20行Python scrapy 代码,去采集蓝桥训练营
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20行Python scrapy 代码,去采集蓝桥训练营相关的知识,希望对你有一定的参考价值。
scrapy 中的 settings.py 文件在项目中是非常重要的,因其包含非常多的配置。
这篇博客基于官方手册为你说明 settings.py 文件相关配置,并补充一些扩展说明。
settings 的 4 个级别
- 优先级最高 - 命令行,例如
scrapy crawl my_spider -s LOG_LEVEL=WARNINI; - 优先级第二 - 爬虫文件自己的设置,例如在
xxx.py文件中设置custom_settings; - 优先级第三 - 项目模块,这里指的是
settings.py文件中的配置; - 优先级第四 -
default_settings属性配置; - 优先级第五 -
default_settings.py文件中的配置。
settings配置的读取,一般使用spider中的from_crawler方法,在中间件,管道,扩展中都可以进行调用。
settings 配置读取操作非常简单,上一篇博客已经有所涉及,命令格式如下所示:
scrapy settings --get 配置变量名称
settings 常用配置
基本配置
BOT_NAME:爬虫名称;SPIDER_MODULES:爬虫模块列表;NEWSPIDER_MODULE:模块在哪里使用genspider命令创建新的爬虫;
日志
scrapy 日志与 logging 模块一致,使用 5 个级别:
配置名为 LOG_LEVEL,最低的是 DEBUG(默认),INFO,WARNING,ERROR,CRITICAL(最高)。
其余日志相关配置如下,
LOGSTATS_INTERVAL:设置日志频率,默认是 60 秒,可以修改为 5 秒,LOG_FILE:日志文件;LOG_ENABLED:是否启用日志,关闭了运行爬虫,就啥都不输出了;LOG_ENCODING:编码;LOG_FORMAT:日志格式,这个可以参考logging模块学习;LOG_DATEFORMAT:同上,负责格式化日期/时间;
统计
STATS_DUMP:默认开启,爬虫采集完毕,将爬虫运行信息统计并输出到日志;DOWNLOADER_STATS:启用下载中间件统计;DEPTH_STATS和DEPTH_STATS_VERBOSE:统计深度相关设置;STATSMAILER_RCPTS:爬虫采集完毕,发送邮箱列表。
性能
CONCURRENT_REQUESTS:最大并发请求数,抓取不同网站时使用,该值默认是 16,如果一次请求耗时 0.2 秒,则并发极限是 16/0.2 = 80 次请求CONCURRENT_REQUESTS_PER_DOMAIN和CONCURRENT_REQUESTS_PER_IP:单个域或者单个 IP 的最大并发请求数;CONCURRENT_ITEMS:每次请求并发处理的最大文件数,如果CONCURRENT_REQUESTS=16,CONCURRENT_ITEMS=100,则表示每秒有 1600 个文件会被写入数据库;DOWNLOAD_TIMEOUT:下载器在超时前等待的时间量;DOWNLOAD_DELAY:下载延迟,限制爬取速度,配合RANDOMIZE_DOWNLOAD_DELAY使用,会使用一个随机值 *DOWNLOAD_DELAY;CLOSESPIDER_TIMEOUT,CLOSESPIDER_ITEMCOUNT,CLOSESPIDER_PAGECOUNT,CLOSESPIDER_ERRORCOUNT:四个配置比较类似,都是为了提前关闭爬虫,分别为时间,抓取 item 的数量,发出一定的请求数,发生一定的错误量。
抓取相关
USER_AGENT:用户代理;DEPTH_LIMIT:抓取的最大深度,在深度抓取时有用;ROBOTSTXT_OBEY:是否遵守robots.txt约定;COOKIES_ENABLED:是否禁用 cookie,禁用之后有时能提高采集速度;DEFAULT_REQUEST_HEADERS:请求头;IMAGES_STORE:使用ImagePipeline时图片的存储路径;IMAGES_MIN_WIDTH和IMAGES_MIN_HEIGHT:筛选图片;IMAGES_THUMBS:设置缩略图;FILES_STORE:文件存储路径;FILES_URLS_FIELD与FILES_RESULT_FIELD:使用Files Pipeline时的一些变量名配置;URLLENGTH_LIMIT:允许抓取网站地址的最大长度。
扩展功能
ITEM_PIPELINES:管道配置;COMMANDS_MODULE:自定义命令;DOWNLOADER_MIDDLEWARES:下载中间件;SCHEDULER:调度器;EXTENSIONS:扩展;SPIDER_MIDDLEWARES:爬虫中间件;RETRY_*:设置了 Retry 相关中间件配置;REDIRECT_*:设置了 Redirect 相关中间件配置;METAREFRESH_*:设置了 Meta-Refresh 中间件相关配置;MEMUSAGE_*:设置了内存相关配置。
settings 配置的一些技巧
- 通用配置写在项目的
settings.py文件中; - 爬虫个性化设置写在
custom_settings变量内; - 不同进行的爬虫,配置要初始化在命令行内。
本篇博客的爬虫案例
这一次的爬虫就采集蓝桥训练营的课程吧,页面经过测试得到的请求地址如下:
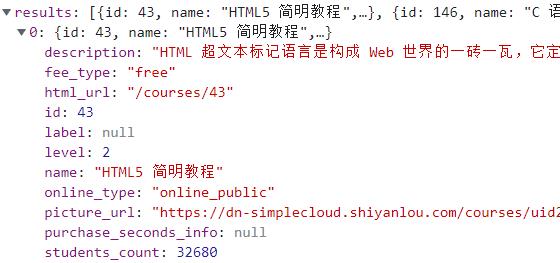
https://www.lanqiao.cn/api/v2/courses/?page_size=20&page=2&include=html_url,name,description,students_count,fee_type,picture_url,id,label,online_type,purchase_seconds_info,level
其中参数除了 page_size 和 page 以外,还存在一个 include 参数,这也是接口中常用的一个参数,其值代表接口返回哪些字段(包含哪些属性),如下图所示。
接下来就使用 scrapy 将其实现,并把结果保存到 json 文件中。
lanqiao.py 文件代码
import json
import scrapy
from lq.items import LqItem
class LanqiaoSpider(scrapy.Spider):
name = 'lanqiao'
allowed_domains = ['lanqiao.cn']
def start_requests(self):
url_format = 'https://www.lanqiao.cn/api/v2/courses/?page_size=20&page={}&include=html_url,name,description,students_count,fee_type,picture_url,id,label,online_type,purchase_seconds_info,level'
for page in range(1, 34):
url = url_format.format(page)
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
json_data = json.loads(response.text)
for ret_item in json_data["results"]:
item = LqItem(**ret_item)
yield item
代码中直接将 ret_item 赋值到了 LqItem 的构造函数中,实现对字段的赋值。
items.py 文件代码
该类主要对数据字段进行限制。
import scrapy
class LqItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
html_url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
students_count = scrapy.Field()
fee_type = scrapy.Field()
picture_url = scrapy.Field()
id = scrapy.Field()
label = scrapy.Field()
online_type = scrapy.Field()
purchase_seconds_info = scrapy.Field()
level = scrapy.Field()
settings.py 开启部分配置
BOT_NAME = 'lq'
SPIDER_MODULES = ['lq.spiders']
NEWSPIDER_MODULE = 'lq.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 16
DOWNLOAD_DELAY = 3
爬虫运行结果:
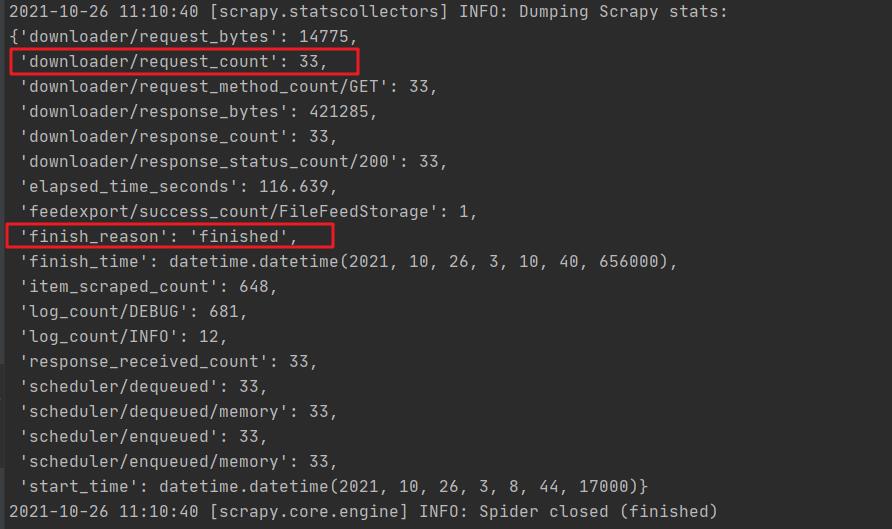
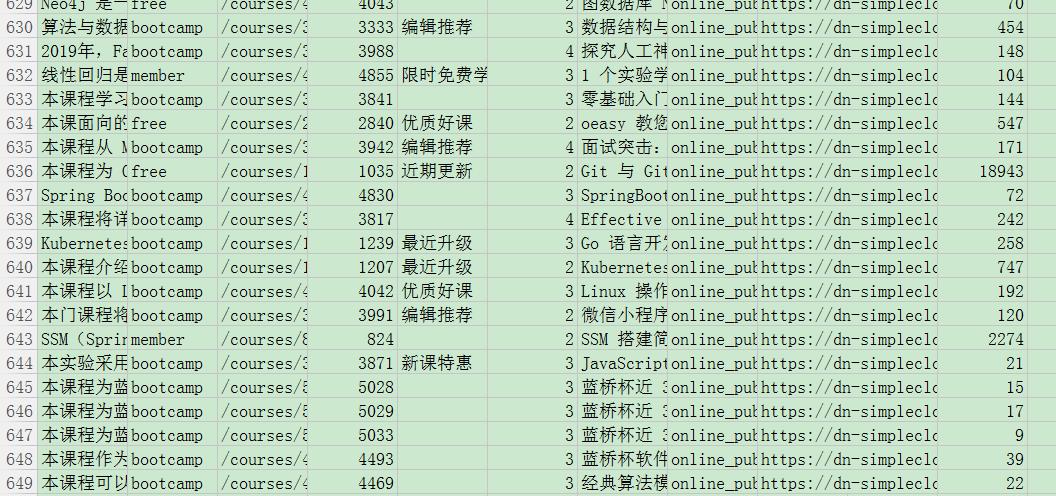
累计爬取到 **600+**课程信息。
写在后面
今天是持续写作的第 254 / 365 天。
期待 关注,点赞、评论、收藏。
更多精彩

以上是关于20行Python scrapy 代码,去采集蓝桥训练营的主要内容,如果未能解决你的问题,请参考以下文章
python scrapy ,几行代码实现一个搜狗图片下载器
分享《精通Python爬虫框架Scrapy》中文PDF+英文PDF+源代码+Python网络数据采集
Python scrapy+selenium登录你的CSDN账号,然后去给别人点关注 -- 2019-08-08 20:39:43