《Python深度学习》第一章笔记
Posted 烟雨行客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Python深度学习》第一章笔记相关的知识,希望对你有一定的参考价值。
《Python深度学习》第一章笔记
1.1人工智能、机器学习、深度学习
什么是人工智能、机器学习与深度学习?这三者之间有什么关系?
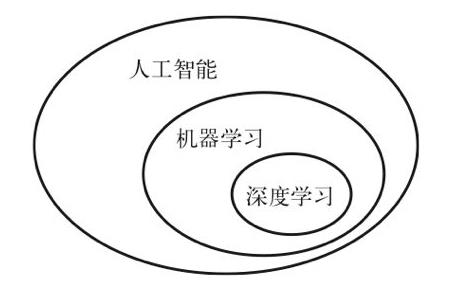
人工智能
人工智能诞生于20世纪50年代,人工智能的简洁定义如下:努力将通常由人类完成的智力任务自动化。人工智能是一个综合性的领域,不仅包括机器学习与深度学习,还包括更多不涉及学习的方法。
机器学习
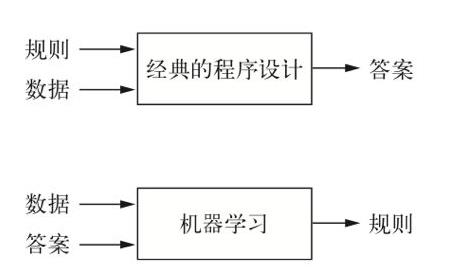
机器学习系统是训练出来的,人们输入的是数据和从这些数据中预期得到的答案,系统输出的是规则。机器学习的技术定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
在符号人工智能中,人们输入规则和需要根据这些规则进行处理的数据,系统输出答案。这种并不属于机器学习。
深度学习
为了给出深度学习的定义并搞清楚深度学习与其他机器学习方法的区别,我们首先需要知道机器学习在做什么。
我们需要以下三要素来进行机器学习。
- 输入数据点。例如,你的任务是语音识别,那么这些数据点可能是记录人们说话的声音文件。如果你的任务是为图像添加标签,那么这些数据点可能是图像。
- 预期输出的示例。对于语音识别任务来说,这些示例可能是人们根据声音文件整理生成的文本。对于图像标记任务来说,预期输出可能是“狗”“猫”之类的标签。
- 衡量算法好坏的方法。这一衡量方法是为了计算算法的当前输出与预期输出的差距。
机器学习和深度学习的核心问题在于有意义地变换数据,在于学习输入数据的有用表示——这种表示可以让数据更接近预期输出。
现在你理解了学习的含义,下面我们来看一下深度学习的特殊之处。
深度学习是机器学习的一个分支领域:它是从数据中学习表示的一种新方法,强调从连续的层(layer)中进行学习,这些层对应于越来越有意义的表示。
“深度学习”中的“深度”是指一系列连续的表示层。数据模型中包含多少层,这被称为模型的深度(depth)。现代深度学习通常包含数十个甚至上百个连续的表示层,这些表示层全都是从训练数据中自动学习的。
因此,深度学习的技术定义:学习数据表示的多级方法。即利用深层神经网络的机器学习来学习输入数据的有用表示。
深度学习的工作原理
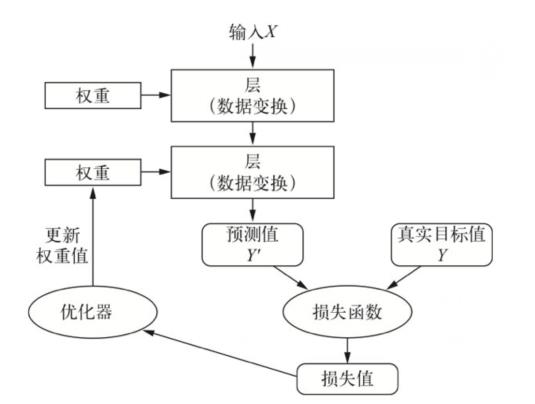
- 首先,深度神经网络通过一系列简单的数据变换(层)来实现输入到输出的映射,神经网络中每层对输入数据所做的具体操作保存在该层的权重中,每层实现的变换由其权重来参数化,但是一个深度神经网络可能包含数千万个参数,找到所有参数的正确取值是一项非常艰巨的任务。
- 其次,想要控制一件事物,需要能够观察它。想要控制神经网络的输出,需要能够衡量该输出与预期值之间的距离,这是神经网络损失函数的任务。
- 最后,深度学习中的核心算法——反向传播算法,利用损失函数计算出的预测值与真实值之间的距离作为反馈信号实现对权重值的调节。
- 一开始对权重随机赋值,但随着网络处理的示例越来越多,权重值也在向正确的方向逐步微调,损失值也逐渐降低。这就是训练循环,将这种循环重复足够多次,得到的权重值可以使损失函数最小。
1.2深度学习之前:机器学习简史
下面让我们简要回顾经典机器学习方法(具体算法实现请读者自行查阅资料进行学习)。这样我们可以将深度学习放入机器学习的大背景中,并更好地理解深度学习的起源以及它为什么如此重要。
概率建模
概率建模是统计学原理在数据分析中的应用。它是最早的机器学习形式之一,至今仍在广泛使用。其中最有名的算法之一是朴素贝叶斯算法。
朴素贝叶斯是一类基于应用贝叶斯定理的机器学习分类器,它假设输入数据的特征都是独立的。朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
另一个模型是logistic回归,它也是一种分类算法,而不是回归算法。logistic回归常用于两分类问题。
早期神经网络
人们早在 20 世纪 50 年代就对神经网络核心思想进行研究,但在很长一段时间内,一直没有训练大型神经网络的有效方法。这一点在 20 世纪 80 年代中期发生了变化,当时很多人都独立地重新发现了反向传播算法——一种利用梯度下降优化来训练一系列参数化运算链的方法,并开始将其应用于神经网络。
贝尔实验室于 1989 年第一次成功实现了神经网络的实践应用,当时 Yann LeCun 将卷积神经网络的早期思想与反向传播算法相结合,并将其应用于手写数字分类问题,由此得到名为LeNet 的网络,在 20 世纪 90 年代被美国邮政署采用,用于自动读取信封上的邮政编码。
核方法
上述神经网络取得了第一次成功,并在 20 世纪 90 年代开始在研究人员中受到一定的重视,但一种新的机器学习方法在这时声名鹊起,很快就使人们将神经网络抛诸脑后。这种方法就是核方法。核方法是一组分类算法,其中最有名的就是支持向量机(SVM,support vector machine)。
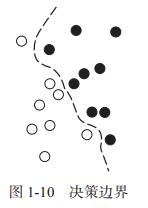
SVM 的目标是通过在属于两个不同类别的两组数据点之间找到良好决策边界来解决分类问题。决策边界可以看作一条直线或一个平面,将训练数据划分为两块空间,分别对应于两个类别。对于新数据点的分类,只需判断它位于决策边界的哪一侧。
决策树、随机森林与梯度提升机
决策树(decision tree)是类似于流程图的结构,可以对输入数据点进行分类或根据给定输入来预测输出值。
 随机森林(random forest)算法,是集成学习算法的一种,它引入了一种健壮且实用的决策树学习方法,即首先构建许多决策树,然后将它们的输出集成在一起。随机森林适用于各种各样的问题——对于任何浅层的机器学习任务来说,它几乎总是第二好的算法。
随机森林(random forest)算法,是集成学习算法的一种,它引入了一种健壮且实用的决策树学习方法,即首先构建许多决策树,然后将它们的输出集成在一起。随机森林适用于各种各样的问题——对于任何浅层的机器学习任务来说,它几乎总是第二好的算法。
与随机森林类似, 梯度提升机(gradient boosting machine)也是将弱预测模型(通常是决策树,但不限于决策树)集成的机器学习技术。它使用了梯度提升方法,通过迭代地训练新模型来专门解决之前模型的弱点,从而改进任何机器学习模型的效果。
回到神经网络
自2012年以来,深度卷积神经网络(DNN)已成为所有计算机视觉任务的首选算法。与此同时,深度学习也在许多其他问题上得到应用,比如自然语言处理。它已经在大量应用中完全取代了SVM与决策树。
卷积神经网络(CNN),这是深度学习算法应用最成功的领域之一,卷积神经网络包括一维卷积神经网络,二维卷积神经网络以及三维卷积神经网络。一维卷积神经网络主要用于序列类的数据处理,二维卷积神经网络常应用于图像类文本的识别,三维卷积神经网络主要应用于医学图像以及视频类数据识别。
关于卷积神经网络的CNN的原理,详情可学习以下链接:
https://www.cnblogs.com/charlotte77/p/7759802.html
以上是关于《Python深度学习》第一章笔记的主要内容,如果未能解决你的问题,请参考以下文章