使用Spring Cloud Sleuth实现微服务跟踪
Posted shi_zi_183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Spring Cloud Sleuth实现微服务跟踪相关的知识,希望对你有一定的参考价值。
使用Spring Cloud Sleuth实现微服务跟踪
之前已经了解了几种监控微服务的方式,例如使用Spring Boot Actuator监控微服务示例,使用Hystrix监控Hystrix Command等。
为什么要实现微服务追踪
Peter Deutsch的分布式计算的八大误区。
- 网络可靠
- 延迟为零
- 带宽无限
- 网络绝对安全
- 网络拓扑不会改变
- 必须有一名管理员
- 传输成本为零
- 网络同质化
从中可以看到,该文章很多点都在描述一个问题——网络问题。网络常常很脆弱,同时网络资源也是有限的。
我们知道,微服务之间通过网络进行通信。如果能够跟踪每个请求,了解请求经过哪些微服务、请求耗费时间、网络延迟、业务逻辑耗费时间等指标,那么就能更好地分析系统瓶颈、解决系统问题。因此,微服务跟踪很有必要。
Spring Cloud Sleuth简介
Spring Cloud Sleuth为Spring Cloud提供了分布式跟踪的解决方式,它大量借用了Google Dapper、Twitter Zipkin和Apache HTrace的设计。
先来了解一下Sleuth的术语,Sleuth借用了Dapper的术语。
- span(跨度):基本工作单位。span用一个64位的ID唯一标识。除ID外、span还包含其他数据,例如描述、时间戳事件、键值对的注解(标签),spanID、span父ID等。
span被启动和停止时,记录了时间信息。初始化span被称为"root span",该span的ID和trace的ID相等。 - trace(跟踪):一组共享"root span"的span组成的树状结构称为trace。trace也用一个64位的ID唯一标识,trace中的所有span都共享该trace的ID。
- annotation(标注):annotation用来记录事件的存在,其中,核心annotation用来定义请求的开始和结束。
1)CS(Client Sent客户端发送):客户端发起一个请求,该annotation描述了span的开始。
2)SR(Server Received服务器端接收):服务器端获得请求并准备处理它。如果用SR减去CS时间戳,就能得到网络延迟。
3)SS(Server Sent服务器端发送):该annotation表明完成请求处理(当响应发回客户端时)。如果用SS减去SR时间戳,就能得到服务器端处理请求所需的时间。
4)CR(Client Received客户端接收):span结束的标识。客户端成功接收到服务器端的响应。如果CR减去CS时间戳,就能得到从客户端发送请求到服务器响应的所需的时间。
整合Spring Cloud Sleuth
1)复制项目microservice-simple-provider-user,将ArtifactId修改为microservice-simple-provider-user-trace。
2)为项目添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
3)修改application.yml,添加以下内容
spring:
application:
name: microservice-provider-user
logging:
level:
root: INFO
org.springframework.web.servlet.DispatcherServlet: DEBUG
这样就整合好Sleuth了。同理,也可为项目microservice-simple-consumer-movie整合Sleuth,记为microservice-simple-consumer-movie-trace。
4)同理,也可为项目microservice-simple-consumer-movie整合Sleuth,记为microservice-simple-consumer-movie-trace。
测试
1)启动项目microservice-simple-provider-user-trace。
2)访问http://localhost:8000/1

其中,ceb98e825708846f是traceID,ceb98e825708846f等是spanID。
仔细分析日志,不难看出请求的具体过程,也可将日志如下设置
logging:
level:
org.springframework.cloud.sleuth: DEBUG

3)启动项目microserver-simple-consumer-movie-trace。
4)访问http://localhost:8010/user/1会发现两个项目都会打印类似以上的日志。


Spring Cloud Sleuth与Zipkin配合使用
Zipkin简介
Zipkin是Twitter开源的分布式跟踪系统,基于Dapper的论文设计而来。它的主要功能是收集系统的时序数据,从而追踪微服务架构的系统延时等问题。Zipkin还提供了一个非常友好的界面,来帮助分析追踪数据。
编写Zipkin Server
1)创建一个ArtifactId是microservice-trace-zipkin-server的Maven工程,并为先买个添加以下依赖
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
2)编写启动类,使用EnableZipkinServer注解,声明一个Zipkin Server。
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import zipkin.server.EnableZipkinServer;
@SpringBootApplication
@EnableZipkinServer
public class ZipkinServerApplication {
public static void main(String[] args){
SpringApplication.run(ZipkinServerApplication.class,args);
}
}
3)编写配置文件,在application.yml中添加
server:
port: 9411
测试
1)启动项目microservice-trace-zipkin-server
2)访问http://localhost:9411/
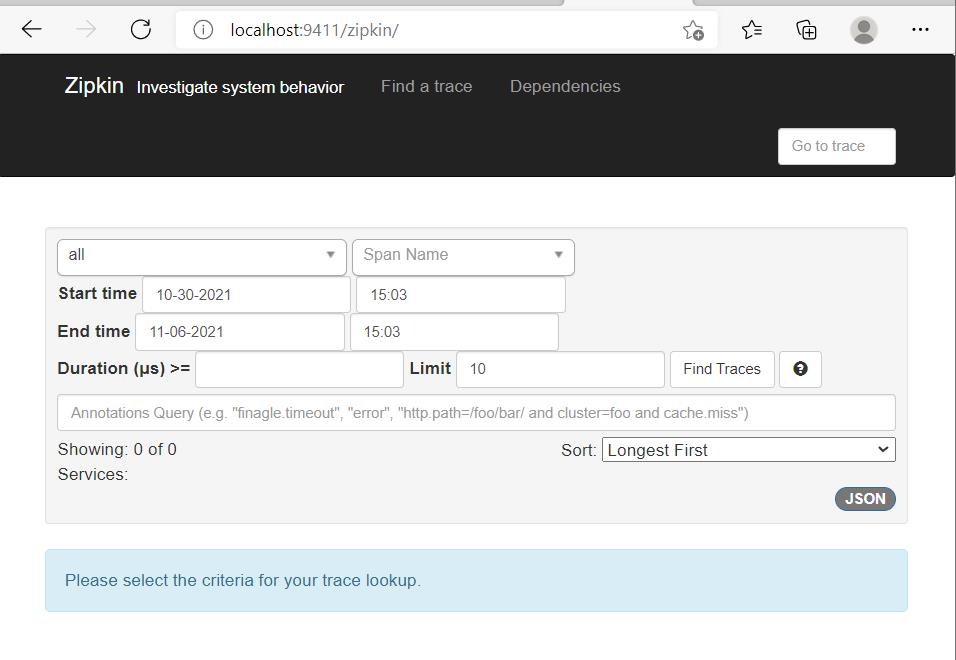
- Service Name表示服务名称,也就是各个微服务spring.application.name的值。
- 第二列表示span的名称,all表示所有span,也可选择指定span
- Start time、End time,分别用于指定起始时间和截止时间。
- Duration表示持续时间,即span从创建到关闭所经历的时间
- Limit表示查询几条数据。类似mysql数据库中的limit关键词。
- Annotation Query,用于自定义查询条件。
微服务整合Zipkin
1)复制项目microservice-simple-provider-user-trace,将ArtifactId修改为microservice-simple-provider-user-trace-zipkin。
2)为项目添加以下依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
3)在配置文件application.yml中添加如下内容
spring:
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
percentage: 1.0
其中:
- spring.zipkin.base-url:指定Zipkin的地址。
- spring.sleuth.sampler.percentage:指定需采样的请求的百分比,默认值是0.1,即10%。这是因为在分布式系统中,数据量可能会非常大,因此采样非常重要。
这样就为项目整合了Zipkin。同理,为项目microservice-simple-consumer-movie-trace整合Zipkin,记为microservice-simple-consumer-movie-trace-zipkin。
测试
1)启动项目microservice-trace-zipkin-server。
2)启动项目microservice-simple-provider-user-trace-zipkin
3)启动项目microservice-simple-consumer-movie-trace-zipkin
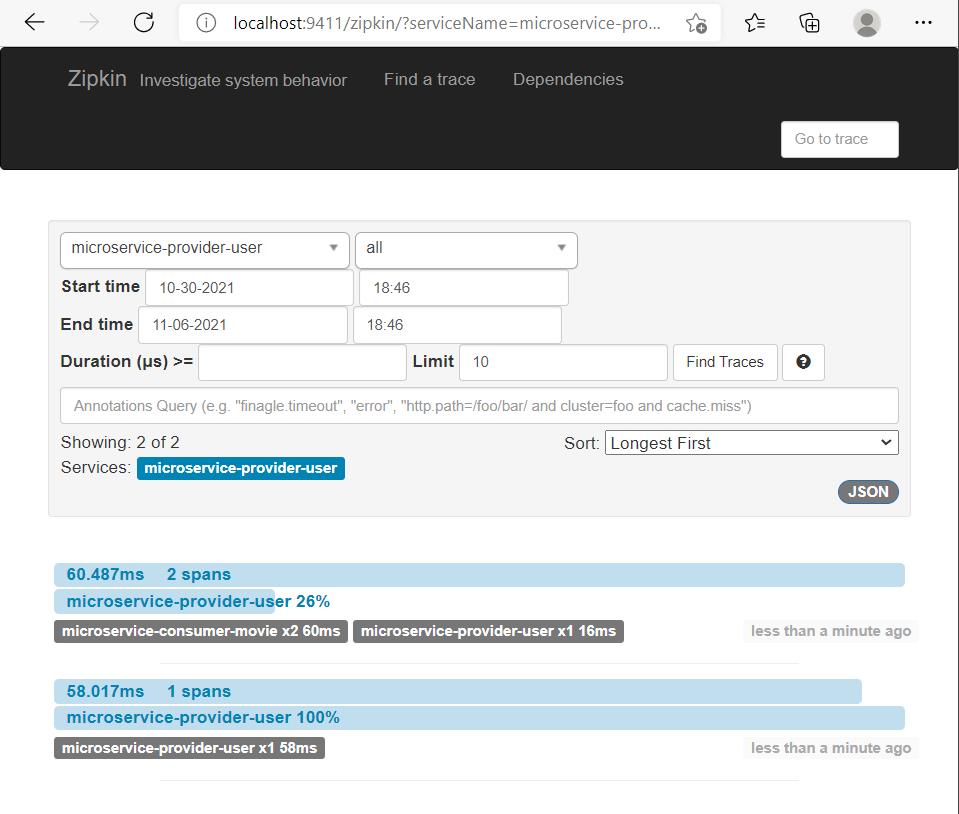
4)访问http://localhost:8010/user/1

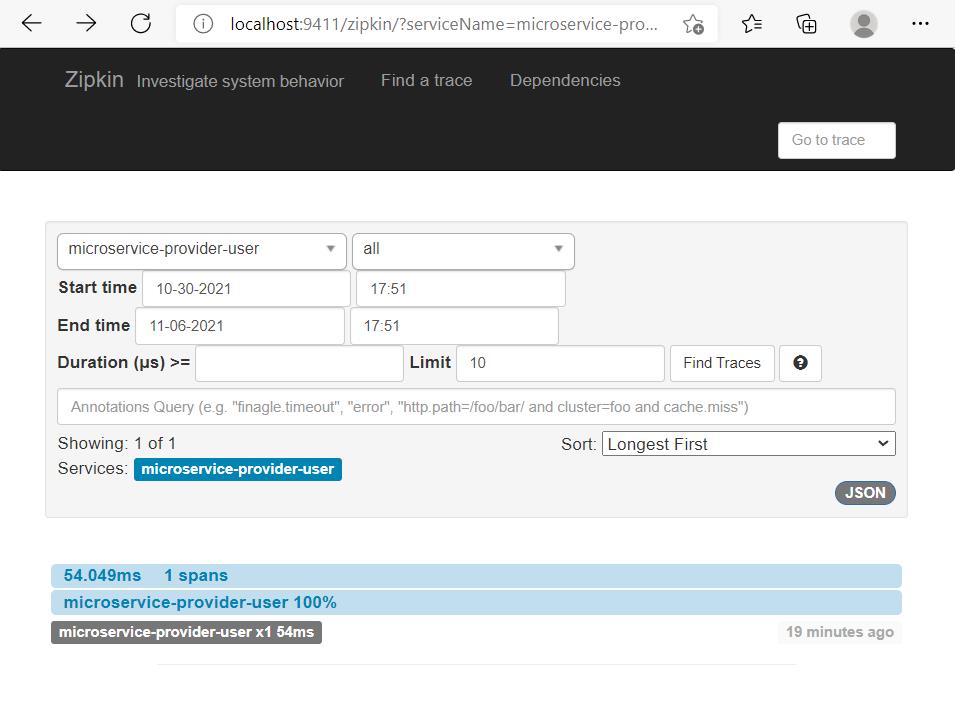
5)访问Zipkin Server首页http://localhost:9411/,填入起始时间、结束时间等筛选条件后,单击Find a trace按钮,可看到trace列表。
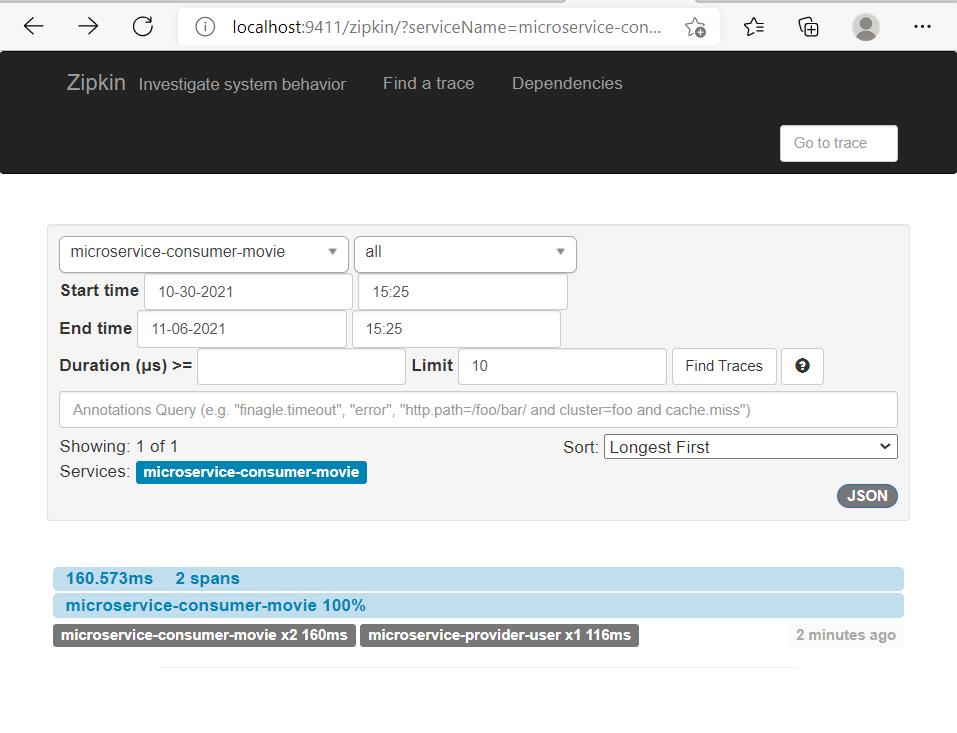
6)单击该trace
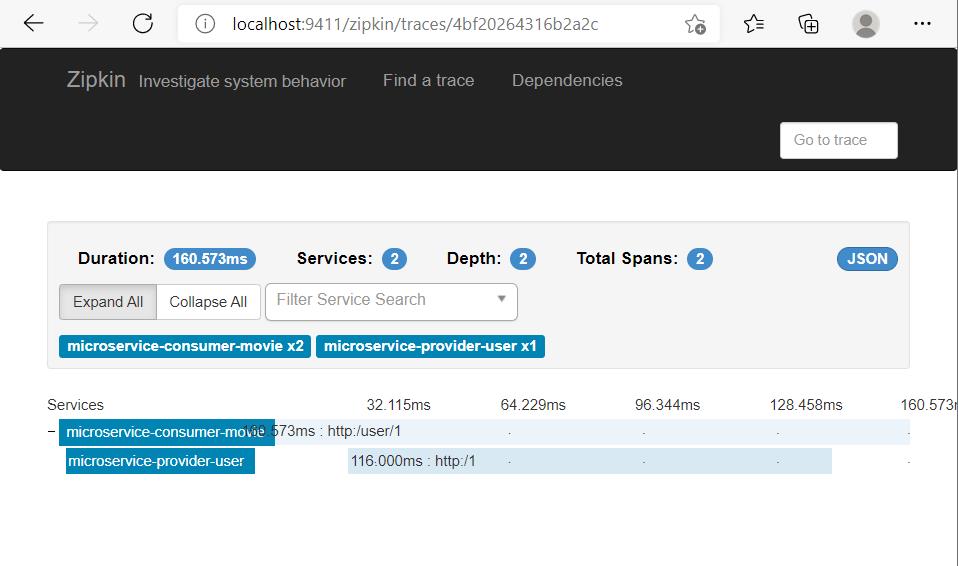
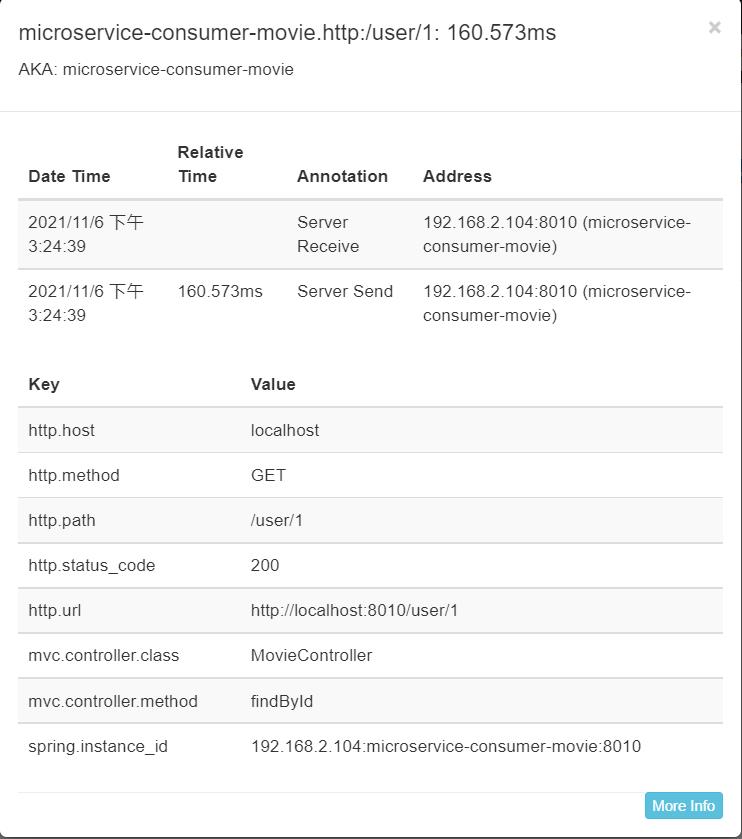
7)单击span,即可获得span的详情信息。
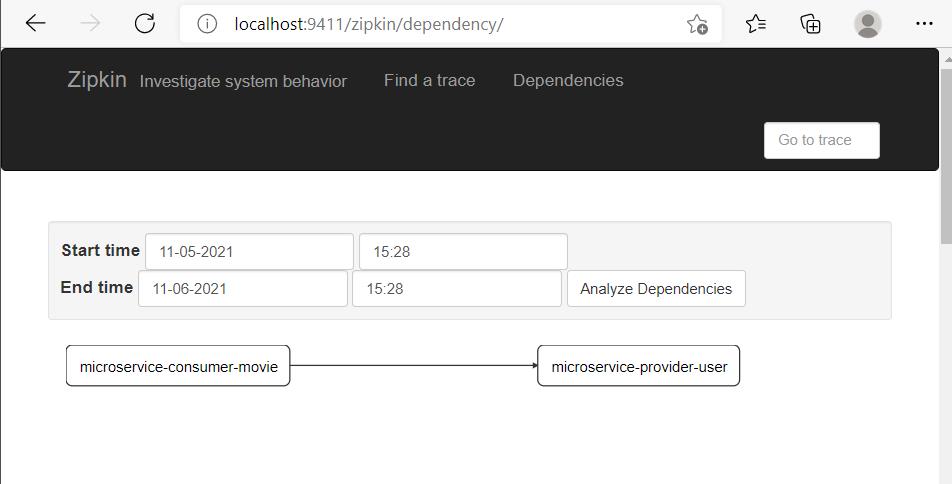
8)Zipkin还有助于分析微服务间的依赖关系。单击导航栏上的Dependencies按钮。
注:Sleuth支持多种采样器,例如AlwaysSampler、NeverSampler、PercentageBasedSampler等。
@Bean
public Sample defaultSampler(){
return new AlwaysSampler();
}
Sleuth默认采样百分比是10%,Sleuth会忽略大量span所导致的。因此,建议在开发、测试时,将属性spring.sleuth.sampler.percentage设大一点,例如1.0(100%)。
Zipkin与Eureka配合使用
改造Zipkin Server
对于Zipkin Server,只需将其注册到Eureka Server上即可。如何将服务注册到Eureka Server,这里略。
为Zipkin Server设置的服务名称为zipkin-server。
server:
port: 9411
spring:
application:
name: zipkin-server
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
instance:
prefer-ip-address: true
改造微服务
1)复制项目microservice-provider-user,将ArtifactId修改为microservice-provider-user-zipkin。
2)为项目添加以下依赖,从而整合Sleuth以及Zipkin
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
3)在配置文件application.yml中添加如下内容
spring:
zipkin:
base-url: http://zipkin-server
sleuth:
sampler:
percentage: 1.0
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
instance:
prefer-ip-address: true
测试
1)启动microservice-discovery-eureka
2)启动microservice-trace-zipkin-server-eureka
3)启动microservice-provider-user-zipkin
4)访问localhost:9411
使用消息中间件收集数据
前文是使用HTTP直接收集跟踪数据的,这里使用消息中间件收集追踪数据。
- 微服务与Zipkin Server解耦,微服务无须知道Zipkin Server的网络地址
- 在一些场景下,Zipkin Server与微服务网络可能不通,使用HTTP直接收集的方式无法工作,此时可借助消息中间件实现数据收集。
这里使用RabbitMQ作为消息中间件进行演示。
注:Spring Cloud Edgware之前的版本使用的是Zipkin 1.x,想要用MQ方式收集数据,需整合spring-cloud-sleuth-stream。而Edgware及更高版本使用Zipkin2.x,本身以支持基于MQ的数据收集方式,故而spring-cloud-sleuth-stream将被废弃。两种使用方式不兼容。
这里基于Edgware,故而讲解的是基于Zipkin2.x自身提供的、基于MQ的数据收集功能。
改造Zipkin Server
1)复制项目microservice-trace-zipkin-server,将ArtifactId修改为microservice-trace-zipkin-server-stream。
2)将pom.xml的依赖修改为
<dependencies>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmq</artifactId>
<version>2.3.1</version>
</dependency>
3)将配置文件application.yml修改为
server:
port: 9411
zipkin:
collector:
rabbitmq:
addresses: localhost:5672
password: guest
username: guest
queue: zipkin
这样,Zipkin Server就改造完成了。
改造微服务
1)复制项目microservice-simple-provider-user-trace-zipkin,将ArtifactId修改为microservice-simple-provider-user-trace-zipkin-stream。
2)修改pom.xml,删除Sleuth及Zipkin相关依赖,并添加以下依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
3)修改配置文件application.yml,删除其中的
spring:
zipkin:
base-url: http://localhost:9411
添加内容
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
zipkin:
rabbitmq:
queue: zipkin
同理改造电影微服务。
测试
同之前测试
使用Elasticsearch存储跟踪数据
在前文的示例中,Zipkin Server是将数据存储在内存中的。这种方式一般不适用于生产环境,因为一旦Zipkin Server重启或发生崩溃,就会导致历史数据的丢失。
Zipkin Server支持多种后端存储,例如MySQL、Elasticsearch、Cassndra等。
用项目microservice-trace-zipkin-server-stream进行改造,让其使用RabbitMQ收集跟踪数据并使用Elasticsearch6.1.1作为后端存储。
1)复制项目microservice-trace-zipkin-server-stream,将ArtifactId修改为microservice-trace-zipkin-server-stream-elasticsearch。
2)为项目添加依赖
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
<version>2.3.1</version>
</dependency>
3)修改配置文件application.yml
zipkin:
storage:
type: elasticsearch
elasticsearch:
cluster: elasticsearch
hosts: http://localhost:9200
index: zipkin
index-shards: 5
index-replicas: 1
测试
1)启动Elasticsearch
2)启动项目microservice-trace-zipkin-server-stream-elasticsearch
3)启动项目microservice-simple-provider-user-trace-zipkin-stream。
4)启动项目microservice-simple-consumer-movie-trace-zipkin-stream
5)按照前文讲解的方式测试,可获得预期结果。
6)访问Zipkin首页,可正常显示跟踪数据。
7)访问http://localhost:9200/_search。
8)重启Zipkin Server,在Zipkin Server首页输入条件查询,仍可查询到历史数据,说明可以正常从Elasticsearch中读取数据。
以上是关于使用Spring Cloud Sleuth实现微服务跟踪的主要内容,如果未能解决你的问题,请参考以下文章
spring-cloud-sleuth-zipkin实现微服务的链路跟踪