ZYNQ+NVME存储方案设计
Posted HeroKern
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZYNQ+NVME存储方案设计相关的知识,希望对你有一定的参考价值。
1.概述
很久没有写文章了,有空余时间还是分享一点技术干货。今天写一下zynq+nvme高速存储设计思想,zynq处理器是将ARM和FPGA集成在一起的处理器,区别于以前ARM+FPGA的板间架构,采用AXI内部总线实现ARM和FPGA内部的通讯,支持低速AXI-GP接口(类型Local Bus),高速AXI-HP接口,ARM端简称PS,FPGA端简称PL。如果数据过PS端,那么数据会经过HP接口,软件上的数据解析和拷贝,这样存储速率大约为130MB/s,速率比较慢,所以就引入了本文方案,控制走PS,数据PL实现分流操作。
2.方案设计
存储方案使用处理器为xilinx公司的xz7045芯片,SSD选用m.2接口的固态硬盘,SSD盘支持pcie接口和nvme协议,SSD盘挂载到PL,数据输入挂载到PL,PL的PCIe IP支持接口2.0,PS运行Linux操作系统。本次存储方案采用linux文件系统进行管理,使用文件系统接口,通过读写文件就能实现数据的下盘和导出操作。FPGA将数据缓存在DDR中,PS直接控制数据从FPGA直接写入到SSD,从而实现高速存储,存储方案如图 1所示。
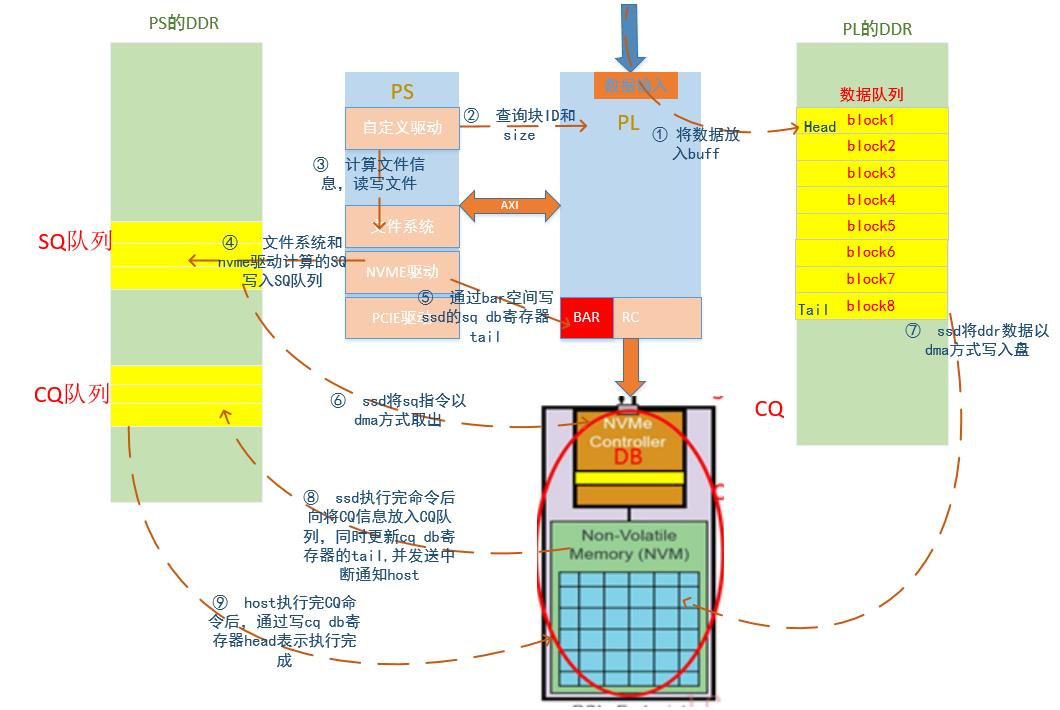
a)fpga收到GTX数据后,先通过三路FIFO(1K),通过轮询FIFO的方法将数据缓存到ddr。fpga在DDR中分配了8个8M大小block,8个缓存块做循环队列使用,fpga收到数据后依次往block中填写数据,当block ID超出队列大小时,又从队列头ID1开始存放数据,这里不存在缓存被耗尽还没有下盘情况,如果有那就是方案不合理。
b)当有一个block存放满时,PL将该ID值和数据大小写入到对应寄存器。Linux驱动查询到寄存器有数据时,通过地址映射表得到地址信息,然后将需要写数据的地址挂入下盘队列中,然后通过异步IO方式通知应用层需要写数据。
c)Linux应用程序根据数据类型打开对应的文件,然后向从队列中取出地址信息,然后向该地址写入指定数据大小
d)文件系统收到指令后将需要写的文件拆分成对应nvme指令,通过nvme驱动填写nvme sq队列。
e)Nvme驱动将sq指令填充完成后,将通过ssd的bar寄存器写SQ门铃寄存器Tail通知ssd nvme控制器取数据。
f)Ssd以DMA方式从SQ队列中将SQ指令取到nvme控制器,并且执行,指定完成后更新SQ门铃寄存器Head。
g)SSD nvme控制器解析SQ指令得到PRP地址,以DMA方式将PL DDR中的数据写入SSD盘,这里比较特殊,当PCIE Host接收到映射表中的地址的DMA请求,应当按照地址映射表将地址请求转换到对应的DDR缓存ID上的请求。只有数据才需要地址转换。
h)执行完成SQ命令后将执行结果状态以DMA方式写入到CQ指令到CQ队列,并且更新CQ的门铃寄存器Tail,同时发送中断通知Host有新的CQ指令到来。
i)Host收到CQ中断后从CQ队列头部取出CQ指令,并且执行CQ指令,CQ指令执行完成后通过BAR寄存器更新CQ门铃寄存器的Head。执行CQ指令将会上报应用态本次数据交互是否正常。
3.FPGA设计
FPGA设计包括,DDR乒乓设计,PCIE接口转BRAM,高速GTX接口等。vivado设计框图如下所示。
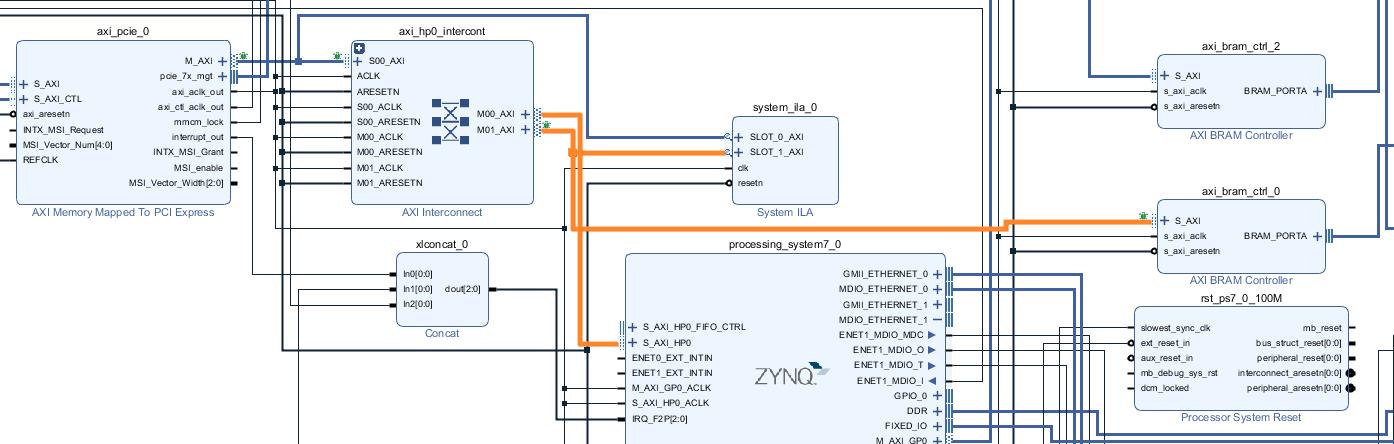
这里展现的是局部框图,这里有个细节需要注意,标红部分是PCIE接口数据进来,然后分流为两部分,一部分进入BRAM,另外一部分进入HP接口。熟悉NVME协议的人应该知道为啥要这么设计了,NVME的协议部分是走HP到PS端,让linux的nvme驱动负责解析,包括SQ,CQ都从PS端取,但是PRP地址列表我们放在PL端,因为PRP地址列表基本是固定的,地址在约定的8M块走BRAM部分数据为真实数据,这样大数据就不会走PS导致降速。这里有几个细节需要注意,PCIE TLP包交互式以4K大小,NVME的SQ交互大小为512KB(这里需要通过命令SQ去查询SSD盘的参数,队列深度和队列个数,最大交互单元为多少,这里不设计NVME协议,SQ和CQ可以网上查阅资料),那么就会头128个TLP发起访问,而HP接口Brust模式为128字节(这里可能记错了),这里提到的参数是方便抓信号使用。
4.软件设计
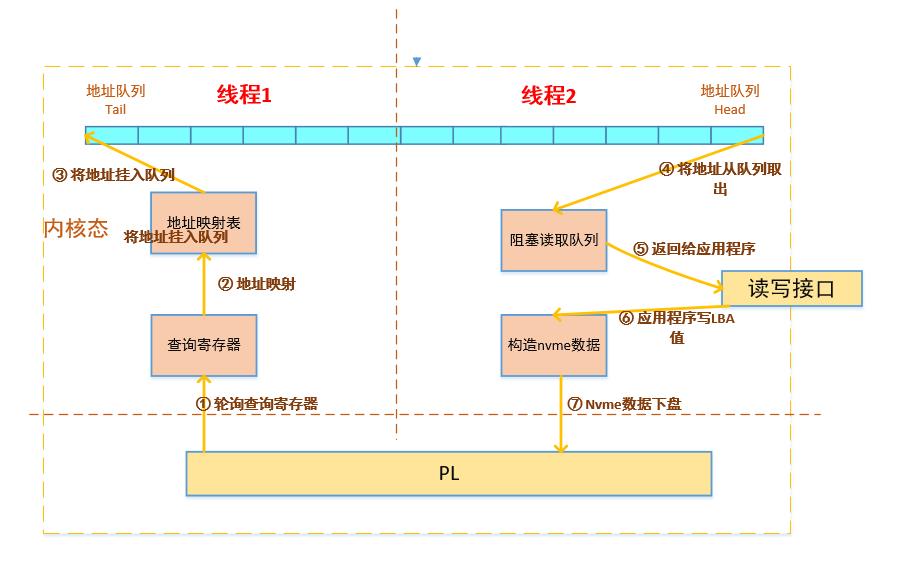
软件设计分为四个部分,PCIE驱动,NVME驱动,自定义驱动和应用程序。PCIe驱动负责解析PCIe接口,NVME驱动解析NVME协议,自定义驱动用于管理NVME驱动和与应用程序交互,应用程序负责文件信息管理,与上位机交互等操作。
软件设计有几个细节需要注意,文件信息可以放到SSD中,对速度不影响,异常掉电软件需要好好处理,数据不是完整的8M块也需要处理。异常掉电和数据不是完整8M块可以放到一起处理,异常掉电尽量让FPGA去检测。HP接口数据是直接到DDR,需要注意Cache一致性问题,因为存在HP接口Cache一致性,当从网络卸载数据时还存在网络MAC的DMA Cache一致性问题,这里涉及东西比较多,后期文章讲解。下图是自定义驱动的框架。
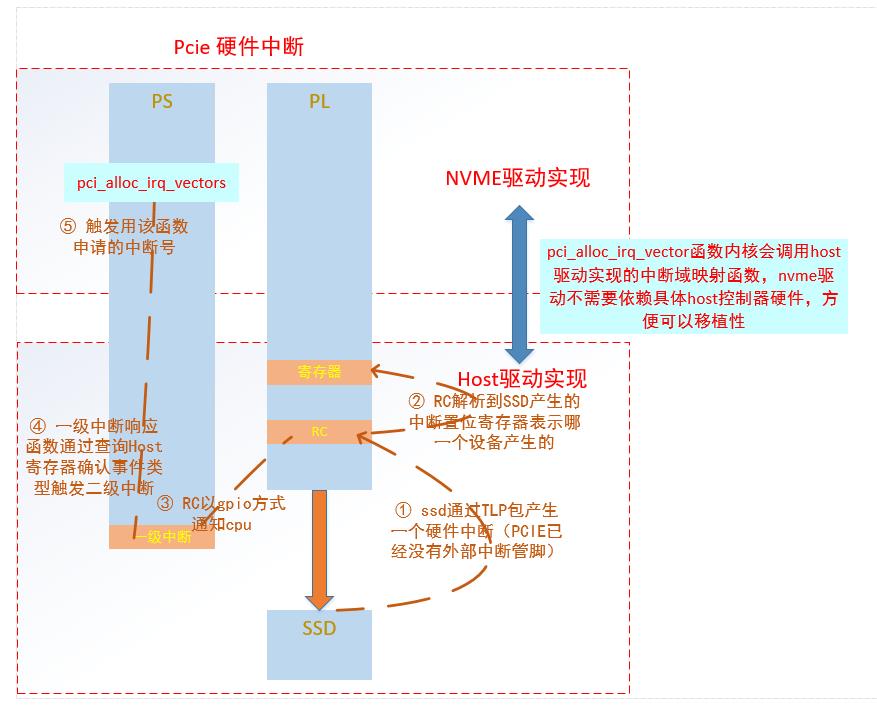
5.PCIE中断分析
PCIE中断分为硬中断和软中断,在zynq中中断处理比较特殊,因为PCIe的RC和协议解析是在不同处理上,中间只能通过GPIO和HP接口进行交互。
PCIe硬件中断如下所示
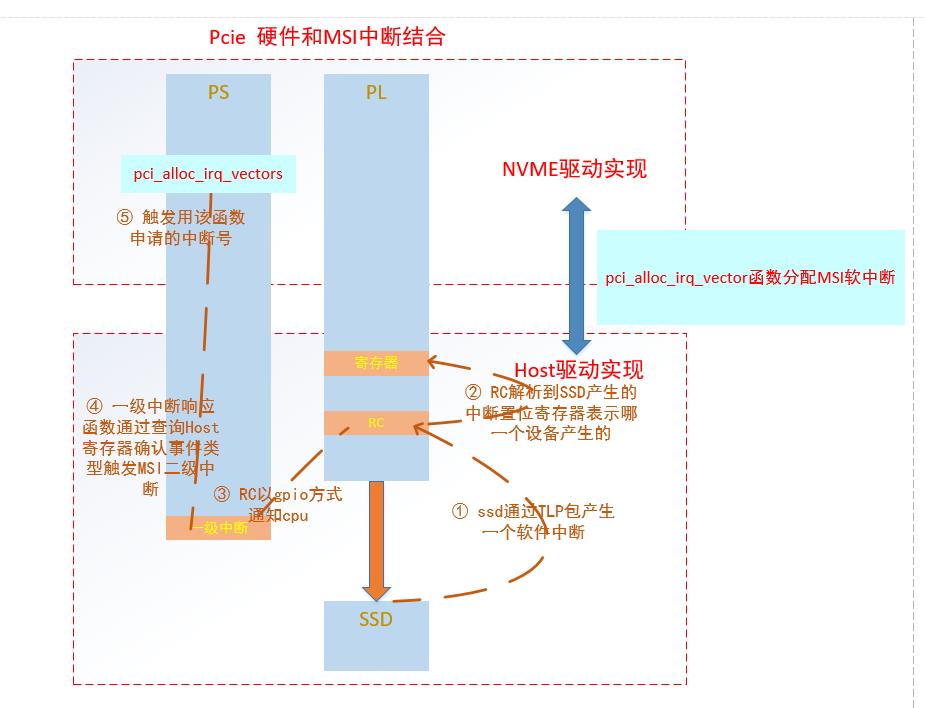
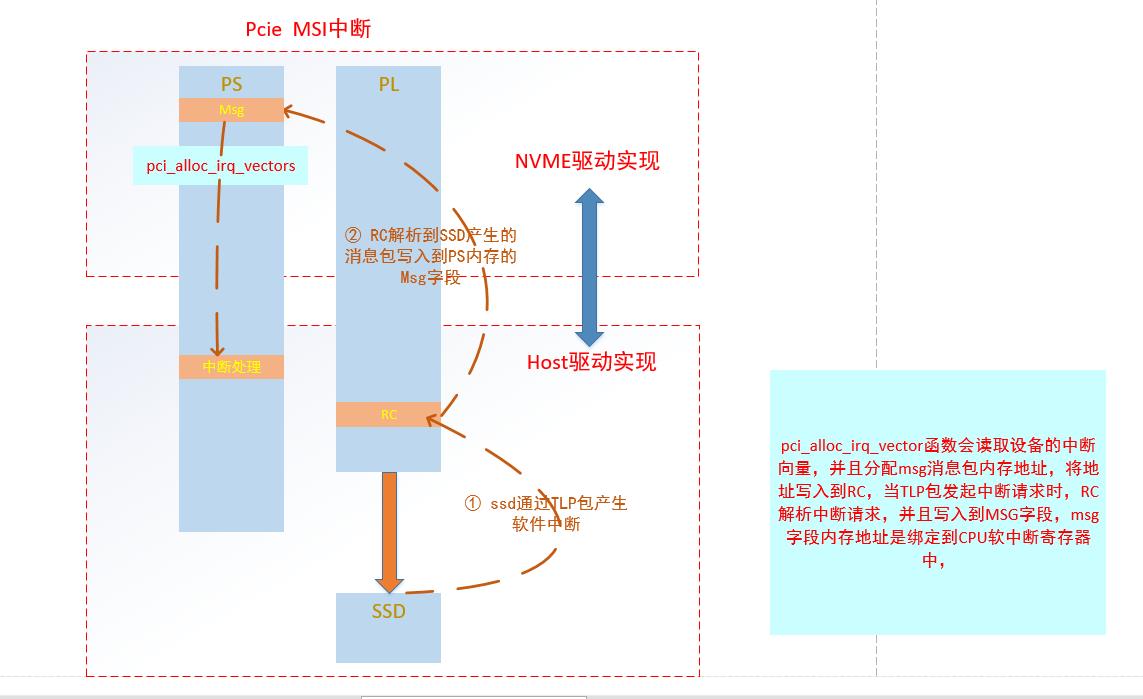
zynq中PCIe的软中断比较特殊,并不能完全按照MSI中断方式取处理。
PCIe真正软中断处理方式如下所示。
6.总结
按照本文方式处理,zc706处理器存储速率能够达到1.2GB/s。本方案设计比较简单,可移植性好,并且成本低,运行稳定,开发高效。
以上是关于ZYNQ+NVME存储方案设计的主要内容,如果未能解决你的问题,请参考以下文章