链表面试题,彻底巩固你的数据结构链表知识~
Posted 再吃一个橘子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了链表面试题,彻底巩固你的数据结构链表知识~相关的知识,希望对你有一定的参考价值。
1.删除链表中等于给定值 val 的所有节点
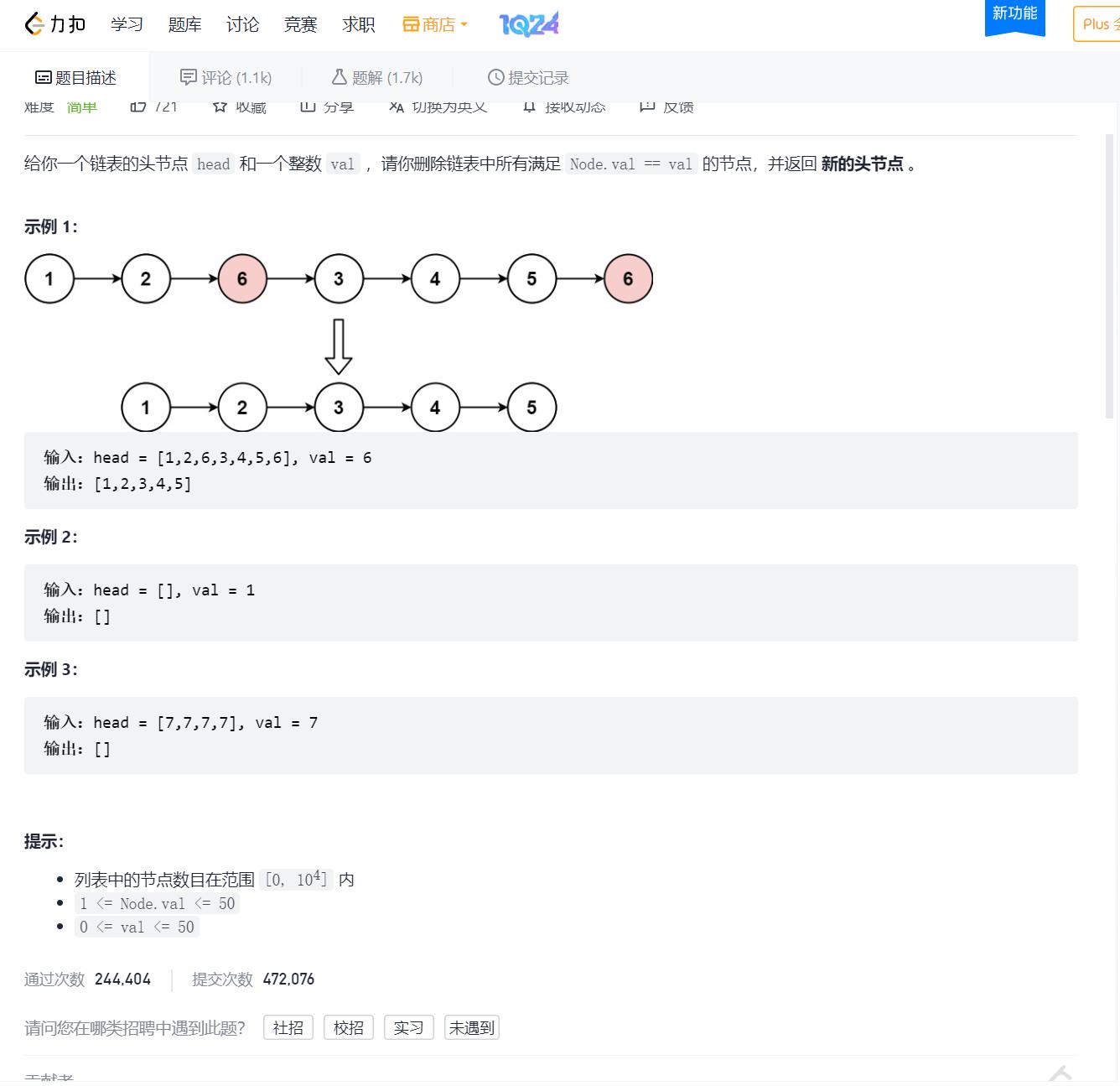
AC代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* prev = NULL, *cur = head;
while(cur)
{
if(cur->val == val)
{
//1.头删
//2.中间删除
if(cur == head)
{
head = cur->next;
free(cur);
cur = head;
}
else
{
prev->next = cur->next;
free(cur);
cur = prev->next;
}
}
else
{
//迭代往后走
prev = cur;
cur = cur->next;
}
}
return head;
}2.反转一个单链表
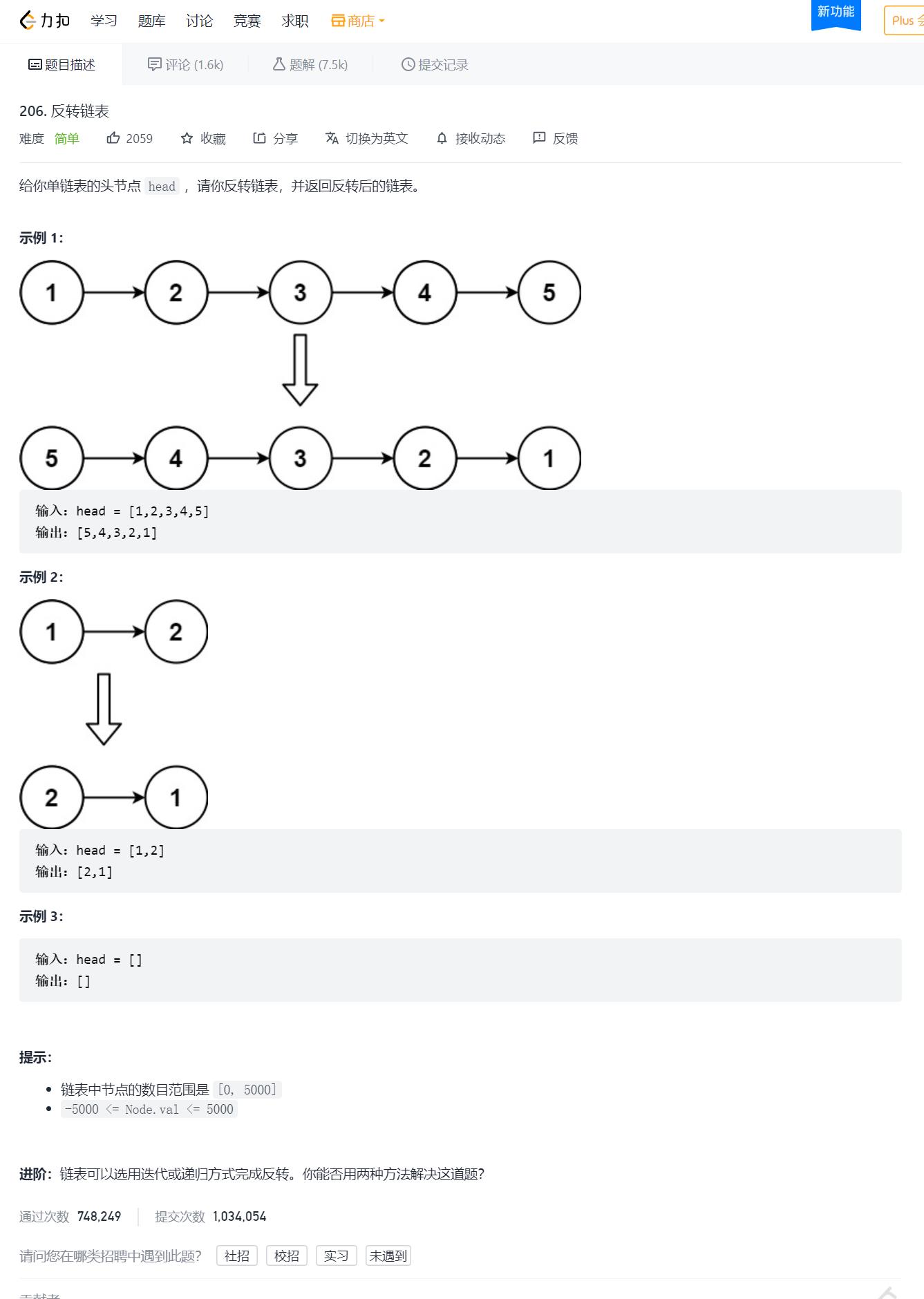
AC代码
思路1:
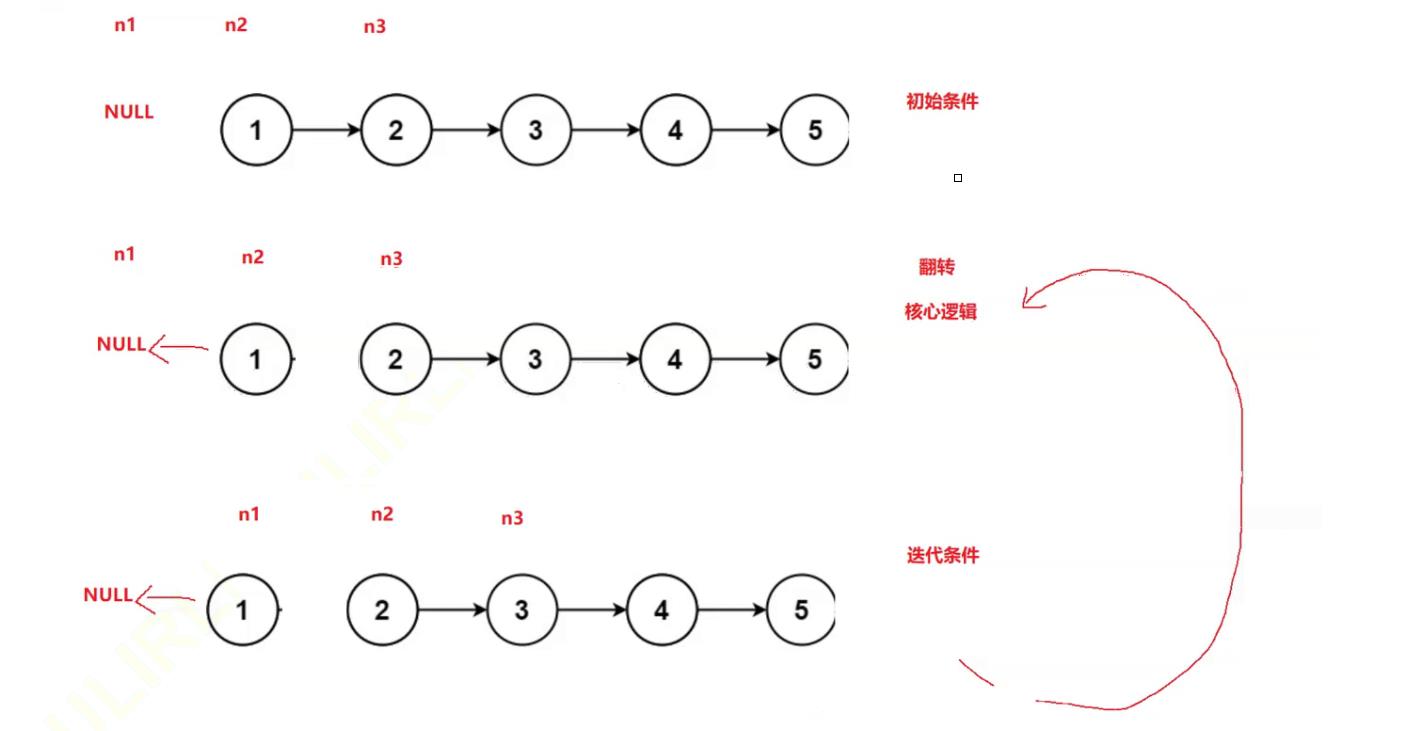
struct ListNode* reverseList(struct ListNode* head){
if(head == NULL)
return NULL;
struct ListNode* n1, *n2, *n3;
n1 = NULL;
n2 = head;
n3 = head->next;
while(n2)
{
//翻转
n2->next = n1;
//迭代往后走
n1 = n2;
n2 = n3;
if(n3 != NULL)
{
n3 = n3->next;
}
}
return n1;
}思路2:头插法
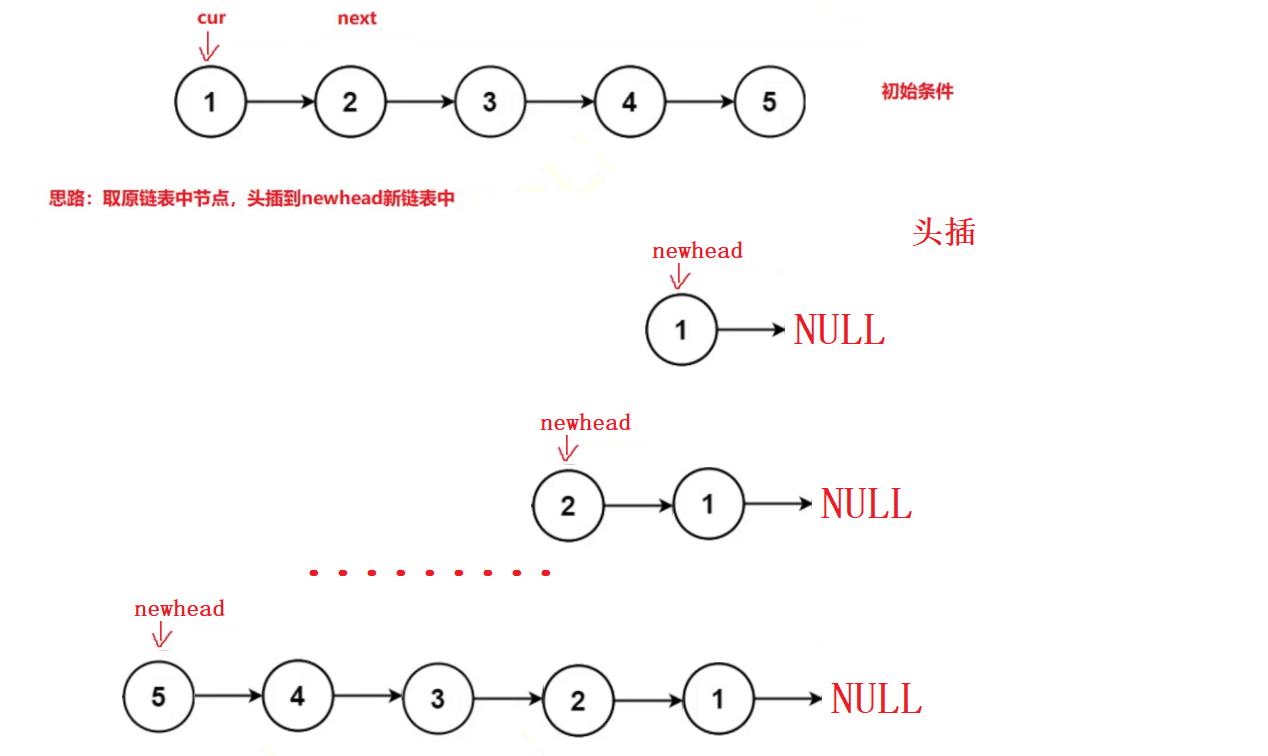
//思路2:头插
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* cur = head;
struct ListNode* newhead = NULL;
while(cur)
{
struct ListNode* next = cur->next;
//头插
cur->next = newhead;
newhead = cur;
//迭代往后走
cur = next;
}
return newhead;
}3.给定一个带有头结点 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
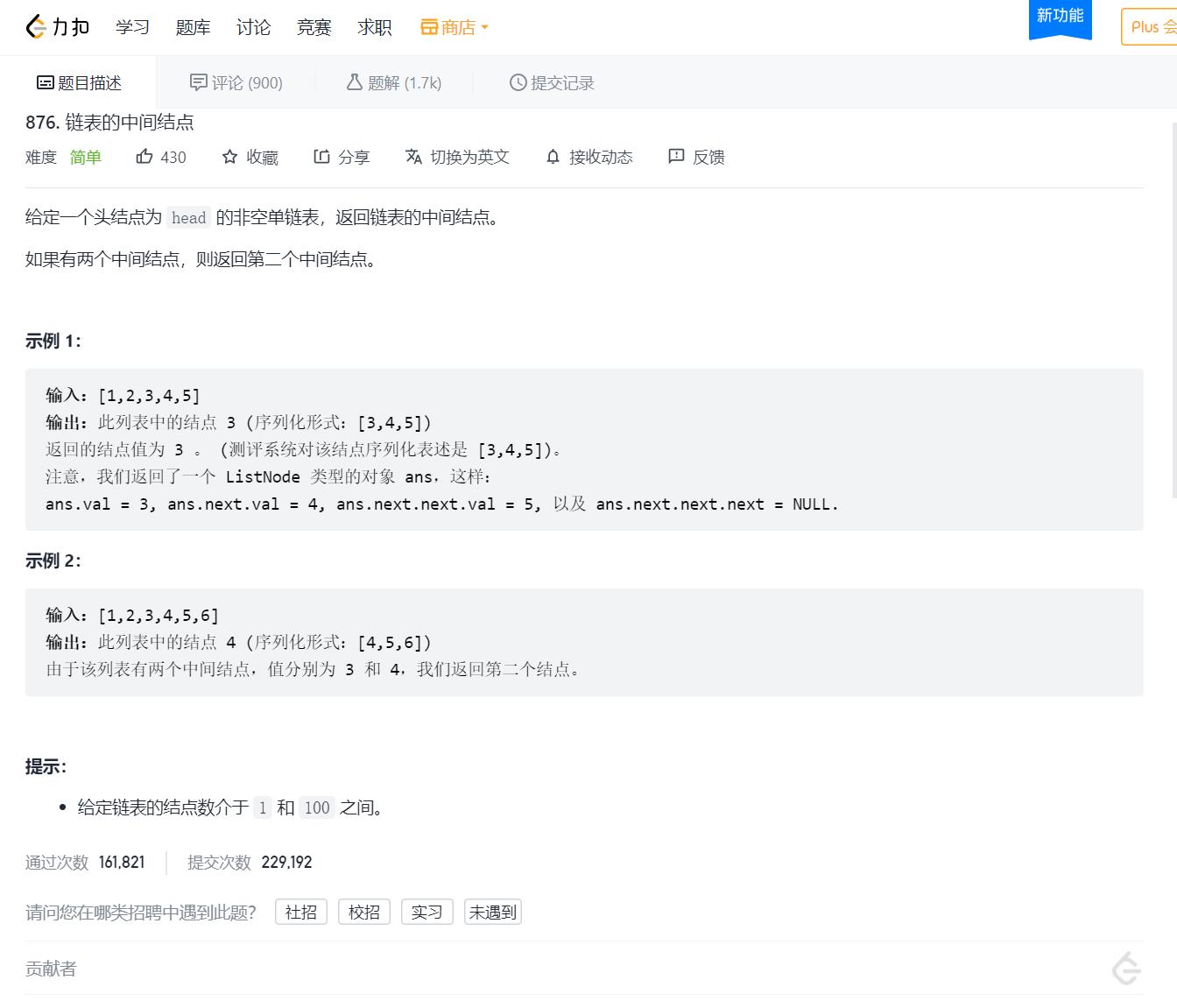
思路:
其实有很简单也很low的思路,就是遍历这个链表两次【 时间复杂度是O(N) 】,即:
————第一次遍历链表,去查看这个链表的长度。
————第二次遍历链表,去查看这个链表的中间结点,所以时间复杂度是F(n) = n + n/2 = 1.5n,即:O(N)
优化的算法思路:
仅仅需要遍历一次即可!!!
——————快慢指针!
慢指针走一步,快指针走两步,则对于链表长度(奇数/偶数)分成两种情况:
- 奇数链表,fast指到最后一个节点
- 偶数链表,fast指到NULL
动态演示:
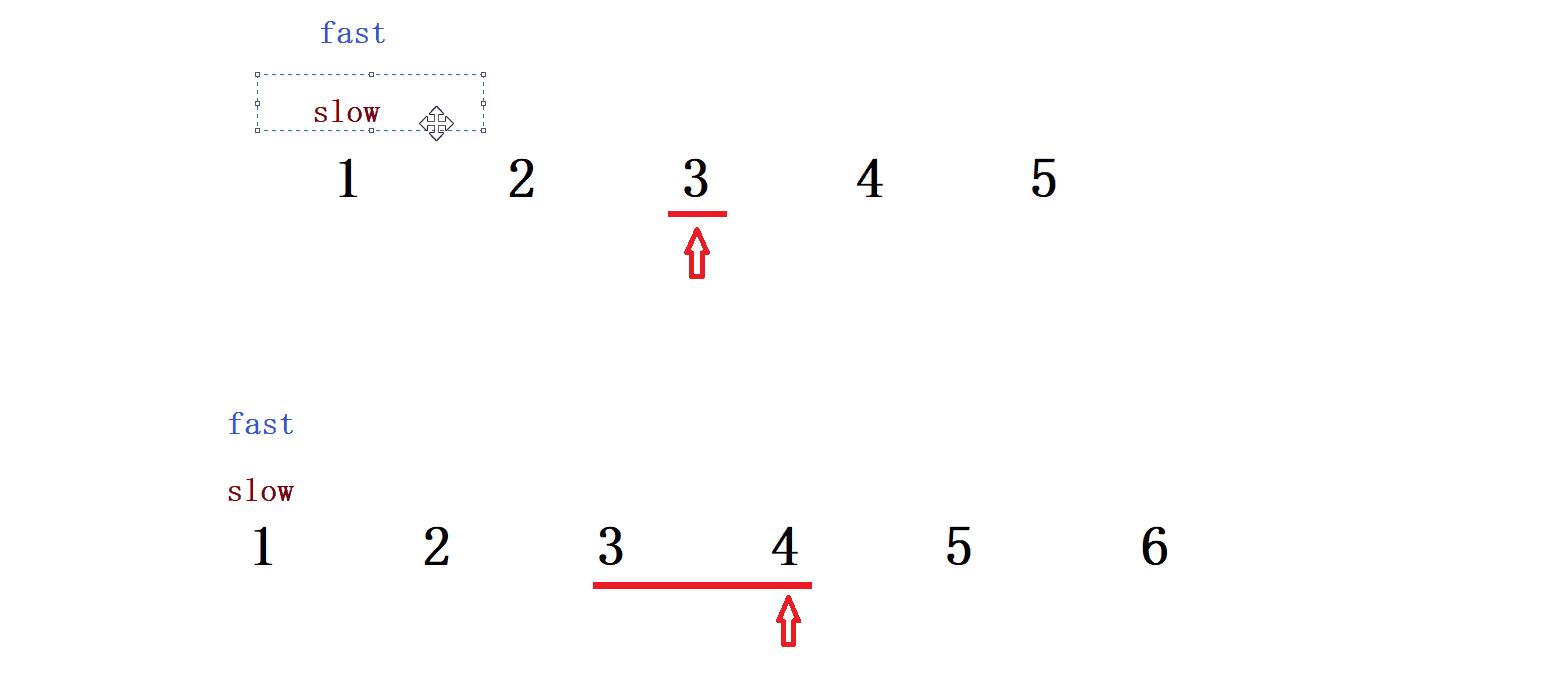
AC代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
//双指针解法:
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* fast, *slow;
fast = slow = head;
while(fast && fast->next)
{
//慢指针1次走1步
//快指针1次走2步
slow = slow->next;
fast = fast->next->next;
}
return slow;
}4.输入一个链表,输出该链表中倒数第k个结点
奇妙思路1~:
快慢指针,保持fast和slow之间有k个距离。

考虑不周全代码:
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
struct ListNode*slow, *fast;
slow = fast = pListHead;
while(k--)
{
fast = fast->next;
}
while(fast)
{
slow = slow->next;
fast = fast->next;
}
return slow;
}——————想想是否是错误的代码??
比如:测试用例6,{1,2,3,4,5}
——————链表长度一共才5个,那么想要找到倒数第6个结点,是肯定没有的,返回NULL即可。
——————————所以,fast往后移动k位的时候,需要判断fast是否==NULL,如果==NULL说明k大于链表长度!!(悟~)
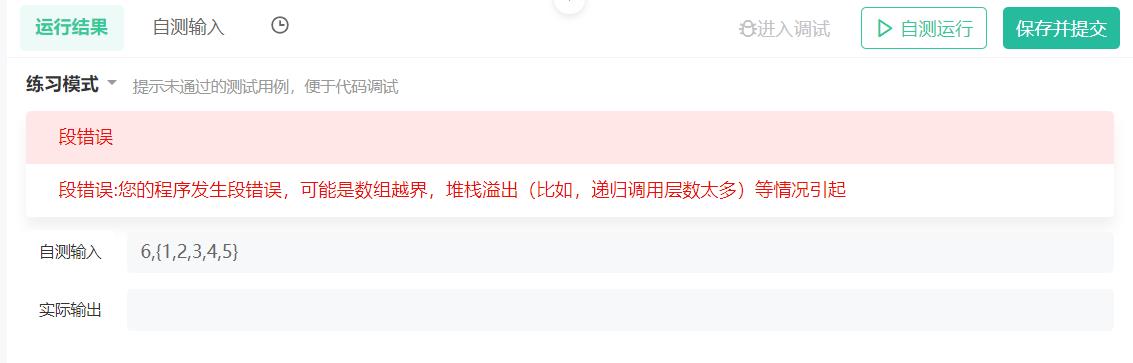
完善代码:
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
struct ListNode*slow, *fast;
slow = fast = pListHead;
while(k--)
{
// k大于链表长度
if(fast == NULL)
{
return NULL;
}
fast = fast->next;
}
while(fast)
{
slow = slow->next;
fast = fast->next;
}
return slow;
}奇妙思路2~:
计数器
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k) {
// write code here
int count = 0;
struct ListNode* cur = pListHead;
while (cur)
{
count++;
cur = cur->next;
}
cur = pListHead;
while (cur)
{
if (count == k)
return cur;
else if (count < k)
return NULL;
count--;
cur = cur->next;
}
return 0;
}5.将两个有序链表合并为一个新的有序链表并返回。(新链表是通过拼接给定的两个链表的所有节点组成的)

思路:

不完善代码未AC代码:
——————没有考虑到特殊情况:
————链表其中一个是NULL的时候,tail->next是野指针。所以需要先判断l1 、l2是不是其中有一个是NULL!!
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
//1.尾插
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
struct ListNode* head = NULL , *tail = NULL;
while(l1 && l2)
{
if(l1->val < l2->val)
{
//头节点
if(head == NULL)
{
head = tail = l1;
}
else
{
tail->next = l1;
tail = tail->next;
}
l1 = l1->next;
}
else
{
//头节点
if(head == NULL)
{
head = tail = l2;
}
else
{
tail->next = l2;
tail = tail->next;
}
l2 = l2->next;
}
}
if(l1)
{
tail->next = l1;
}
else if(l2)
{
tail->next = l2;
}
return head;
}改善代码的AC代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
//1.尾插
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
//如果一个链表为NULL,直接返回另一个链表
if(l1 == NULL)
{
return l2;
}
if(l2 == NULL)
{
return l1;
}
struct ListNode* head = NULL , *tail = NULL;
while(l1 && l2)
{
if(l1->val < l2->val)
{
//头节点
if(head == NULL)
{
head = tail = l1;
}
else
{
tail->next = l1;
tail = tail->next;
}
l1 = l1->next;
}
else
{
//头节点
if(head == NULL)
{
head = tail = l2;
}
else
{
tail->next = l2;
tail = tail->next;
}
l2 = l2->next;
}
}
if(l1)
{
tail->next = l1;
}
else if(l2)
{
tail->next = l2;
}
return head;
}完善精简的AC代码:
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
struct ListNode* head = NULL , *tail = NULL;
//如果一个链表为NULL,直接返回另一个链表
if(l1 == NULL)
{
return l2;
}
if(l2 == NULL)
{
return l1;
}
//先取一个小的做第一个结点
if(l1->val < l2->val)
{
head = tail = l1;
l1 = l1->next;
}
else
{
head = tail = l2;
l2 = l2->next;
}
//链接
while(l1 && l2)
{
if(l1->val < l2->val)
{
tail->next = l1;
tail = tail->next;
l1 = l1->next;
}
else
{
tail->next = l2;
tail = tail->next;
l2 = l2->next;
}
}
if(l1)
{
tail->next = l1;
}
else if(l2)
{
tail->next = l2;
}
return head;
}但是我们发现,取一个小的作起始结点判断很麻烦(重复冗长),所以我们可以采用带哨兵位的头节点的方式来省去判断起始结点。
————注意,malloc以后的结点,最好要free掉,不free虽然能编译运行成功,但是又内存泄漏的风险。所以,在free(head)之前需要记录一下head的值再free(head)。
再完善的终极代码:
//1.尾插
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
//如果一个链表为NULL,直接返回另一个链表
if(l1 == NULL)
{
return l2;
}
if(l2 == NULL)
{
return l1;
}
// //先取一个小的做第一个结点
// if(l1->val < l2->val)
// {
// head = tail = l1;
// l1 = l1->next;
// }
// else
// {
// head = tail = l2;
// l2 = l2->next;
// }
struct ListNode* head = NULL , *tail = NULL;
//带哨兵位
head = tail = (struct ListNode*)malloc(sizeof(struct ListNode));
//链接
while(l1 && l2)
{
if(l1->val < l2->val)
{
tail->next = l1;
tail = tail->next;
l1 = l1->next;
}
else
{
tail->next = l2;
tail = tail->next;
l2 = l2->next;
}
}
if(l1)
{
tail->next = l1;
}
else if(l2)
{
tail->next = l2;
}
struct ListNode* list = head->next;
free(head);
return list;
}以上是关于链表面试题,彻底巩固你的数据结构链表知识~的主要内容,如果未能解决你的问题,请参考以下文章