爬虫学习笔记 -- 实战某电影网(lxml库版)
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习笔记 -- 实战某电影网(lxml库版)相关的知识,希望对你有一定的参考价值。
0x01 安装lxml库文件
pip3 install lxml
0x02 初始化字符串
1、通过html类初始化字符串
from lxml import etree
import requests
url = "https://www.dandanzan10.top/dianying/index.html"
heads =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
r = requests.get(url, headers=heads)
str = r.text
html=etree.HTML(str)
print(html)
运行结果:<Element html at 0x17bf61e9d80>0x03 获取xpath路径
1、右击要获取的字符串,选择审查元素
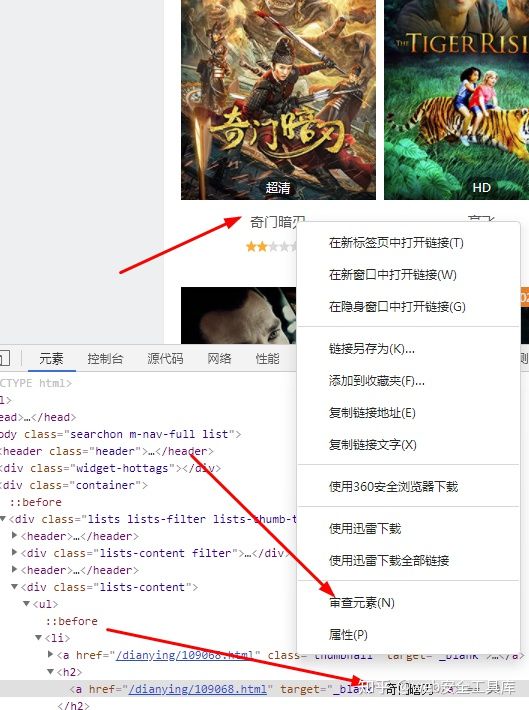
2、右击要获取字符串这行,选择复制,选择复制Xpath

/html/body/div[2]/div/div[2]/ul/li[1]/h2/a0x04 利用Xpath获取电影名
from lxml import etree
import requests
url = "https://www.dandanzan10.top/dianying/index.html"
heads =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
r = requests.get(url, headers=heads)
str = r.text
html=etree.HTML(str)
res=html.xpath('/html/body/div[2]/div/div[2]/ul/li[1]/h2/a/text()')
print(res)
运行结果:['奇门暗刃']1、text()获取节点内容
2、"ul/li[1]",这里只是获取了第一个电影名字
3、因为有多个li节点,所以将下标1去了就可以获取所有节点内容
res=html.xpath('/html/body/div[2]/div/div[2]/ul/li/h2/a/text()')0x05 声明
仅供安全研究与学习之用,若将工具做其他用途,由使用者承担全部法律及连带责任,作者不承担任何法律及连带责任。
欢迎关注编程者吧


以上是关于爬虫学习笔记 -- 实战某电影网(lxml库版)的主要内容,如果未能解决你的问题,请参考以下文章