数据湖构建与计算
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖构建与计算相关的知识,希望对你有一定的参考价值。
简介: 2021云栖大会云原生企业级数据湖专场,阿里云智能高级产品专家李冰为我们带来《数据湖构建与计算》的分享。本文主要从数据的入湖和管理、引擎的选择展开介绍了数据湖方案降本增效的特性。
摘要:2021云栖大会云原生企业级数据湖专场,阿里云智能高级产品专家李冰为我们带来《数据湖构建与计算》的分享。

本文主要从数据的入湖和管理、引擎的选择展开分享了数据湖方案降本增效的特性。
以下是精彩视频内容整理:
一、面临的挑战
- 数据如何入湖和管理
- 引擎如何选择
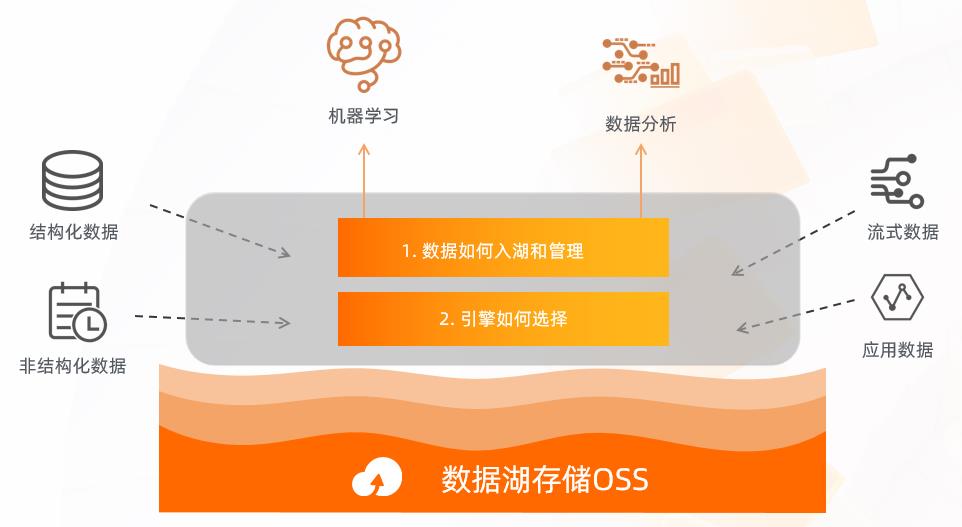
我们在前面的分享当中了解到了OSS将作为数据湖计算当中的中心化的存储。其实数据湖计算本质上就是输入来自各种云上的数据源,经过一系列的转化运算,最终能够支持上层计算的 BI 和 AI 的分析。那在整个数据湖的构建当中,其实我们需要考虑两个问题,一个是各种各样的数据,如何流入到 OSS 的存储当中,流入以后需要做怎样的管理和规划;第二个就是为了支持上层的业务,如何选择计算引擎。接下来我们带着这两个问题开始今天的分享。
二、数据湖的构建
如何进行数据湖构建与管理
如何搭建数据湖
- 存储配置
- 开通 OSS 存储
- 配置存储
- 元数据配置
- 元数据服务搭建
- 创建元数据
- 迁移元数据
- 数据迁移
- 实时数据/全量数据入湖
- 数据清洗
- 更新元数据
- 安全管理
- 数据权限配置
- 数据审计
- 数据计算与分析
- 交互式分析
- 数据仓库
- 实时分析
- 可视化报表分析
- 机器学习
需要解决的问题:
- 元数据服务搭建复杂,维护成本较高
- 实时数据入湖,开发周期长,运维成本高,需要构建流计算任务SparkStreaming/Flink 对数据进行清理
- 多个计算引擎,需要配置多套元数据,且需要考虑元数据同步,同步的准确性,实时性等问题
- 湖上的不同计算引擎使用了不同的权限体系,同一个资源的权限需要在多个引擎多次配置,配置和维护成本高
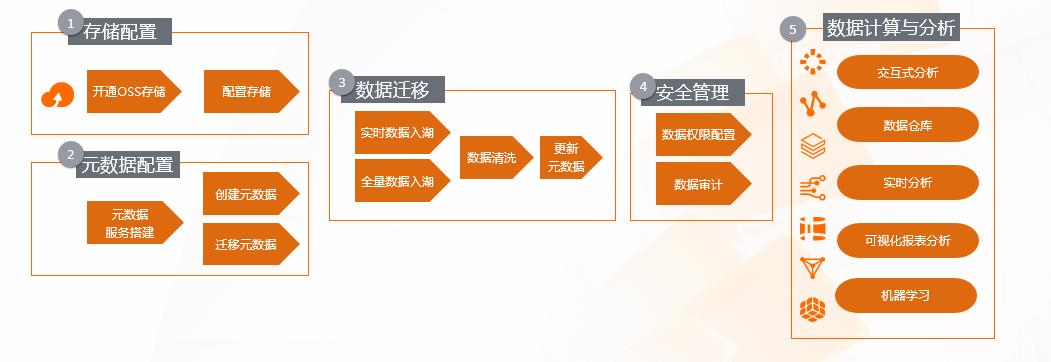
首先我们来看数据湖的构建。如果我们没有一个标准的云产品,我们在云上怎么样去搭建数据湖呢?我拆解了一下,大概需要五部分。
首先要选择一个存储,我们开通了 OSS 服务以后,选择一个 burket,然后做一些基本的配置。第二步就是数据已经存到 OSS 以后,如何管理数据的元数据。这里面可能会涉及到目录的编排、scheme 的设计等。这一步其实是非常重要的,因为它会关系到后面的运算。在数据湖计算当中,存储是统一,计算是支持多类计算引擎的,所以我们在设计元数据的时候,需要考虑如何让它被所有的计算引擎去消费;当计算引擎对数据做了变更以后,元数据怎么样做到同步,保持一致性。元数据设计完以后,我们就需要考虑重头戏--数据的迁移。我们知道数据通常分为两大部分,一个是原始的历史数据怎么全量到云上,这部分我们会通过一些工具,一次性的把它导入到 OSS 当中;还有一个需要去考虑的就是增量数据怎么样能够实时的入湖,入湖以后选择什么样的格式?这些数据进入数据湖以后,是否需要修改,修改的话对上面的引擎有没有影响?数据变了以后,对元数据怎么样把这个消息带过去?以上是我们在做数据迁移时需要考虑和解决的问题。
然后就是安全,我们知道数据湖虽然是开放的,但是访问权限是有限制的,不能所有用户都可以访问这些数据,所以我们要有一个统一的权限规划。这里面我们需要考虑的问题是,这个权限是否可以被所有的引擎所读到和了解?如果我用了五种引擎,每一种引擎都设置他自己的权限和配置,这样对于使用和运维其实都是非常大的一个困扰。
数据湖构建 Data Lake Formation
- 元数据管理
- 统一元数据管理,对接多种计算引擎
- 兼容开源生态API
- 自动生成元数据,降低使用成本
- 提供一键式元数据迁移方案
- 访问控制
- 集中数据访问权限控制,多引擎统一集中式赋权
- 数据访问日志审计,统计数据访问信息
- 数据入湖
- 支持多种数据源入湖,mysql、Polardb、SLS、OTS、Kafka等
- 离线/实时入湖,支持Delta/Hudi等多种数据湖格式
- 数据探索
- 支持便捷的数据探查能力,快速对湖内(OSS)数据进行探索与分析
- 支持 Spark SQL 语法
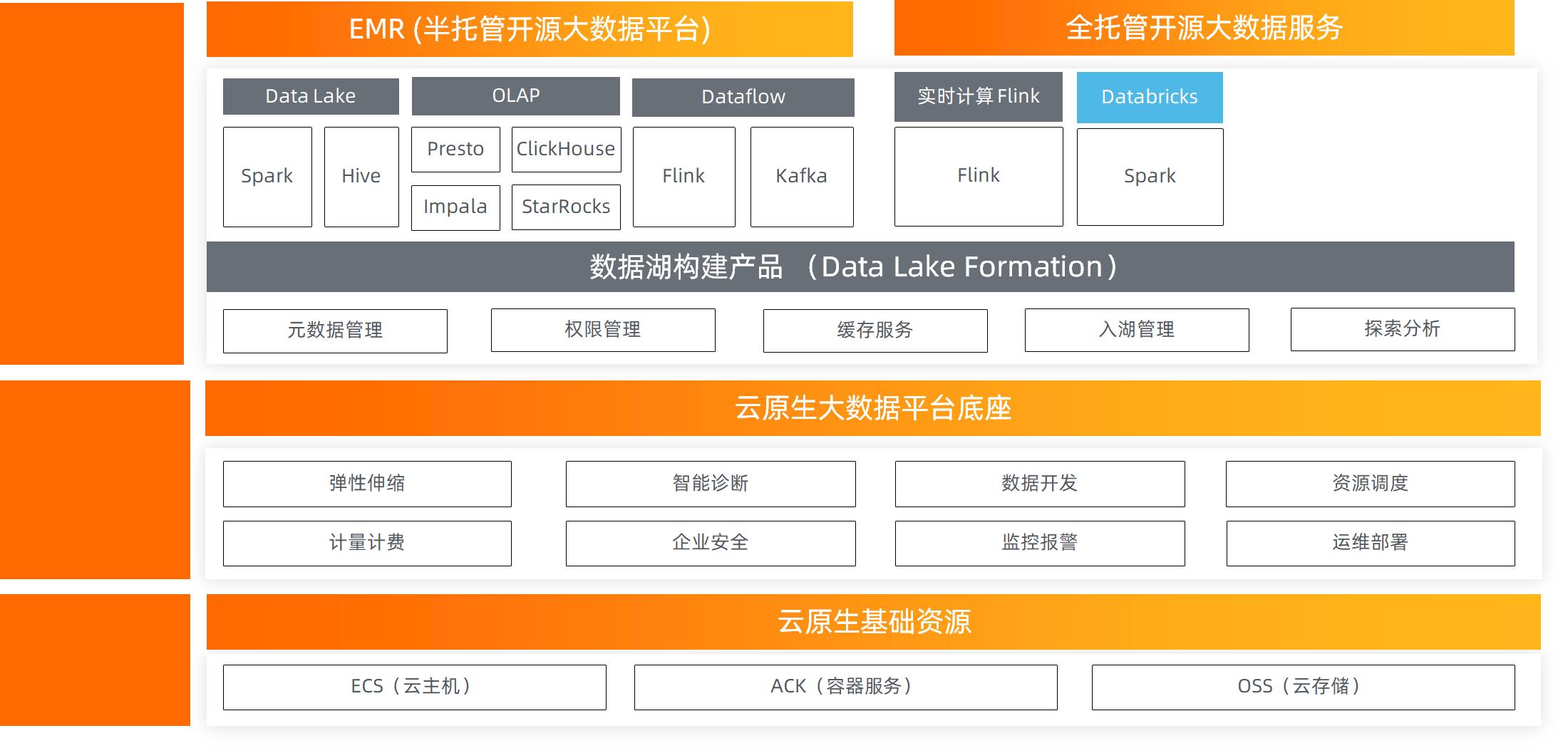
基于前面的这些问题,在阿里云上,我们提供了这样一个产品帮助大家来完成数据湖的构建。这个产品叫 Data Lake Formation,简称 DLF。DLF 主要提供了四个能力。首先是数据的入湖,我们知道数据源是多种多样的,所以 DLF 数据入湖的这个功能,也是支持了阿里云上很多比较通用和标准的数据源,比如 MySQL,SLS、 Kafka 等等。针对入湖,用户可以选择不同的入湖方式。离线还是实时、数据以什么格式进入?包括在入湖的过程当中,是否加入一些简单的计算,对这些数据做一些清理?或者加入一些自定义 UDF,以上这些能力在 DLF 当中都是支持的。然后数据进入以后,元数据的部分,我们对外会提供了一个统一的元数据接口。这个接口是可以被阿里云上的大部分引擎去消费的,包括 EMR、Databricks、PAI、 MaxCompute、Hologres 等等。并且这个元数据是支持一键同步的,比如我在 RDS 里面有一份元数据,转化成数据湖的方案以后,库表信息可以通过一键的方式同步到 DLF 当中。第三点就是权限的配置,用户只需要设置一次,比如某一个用户,对某一份数据有怎样的读取权限,设置好之后就可以被上面所有的引擎所共用。在这基础之上,DLF 还提供一个叫数据探索的能力,这个是一个开箱即用的功能。用户数据进入到数据湖以后,可以通过它做一个快速的验证。可以输入标准的 Spark SQL 语法,然后就可以查询出结果是不是用户所需要的,来验证这个数据的正确性。

三、数据湖的计算
阿里云 EMR 开源大数据平台
说完了前面的数据湖构建以后,下一部分就是计算。其实在阿里云上,我们有一个产品叫 EMR,与其说 EMR 是一个产品,不如说它更像是一个开源大数据平台。在这个平台上,我们提供非常多的 Hadoop 开源生态引擎,用户几乎可以在这里面找到所有能够满足业务场景的引擎。首先 EMR 是构建在云原生的基础资源之上的,它是构建在 ECS 之上的,如果你有 ACK 的容器服务,也可以部署在容器上。然后存储的话,可以存到 OSS 上,然后有一个基础的管控平台,在这个平台上,会给用户提供一些运维部署、资源管理、弹性伸缩等等这样的能力,最终目的就是帮助用户更简单,更容易的去运维大数据集群。然后 EMR 的引擎部分,一共提供了几十种不同的丰富的引擎,这里面罗列了几个比较代表性的,用户可以根据不同的业务需求去选择。值得一提的是,所有的引擎都可以作为数据湖的引擎,可以去消费 OSS 数据,把 OSS 作为它的最终存储。同时它可以对接到 DLF 上面,用户做完了元数据的配置、权限的配置后,就可以很方便的在 EMR 上去切换不同的引擎,这样可以达到元数据的统一和数据的统一。
主要解决两大问题
- 降低成本
- 硬件成本
- 改造和使用成本
- 运维成本
- 提高效率
- 性能
- 资源利用率
- 可扩展性
我们自己构建大数据平台的时候,其实比较关心的核心的两个问题,一个是成本,还有一个就是效率。这个也是 EMR 主要去解决的两个问题。这里面的成本其实包括三个方面,硬件的成本、软件的成本,还有后期运维的成本。相信这些是大家在线下去构建自己的大数据平台当中,一定会遇到的非常头疼和急需面对的问题。另外与它相对应的效率,我们希望能够最大限度的去提高资源的利用率。同时希望集群是具有灵活性和可扩展性的。接下来我们看一下 EMR 是怎么样去解决这两个问题的。
全新容器化部署EMR on ACK
- 节省成本
- 复用已有 ACK 集群的空闲资源
- 大数据和在线应用程序共享集群资源,削峰填谷
- 简化运维
- 一套运维体系,一套集群管理
- 提升效率
- 利用 ACK/ECI 的资源快速交付能力,资源获取时间更短;
- 结合自研 Remote Shuffle Service,Spark 内核及资源调度优化,满足生产级业务需求
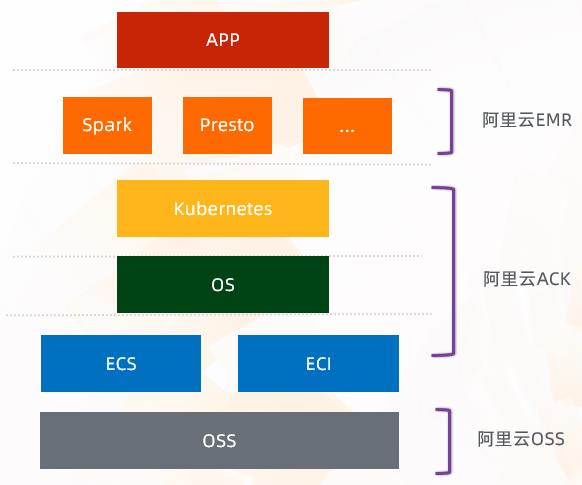
首先,EMR 在今年推出了一个新的特性,就是容器化的部署方案。之前传统的 EMR 都是部署在 ECS 上的,现在 EMR 可以部署在 ACK 上。这里的 ACK 其实是一个已有的 ACK 集群。随着大数据生态的发展,Kubernetes 这个技术也越来越成熟,很多用户会把自己在线的业务,甚至是一些在线的作业去跑在 ACK 集群上。但是在线的业务有一个特点,它使用的时间通常在白天,这样就造成了晚上这部分计算资源的空闲。相比较大数据而言,很多是为了支持报表类的业务,所以它使用资源的高峰期大多在晚上。如果能够把大数据作业和在线作业跑在一套系统里面,对用户来说就达到了削峰填谷、资源重复利用的能力。同时从运维的角度,只需要运维一套 ACK 的集群,这样就可以统一运维体系,降低运维成本。从 EMR 这一侧的引擎来说,从开源上大数据跑在 ACK 上,其实还是一个相对初期的阶段,可能它有一些特性在企业级的应用上是没办法支持的。基于这一点,EMR 也做了很多引擎上的优化,包括提供了这种 Remote Shuffle 的能力,它主要是为了解决在 ACK 上的挂盘问题,另外在调度上面也做了很多深入的优化,能够满足用户大数据量的企业级的查询分析需求。
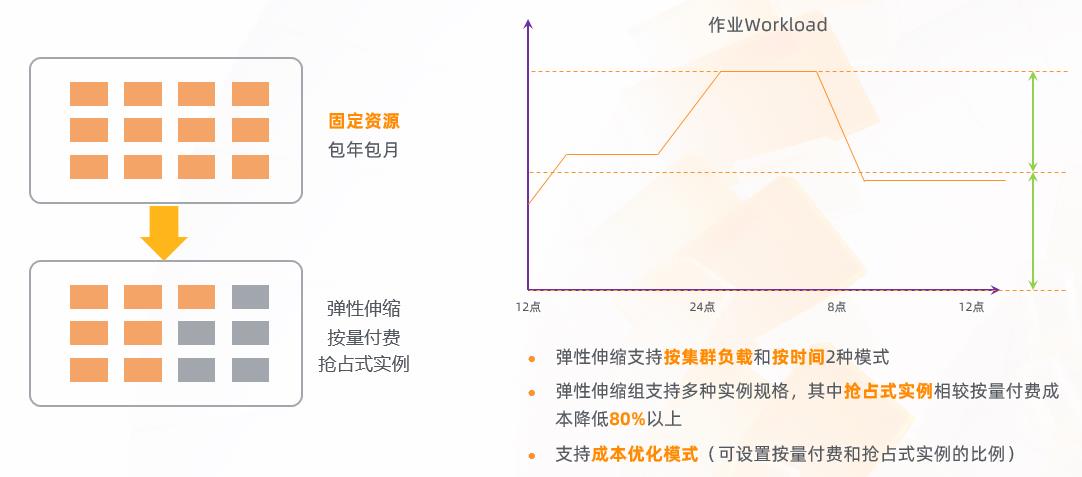
弹性伸缩
EMR 集群:固定资源 -> 固定资源 + 弹性动态资源
和线下的 IDC 集群相比,云上最显著的一个特性就是动态和可扩展性。为了最大限度的发挥这部分的价值, EMR 提供了集群级别的弹性伸缩。简单来说就是比如原先有一个集群,这个集群是固定的,假设有100台节点,7×24小时去跑。但其实在这100台节点当中,可能大部分时间只用了里面50%的能力,这个时候会把集群做一个拆分,一部分只保留固定的计算资源,其他的高峰期则用一个弹性的资源去弥补,这样就可以从硬件资源的使用上面去压缩成本。另外在 EMR 里面,对于弹性资源的部分是支持成本优化模式的。在 ECS 里面它有一种实力叫挑战式的实力,这种实力它的收费方式会比按量付费更便宜,这样就可以进一步的压缩计算的成本,真正做到按需创建机器资源,用户去谈这部分资源的时候,也可以按照自己的集群的负载或者是时间段去灵活的控制。
引擎优化
Spark
- 支持Spark 3.1.2,相对社区版Spark 2,性能提升3倍以上
- 针对复杂分析场景优化,TPC-DS较社区版提速59%
- 在ACK场景下,优化了调度性能,较社区版K8S有4倍提升
Hive
- TPC-DS 特定 SQL 达到数倍性能提升,整体性能提升19%;
- 针对大表 Join 的性能优化
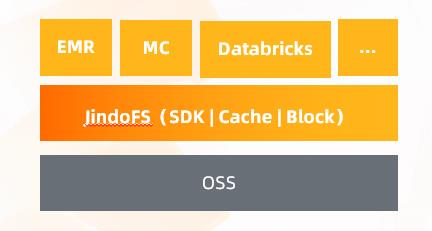
JindoFS
- OSS 访问加速,提供标准的 HDFS 访问接口,支持 EMR 所有引擎
- 冷热数据自动分离,对计算层透明
- 对文件的 ls/delete/rename 等操作,较开源方案性能数倍提升
传统的大数据集群是跑在 Hadoop 生态下面的,它本身的存储是 HDFS ,转换到数据湖以后,当你的介质变成了不是本地的 OSS 时,需要引擎上面做很多支持。我列举了几个比较有代表性的,比如 Spark、Hive,在官方的 TPC-DS上面可以看到我们的成绩是优于社区数倍的。另外值得一提的就是 JindoFS ,这个组件是 EMR 自研的一个组件,可以把它看做承上启下的作用。对下面底层的话,它的数据还是存储在 OSS 上面,对上层的引擎除了在接口上面的支持以外,更多的是对 OSS 的访问做了一个加速,并且让引擎能够很透明的去使用 OSS。数据落进来以后可以做到自动的冷热分离,并且我们和 OSS 团队做了深度的优化,OSS 在做一些文件级别的操作,尤其是小文件的操作上面,性能都要比开源的方案或者甚至有的场景下会比 HDFS 的性能更好。
丰富的生态
- 更多开源组件
ClickHouse、StarRocks、EMR Studio(Notebook,AirFlow)、Spark 3.0 等
- 深度云产品集成
阿里云 DataWorks、阿里云容器服务(ACK)、云监控等
- 支持更多三方产品
Databricks、Cloudera、Confluent、神策等
EMR 更多的是一个开源的开放的大数据平台,在这个平台上面不仅有开源的产品,这部分的组件会根据市场情况逐步增加到平台中。除此以外,作为阿里云上的一款产品,EMR 会和像 DataWorks、ACK、甚至还有云监控等产品做一个深度的集成,方便大家能充分利用阿里云上其他云产品的特性。除此之外,EMR 还会支持更多的第三方产品,比如 Databricks、Cloudera、Confluent、神策等来让平台有更好的扩展性和可集成性。
使用 EMR 降本增效
- 使用弹性伸缩,动态调整集群规模,按需购买 ECS 资源
- 利用已有 ACK 集群,大数据和在线应用共享计算资源
- EMR 计算引擎的优化,提高任务执行效率
- OSS 访问利器 JindoFS,让迁移更平滑
最后总结一下,其实 EMR 能够达到降本增效主要是从硬件和软件两方面。硬件上让计算更按需进行,不会有过多资源上的浪费;软件上通过提升引擎的性能来做到加速,让单位的计算的成本更低。
四、小结
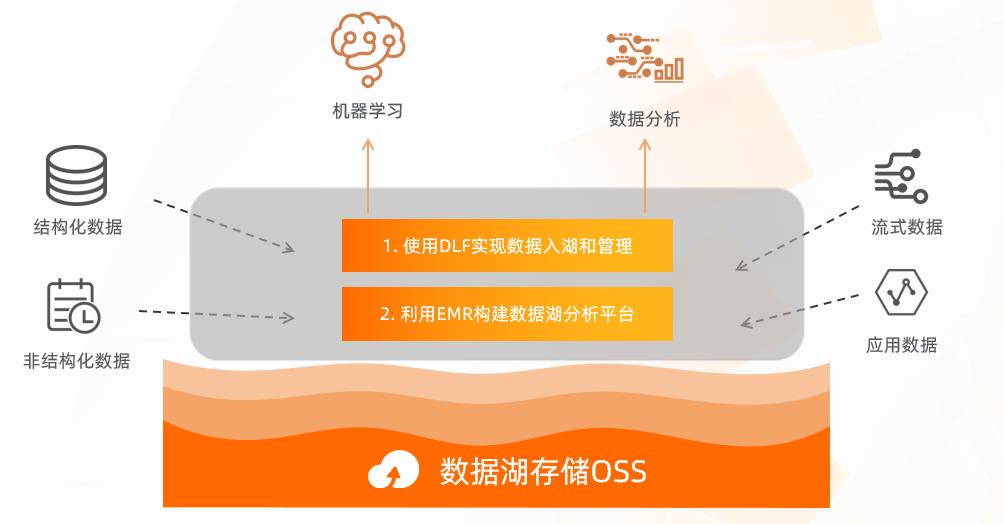
回到最开始提到的问题,构建数据湖的时候,我们首先会使用 DLF 来完成数据的入湖和元数据的管理;通过 EMR 上丰富的引擎来构建计算平台;然后利用 OSS 的存储来发挥最大的价值,做数据的冷热分层,从而使整体的数据湖方案能够达到降本增效的目的。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于数据湖构建与计算的主要内容,如果未能解决你的问题,请参考以下文章