学习笔记Python - Lxml
Posted SAP剑客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Python - Lxml相关的知识,希望对你有一定的参考价值。
Lxml库
Lxml库是基于libxm12的XML解析库的Python封装,该模块使用C语言编写,解析的速度比Beautiful Soup更快。Lxml库使用Xpath语法解析定位网页数据。
Lxml库的安装
pip install lxml
Lxml库的使用
1、修正HTML代码
Lxml为XML解析库,但也很好地支持了html文档地解析功能,这为使用Lxml库爬取网络信息提供了支持条件。
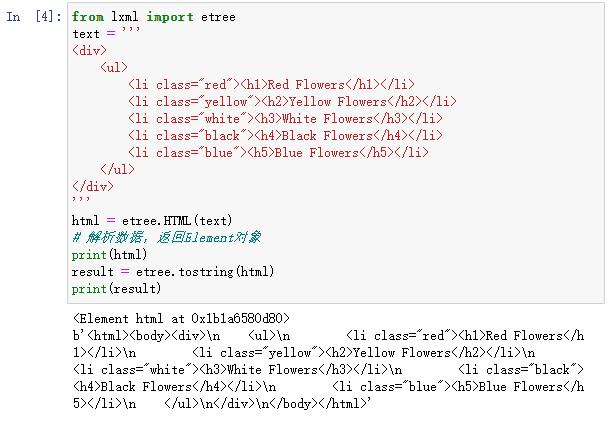
首先需要导入Lxml库中地etree库,利用etree.HTML进行初始化,返回解析后的Element对象,这里可以看到,Lxml有一个非常实用的功能,就是自动修正了HTML代码(比如标签对漏掉的情况也会自动补齐)。
2、读取HTML文件
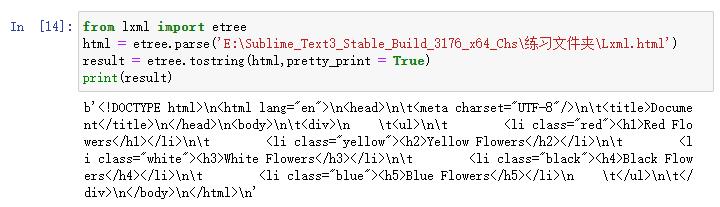
将上面的HTML文件拷贝到Sublime中保存为HTML文件。

然后通过Lxml库读取HTML文件中的内容。
3、解析HTML文件
经过上面的步骤,便可以使用requests库获取HTML文件,然后用Lxml库来解析HTML文件。

Xpath语法
Xpath是一门在XML文档中查找信息的语言,对HTML文档又很好的支持。
|
【基本概念】
- 父节点:每个元素及属性都有一个父节点,上例中的user元素就是name、sex、id和goal的父节点;
- 子节点:元素节点可以有0个或者多个子节点,上例中的name、sex、id和goal元素就是user的子节点;
- 同胞节点:拥有相同父节点,上例中的name、sex、id和goal元素就是同胞节点;
- 先辈节点:某节点的父节点、父节点的父节点等,上例中的name元素的先辈节点是user和user_database;
- 后代节点:某个节点的子节点、子节点的子节点等,上例中的user_database元素的后代节点是user、name、sex、id和goal;
Xpath使用路径表达式在XML文档中选取节点,节点是通过沿着路径或者step来选取的。
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
根据上例举例说明:
| 路径表达式 | 结果 |
| user_databaser | 选取元素user_databaser的所有子节点 |
| /user_databaser | 选取根元素user_databaser |
| user_databaser/user | 选取属于user_databaser的子元素的所有user元素 |
| //user | 选取所有user子元素,不考虑他们在文档中位置 |
| user_databaser//user | 选取属于user_databaser元素的后代所有user元素,不管位置 |
| //@attribute | 选取名为attribute的所有属性 |
Xpath中也可以使用通配符来选取位置的元素,常用的就是“*”通配符,它可以匹配任何元素节点。
Xpath语法中的谓语用来查找某个特定的节点或者包含某个指定值的节点,谓语被嵌在方括号中。
| 路径表达式 | 结果 |
| /user_databaser/user[1] | 选取属于user_databaser子元素的第一个user元素 |
| //li{[@attribute] | 选取所有拥有名为attribute属性的li元素 |
| //li{[@attribute=’red’] | 选取所有li元素,且这些元素拥有值为red的attribute属性 |


以上是关于学习笔记Python - Lxml的主要内容,如果未能解决你的问题,请参考以下文章
python笔记:windows 下安装 python lxml