Spatial Transformer Networks(STN)-代码实现
Posted Paul-Huang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spatial Transformer Networks(STN)-代码实现相关的知识,希望对你有一定的参考价值。
Spatial Transformer Networks(STN)-代码实现
-
pytorch为了方便实现STN,里面封装了
affine_grid和grid_sample两个高级API。 -
STN的基本步骤是:
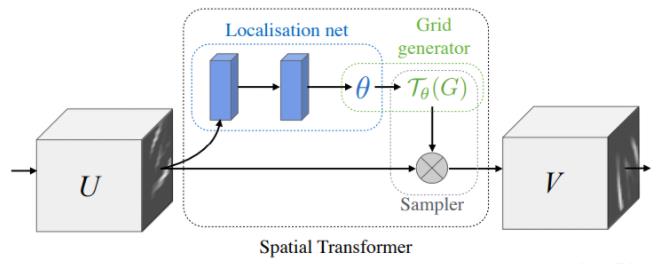
-
L o c a l i s a t i o n n e t \\colorblueLocalisation\\;net Localisationnet(参数预测):
Localisation net模块通过 C N N CNN CNN提取图像的特征来预测变换矩阵 θ \\theta θ -
G r i d g e n e r a t o r \\colorgreenGrid\\;generator Gridgenerator(坐标映射):
Grid generator模块就是利用Localisation net模块回归出来的 θ \\theta θ参数来对图片中的位置进行变换,输入图片到输出图片之间的变换,需要特别注意的是这里指的是图片像素所对应的位置。 -
S a m p l e r \\colorgraySampler Sampler(像素的采集):
Sampler就是用来解决Grid generator模块变换出现小数位置的问题的。针对这种情况,STN采用的是双线性插值(Bilinear Interpolation),下面我们来介绍一下这个算法
1. STN层的实现
from torchvision import transforms
import torch.nn.functional as F
import torch
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
#读取图片
img = Image.open("img/test.jpg")
#将图片转换为torch tensor
img_tensor = transforms.ToTensor()(img)
#定义平移变换矩阵
#0.1表示将图片向左平移图片宽的百分比
#0.2表示将图片向上平移图片高的百分比
theta = torch.tensor([[1,0,0.1],[0,1,0.2]],
dtype=torch.float)
#根据变换矩阵来计算变换后图片的对应位置
grid = F.affine_grid(theta.unsqueeze(0),
img_tensor.unsqueeze(0).size(),align_corners=True)
#默认使用双向性插值,可以通过mode参数设置
output = F.grid_sample(img_tensor.unsqueeze(0),
grid,align_corners=True)
plt.figure()
plt.subplot(1,2,1)
plt.imshow(np.array(img))
plt.title("original image")
plt.subplot(1,2,2)
plt.imshow(output[0].numpy().transpose(1,2,0))
plt.title("stn transform image")
plt.show()

2. STN+CNN
当输入图片通过STN模块之后获得变换后的图片,然后我们再将变换后的图片输入到 C N N CNN CNN网络中,通过损失函数计算 l o s s loss loss,然后计算梯度更新 θ \\theta θ参数,最终STN模块会学习到如何矫正图片。
2.1 参数设置
config.py
import argparse
def parse_args():
parse = argparse.ArgumentParser("config stn args")
parse.add_argument("--lr",default=0.01,
type=float,help="learning rate")
parse.add_argument("--epoch_nums",default=20,
type=int,help="iterated epochs")
parse.add_argument("--use_stn",default=True,
type=bool,help="whether to use STN module")
parse.add_argument("--batch_size",default=64,
type=int,help="batch size")
parse.add_argument("--use_eval",default=True,
type=bool,help="whether to evaluate")
parse.add_argument("--use_visual",default=True,
type=bool,help="visual STN transform image")
parse.add_argument("--use_gpu",default=True,
type=bool,help="whether to use GPU")
parse.add_argument("--show_net_construct",default=False,
type=bool,help="print net construct info")
return parse.parse_args()
2.2 加载数据
DataLoader.py
import torch
from torchvision import datasets,transforms
import numpy as np
def get_dataloader(batch_size):
# 加载数据集
# 如果GPU可用就用GPU,否则用CPU
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# 加载训练集
train_dataloader = torch.utils.data.DataLoader(
datasets.MNIST(root="D:\\PyCharm\\PyCharm_Project\\STN", train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=batch_size, shuffle=True)
# 加载测试集
test_dataloader = torch.utils.data.DataLoader(
datasets.MNIST(root="D:\\PyCharm\\PyCharm_Project\\STN", train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=batch_size, shuffle=True)
return train_dataloader,test_dataloader
def tensor_to_array(img_tensor):
img_array = img_tensor.numpy().transpose((1,2,0))
mean = np.array([0.485,0.456,0.406])
std = np.array([0.229,0.224,0.225])
img_array = std * img_array + mean
img = np.clip(img_array,0,1)
return img
2.3 定义网络
Net.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class STN_Net(nn.Module):
def __init__(self,use_stn=True):
super(STN_Net, self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(10,20,kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320,50)
self.fc2 = nn.Linear(50,10)
#用来判断是否使用STN
self._use_stn = use_stn
#localisation net
#从输入图像中提取特征
#输入图片的shape为(-1,1,28,28)
self.localization = nn.Sequential(
#卷积输出shape为(-1,8,22,22)
nn.Conv2d(1,8,kernel_size=7),
#最大池化输出shape为(-1,1,11,11)
nn.MaxPool2d(2,stride=2),
nn.ReLU(True),
#卷积输出shape为(-1,10,7,7)
nn.Conv2d(8,10,kernel_size=5),
#最大池化层输出shape为(-1,10,3,3)
nn.MaxPool2d(2,stride=2),
nn.ReLU(True)
)
#利用全连接层回归\\theta参数
self.fc_loc = nn.Sequential(
nn.Linear(10 * 3 * 3,32),
nn.ReLU(True),
nn.Linear(32,2*3)
)
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1,0,0,0,1,0]
,dtype=torch.float))
def stn(self,x):
#提取输入图像中的特征
xs = self.localization(x)
xs = xs.view(-1,10*3*3)
#回归theta参数
theta = self.fc_loc(xs)
theta = theta.view(-1,2,3)
#利用theta参数计算变换后图片的位置
grid = F.affine_grid(theta,x.size())
#根据输入图片计算变换后图片位置填充的像素值
x = F.grid_sample(x,grid)
return x
def forward(self,x):
#使用STN模块
if self._use_stn:
x = self.stn(x)
#利用STN矫正过的图片来进行图片的分类
#经过conv1卷积输出的shape为(-1,10,24,24)
#经过max pool的输出shape为(-1,10,12,12)
x = F.relu(F.max_pool2d(self.conv1(x),2))
#经过conv2卷积输出的shape为(-1,20,8,8)
#经过max pool的输出shape为(-1,20,4,4)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)),2))
x = x.view(-1,320)
x = F.relu(self.fc1(x))
x = F.dropout(x,training=self.training)
x = self.fc2(x)
return F.log_softmax(x,dim=1)
2.4 训练模型
train.py
import torch,torchvision
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
def train(net,epoch_nums,lr,train_dataloader,per_batch,device):
#使用训练模式
net.train()
#选择梯度下降优化算法
optimizer = optim.SGD(net.parameters(),lr=lr)
#训练模型
for epoch in range(epoch_nums):
for batch_idx,(data,label) in enumerate(train_dataloader):
data,label = data.to(device),label.to(device)
optimizer.zero_grad()
pred = net(data)
loss = F.nll_loss(pred,label)
loss.backward()
optimizer.step()
if batch_idx % per_batch == 0:
print('Train Epoch: [/ (:.0f%)]\\tLoss: :.6f'.format(
epoch, batch_idx * len(data), len(train_dataloader.dataset),
100. * batch_idx / len(train_dataloader), loss.item()))
2.5 评估模型
evaluate.py
import torch
import torch.nn.functional as F
def evaluate(net,test_dataloader,device):
with torch.no_grad():
#使用评估模式
net.eval()
eval_loss = 0
eval_acc = 0
for data,label in test_dataloader:
data,label = data.to(device),label.to(device)
pred = net(data)
eval_loss += F.nll_loss(pred,label,
size_average=False).item()
pred_label = pred.max(1,keepdim=True)[1]
eval_acc += pred_label.eq(label.view_as(pred_label)
).sum().item()
eval_loss /= len(test_dataloader.dataset)
print('\\nTest set: Average loss: :.4f, Accuracy: / (:.0f%)\\n'
.format(eval_loss, eval_acc, len(test_dataloader.dataset),
100. * eval_acc / len(test_dataloader.dataset)))
2.6 可视化
Visualize.py
import torch,torchvision
import matplotlib.pyplot as plt
from DataLoader import tensor_to_array
def visualize_stn(net,dataloader,device):
with torch.no_grad():
data = next(iter(dataloader))[0].to(device)
input_tensor = data.cpu()
t_input_tensor = net.stn(data).cpu()
in_grid = tensor_to_array(torchvision.utils.make_grid(
input_tensor))
out_grid = tensor_to_array(torchvision.utils.make_grid(
t_input_tensor))
f,axarr = plt.subplots(1,2)
axarr[0].imshow(in_grid)
axarr[0].set_title("input images")
axarr[1].imshow(out_grid)
axarr[1].set_title("stn transformed images")
plt.show()
2.7 主函数
MAIN.py
import torch
from Net import STN_Net
from Visualize import visualize_stn
from train import train
from config import parse_args
from DataLoader import get_dataloader
from evaluate import evaluate
if __name__ == "__main__":
args = parse_args()
if args.use_gpu and torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
#加载数据集
train_loader,test_loader = get_dataloader(args.batch_size)
#创建网络
net = STN_Net(args.use_stn).to(device)
#训练模型
train(net,args.epoch_nums,args.lr,train_loader
,args.batch_size,device)
if args.use_eval:
#评估模型
evaluate(net,test_loader,device)
if args.use_visual:
#可视化展示效果
visualize_stn(net,test_loader,device)
Test set: Average loss: 0.0423, Accuracy: 9868/10000 (99%)
