MapReduce编程实践——WordCount运行实例(Python实现)
Posted Z.Q.Feng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce编程实践——WordCount运行实例(Python实现)相关的知识,希望对你有一定的参考价值。
一、实验目的
- 通过实验掌握基本的 MapReduce 编程方法;
- 掌握用 MapReduce 解决一些常见数据处理问题的方法,包括数据合并、数据去重、数据排序和数据挖掘等。
二、实验平台
- 操作系统:Ubuntu 18.04(或 Ubuntu 16.04)
- Hadoop 版本:3.2.2
三、实验内容和要求
1. 任务要求
首先我们在本地创建两个文件,即文件A和B。
对于两个输入文件,即文件A和文件B,请编写 MapReduce 程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例,以供参考。
文件A的内容如下:
China is my motherland
I love China
文件B的内容如下:
I am from China
根据输入文件A和B合并得到的程序应该输出如下形式的结果:
I 2
is 1
China 3
my 1
love 1
am 1
from 1
motherland 1
2. 编写Map处理逻辑
编写 Map 的 Python 代码如下(mapper.py):
#!/usr/bin/env python3
# encoding=utf-8
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\\t%s" % (word, 1))
3. 编写Reduce处理逻辑
编写 Reduce 的 Python 代码如下(reducer.py):
#!/usr/bin/env python3
# encoding=utf-8
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\\t%s" % (current_word, current_count))
current_count = count
current_word = word
if word == current_word:
print("%s\\t%s" % (current_word, current_count))
4. 简单测试
简单在本地测试一下,运行如下代码:
cat A B | python3 mapper.py | python3 reducer.py
输出如下:
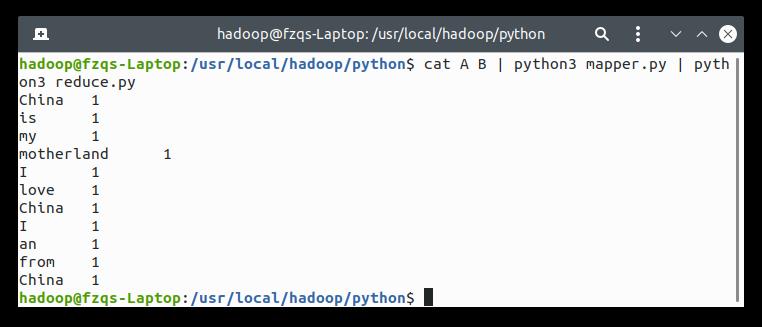
文末我会介绍如何将 Python 程序应用于 HDFS 文件系统中。
四、在HDFS中运行Python程序
首先启动 Hadoop:
cd /usr/local/hadoop
sbin/start-dfs.sh
创建 input 文件夹,把我们的数据文件传进去(注意这里你的 A、B 数据文件所处的位置):
bin/hdfs dfs -mkdir /input
bin/hdfs dfs -copyFromLocal /usr/local/hadoop/MapReduce/python/A /input
bin/hdfs dfs -copyFromLocal /usr/local/hadoop/MapReduce/python/B /input
确保 output 文件夹之前不存在:
bin/hdfs dfs -rm -r /output
我们只需要使用 Hadoop 提供的 Jar 包来为我们的 Python 程序提供一个接口就好了,这里我们所使用的 Jar 包一般在此目录下:
ls /usr/local/hadoop/share/hadoop/tools/lib/
找到名为 hadoop-streaming-x.x.x.jar 的包:
hadoop@fzqs-Laptop:/usr/local/hadoop/MapReduce/sample3$ ls /usr/local/hadoop/share/hadoop/tools/lib/
…
hadoop-streaming-3.2.2.jar
…
调用此包,把我们本地的 Python 文件作为参数传进去即可(注意这里我的 streaming 包是 3.2.2,看你自己的版本号):
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.2.2.jar \\
-file /usr/local/hadoop/MapReduce/sample1/mapper.py -mapper /usr/local/hadoop/MapReduce/sample1/mapper.py \\
-file /usr/local/hadoop/MapReduce/sample1/reducer.py -reducer /usr/local/hadoop/MapReduce/sample1/reducer.py \\
-input /input/* -output /output
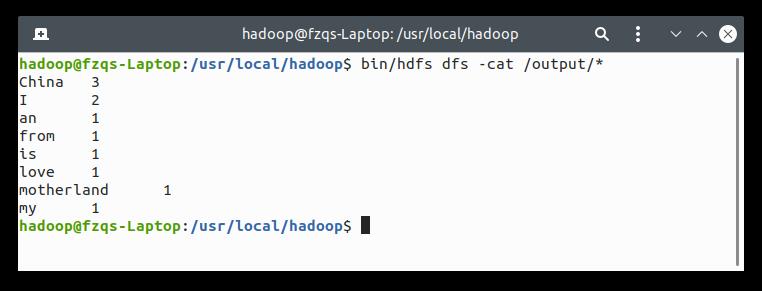
查看我们的输出:
bin/hdfs dfs -cat /output/*
输出正确,执行成功:
五、总结
以上是关于MapReduce编程实践——WordCount运行实例(Python实现)的主要内容,如果未能解决你的问题,请参考以下文章