Mapreduce编程-----WordCount程序编写及运行
Posted 会编程的李较瘦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mapreduce编程-----WordCount程序编写及运行相关的知识,希望对你有一定的参考价值。
一、MapReduce概述
1.核心思想
MapReduce的核心思想是“分而治之”,就是把一个复杂的问题,按照一定的“分解”方式分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果。
2.Map和Reduce阶段介绍
Map Reduce作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce分析海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段,具体介绍如下:
(1)Map阶段
负责将任务进行分解,处理数据,为reduce端做准备。
(2)Reduce阶段
进行汇总操作,得到最终结果
二、MapReduce编程模型
1.将原始数据处理成键值对<K1,V1>形式
2.将解析后的键值对<K1,V1>传给map()函数,map()函数会根据映射规则,将键值对<K1,V1>映射为一系列中间结果形式的键值对<K2,V2>.
3.将中间形式的键值对<K2,V2>形成<K2,{v2,……}>形式传给reduce()函数处理,把具有相同key的value合并在一起,产生新的键值对<K3,V3>,此时的<K3,V3>就是最终输出结果。
三、WordCount编程实例
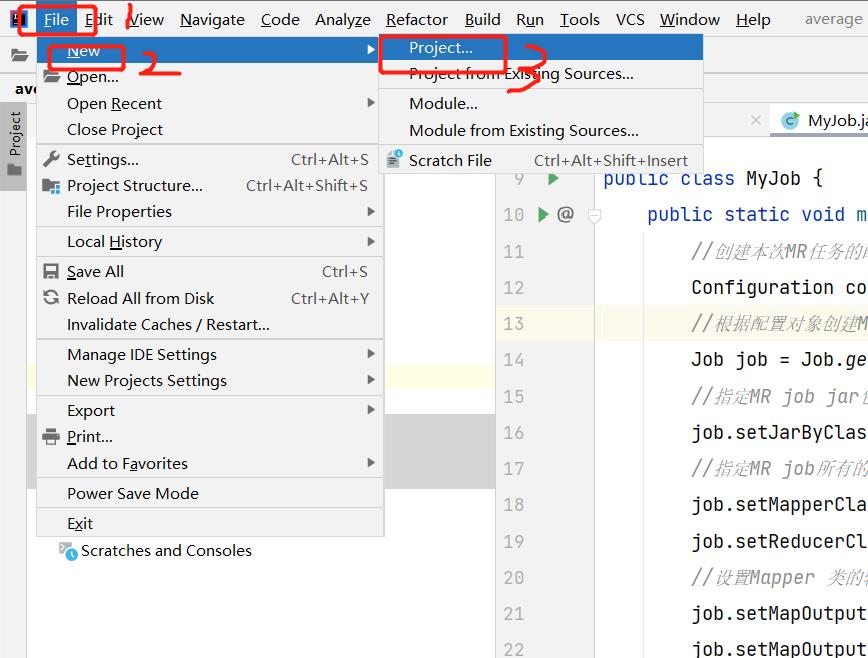
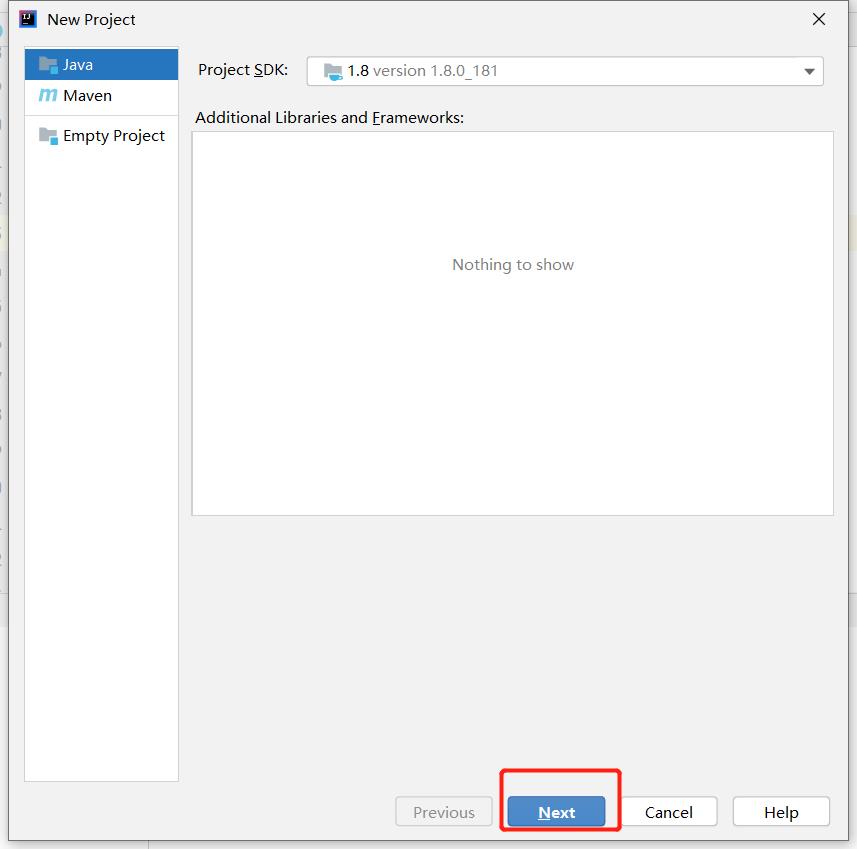
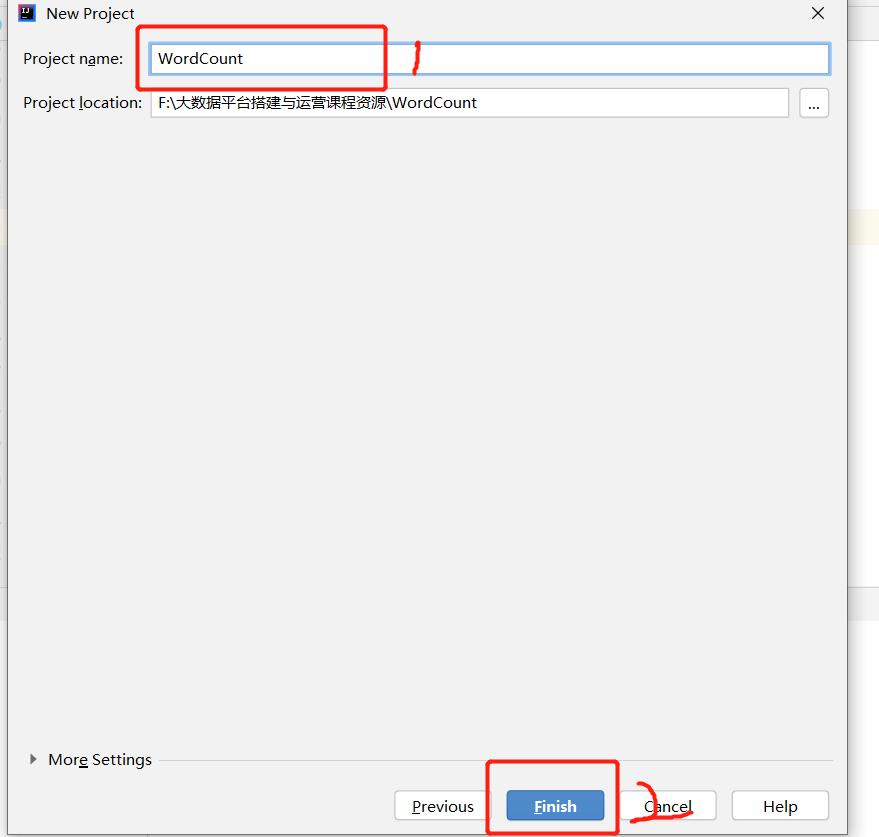
1.在IDEA中新建项目:File—>New—>Project
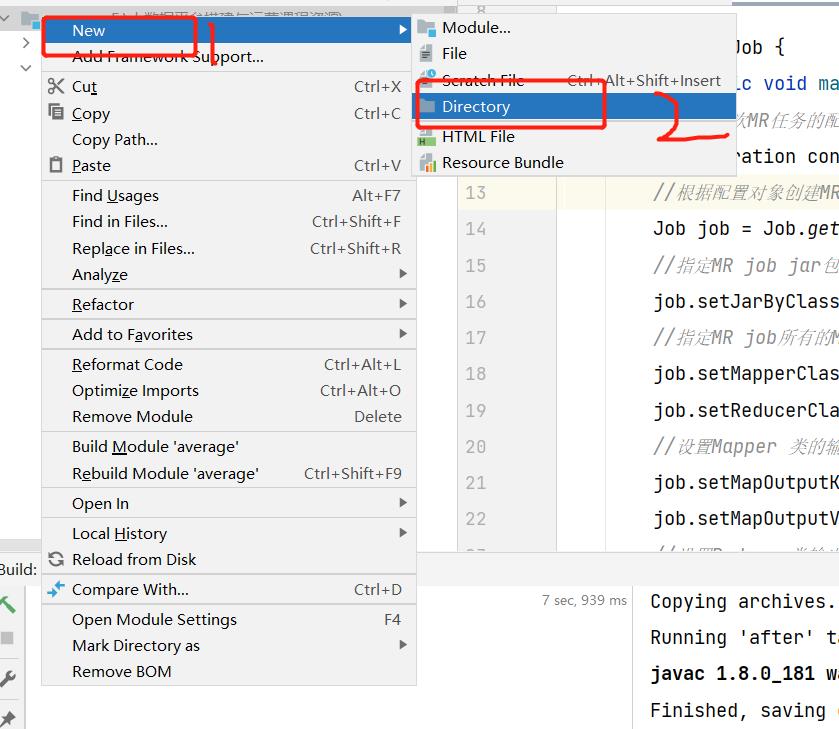
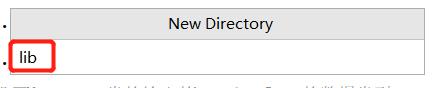
2.创建lib文件夹:选中项目名,右键new—>Directory
3.导入相关依赖jar包
选择hadoop的包,我用得是hadoop2.4.1。把下面的依赖包都加入到工程中,否则会出现某个类找不到的错误。
(1)”hadoop2.4.1/share/hadoop/common”目录下的hadoop-common-2.4.1.jar和haoop-nfs-2.4.1.jar;
(2)hadoop2.4.1/share/hadoop/common/lib”目录下的所有JAR包;
(3)hadoop2.4.1/share/hadoop/hdfs”目录下的haoop-hdfs-2.41.jar和haoop-hdfs-nfs-2.4.1.jar;
(4)“hadoop2.4.1/share/hadoop/hdfs/lib”目录下的所有JAR包。
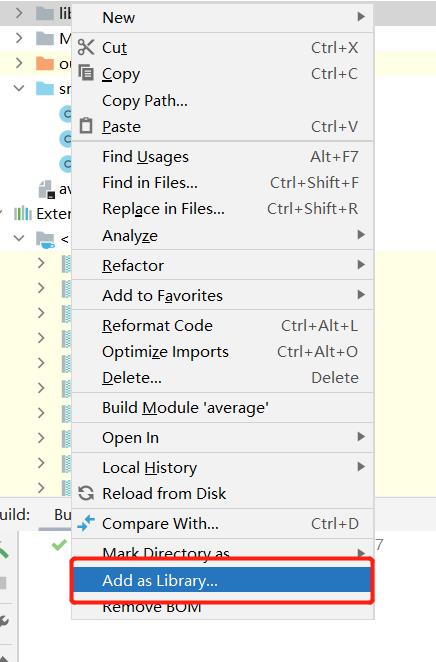
4.将第3步中添加的外部jar添加到IntelliJ IDEA项目
选中lib文件夹—>右键—>add as library
以上是关于Mapreduce编程-----WordCount程序编写及运行的主要内容,如果未能解决你的问题,请参考以下文章
Mapreduce编程-----WordCount程序编写及运行