Elasticsearch 脚本安全使用指南
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 脚本安全使用指南相关的知识,希望对你有一定的参考价值。
1、关于 Elasticsearch 脚本实战问题
最近星球群里讨论了脚本的使用。

当看到复杂脚本的时候,我的第一反应是:
类似复杂查询要搞这么复杂吗?
能否前置让 ingest 预处理多花时间,哪怕加个字段?
Elasticsearch 更擅长的是检索,能否让他专注干更擅长的事?
预处理或者写入前的 ETL 能否解决类似问题?
那么问题来了。
Elasticsearch 脚本有没有替代方案?
如何在 Elasticsearch 端限制脚本的使用?
我们可以控制 Elasticsearch 脚本的使用吗?
带着这些疑问,本文展开讲解。
2、Elasticsearch 脚本演变史
| 版本 | 使用脚本类型 |
|---|---|
| < Elasticsearch 1.4 | MVEL 脚本 |
| < Elasticsearch 5.0 | Groovy 脚本 |
| >= Elasticsearch 5.0 | painless 脚本 |
Groovy 的出现是解决MVEL的安全隐患问题;但Groovy仍存在内存泄露+安全漏洞问题。
painless 脚本的官宣时间:2016年9月21日。
正如其名字:无痛。painless 的出现是为了用户更方便、高效的使用脚本。
https://www.elastic.co/cn/blog/painless-a-new-scripting-language
Painless 是一种简单,安全的脚本语言,专为与 Elasticsearch 一起使用而设计。它是 Elasticsearch 的默认脚本语言,可以安全地用于内联(inline)和存储(stored)脚本。
关于 inline 和 stored 的区别,后面会讲解。
Painless特点:
性能牛逼:Painless脚本运行速度比备选方案(包括Groovy)快几倍。
安全性强:使用白名单来限制函数与字段的访问,避免了可能的安全隐患。
可选输入:变量和参数可以使用显式类型或动态 def 类型。
上手容易:扩展了java 的基本语法,并兼容 groove 风格的脚本语言特性。
特定优化:是 ES 官方专为 Elasticsearch 脚本编写而设计。
3、Elasticsearch 使用脚本可能带来的问题?
3.1 语法相对晦涩,实现起来不是特别便捷
从 Elastic 中文社区、各个微信群、QQ群的技术交流可见一斑,几乎隔几天就会有“脚本语法如何使用?”的问题抛出来。
3.2 可能带来性能问题
Elasticsearch 脚本会给集群带来沉重的负担,编写脚本往往仅考虑功能实现层面,而极大可能会忽略或者忘记考虑到它可能需要的资源。
4、Elasticsearch 脚本替换方案
直接上替换方案——空间换时间,在写入前将相关数据尽可能使用 Ingest 管道完成“ETL”抽取、转换、加载“清洗”工作。
这时候读者不免有读者会问:“上来就提方案,你的方案依据是什么?空间换时间仅是你的一家之言,你有什么资格提方案?”
其实这是企业内部讨论方案经常被问到的问题,实际说辞可能会比这要委婉一些。
首先:实践和咨询经验的总结。
其次,官方文档有详细阐述,可以参考如下,为了更精准说明,我保留了英文原文。
If possible, avoid using script-based sorting, scripts in aggregations, and the script_score query.
Scripts are incredibly useful, but can’t use Elasticsearch’s index structures or related optimizations. This relationship can sometimes result in slower search speeds.
If you often use scripts to transform indexed data, you can make search faster by transforming data during ingest instead.
英文释义解读如下:
第一:如果可能,避免使用脚本进行排序、聚合、script_score 类型检索操作。
第二:脚本非常有用,但不能使用 Elasticsearch 的索引结构或相关优化。这有时会导致搜索速度变慢。
第三:如果你经常使用脚本来转换索引数据,则可以通过在 Ingest 数据预处理阶段转换数据来加快搜索速度。
三条解释,清晰明了。
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-search-speed.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/scripts-and-search-speed.html
这里要分为几种情况:
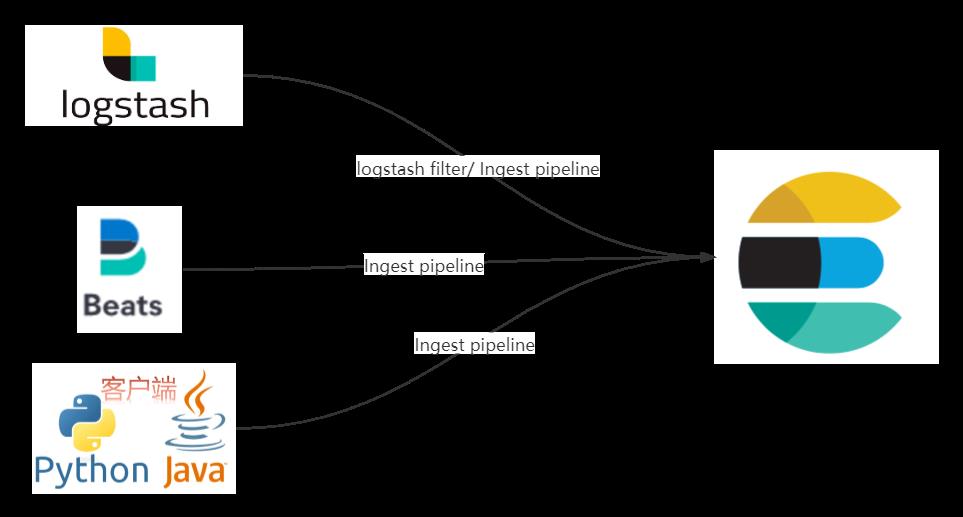
第一:java 或者 python 客户端直连 Elasticsearch。
借助 Ingest pipeline 可以实现写入数据的预处理。
第二:Beats 直连 Elasticsearch。
借助 Ingest pipeline 可以实现写入数据的预处理。
Beats 端输出到 Elasticsearch 配置 pipeline 参考:
output.elasticsearch:
hosts: ["localhost:9200"]
pipeline: my-pipeline第三:logstash 直连 Elasticsearch。
借助 Ingest pipeline 或者 logstash filter 可以实现数据预处理。
那,到底什么是空间换时间呢?
举个栗子进一步解释一把:

以最易理解的学生成绩表为例,要统计每个学生的成绩总和,并要求按照成绩之和排序。
DELETE my_test_scores
# 创建索引并指定 Mapping
PUT my_test_scores
"mappings":
"properties":
"name":
"type": "keyword"
,
"english_score":
"type": "integer"
,
"math_score":
"type": "integer"
# 写入数据
POST my_test_scores/_bulk
"index":"_id":1
"name":"xiaoming","english_score":95,"math_score":85
"index":"_id":2
"name":"xiaowang","english_score":75,"math_score":95
"index":"_id":3
"name":"xiaozhang","english_score":94,"math_score":81
# 按照两门课程成绩之和召回排序结果
GET /my_test_scores/_search
"sort": [
"_script":
"type": "number",
"script":
"source": "doc['math_score'].value + doc['english_score'].value"
,
"order": "desc"
]
# 不用脚本如何搞?
# 更新 Mapping
PUT /my_test_scores/_mapping
"properties":
"total_score":
"type": "long"
# 写入之前管道预处理:两门课程之和字段生成
PUT _ingest/pipeline/sum_score_pipeline
"description": "Calculates the total test score",
"processors": [
"script":
"source": "ctx.total_score = (ctx.math_score + ctx.english_score)"
]
# 数据迁移
POST _reindex
"source":
"index": "my_test_scores"
,
"dest":
"index": "my_test_scores_ext",
"pipeline": "sum_score_pipeline"
GET my_test_scores_ext/_search
# 重新获取排序结果数据
GET /my_test_scores_ext/_search
"sort": [
"total_score":
"order": "desc"
]
如上的示例前半部分使用脚本处理实现。
后半部分使用预处理管道实现,sum_score_pipeline 预处理管道实现了成绩字段的求和操作。
本质上是:新增了total_score 字段,且写入前加了管道的处理。写入会慢一些,但检索的时候就不涉及任何脚本处理,所以是增加空间换来了检索时间的缩短,提升了检索效率。
5、 Elasticsearch 脚本如何安全受控使用?
既然前面提到了脚本的使用弊端和“空间换时间”前置预处理的替换解决方案。
那么问题来了,作为集群管理人员或者研发团队的Boss,能否做到整个集群禁用脚本呢?
这个脑洞可以!实际也是可以实现的,操作层面实现参考如下内容。
5.1 大前提——Elasticsearch 安全原则
安全无小事,“小心驶得万年船”。
1、在启用安全的前提下运行 Elasticsearch。
使用 XPack 的免费的精简安全(配置登录账号和密码)、基础安全(SSL层面)功能。
2、不要使用 root 账号登录 Elasticsearch。
即便可以实现,但安全风险把控角度,强烈不建议。
3、不要暴露集群的公网 IP。
尽可能保持 Elasticsearch 的隔离,最好是在防火墙和 VPN 之后使用 Elasticsearch。
关于“裸奔”的危害,看这里:你的Elasticsearch在裸奔吗?
4、实施基于角色的方案控制策略。
Kibana 就可能快捷上手配置,包含但不限于:Space(空间)、Role(角色)、Privelege(访问权限)。
字段级别的权限是收费功能,其他都是免费的。
5.2 限制允许运行的脚本类型
这个也是我的知识盲点,我也是近期才关注到的。
Elasticsearch 支持两种脚本类型:内联(inline)和存储(stored)。
默认情况下,Elasticsearch 配置为运行这两种类型的脚本。
相信读者读到这里会和我一样一脸懵逼,啥叫 inline?啥叫 stored?inline 和 stored 有什么区别?

5.2.1 stored 类型脚本
所谓:stored 存储类型的脚本。就是先定义好脚本,“存储起来”,后面可以用,当然也可以不用。
用的时候指定 id 来取就可以。
如下示例延续上面的例子。
定义脚本,实现成绩求和。
POST _scripts/sum_score_script
"script":
"lang": "painless",
"source": "ctx._source.total_score=ctx._source.math_score + ctx._source.english_score"
批量全量更新,更新时使用刚才定义的脚本 id(这里本质就是 stored 类型脚本)。
POST my_test_scores/_update_by_query
"script":
"id": "sum_score_script"
,
"query":
"match_all":
检索,验证脚本是否生效。
GET my_test_scores/_search5.2.2 inline 类型脚本
批量全量更新,更新时使用刚才定义的脚本 id。
POST my_test_scores/_update_by_query
"script":
"lang": "painless",
"source": "ctx._source.total_score=ctx._source.math_score + ctx._source.english_score"
,
"query":
"match_all":
检索,验证脚本是否生效。
GET my_test_scores/_search对比 stored 类型,inline 脚本就是使用的时候直接指定脚本,不存在提前创建脚本的说法。
知道了两者的区别,如何做限制呢?
5.2.3 脚本分级限制
如下使用的配置:script.allowed_types 是 集群配置层面 elasticsearch.yml 的配置,不支持动态更新配置。
第一:默认配置,没有任何限制。
等价于:
script.allowed_types: both如果你想保留现状,脚本不做任何使用限制,那就无需更改任何配置。
第二:部分限制。
要限制运行的脚本类型,请将 script.allowed_types 设置为内联(inline)或存储(stored)。
script.allowed_types: inline如果仅设置支持:inline,再创建 stored 类型脚本就会报错。
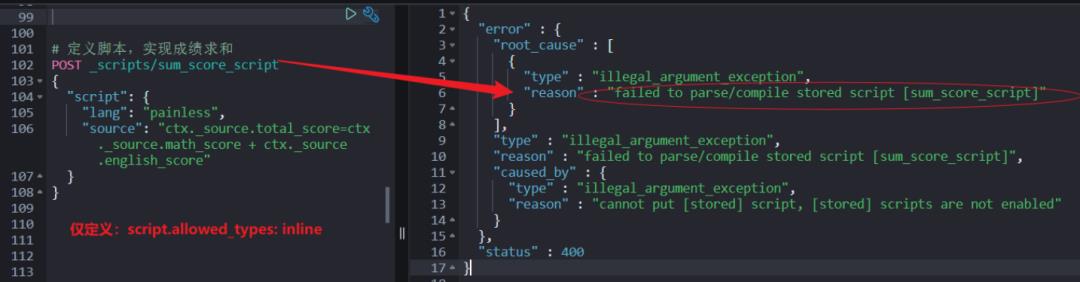
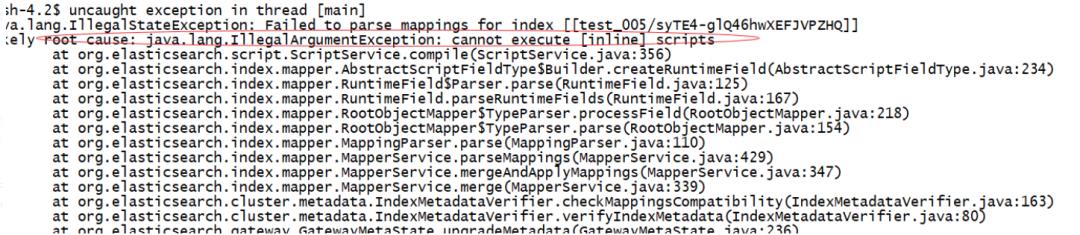
如果仅设置支持:stored,集群启动就会报错。
如果您使用 Kibana,请将 script.allowed_types 设置为 both 或 inline。
因为:某些 Kibana 功能依赖于内联脚本,如果 Elasticsearch 不允许内联脚本,则无法按预期运行。
第三:完全禁止。
要阻止任何脚本运行,请将 script.allowed_types 设置为 none。
script.allowed_types: none5.3 控制可以运行脚本的可用范围
范围有哪些?举例:
scoring:计算评分。
update :更新操作。
Ingest processor:管道预处理。
reindex:索引迁移。
sort:排序。
metric aggregation map:指标聚合。等等......
默认情况下,使用范围是没有任何限制的。
如果全部范围都不允许使用,可以配置如下:
script.allowed_contexts: none如果仅允许部分使用,比如只允许评分、更新使用脚本,可以配置如下:
script.allowed_contexts: score, update如上几条,就实现了脚本的受控的使用,实战环节结合当前业务需求和未来扩展业务需求,谨慎选型。
6、小结
对于脚本来说,要辩证的看待。存在即为合理,有应用场景就会有新的 feature。
如果没有准实时的要求的业务场景,多半都会接受延时写入,但对检索响应慢会“深恶痛绝”。
遇到类似问题的时候,多在建模、设计阶段花时间。建议不要把问题都抛到检索的时候实现,一方面:脚本实现起来的确有性能问题;另一方面:脚本处理的方式已然不是 Elasticsearch 最擅长的事。
可以选择 logstash filter 环节做数据的预处理 或者借助 pipeline 实现写入数据的预处理。
空间换时间,推荐使用 Ingest 管道预处理的方式在写入前尽可能的对字段实时预处理。
选型阶段多考虑选型 Elasticsearch 终极目的和初衷,使用过程中发挥 Elasticsearch 优势,且要确保优势最大化。
PS:细心的 Elastic 爱好者会发现 Elasticsearch 的官方文档在往条理更加清晰、模块更加分明的方向努力,这样我们的学习有了更新的、更大的动力!
参考
https://opster.com/guides/elasticsearch/best-practices/elasticsearch-all-script-types-allowed/
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting-security.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/es-security-principles.html
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、Elasticsearch 7.X 进阶实战私训课(口碑不错)
3、干货 | Elasticsearch7.X Scripting 脚本使用详解
4、Elasticsearch 线上问题实战——如何借助 painless 更新时间?

更短时间更快习得更多干货!
已带领71位球友通过 Elastic 官方认证!
中国仅通过百余人

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch 脚本安全使用指南的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch使用 Elasticsearch Painless 脚本以递归方式遍历 JSON 字段
Elasticsearch全文检索技术 一篇文章即可从入门到精通(Elasticsearch安装,安装kibana,安装ik分词器,数据的增删改查,全文检索查询,聚合aggregations)(代码片
Elasticsearch:如何使用 shell 脚本来写入数据到 Elasticsearch 中
Elasticsearch进阶篇 | 记一次kibana执行dsl脚本实战过程