从零开始学习Java设计模式 | 行为型模式篇:解释器模式
Posted 李阿昀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始学习Java设计模式 | 行为型模式篇:解释器模式相关的知识,希望对你有一定的参考价值。
在本讲,我们来学习一下行为型模式里面的最后一个设计模式,即解释器模式。总算是将这23种设计模式干完了,奥里给!
概述
在学习解释器模式之前,我们先来看下下面这张图。
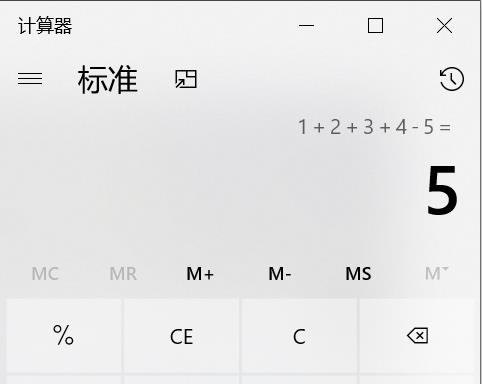
可以看到,这就是一个计算器,大家平时用的应该也是比较多的,当我们输入了1+2+3+4-5之后,它就会给我们出一个结果5。现在我们想要设计一个软件,类似于这样的一个计算器,用来进行加减计算。
各位来思考一下,我们应该如何来设计这样一个软件呢?可能大家的第一想法就是写个工具类不就得了,然后在该工具类中提供对应的加法和减法的工具方法,就像下面这段代码一样。
// 用于两个整数相加
public static int add(int a, int b){
return a + b;
}
// 用于三个整数相加
public static int add(int a, int b, int c){
return a + b + c;
}
// 用于n个整数相加
public static int add(Integer ... arr) {
int sum = 0;
for (Integer i : arr) {
sum += i;
}
return sum;
}
当然,上面代码中减法我们还没有提供出来。
不知你注意到了没有,上面的形式是比较单一、有限的,如果形式变化非常多,那么这就不符合要求了,因为加法和减法运算,两个运算符与数值可以有无限种组合方式,比如1+2+3+4+5、1+2+3-4等等,这样,我们再去设计像上面那样的一个工具类就不是特别合适了。而现在我们想实现的就是当我们输入了1+2+3+4-5这样一个语法之后,就能计算出一个正确的结果。
明白解释器模式的思维之后,接下来我们来看一下其概念。
给定一个语言(也就是说让我们自己定义一个语言),定义它的文法表示(即该语言的组成规则),并定义一个解释器,这个解释器会使用该语言的文法规则表示来解释语言中的句子。
注意,定义解释器是最关键的,解释器的作用就是根据给定语言的文法规则表示来解释语言中的句子,最终达到我们想要的结果。对于加减法运算来说,我们最重要的是要得到语句里面描述的最终的运算结果。
在解释器模式中,我们需要将待解决的问题,提取出规则,抽象为一种"语言"。比如加减法运算,它的规则为:由数值和+、-符号组成的合法序列,例如1+3-2就是这种语言的句子。
解释器就是要解析出来语句的含义。但是问题来了,我们如何来描述语句组成的规则呢?要想知道该问题的答案,那么你就不得不来认识一下下面要讲述的文法(语法)规则了。
文法(语法)规则是用于描述语言的语法结构的形式规则。例如,这儿就有一个文法表达式。
expression ::= value | plus | minus
plus ::= expression '+' expression
minus ::= expression '-' expression
value ::= integer
可以看到,这里面有很多符号,对于这些符号我们得先来说明一下。
::=:表示"定义为"的意思。|:表示或,也就是竖线两边选一个就可以了。'':引号内为字符本身,引号外为语法。
明白上述这些符号的意思之后,那么我们就能知道上述文法规则描述的是什么意思了。看一下,是不是下面这个意思啊?
表达式可以是一个值,也可以是plus或者minus运算,而plus和minus又是由表达式结合运算符构成的,至于值,只要它是一个整型数就可以了。
很明显,上述我们定义的文法(语法)规则只针对于加减法运算的语句,例如1+2、2-1等等。
简单了解了一下文法(语法)规则之后,接下来还有一个概念我得给大家说一下,那就是抽象语法树。
什么是抽象语法树呢?看下面的概念。
在计算机科学中,抽象语法树(AbstractSyntaxTree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
我们不妨来看一下下面这种树形结构啊!
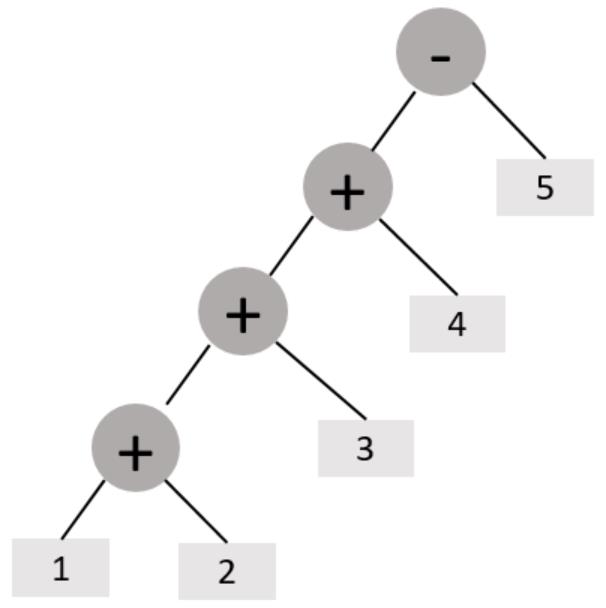
很明显,这就是一棵抽象语法树。对于这一棵语法树而言,我们应该从左边往右边去看,它的含义我不说,想必大家应该已经很清楚了,无非就是1+2的结果再去加3,然后加3的结果再去加4,最后加4的结果再去减5,很容易理解。
可以看到,解释器模式这一块的概念还是比较多的,有很多概念是需要大家好好去理解的。
对解释器模式这一块的概念有了一定了解之后,接下来,我们就来看看解释器模式的结构,也就是它里面所拥有的角色。
结构
解释器模式包含以下主要角色:
-
抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法,即interpret方法。
-
终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
看到这儿,很多人可能都懵逼了,What’up,什么是终结符表达式啊?这里我就要给大家解释解释了。大家不妨再看一下上述我们定义的文法规则,如下所示,这里我就给大家复制过来了哟,够贴心吧😊!
expression ::= value | plus | minus plus ::= expression '+' expression minus ::= expression '-' expression value ::= integer在上面定义的文法规则中,value就属于终结符表达式。至于plus或者minus,它们里面又包含了表达式,而表达式又有可能是plus或者minus,但是如果表达式是value(即具体的整形的数据)的话,那么整个表达式就结束了,所以我们才说value属于终结符表达式。
-
非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
很明显,上述我们定义的文法规则中,plus或者minus就属于非终结符表达式。
-
环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。也就是说,环境角色可以对给定文法里面牵扯到的那些表达式数据进行一个存储。
-
客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法,最终获得我们所想要的结果。
解释器模式案例
接下来,按照惯例我们通过一个案例来让大家再去理解一下解释器模式的概念,以及它里面所包含的角色,而这个案例就是设计一个实现加减法的软件。
分析
我们先来看下该软件的设计类图。
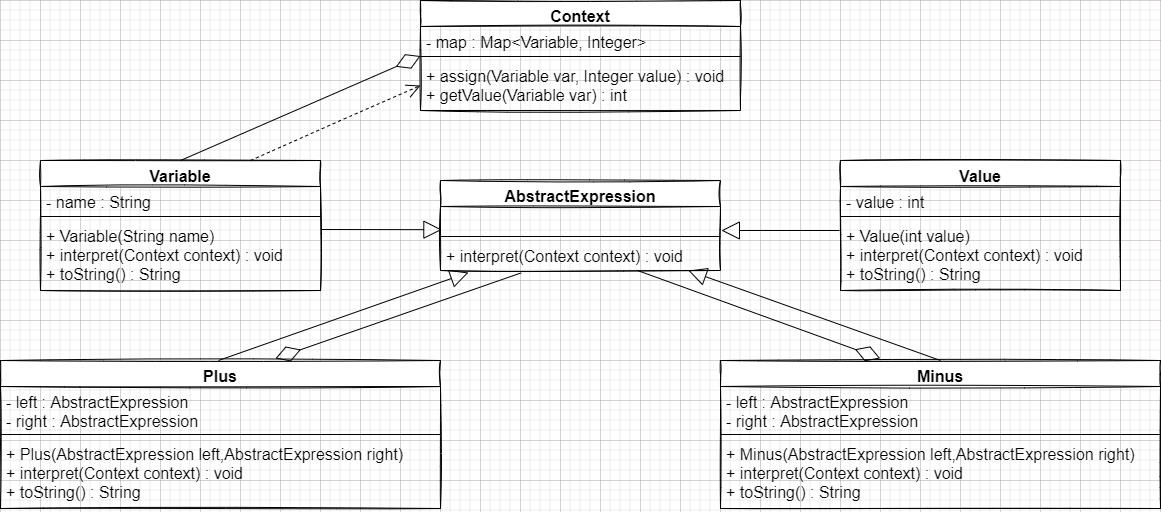
首先,我们来看一下类图里面的AbstractExpression类,它充当的是解释器模式中的抽象表达式角色,在该类里面我们定义了一个interpret方法,该方法就是用来解释表达式的,而且该方法需要依赖Context类,至于Context类,我们等会就会说到。
从以上类图中可以看到,该抽象表达式类有好几个子类,它们分别是:
-
Variable类:该类是用于对变量进行封装的,它里面有一个name属性,表示的就是变量的名称。此外,我们还在该类里面定义如下几个方法:
- 有参构造:用于给变量起名字的。
- interpret方法:该方法是重写父类中的interpret方法。
- toString方法:该方法只是为了我们在后期验证测试的时候想看到更好的效果而定义的。
-
Value类:该类是用于对具体的值进行封装的。注意,在该案例中,我们并没有用到该类,只是在类图里面将其表示出来了而已。
-
Plus类:该类是用于对加法表达式进行封装的,它里面定义有两个AbstractExpression类型的成员变量,名字分别叫left和right,表示的就是加号左右两边的表达式,很明显,这俩成员变量将AbstractExpression类的对象聚合进来了。此外,我们还在该类里面定义如下几个方法:
- 有参构造:用于设置加号左右两边的表达式的。
- interpret方法:该方法是重写父类中的interpret方法。
- toString方法:该方法只是为了我们在后期验证测试的时候想看到更好的效果而定义的。
-
Minus类:该类是用于对减法表达式进行封装的。该类同以上Plus类基本类似,所以在这里我就不再详细赘述了。
反正不管怎么着,Plus和Minus这俩类既继承自抽象表达式类,同时又聚合进来了抽象表达式类的对象,所以大家要把这一块的复杂关系给理清楚。
最后,我们再来看一个类,那就是Context类,很明显,该类充当的是解释器模式中的环境角色。从上可以看到,该类里面定义了一个Map集合,Map集合里面存储的就是变量以及变量对应的值。此外,我们还在该类里面定义了两个方法,一个是assign,该方法是用来向Map集合里面添加变量及其对应的值的;一个是getValue,该方法就是根据变量来获取变量对应的值的。
至此,以上类图我们就分析完了,接下来我们就要编写代码来实现以上案例了。
实现
首先,打开咱们的maven工程,并在com.meimeixia.pattern包下新建一个子包,即interpreter,也即实现以上案例的具体代码我们是放在了该包下。
然后,创建抽象表达式类,这里我们就命名为AbstractExpression了。
package com.meimeixia.pattern.interpreter;
/**
* 抽象表达式类
* @author liayun
* @create 2021-09-19 12:20
*/
public abstract class AbstractExpression {
/*
* 为什么该抽象方法的返回值类型是int呢?因为在该案例里面我们只考虑对int类型的数据进行加减法运算
*/
public abstract int interpret(Context context);
}
接着,创建以上抽象表达式类的子类。这里,我们先创建第一个子类,即用于封装变量的类,名字就取为Variable。
package com.meimeixia.pattern.interpreter;
/**
* 用于封装变量的类(属于终结符表达式角色)
* @author liayun
* @create 2021-09-19 12:27
*/
public class Variable extends AbstractExpression {
// 声明一个存储变量名的成员变量
private String name;
public Variable(String name) {
this.name = name;
}
@Override
public int interpret(Context context) {
// 直接返回变量的值。问题是变量的值在哪存储呢?既然在本类中没有存储,那么肯定就是存储在Context类里面了!
return context.getValue(this); // 注意,调用getValue方法时,需要向其传递一个Variable类型的对象,而当前类的对象就是这样一个对象,所以这里传递this即可
}
@Override
public String toString() {
return name; // 返回变量的名称就好
}
}
再创建第二个子类,即用于封装加法表达式的类,名字就取为Plus。
package com.meimeixia.pattern.interpreter;
/**
* 用于封装加法表达式的类(属于非终结符表达式角色)
* @author liayun
* @create 2021-09-19 12:37
*/
public class Plus extends AbstractExpression {
// +号左边的表达式
private AbstractExpression left;
// +号右边的表达式
private AbstractExpression right;
public Plus(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
@Override
public int interpret(Context context) {
// 将左边表达式的结果和右边表达式的结果进行相加
return left.interpret(context) + right.interpret(context);
}
@Override
public String toString() {
// 无非就是返回加号左边表达式的字符串表示形式+加号右边表达式的字符串表示形式
return "(" + left.toString() + " + " + right.toString() + ")";
}
}
再再创建第三个子类,即用于封装减法表达式的类,名字就取为Minus。
package com.meimeixia.pattern.interpreter;
/**
* 用于封装减法表达式的类(属于非终结符表达式角色)
* @author liayun
* @create 2021-09-19 12:37
*/
public class Minus extends AbstractExpression {
// -号左边的表达式
private AbstractExpression left;
// -号右边的表达式
private AbstractExpression right;
public Minus(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
@Override
public int interpret(Context context) {
// 将左边表达式的结果和右边表达式的结果进行相减
return left.interpret(context) - right.interpret(context);
}
@Override
public String toString() {
// 无非就是返回减号左边表达式的字符串表示形式 - 减号右边表达式的字符串表示形式
return "(" + left.toString() + " - " + right.toString() + ")";
}
}
紧接着,创建环境类。注意了,大家可千万别忘记了创建该类哟,因为上面的类都要用到它,我们这里是放在了最后来创建的。
package com.meimeixia.pattern.interpreter;
import java.util.HashMap;
import java.util.Map;
/**
* 环境角色类
* @author liayun
* @create 2021-09-19 12:21
*/
public class Context {
// 定义一个Map集合,用来存储变量及其对应的值
private Map<Variable, Integer> map = new HashMap<Variable, Integer>();
// 添加变量的功能
public void assign(Variable var, Integer value) {
map.put(var, value);
}
// 根据变量获取对应的值
public int getValue(Variable var) {
return map.get(var);
}
}
最后,创建客户端类用于测试。
package com.meimeixia.pattern.interpreter;
/**
* @author liayun
* @create 2021-09-19 14:43
*/
public class Client {
public static void main(String[] args) {
// 创建环境对象
Context context = new Context();
// 创建多个变量对象
Variable a = new Variable("a");
Variable b = new Variable("b");
Variable c = new Variable("c");
Variable d = new Variable("d");
// 将变量存储到环境对象中
context.assign(a, 1);
context.assign(b, 2);
context.assign(c, 3);
context.assign(d, 4);
// 获取抽象语法树,例如a + b - c + d就是一棵抽象语法树
AbstractExpression expression = new Minus(a, new Plus(new Minus(b, c), d)); // 通过对应的表达式对象去构建a - ((b - c) + d)这样一棵抽象语法树
// 解释(加减法计算)
int result = expression.interpret(context);
System.out.println(expression + " = " + result);
}
}
此时,运行以上客户端类的代码,打印结果如下图所示,可以看到确实是我们所想要的结果,因为1-((2-3)+4)的结果就是-2。
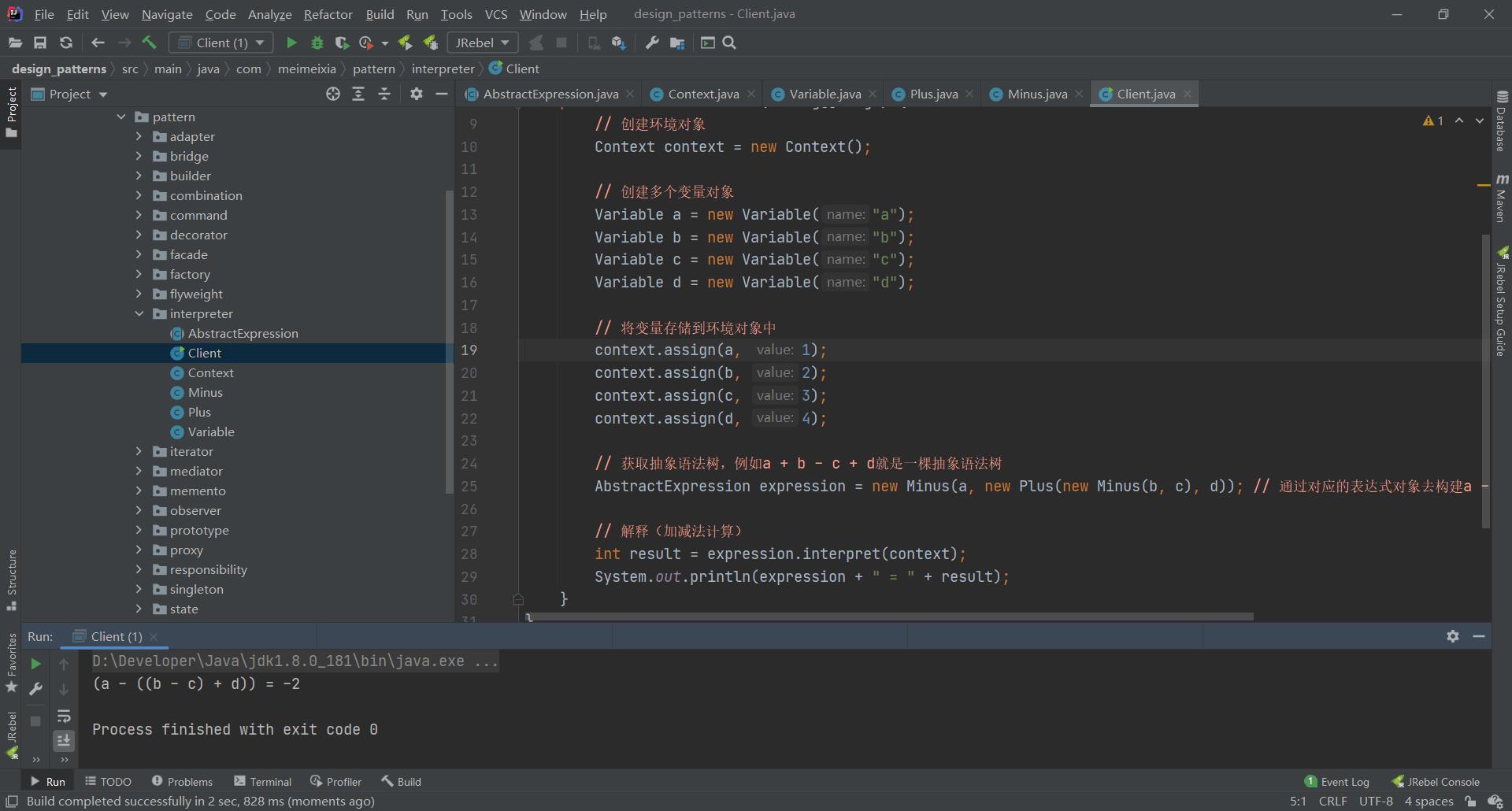
当然了,你也可以尝试着去修改一下构建的抽象语法树,然后再来验证一下上面我们写的代码到底有没有问题啊!但我想是没有任何问题的。
解释器模式的优缺点以及使用场景
接下来,我们来看一下解释器模式的优缺点以及使用场景。
优缺点
优点
关于解释器模式的优点,我总结出来了如下三点。
-
易于改变和扩展文法。
由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
上面这段话,聪明的童鞋肯定能看得懂,但是有些人或许还是不能看懂,所以,我觉得有必要对上面这段话解释一番。先来看在解释器模式中使用类来表示语言的文法规则这句话,文法规则,我相信大家都明白是啥,就拿上述案例来说,我们定义的文法规则它里面包含的无非就是一些变量、加法表达式以及减法表达式。对于变量来说,我们是使用Variable类来表示它的文法规则的,即获取变量对应的值;对于加法表达式来说,我们是使用Plus类来表示它的文法规则的,即将加号左边表达式的结果和右边表达式的结果进行相加;对于减法表达式来说,我们是使用Minus类来表示它的文法规则的,即将减号左边表达式的结果和右边表达式的结果进行相减。所以,每一条文法规则都可以表示为一个类。
再来看可以通过继承等机制来改变或扩展文法这句话,这句话说的啥意思呢?举个例子,假如现在我们想要定义一个乘法表达式的文法规则,那么应该怎么办呢?很简单,我们只需要定义一个类,让它去继承抽象表达式类就可以了。
-
实现文法较为容易。
在抽象语法树中,每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂。
还是拿上述案例来说,对于Variable这个封装变量的表达式类而言,它里边的代码实现还是比较简单的,而且也符合我们人类思考的逻辑,因为对于一个变量来说,我们无非就是从它里面去获取对应的数据;对于Plus这个封装加法表达式的表达式类而言,它里边的代码实现也是比较简单的,而且同样也符合我们人类思考的逻辑,不就是把加号两边表达式的结果进行一个相加吗?对于Minus这个封装减法表达式的表达式类而言,也是同样的一个道理。
-
增加新的解释表达式较为方便。
如果用户需要增加新的解释表达式,那么他只需要对应增加一个新的终结符表达式或非终结符表达式类即可,而且原有表达式类代码无须修改,很显然,这符合"开闭原则"。
缺点
关于解释器模式的缺点,我总结出来了如下两点。
-
对于复杂文法难以维护。
在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,那么类的个数将会急剧增加,从而导致系统难以管理和维护。也就是说,如果给定语言的文法规则特别复杂的话,那么我们就需要定义很多抽象表达式的子类了,这样的话,会显得我们的系统特别特别庞大,从而也就导致了系统难以管理和维护。
-
执行效率较低。
由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度会很慢,而且代码的调试过程也会变得比较麻烦。
有些人可能会说,在上述案例的解释器模式中,到底用的是循环还是递归啊?其实使用的是递归啊!大家不妨去看一下Minus、Plus这些表达式类,你会发现它们不仅继承了AbstractExpression类,而且还聚合进来了该类的对象,所以这就是递归。
对于递归来说,它必须是要有出口的,那么这里面的出口又是什么呢?很显然,是变量。因为对于终结符表达式(即Variable这个封装变量的表达式类)而言,调用其interpret方法获取的就是其封装的变量的值,而对于非终结符表达式而言,调用其interpret方法时,又会去调用其他表达式类里面的interpret方法,这不就是递归调用吗?
使用场景
只要出现如下几个场景,我们就可以去考虑一下能不能使用解释器模式了。
- 当语言的文法较为简单,且执行效率不是关键问题时,完美地把上面的两个缺点给避开了。
- 当问题重复出现,且可以用一种简单的语言来进行表达时。
- 当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候。
至此,23种设计模式的讲解就到此为止了,完美落幕😘!谢谢努力而又无私奉献的自己👍!
以上是关于从零开始学习Java设计模式 | 行为型模式篇:解释器模式的主要内容,如果未能解决你的问题,请参考以下文章