《Python深度学习》第三章第一部分读书笔记
Posted Paul-Huang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Python深度学习》第三章第一部分读书笔记相关的知识,希望对你有一定的参考价值。
第三章 神经网络入门-1
本次重点:
- 层的应用(2D对应Dense,3D对应LST,4D对应Con2);
- 损失函数(二分类问题用二元交叉熵二元交叉熵( binary crossentropy)损失函数;多分类问题用分类交叉熵( categorical crossentropy)损失函数;回归问题用均方误差均方误差( mean-squared error)损失函数;序列学习问题用联结主义时序分类( CTC, connectionist temporal classification)损失函数)
- Sequential 类和API;
- 二分类问题:电影评论分类
3.1 神经网络剖析
训练神经网络主要围绕以下四个方面:
- 层,多个层组合成网络(或模型)
- 输入数据和相应的目标
- 损失函数,即用于学习的反馈信号
- 优化器,决定学习过程如何进行
如图 3-1 所示:多个层链接在一起组成了网络,将输入数据映射为预测值。然后损失函数将这些预测值与目标进行比较,得到损失值,用于衡量网络预测值与预期结果的匹配程度。优化器使用这个损失值来更新网络的权重。
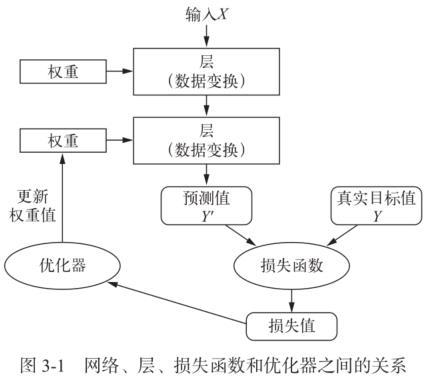
3.1.1 层:深度学习的基础组件
- 层的定义
- 层是一个数据处理模块,将一个或多个输入张量转换为一个或多个输出张量。
- 有些层是无状态的,但大多数的层是有状态的,即 层 的 权 重 \\color{red}层的权重 层的权重。
- 权重是利用随机梯度下降学到的一个或多个张量,其中包含网络的知识。
- 不同层的应用
不同的张量格式与不同的数据处理类型需要用到不同的层。- 简单的向量数据保存在形状为 (samples, features) 的
2
D
张
量
\\color{red}2D 张量
2D张量中,通常用密集连接层[ 也叫全连接层或密集层,对应于 Keras 的
Dense类]来处理。 - 序列数据保存在形状为 (samples, timesteps, features) 的
3
D
张
量
\\color{red}3D 张量
3D张量中,通常用循环层( recurrent layer,比如 Keras 的
LSTM层)来处理。 - 图像数据保存在
4
D
张
量
\\color{red}4D 张量
4D张量中,通常用二维卷积层( Keras 的
Conv2D)来处理。
现实世界中的数据张量
- 向量数据:2D 张量,形状为 (samples, features) 。
- 时间序列数据或序列数据:3D 张量,形状为 (samples, timesteps, features) 。
- 图像:4D张量,形状为 (samples, height, width, channels) 或 (samples, channels,height, width) 。
- 视频:5D张量,形状为 (samples, frames, height, width, channels) 或 (samples,
frames, channels, height, width) 。
- 简单的向量数据保存在形状为 (samples, features) 的
2
D
张
量
\\color{red}2D 张量
2D张量中,通常用密集连接层[ 也叫全连接层或密集层,对应于 Keras 的
3.1.2 模型:层构成的网络
-
深度学习模型是层构成的 有 向 无 环 图 \\color{red}有向无环图 有向无环图。
-
常见的网络拓扑结构:
- 线性堆叠,将单一输入映射为单一输出。
- 双分支( two-branch)网络。
- 多头( multihead)网络。
- Inception 模块。
选择正确的网络架构更像是一门艺术而不是科学。虽然有一些最佳实践和原则,但只有动
手实践才能让你成为合格的神经网络架构师。
3.1.3 损失函数与优化器:配置学习过程的关键
- 定义
-
损
失
函
数
(
目
标
函
数
)
\\color{red}损失函数(目标函数)
损失函数(目标函数)——在训练过程中需要将其最小化。它能够衡量当前任务是否已
成功完成。 -
优
化
器
\\color{red}优化器
优化器——决定如何基于损失函数对网络进行更新。它执行的是随机梯度下降(SGD)
的某个变体。
Tip:
- 具有多个输出的神经网络可能具有多个损失函数(每个输出对应一个损失函数)。
- 但是,梯度下降过程必须基于 单 个 标 量 损 失 值 \\color{red}单个标量损失值 单个标量损失值。因此,对于具有多个损失函数的网络,需要将所有损失函数进行处理,变为一个标量值。
-
损
失
函
数
(
目
标
函
数
)
\\color{red}损失函数(目标函数)
损失函数(目标函数)——在训练过程中需要将其最小化。它能够衡量当前任务是否已
- 如何选择损失函数
- 对于二分类问题,你可以使用 二 元 交 叉 熵 \\color{red}二元交叉熵 二元交叉熵( binary crossentropy)损失函数;
- 对于多分类问题,可以用 分 类 交 叉 熵 \\color{red}分类交叉熵 分类交叉熵( categorical crossentropy)损失函数;
- 对于回归问题,可以用 均 方 误 差 \\color{red}均方误差 均方误差( mean-squared error)损失函数;
- 对于序列学习问题,可以用 联 结 主 义 时 序 分 类 \\color{red}联结主义时序分类 联结主义时序分类( CTC, connectionist temporal classification)损失函数,
3.2 Keras 简介
3.2.1 典型的 Keras 工作流程
(1)
定
义
训
练
数
据
\\color{blue}定义训练数据
定义训练数据:输入张量和目标张量。
(2)
定
义
层
组
成
的
网
络
\\color{blue}定义层组成的网络
定义层组成的网络(或模型),将输入映射到目标。
(3)
配
置
学
习
过
程
\\color{blue}配置学习过程
配置学习过程:选择损失函数、优化器和需要监控的指标。
(4)
调
用
模
型
的
f
i
t
方
法
在
训
练
数
据
上
进
行
迭
代
\\color{blue}调用模型的 fit 方法在训练数据上进行迭代
调用模型的fit方法在训练数据上进行迭代。
3.2.2 定义网络模型的两种方法
-
使用 Sequential 类
一种是使用 Sequential 类(仅用于层的线性堆叠,这是目前最常见的网络架构),另一种是函数式 API( functional API,用于层组成的有向无环图,让你可以构建任意形式的架构)。from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(32, activation='relu', input_shape=(784,))) model.add(layers.Dense(10, activation='softmax’)) -
使用API
下面是用函数式 API 定义的相同模型。input_tensor = layers.Input(shape=(784,)) x = layers.Dense(32, activation='relu')(input_tensor) output_tensor = layers.Dense(10, activation='softmax')(x) model = models.Model(inputs=input_tensor, outputs=output_tensor)利用函数式 API,你可以操纵模型处理的数据张量,并将层应用于这个张量,就好像这些层是函数一样。
3.2.3 配置学习过程
配置学习过程是在编译这一步,你需要指定模型使用的优化器和损失函数,以及训练过程中想要监控的指标:
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss='mse', metrics=['accuracy'])
3.2.4 模型训练
学习过程就是通过 fit() 方法将输入数据的 Numpy 数组(和对应的目标数据)传入模型:
model.fit(input_tensor, target_tensor, batch_size=128, epochs=10)
3.3 电影评论分类:二分类问题
IMDB 数据集,它包含来自互联网电影数据库(IMDB)的 50 000 条严重两极分化的评论。数据集被分为用于训练的 25 000 条评论与用于测试的 25 000 条评论,训练集和测试集都包含 50% 的正面评论和 50% 的负面评论。
与 MNIST 数据集一样,IMDB 数据集也内置于 Keras 库。它已经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
3.3.1 加载 IMDB 数据集
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
- 参数 num_words=10000 的意思是仅保留训练数据中前 10 000 个最常出现的单词。低频单词将被舍弃。这样得到的向量数据不会太大,便于处理。
- train_data 和 test_data 这两个变量都是评论组成的列表,每条评论又是单词索引组成的列表(表示一系列单词)。
- train_labels 和 test_labels 都是 0 和 1 组成的列表,其中 0代表负面(negative),1 代表正面(positive)。
3.3.2 准备数据
你不能将整数序列直接输入神经网络。你需要 将 列 表 转 换 为 张 量 \\color{red}将列表转换为张量 将列表转换为张量。转换方法有以下两种。
- 填充列表,使其具有相同的长度,再将列表转换成形状为 (samples, word_indices)的整数张量,然后网络第一层使用能处理这种整数张量的层(即 Embedding 层,本书后面会详细介绍)。
- 对列表进行 one-hot 编码,将其转换为 0 和 1 组成的向量。举个例子,序列 [3, 5] 将会被转换为 10 000 维向量,只有索引为 3 和 5 的元素是 1,其余元素都是 0。然后网络第一层可以用 Dense 层,它能够处理浮点数向量数据。
此处采用第二种方法。将整数序列编码为二进制矩阵(One-hot编码)。
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
#创建一个形状为(len(sequences),dimension) 的零矩阵
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
#将 results[i] 的指定索引设为 1
return results
x_train = vectorize_sequences(train_data) #将训练数据向量化
x_test = vectorize_sequences(test_data) #将测试数据向量化
将标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
3.3.3 构建网络
输入数据是向量,而标签是标量(1 和 0),常用带有 relu 激活的全连接层( Dense )的简单堆叠。选择的下列架构:
- 两个中间层,每层都有 16 个隐藏单元;
- 第三层输出一个标量,预测当前评论的情感。
中间层使用 relu 作为激活函数,最后一层使用 sigmoid 激活以输出一个 0~1 范围内的概率值(表示样本的目标值等于 1 的可能性,即评论为正面的可能性)。
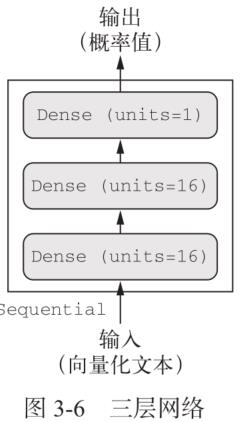
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
3.3.4 编译模型
三种方法选一种:
- 使用默认优化器
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])上述代码将优化器、损失函数和指标作为字符串传入,这是因为 rmsprop 、 binary_crossentropy 和 accuracy 都是 Keras 内置的一部分。
- 使用配置优化器
from keras import optimizers model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['accuracy']) - 使用自定义的损失和指标
from keras import losses from keras import metrics model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss=losses.binary_crossentropy, metrics=[metrics.binary_accuracy])
3.3.5 留出验证集
为了在训练过程中监控模型在未见的数据上的精度,你需要将原始训练数据留出 10 000个样本作为验证集。
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
3.3.6 训练模型
- 主要思路
- 现在使用 512 个样本组成的小批量,将模型训练 20 个轮次(即对 x_train 和 y_train 两个张量中的所有样本进行 20 次迭代)。
- 你还要监控在留出的 10 000 个样本上的损失和精度。
- 通过将验证数据传入 validation_data 参数来完成。
history = model.fit(partial_x_train,partial_y_train, epochs=20,batch_size=512, validation_data=(x_val, y_val)) - 查看所有训练数据
调用 model.fit() 返回了一个 History 对象。这个对象有一个成员 history ,它是一个字典,包含训练过程中的所有数据。history_dict = history.history history_dict.keys()dict_keys(['val_acc', 'acc', 'val_loss', 'loss'])包含 4 个条目,对应训练过程和验证过程中监控的指标。
3.3.7 绘制结果
- 绘制训练损失和验证损失
import matplotlib.pyplot as plt history_dict = history.history loss_values = history_dict['loss'] val_loss_values = history_dict['val_loss'] epochs = range(1, len(loss_values) + 1) plt.plot(epochs, loss_values, 'bo', label='Training loss') # 'bo' 表示蓝色圆点 plt.plot(epochs, val_loss_values, 'b', label='Validation loss') # 'b' 表示蓝色实线 plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()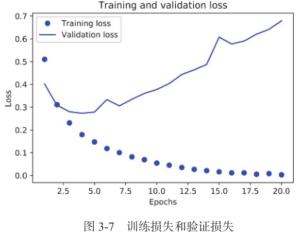
- 绘制训练精度和验证精度
plt.clf() #清空图片 acc = history_dict['accuracy'] val_acc = history_dict['val_accuracy'] plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()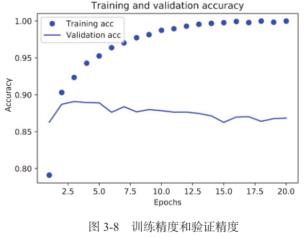
从图中可知:
- 训练损失每轮都在降低,训练精度每轮都在提升。这就是梯度下降优化的预期结果——你想要最小化的量随着每次迭代越来越小。
- 但验证损失和验证精度并非如此:它们似乎在第四轮达到最佳值。
所以 过 拟 合 \\color{red}过拟合 过拟合了。
3.3.8 重新训练模型
- 从头开始重新训练一个模型
最终结果如下所示。model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=4, batch_size=512) results = model.evaluate(x_test, y_test)
这种相当简单的方法得到了 88% 的精度。利用最先进的方法,你应该能够得到接近 95% 的精度。>>> results [0.2929924130630493, 0.88327999999999995]
使用训练好的网络在新数据上生成预测结果:
网络对某些样本的结果非常确信(大于等于 0.99,或小于等于 0.01),但对其他结果却不那么确信(0.6 或 0.2)。>>> model.predict(x_test) array([[ 0.98006207] [ 0.99758697] [ 0.99975556] ..., [ 0.82167041] [ 0.02885115] [ 0.65371346]], dtype=float32)
3.3.9 总结
- 进一步实验:
- 前面使用了两个隐藏层。你可以尝试使用一个或三个隐藏层,然后观察对验证精度和测
试精度的影响。 - 尝试使用更多或更少的隐藏单元,比如 32 个、64 个等。
- 尝试使用
mse损失函数代替binary_crossentropy。 - 尝试使用
tanh激活(这种激活在神经网络早期非常流行)代替relu。
- 前面使用了两个隐藏层。你可以尝试使用一个或三个隐藏层,然后观察对验证精度和测
- 小结
- 通常需要对原始数据进行大量预处理,以便将其转换为张量输入到神经网络中。单词序列可以编码为二进制向量,但也有其他编码方式。
- 带有
relu激活的Dense层堆叠,可以解决很多种问题(包括情感分类),你可能会经常用到这种模型。 - 对于二分类问题(两个输出类别),网络的最后一层应该是只有一个单元并使用
sigmoid激活的Dense层,网络输出应该是 0~1 范围内的标量,表示概率值。 - 对于二分类问题的
sigmoid标量输出,你应该使用binary_crossentropy损失函数。 - 无论你的问题是什么,
rmsprop优化器通常都是足够好的选择。这一点你无须担心。 - 随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未见的数据上得到越来越差的结果。一定要一直监控模型在训练集之外的数据上的性能。
以上是关于《Python深度学习》第三章第一部分读书笔记的主要内容,如果未能解决你的问题,请参考以下文章