OPPO大数据计算集群资源调度架构演进
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OPPO大数据计算集群资源调度架构演进相关的知识,希望对你有一定的参考价值。
1 背景
随着公司这两年业务的迅速扩增,业务数据量和数据处理需求也是呈几何式增长,这对底层的存储和计算等基础设施建设提出了较高的要求。本文围绕计算集群资源使用和资源调度展开,将带大家了解集群资源调度的整体过程、面临的问题,以及我们在底层所做的一系列开发优化工作。
2 资源调度框架---Yarn
2.1 Yarn的总体结构
从大数据的整个生态体系来说,hadoop处于离线计算的核心位置。为了实现大数据的存储和计算,hadoop1.0提供了hdfs分布式存储以及mapreduce计算框架,虽然整体具备了大数据处理的雏形,但还不支持多类型的计算框架,如后来的spark、flink,这个时候也并没有资源调度的概念。
到了hadoop2.0,为了减轻单台服务节点的调度压力,兼容各个类型的调度框架,hadoop抽离出了分布式资源调度框架---YARN(Yet Another Resource Negotiator)。Yarn在整个架构中所处的地位如图1:

图1:Hadoop生态体系
Yarn通过优化后的双层调度框架,将hadoop1.0中原本需要执行资源调度和任务调度的单点JobTracker分为Resourcemanager和ApplicationMaster两个角色,分别负责集群总体的资源调度和单个任务的管理调度,而新增的Nodemanager角色负责各计算节点的管理。Yarn任务提交流程如图2:
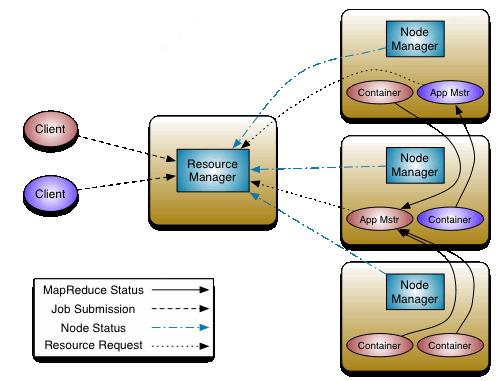
图2:Yarn任务提交过程
客户端提交的任务实际由Resourcemanager直接处理,Resourcemanager为每一个任务启动ApplicationMaster,任务资源申请由ApplicationMaster直接负责,这样,各个框架通过实现自己的ApplicationMaster来管理任务,申请container作为资源,就能成功在yarn集群将任务运行起来,资源的获取对任务完全透明,任务框架和yarn完全解耦。
2.2 Yarn的调度策略
Yarn对于任务的调度在开源版本实现了3种策略,分别为先进先出(FIFO Scheduler)、容量调度(Capacity Scheduler)和公平调度(Fair Scheduler),经过社区版本演化,目前公平调度已经按队列级别实现了公平机制,我们集群采用的正是公平调度策略。
在了解几种调度策略之前我们先理解一个概念:队列。在Yarn中,队列其实就是指资源池,如果把整个集群的资源看做大的资源池的话,Yarn会根据用户配置把这个资源池进一步划分成小的资源池;父队列可以进一步向下划分,子队列会继承父队列的资源并且不会超过父队列的最大资源,整个资源队列的组织形式就像一颗多叉树。
先进先出和容量调度策略分别按任务提交顺序和为任务划分队列的方式来组织任务,这两种方式对生产环境来说并不是十分适用,因为我们的目的是让尽可能多的任务运行起来,并且尽量充分利用集群资源,而这两种策略分别会导致任务堵塞以及资源浪费。
生产环境中的公平调度遵循这样一种规则:保证任务资源分配的公平,当小任务提交过来没资源时,调度器会将大任务释放的资源留给小任务,保证了不会让大任务一直占有资源不释放。三种调度策略的组织形式如图3:
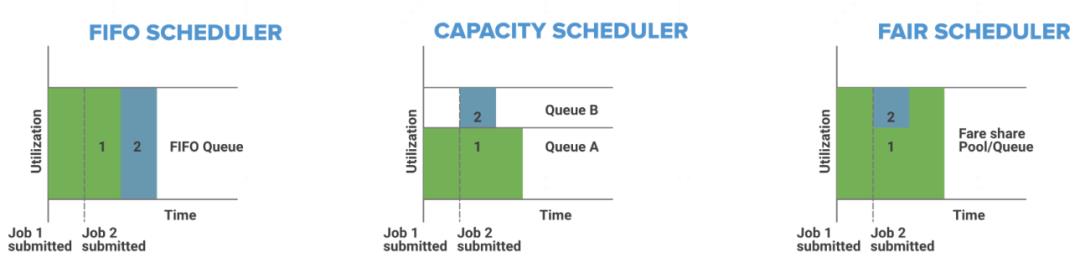
图3:Yarn的三种调度策略
公平调度除了上述所说保证任务间的资源公平之外,还会动态调整队列大小,保证队列间的资源公平,调整依据是集群实时负载,当集群闲时,队列基本能获得配置的最大资源值;当集群忙时,调度器优先满足队列最小值,满足不了时会根据配置的最小值等参数来平均分配。
2.3 Yarn的联邦调度
在单个集群到达数千节点规模时,单台Resourcemanager实际已经接近了调度的性能瓶颈,要想进一步扩大集群规模社区给出的方案是通过联邦调度横向扩展。该方案的核心就在于Router,对外,Router提供了任务提交的统一入口;对内,Router管理了多套集群,实际任务由Router负责转发,转发到哪个集群由Router来决定。Router的实际工作流程如图4:
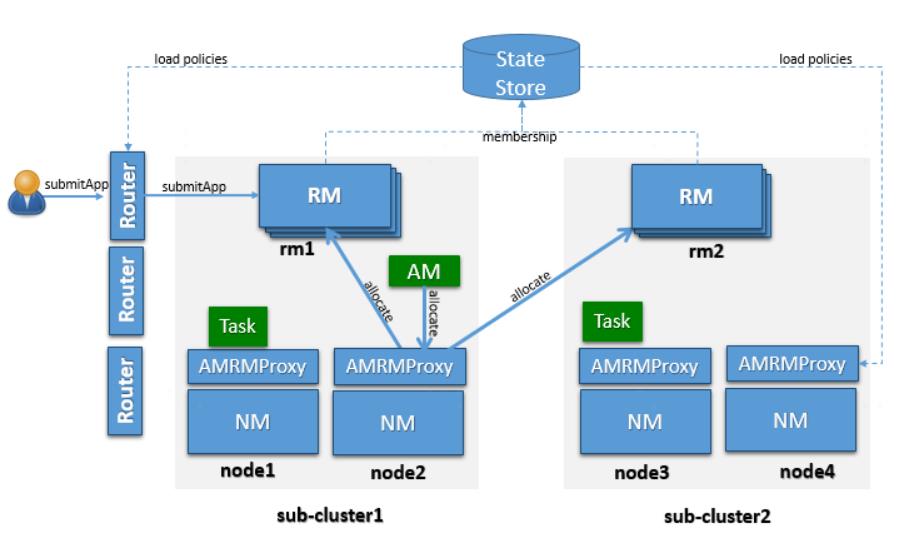
图4:Yarn的联邦调度
可以看到,通过Router管理的联邦调度方式,集群的概念实际已经对用户透明,并且在当某个集群出现问题时,Router能通过配置及时进行故障转移,将任务路由到健康的集群,从而保证了整体集群的对外服务稳定性。
3 OPPO计算集群现状
3.1 集群规模和现状
经过两年多的集群建设,目前我们的集群已经达到了比较可观的规模,在这样的集群规模下,维护稳定性其实是第一要务,我们对集群做了不少稳定性方面的工作,如权限管控、各项重要指标监控等。
除了部分稳定性建设的工作之外,另一个重点关注的是集群资源使用率,当前大部分集群资源使用有比较明显的周期性规律,从图5的集群监控能看出集群经常凌晨繁忙而白天相对空闲。
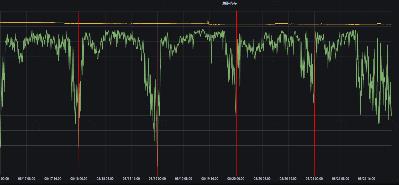
图5:单个集群资源使用率变化图
集群高峰期的资源紧张问题仅依靠集群内部自身协调其实能取得的效果有限,我们针对这种情况是考虑在凌晨高峰期与k8s联合调度,将空闲的在线资源协调部分到离线集群,后文将对该方案进行详细描述。
3.2 集群pending问题
除了高峰期的资源紧张,我们发现在白天也会出现队列任务大量pending的情况,我们对具体的pending任务进行分析,总结出了以下3种导致任务pending的问题:
1)队列配置不合理:
根据公平调度机制,队列的实时可用资源很大程度由配置的最小值决定,某些队列配置的最小值过小或为0会直接导致队列无法获取足够的资源。
另外,如果队列配置的CPU和内存比例与实际执行的任务CPU内存比差距过大,也会导致资源不足任务无法运行。
2)用户突然向某一队列提交大量任务,资源使用量超出队列上限:
这种情况实际上与用户自身的使用有关,当自身的任务量加大后,向我们提出申请来扩充队列是比较合适的。
3)有大任务占住资源不释放,导致后续提交的任务申请不到启动资源:
Spark或者Flink任务与传统的Mapreduce任务运行机制不太一样,这两类任务会长期占有资源不释放,导致新提交任务无法及时获取到资源。针对该问题,我们也设计了相应的资源抢占机制,后文详述。
总体来说,队列配置很大程度上影响了作业的运行,合理地优化配置往往能达到事半功倍的效果。
3.3 集群资源使用率现状
从上文看出监控中的集群大部分时间都处于繁忙状态,但是我们通过统计单台服务器的资源使用,发现还有很多资源的空余,如图6所示:
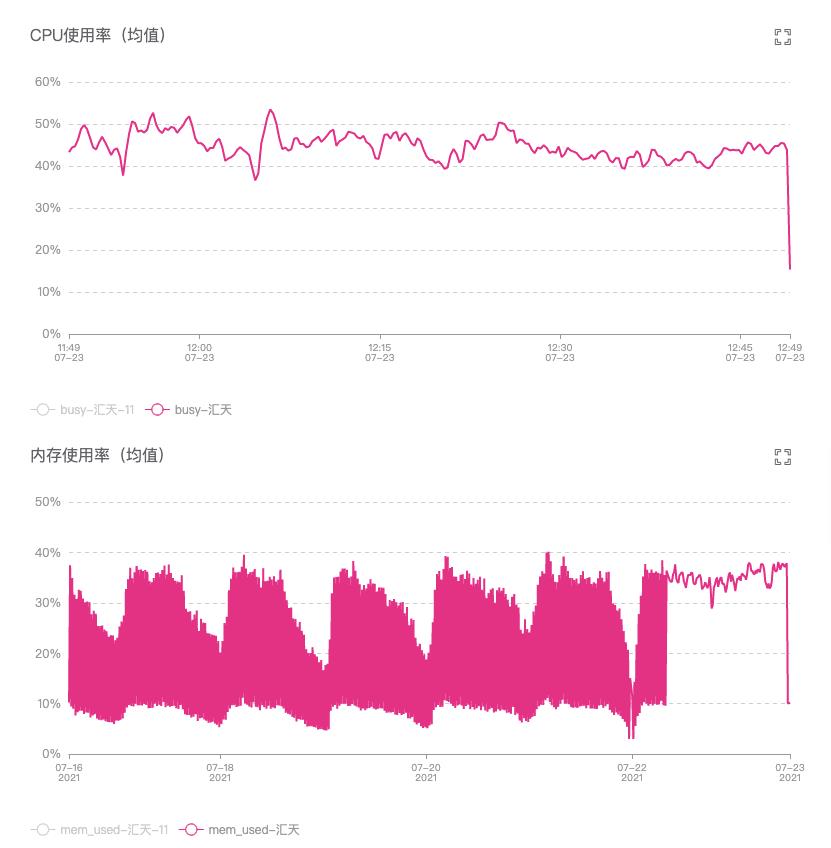
图6:单台服务器CPU和内存使用率
导致该问题的原因实际是用户作业申请的资源经常远超过实际需要的资源,我们统计发现95%的Container实际利用率低于76%, 99%的Container实际利用率低于90%。表明作业申请的资源大小存在"虚胖"问题。这部分浪费的资源如果能利用起来,其实能极大提高集群资源使用率。我们针对这部分浪费资源的优化利用也会在后续一并讨论。
4 Yarn的优化之路
4.1 Yarn联邦调度的优化
社区的联邦调度方案对于我们来说过于简单,只是实现了简单的加权随机路由。在后续计划中,我们会把更多的资源接入路由集群中,Router服务会提供统一个队列和任务管理,用户只需要把任务统一提交到Router集群,而不用关系具体到哪个集群。Router会统计所有集群的状态和负载,寻找合适的资源调度给任务。
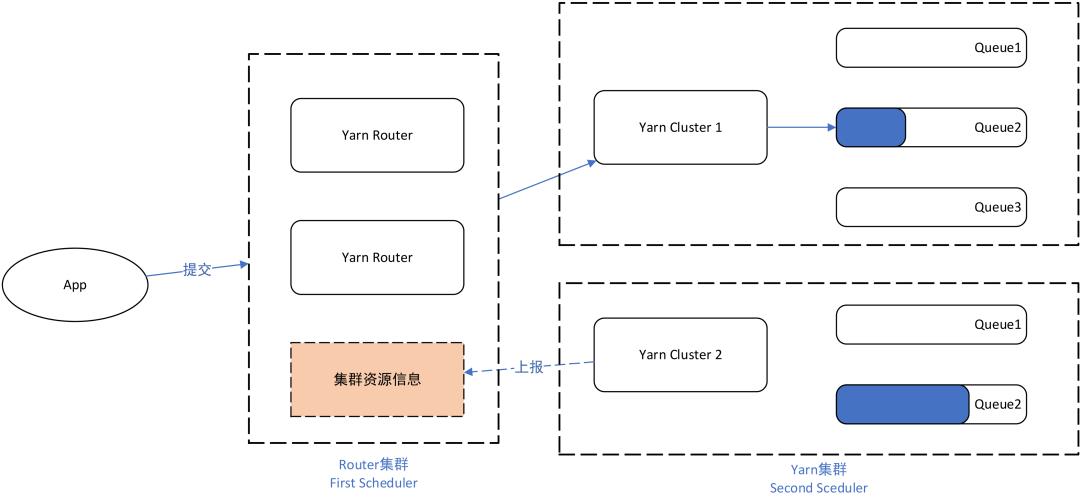
图7:Yarn router动态路由
4.2 资源编配和超卖
资源变配和资源超卖的目的是为了提升每个节点的实际资源使用效率。
资源变配:基于历史的统计值,在调度资源时,调整分配给container的资源更接近container实际需求的资源。经过我们的实践,资源变配可以提升10-20%的资源使用效率。
资源超卖:每个container运行时,都会产生一定的碎片,nodemanager可以将自己管理资源碎片收集起来,插入一些额外的container上去。我们计划通过一个额外的碎片调度器来完成这个过程,在碎片比较多时,启动一些额外的container,碎片如果减少,这些额外container会被回收掉。
图8:资源限售
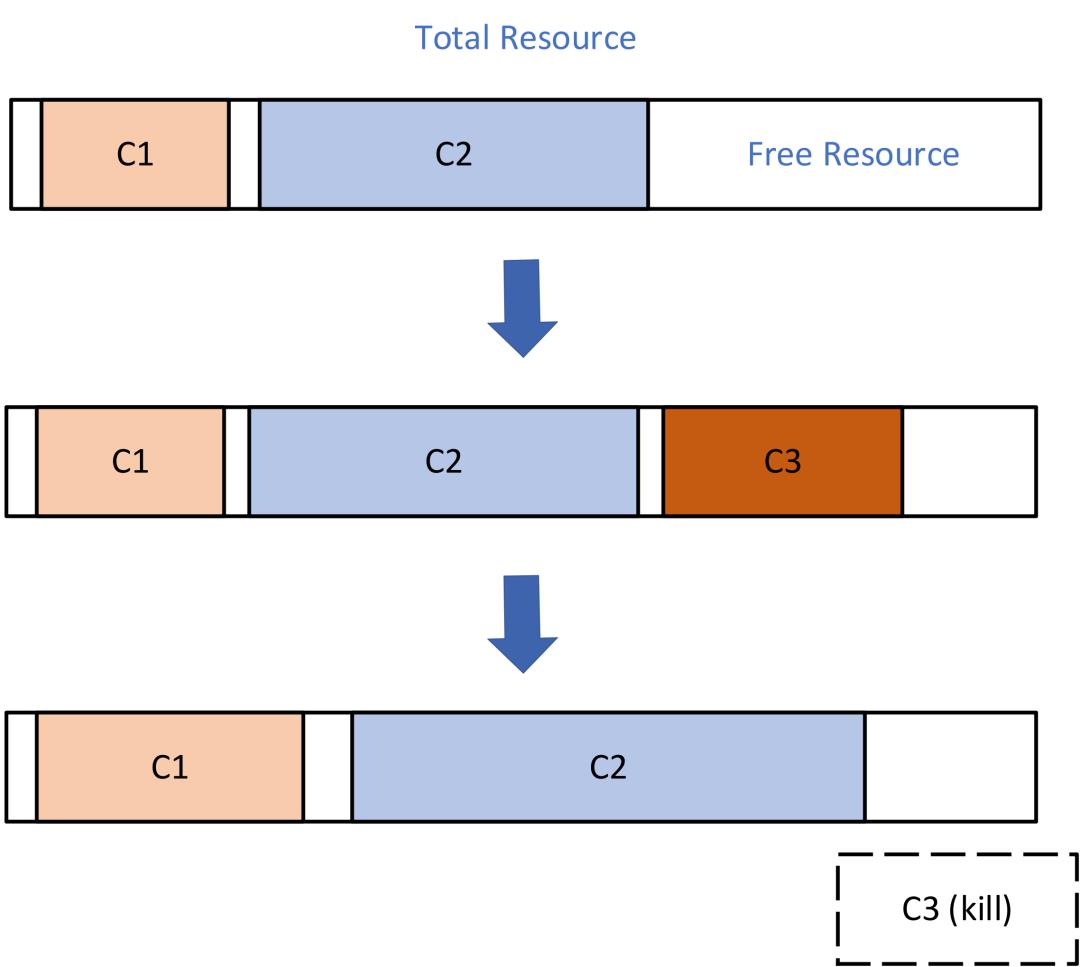
图9:资源超卖
4.3资源动态扩缩
为了解决资源波峰波谷的问题,我们正在与云平台合作,实现一个在线离线资源的混部框架,通过错峰的资源调度,提升资源的整体使用率。调度过程主要通过Yarn Router和OKE两个服务协调完成,在实时资源有空闲而离线资源紧张时,Yarn会向OKE申请资源,实时资源紧张时,OKE会向YARN申请回收这部分资源。同时,我们引入了自研的Remote Shuffle Service来提升动态Nodemanager的稳定性。
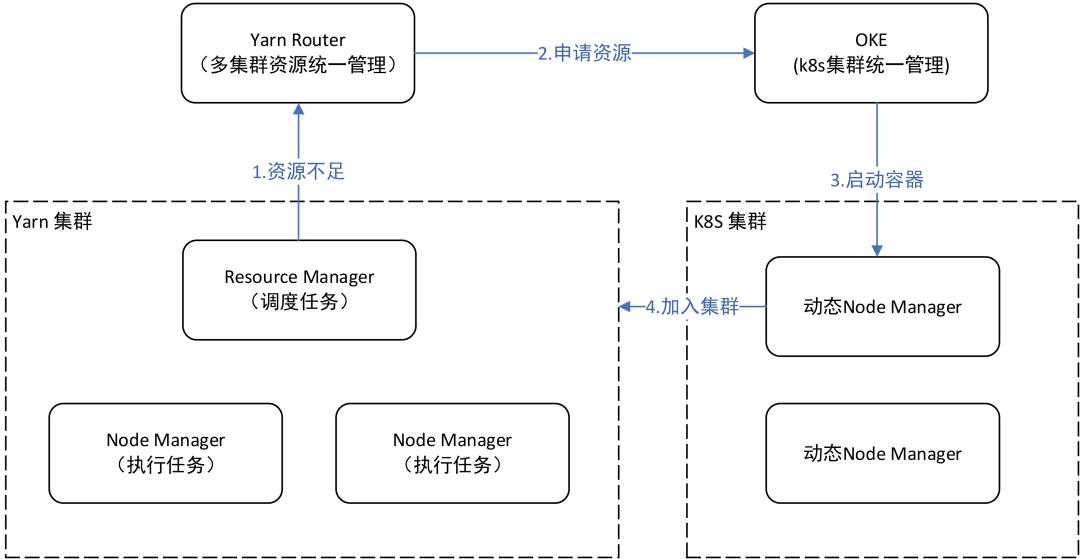
图10:Yarn动态扩缩容
4.4 任务优先级管理
在实践过程中,我们发现用户任务会有明显的优先级区别,因此我们计划实现一个基于优先级的公平调度器,来保障高优先级任务的运行延时和效率。一个队列下的资源会优先保障高优先级任务,统一优先级的任务之间公平分配资源。同时,我们也实现了任务抢占功能,即使低级任务已经拿到了资源,高级别任务也可以用抢占调度来强行获取资源。
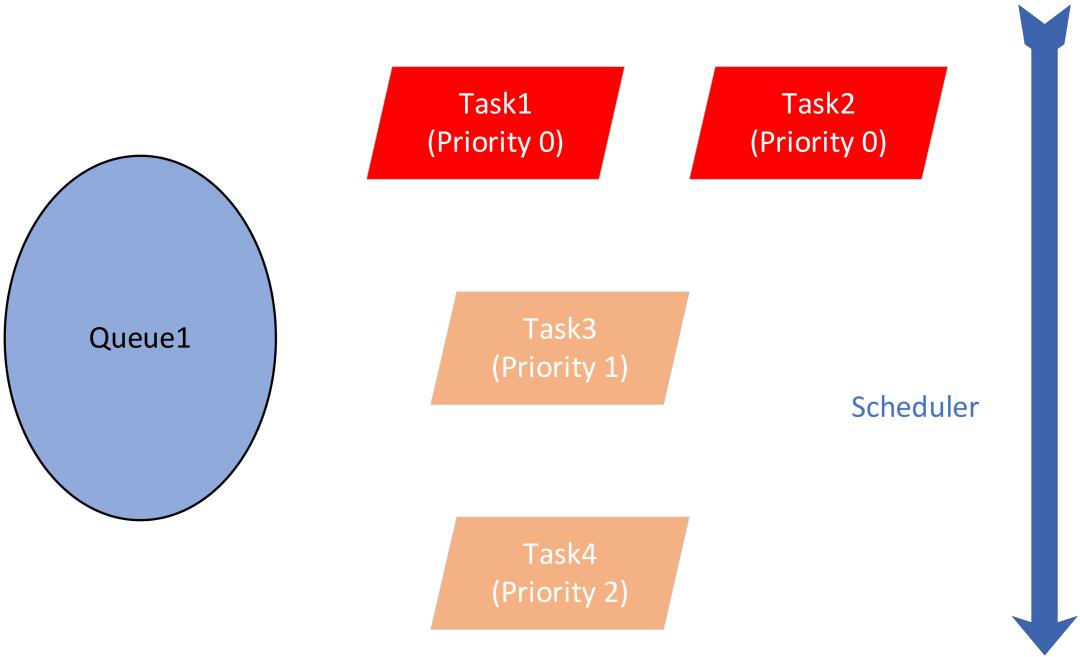
图11:基于优先级的公平调度
4.5 队列权限管理
Oppo yarn权限采用神盾统一鉴权,每个用户组在神盾申请队列权限。用户通过hive,livy,或者flink等客户端直接提交的任务,都会在神盾系统上进行用户的认证和队列的鉴权,无权限的用户会被拒绝访问。
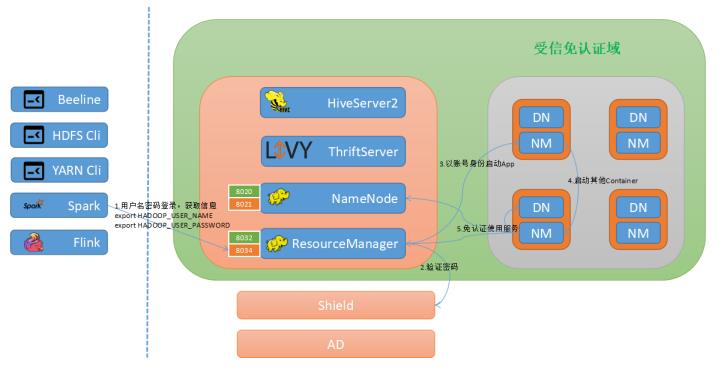
图12:Yarn队列权限管理
5 总结
本文主要介绍了Yarn的基本工作原理及Yarn在OPPO的落地实践,总体来说可以归纳为以下几点:
1)Yarn作为典型的双层调度架构,突破了单层调度架构的资源和框架限制,使作业的运行和资源分配更加灵活。
2)如何优化作业pending与如何使资源利用最大化是所有调度系统都会面临的问题,对此,我们可以从自己系统本身特点来分析,寻找适合自己的解决方案。我们认为分析可以基于现有的数据统计。
3)离线和在线业务的错峰特性决定了单项业务无法充分利用所有服务器资源,通过合适的调度策略组织这些资源将会极大降低服务器成本。
以上是关于OPPO大数据计算集群资源调度架构演进的主要内容,如果未能解决你的问题,请参考以下文章