时候你需要优化的就是尽可能的读取少的表,可以增加索引,减少读取行数
11、filtered:返回结果的行数占读取行数的百分比,值越大越好
比如全表有100条数据,可能读取了全表数据,但是只有一条匹配上,这个时候百分比就是1,所以你需要让这个比例越大越好,也就是读到的数据尽量都是有用的,避免读取不用的数据,因为IO是很费时的。
12、extra
常见的有下面几种
use filesort:MySQL需要额外的一次传递,以找出如何按排序顺序检索行,如果是这个值,应该优化索引。
use temporary:为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。
use index:从只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的列信息。当查询只使用作为单一索引一部分的列时,可以使用该策略
use where:where子句用于限制哪一行
4、总结
sql 优化的原则就是在保证正确的情况下缩短时间,目标是确定的,通过目标进行回推可以知道想要执行的快就要尽可能的少读数据,减少读取数据的方式大的只有两种过滤和使用索引,在这样的规则范围内进行优化,但是注意索引会占用额外的空间,要平衡好这两者的关系。
以上是关于SQL优化老出错,那是你没弄明白MySQL解释计划的主要内容,如果未能解决你的问题,请参考以下文章