Enterprise:Web Crawler 基础
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Enterprise:Web Crawler 基础 相关的知识,希望对你有一定的参考价值。
在 Elastic Enterprise Search 7.11 中,Elastic 宣布推出 Elastic App Search 网络爬虫,这是一种简单而强大的方式来提取公开可用的网络内容,以便在你的网站上立即搜索。
使网站上的内容可搜索可以采用多种形式。 Elastic App Search 已经允许用户通过 JSON 上传、JSON 粘贴和 API 端点摄取内容。 网络爬虫的引入为用户提供了另一种方便的内容摄取方法。
在今天的文章中,我将使用 Elastic 提供的 App Search 网路爬虫来迅速地实现对网站内容的搜索及统计。在整个实践中,我将使用 Elastic Cloud 来做演示。当然你也可以在自己的电脑上进行部署。请参阅我之前的文章 “Enterprise:Elastic App Search - Web 爬虫器实践”。
创建一个 Enterprise Search 部署
在这个章节里,我们将使用 Elastic Cloud 来创建一个 Enterprise Search 的部署。我们按照如如下步骤来进行:
1)进入 …https://cloud.elastic.co 网址。点击 Sign up:
2)输入你的办公电子邮件地址及密码:
3)点击上面的 “Start your free trial”,你应该在收件箱中找到一封包含验证链接的电子邮件。
选择(安全!)密码后,你将被定向到登录页面:
4)点击上面的 Create deployment:
在上面我选择离我们较近的 Hong Kong 及 AWS Web Services。我们可以为自己的部署取名。我们取一个叫做 enterprise-search-crawler 的部署。在上面,我们可以看到每个小时需要花费多少钱。请注意:在此期间,你并没有要求提供你的信用卡支付信息,所以你不比担心在试用期间你需要付任何的费用。我们可以点击 Advanced settings 来查看当前的配置。如果你不满意,你可以进行调整。
5)点击上面的 Create deployment。你需要等一小会的时间,就可以发现如下的画面:
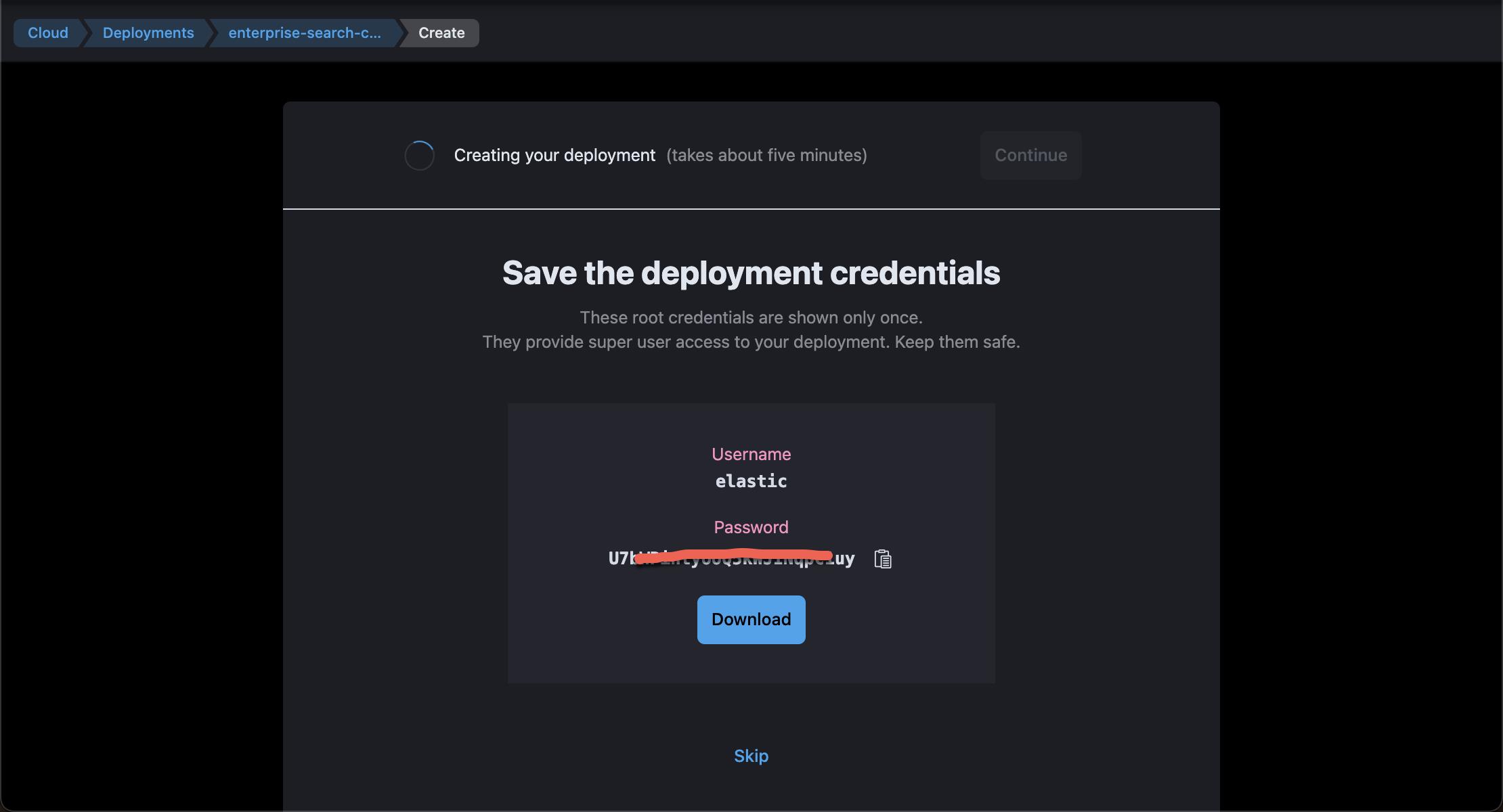
点击上面的 Download,这样就可以保存我们的密码到一个 .csv 文件中。这个密码在以后的数据导入及登录中需要用到,所以你需要妥善保存。
上面显示我们需要大约 5 分钟的时间就可以把集群准备好。是不是非常方便啊?
点击上面的 Continue:
这样就进入到我们的 Kibana 中了。是不是感觉到无缝连接到我们最常用的 Kibana 了?
在我们今天的练习中,我们将不使用 Kibana。我们将使用 Enterprise Search。
我们再次在浏览器中打开链接 https://cloud.elastic.co:
在上面,我们看到已经被创建的 enterprise-search-crawler 部署。点击上面的链接:
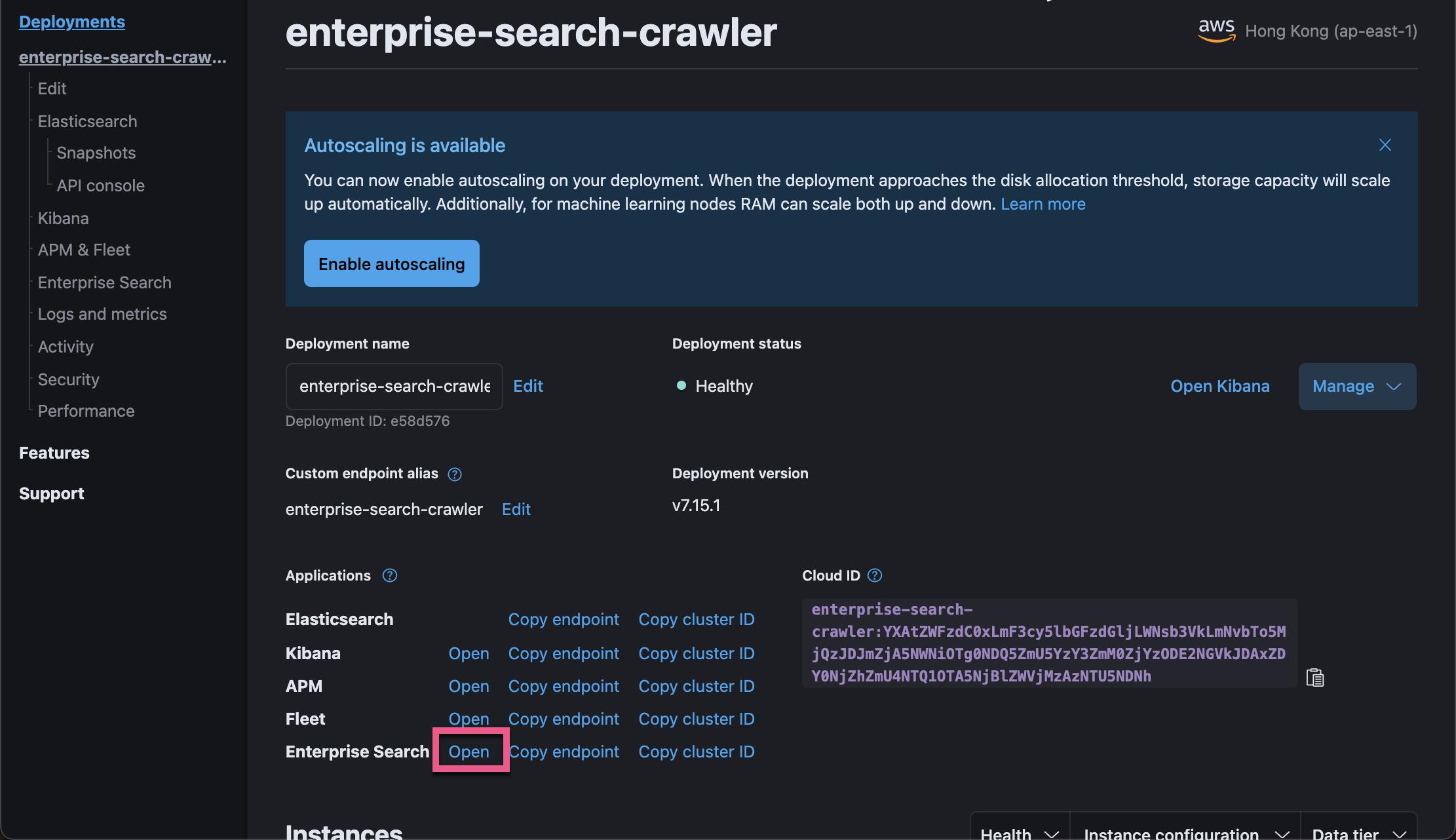
在上面,我们可以看到 Elasticsearch,Kibana,APM,Fleet 及 Enterprise Search 的应用。在这里我们也可以打开 Kibana。Kibana 将在后面可视化 Web Crawler 日志用到。
点击上面位于 Enterprise Search 下的 Open 链接:
这样我们就进入到 Elastic Enterprise Search 界面了。
到目前为止我们已经很快地创建了一个 Elastic Enterprise Search 的部署。步骤非常地简单,直接。只需要几分钟的时间。你不需要提供任何的支付信息。
使用 Web Crawler 添加数据
在这个章节里,我们将创建一个 Elastic App Search Engine,并使用 Web Crawler 来把数据摄入。我们将使用的网址是 elastic.co。在这个网址上,我们可以找到 https://www.elastic.co/blog/。这个其实就是我们的官方博客地址。
创建 engine
点击上面图中的 Launch App Search:
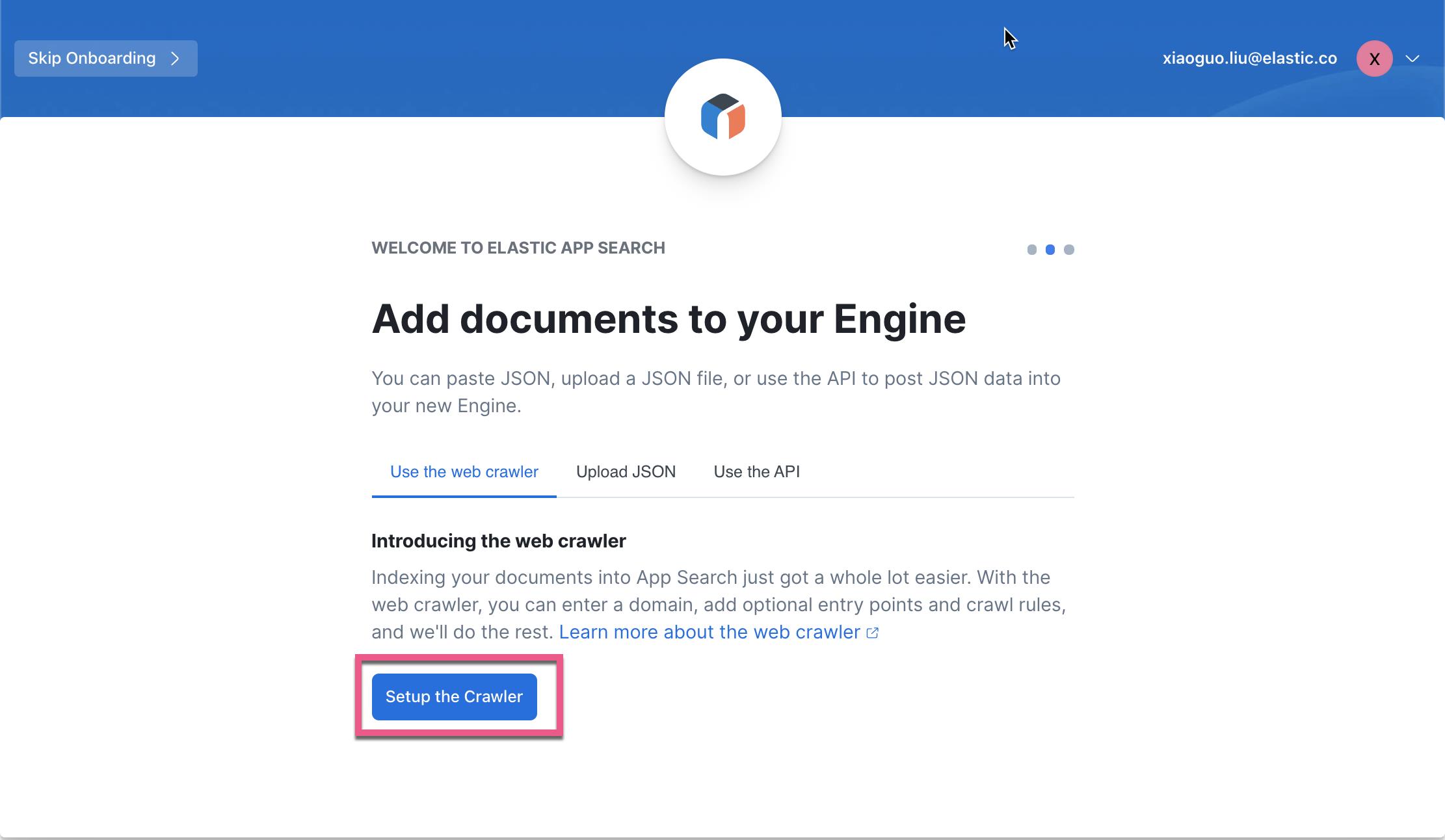
Web crawler 针对网页来说是一种非常快的数据摄入方式。它也是被推荐的方式。当然我们也可以使用 Upload JSON 及使用 API 的方式来进行数据的摄入。
点击上面的 Setup the Crawler:
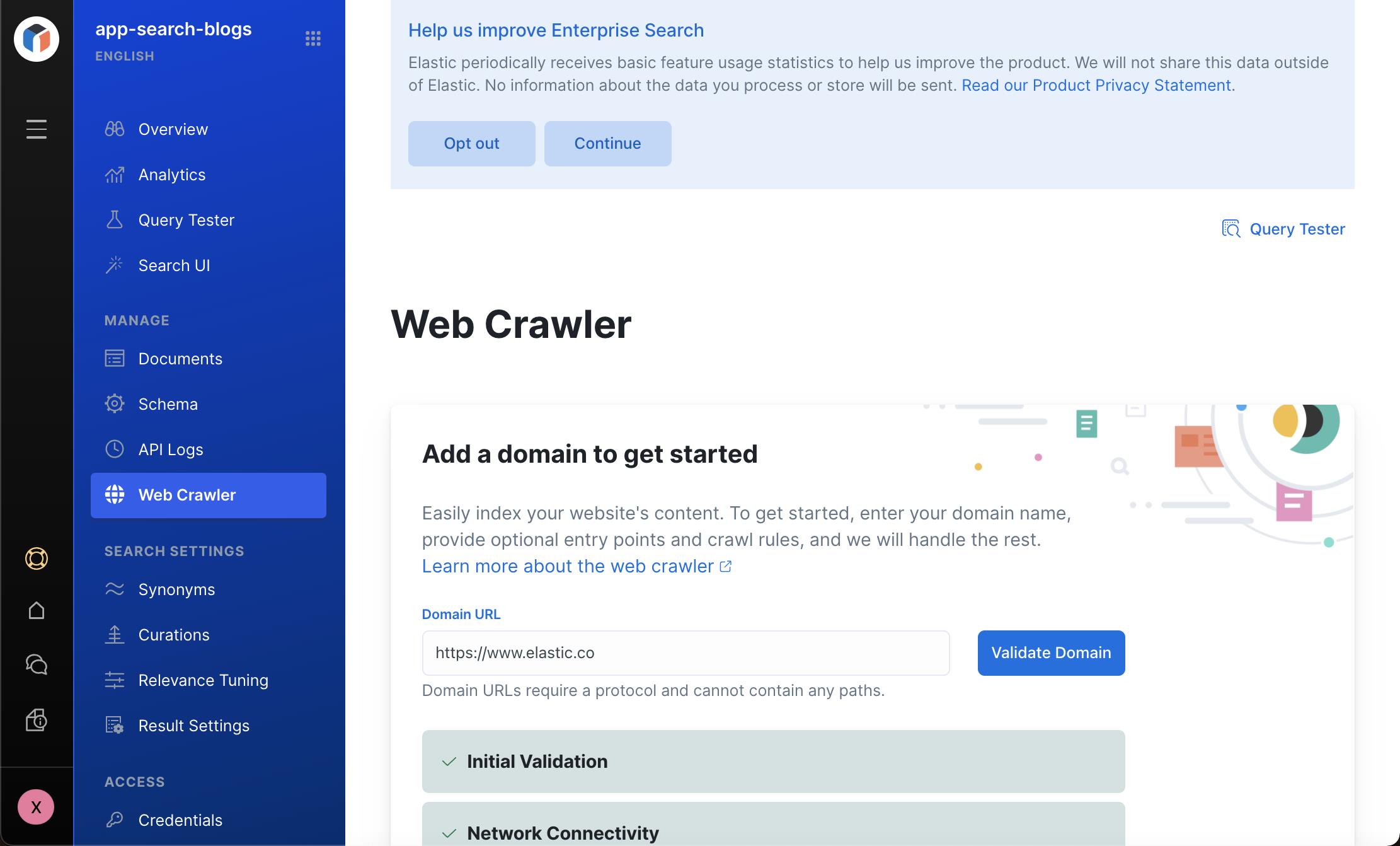
首先,我们需要填入的是 domain。我们需要爬虫的网站是位于 https://www.elastic.co 网站上的,所以在上面我填入 https://www.elastic.co。我们也可以点击 Validate Domain 来检查网络的连接性。
接下来,我们需要定义 entry points。这些 entry points 是 web crawler 最开始需要 crawl 的入口地址。Web crawler 将递归地爬虫在这些入口地址一下的页面:
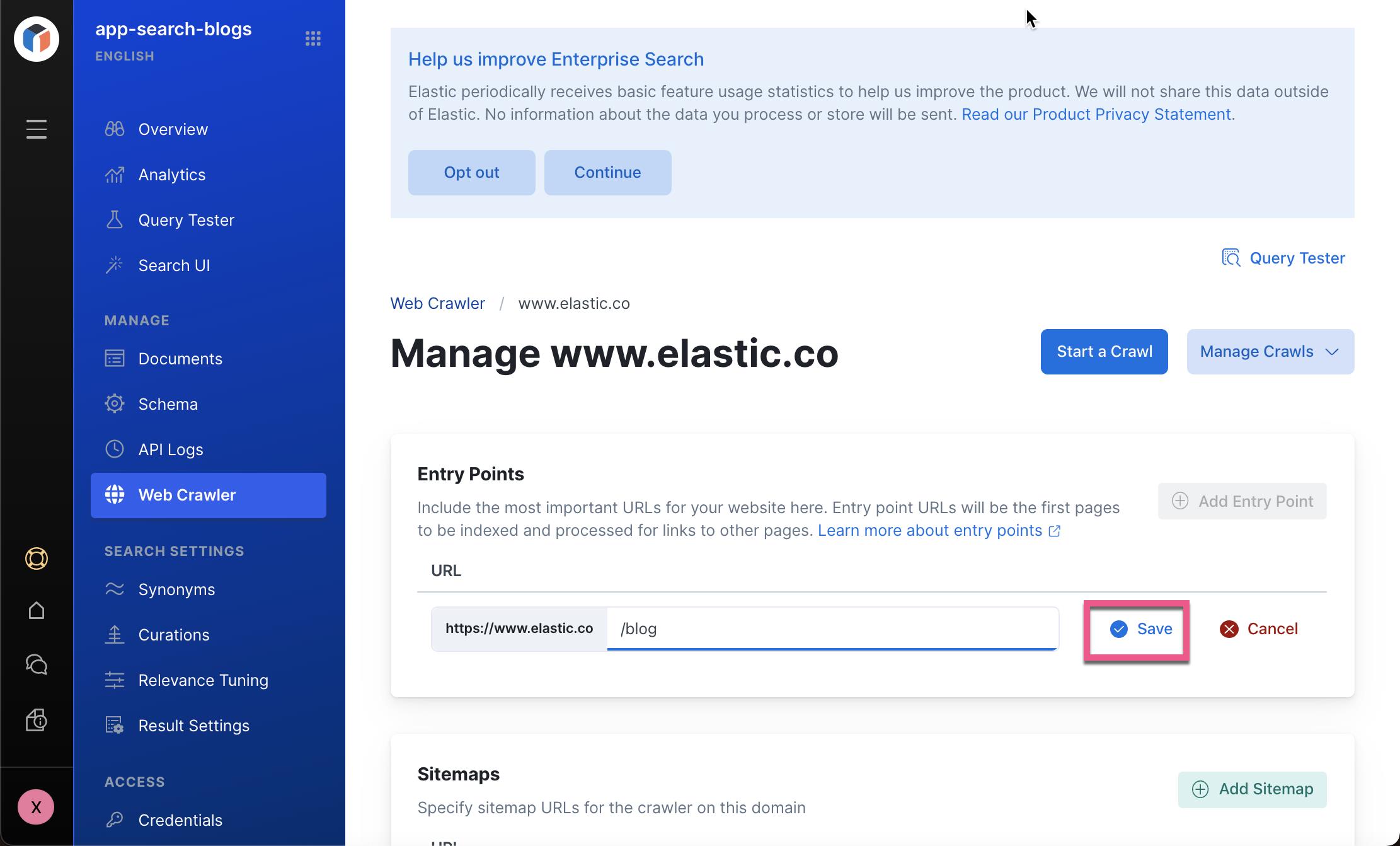
针对我们的应用场景,我们定义唯一的一个入口地址 https://www.elastic.co/blog/。 点击上面的 Save 按钮:
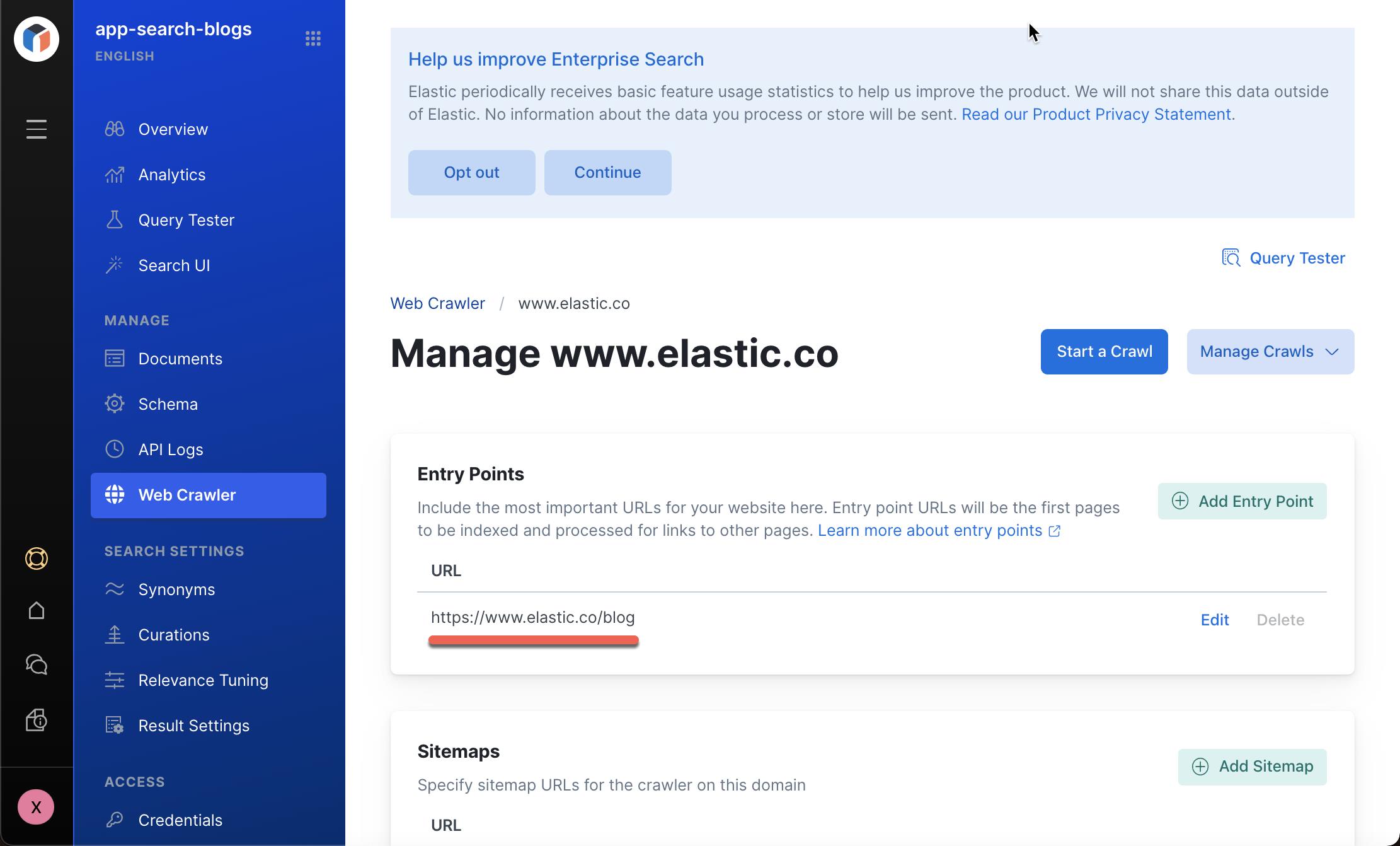
接下来,我们将定义一些 rules 来规范 crawler 如何爬虫我们的网页。
在上面的页面中,我们向下滚动。我们定义如下的一些 rules:
a)禁止所有页面的规则。
b)忽略 author 页面的规则(从 /blog/author/ 开始)
c)忽略 category 页面的规则(从/blog/category/ 开始)
d)允许路径中包含词条 /blog/ 的页面的规则。
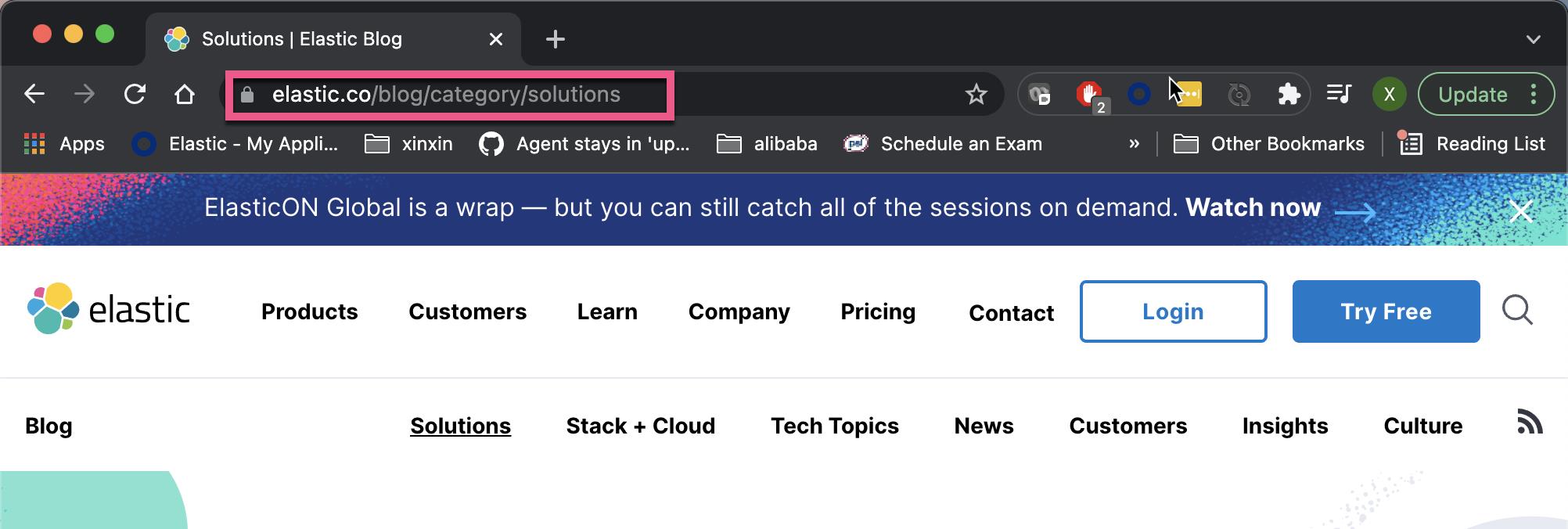
在 elastic.co 的页面中,我们可以看到如下的页面:
以及:
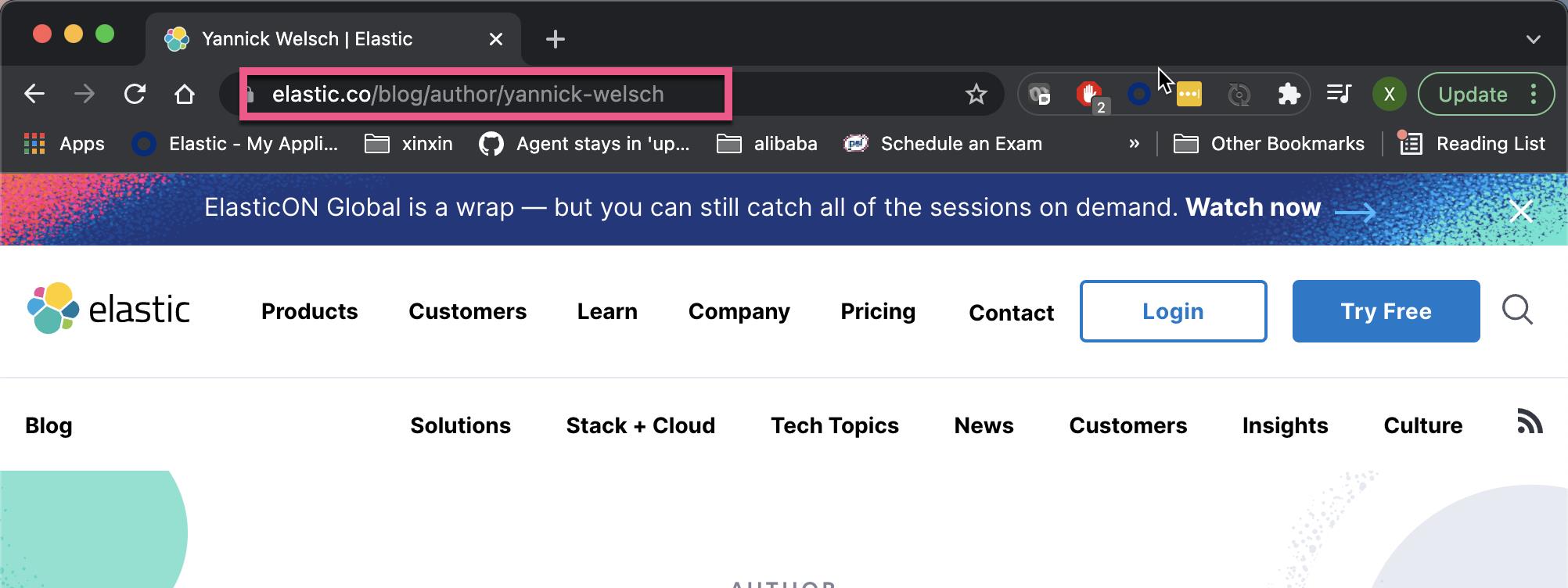
我们对上面的路径里以 /blog/author/ 及 /blog/category/ 起始的路径不感兴趣。
另外,我们使用 regex 正则表达式 .* 来禁止所有的页面。
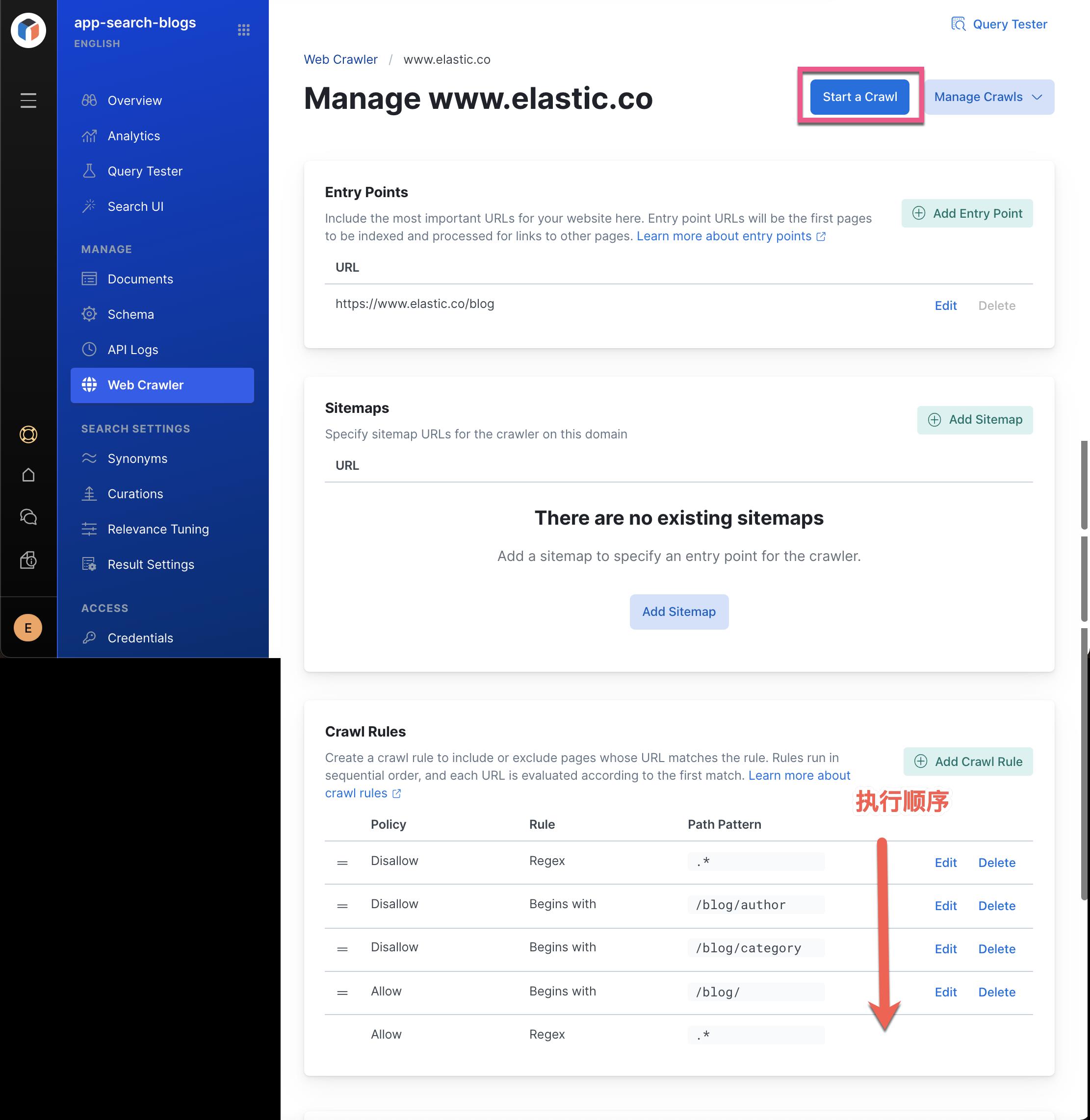
必须明确的是:所有的规则时从上而下进行执行的。也就是是说从上面的第一个规则执行,直到最下面。我们可以点击上面的 Start a Crawl 按钮。我们会立即注意到,按钮上的旋转圈立马就消失了,也就是说我们几乎没有爬虫任何的网页。这是可以理解的,因为我们的第一个规则就是禁止所有的页面。这在 Documents 中也可以看出来:
显然上面的情况,我们很容易分析处理。但是在实际的使用中,我们可能需要一定的调试技巧才能找出这个问题的所在。
在 Kibana 中可视化 Web Crawler 日志
有时,爬网行为不符合预期,你需要能够看到出了什么问题才能修复它。 在本节中,你将学习如何使用 Kibana 来可视化你的网络爬虫的日志。
1) 从你的云控制台,转到你创建的部署并打开 Kibana。这个在上面的章节中我已经提到。
2) 在 Kibana 中可视化任何数据之前,你需要创建一个索引模式。 打开左侧菜单并单击 Stack management。 在 Kibana 下选择 Index Patterns,然后单击创建索引模式。
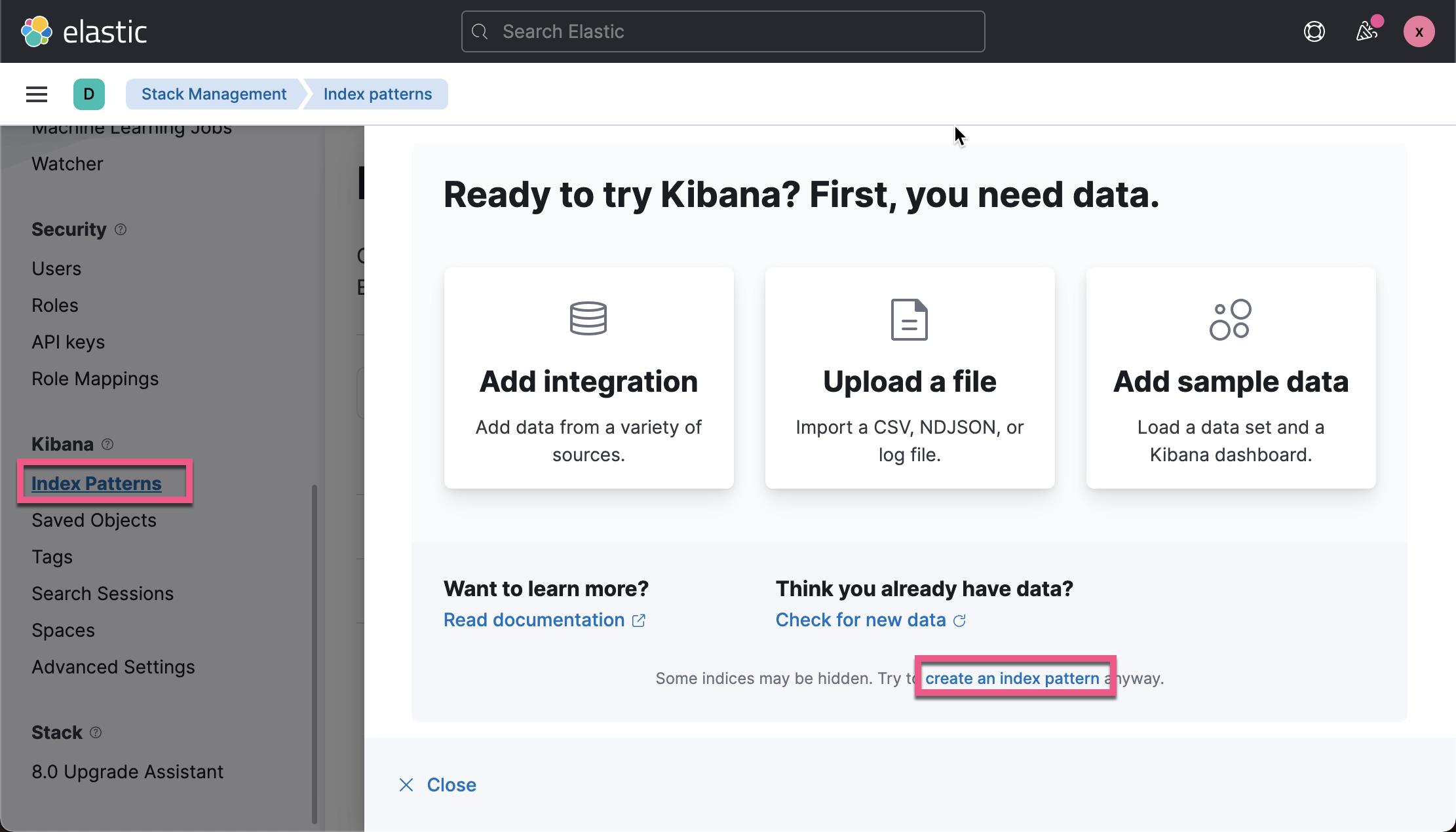
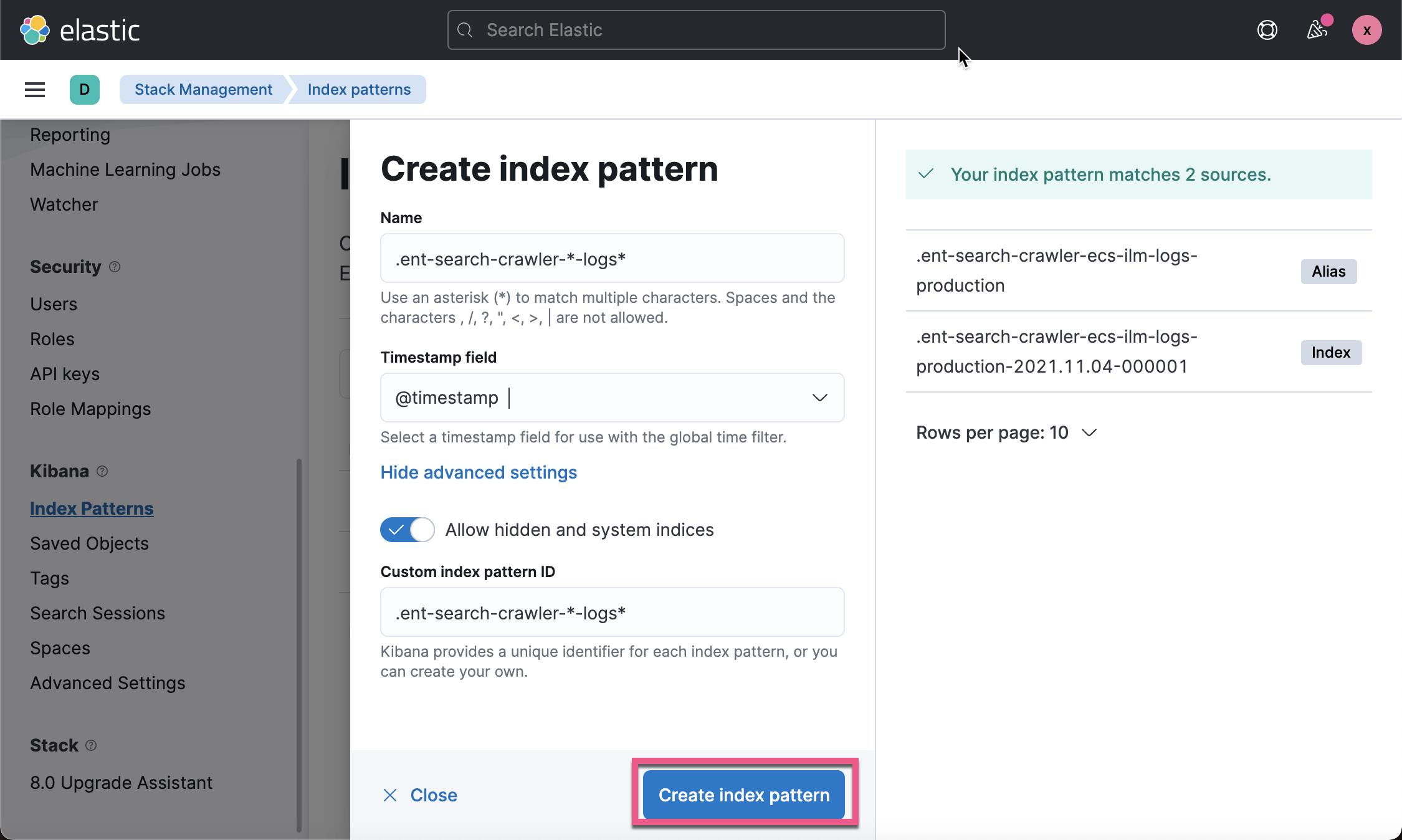
这样我们就创建了这个 .ent-search-crawler-*-logs* 索引模式。
我们接着打开 Kibana 中的 Log 应用:
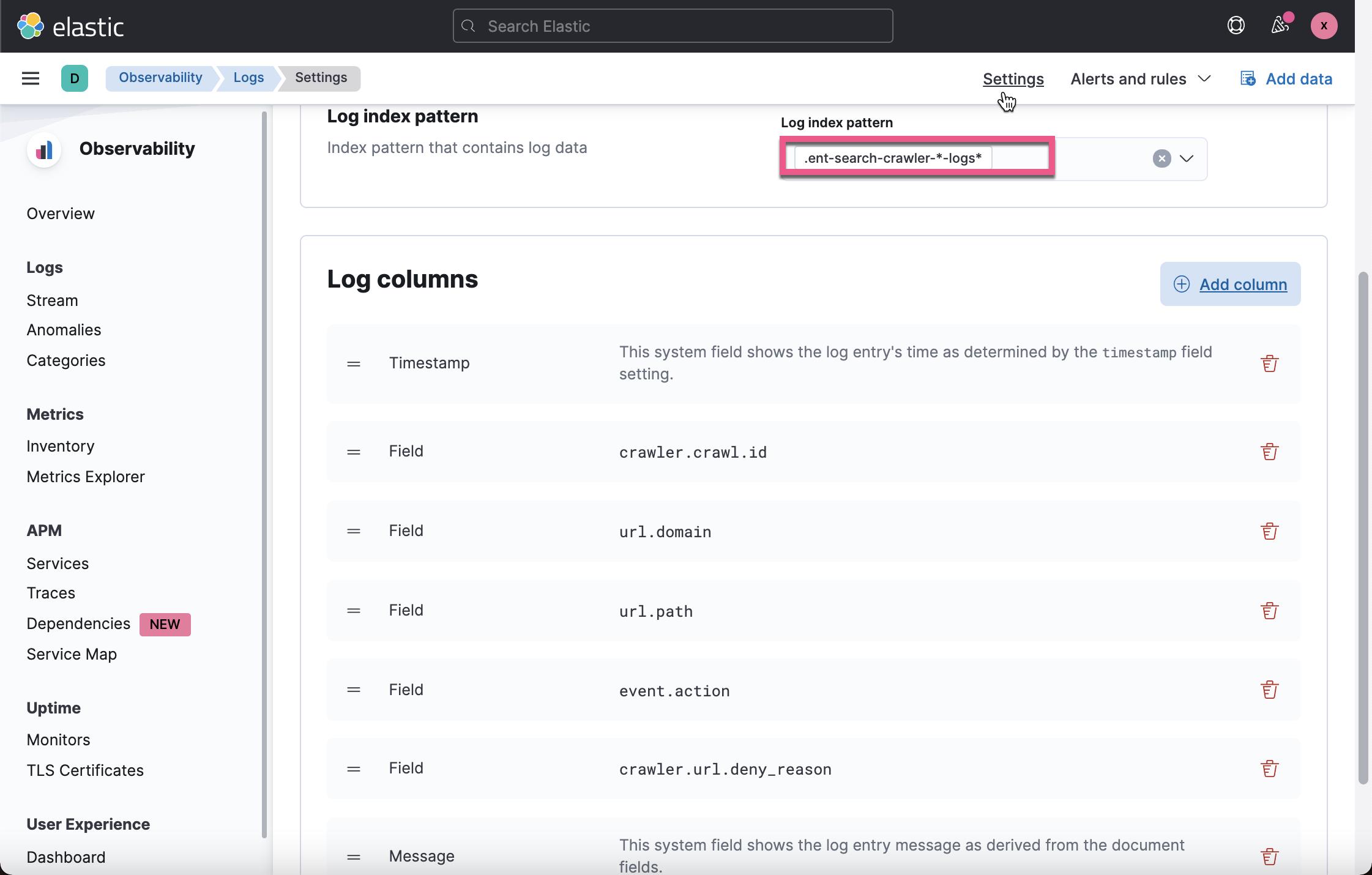
在我们配置上面的页面时,当我们选定 Log Index pattern 后,我们必须点击 Apply,那么之后可以在点击 Add column 时选我们所需要的字段。配置完毕后,点击页面的 Apply 按钮,并回到 Logs stream 页面:
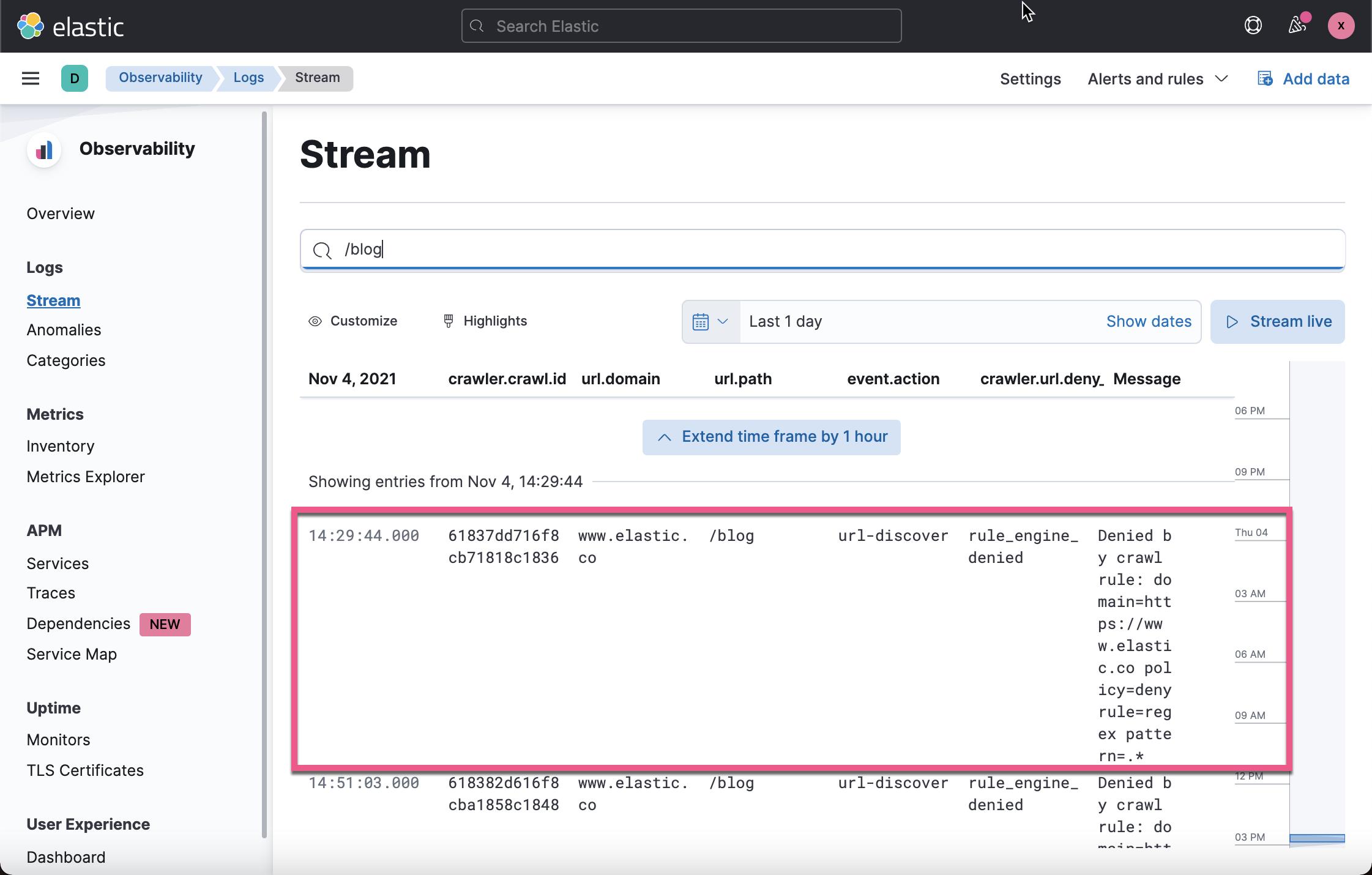
当我们搜索 /blog 时,我们可以看到上面的日志信息。它清楚地表明了我们错误的原因。
我们需要回到我们的 Enterprise Search rule 设置页面今天如下的调整:
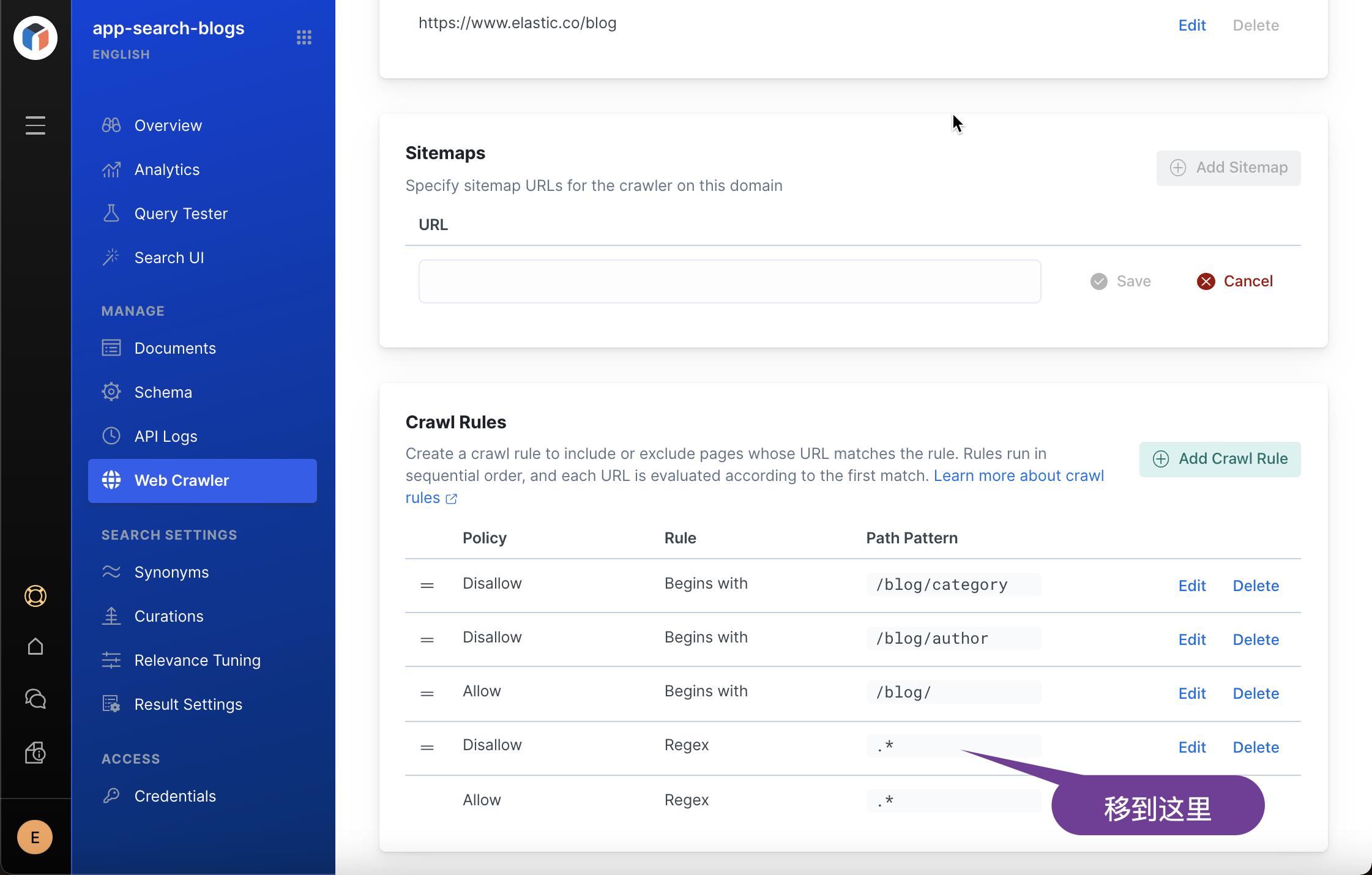
我们重新把 rule 的顺序组织一下。把 Disallow .* 移到最后。我们重新 Crawl。点击 Start a Crawl 按钮。我们再一次发现没有任何文档。这是什么原因呢?我们再一次切换到 Logs stream 里进行查看:
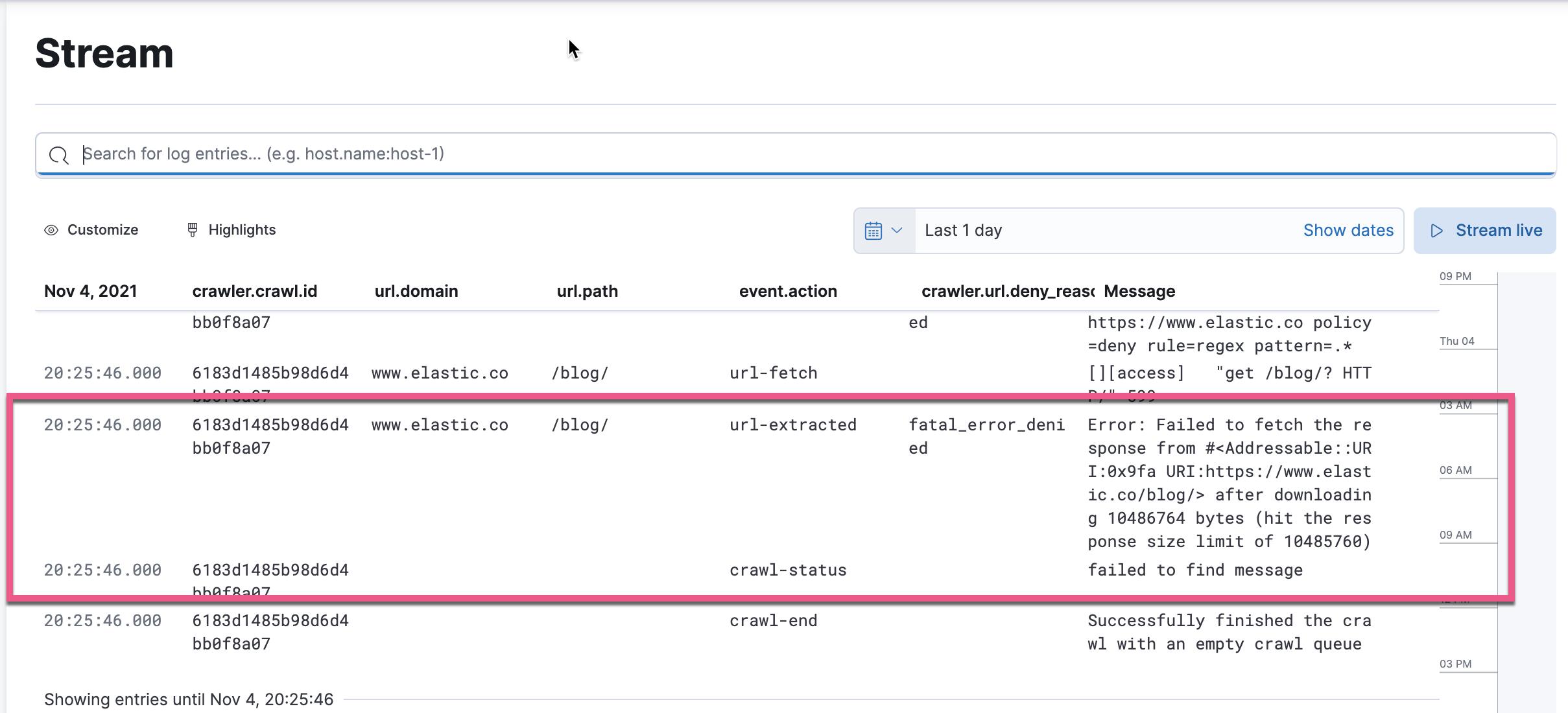
我们发现一个新的错误信息出现了。它显示 response 的长度超过设定的阈值。我们可以在Configuration | Elastic Enterprise Search Documentation [7.15] | Elastic 找到 Enterprise Search 的配置。
我们到 Enterprise Search 的服务器中去配置这个:
向下滚动到 Enterprise Search:
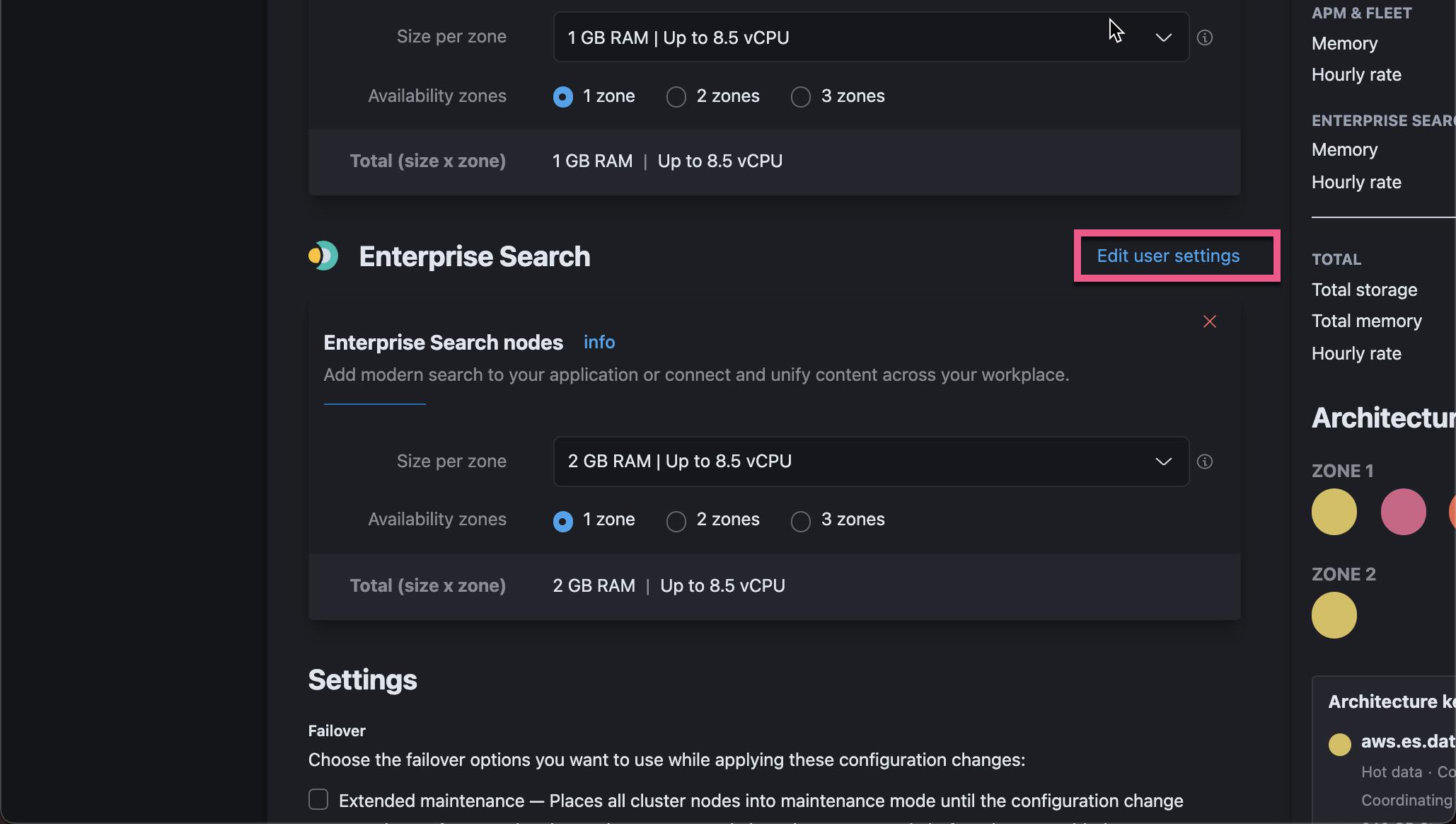
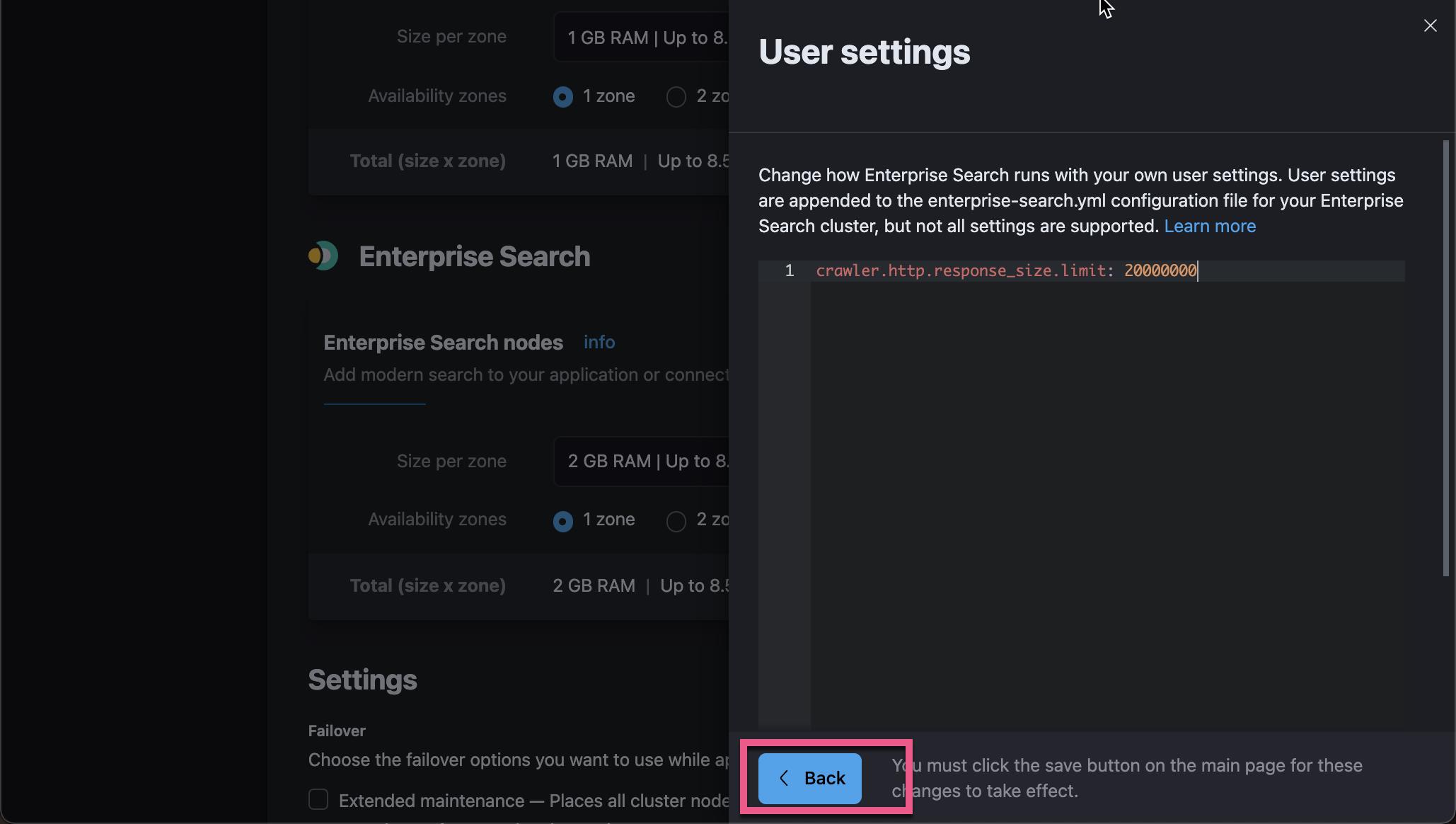
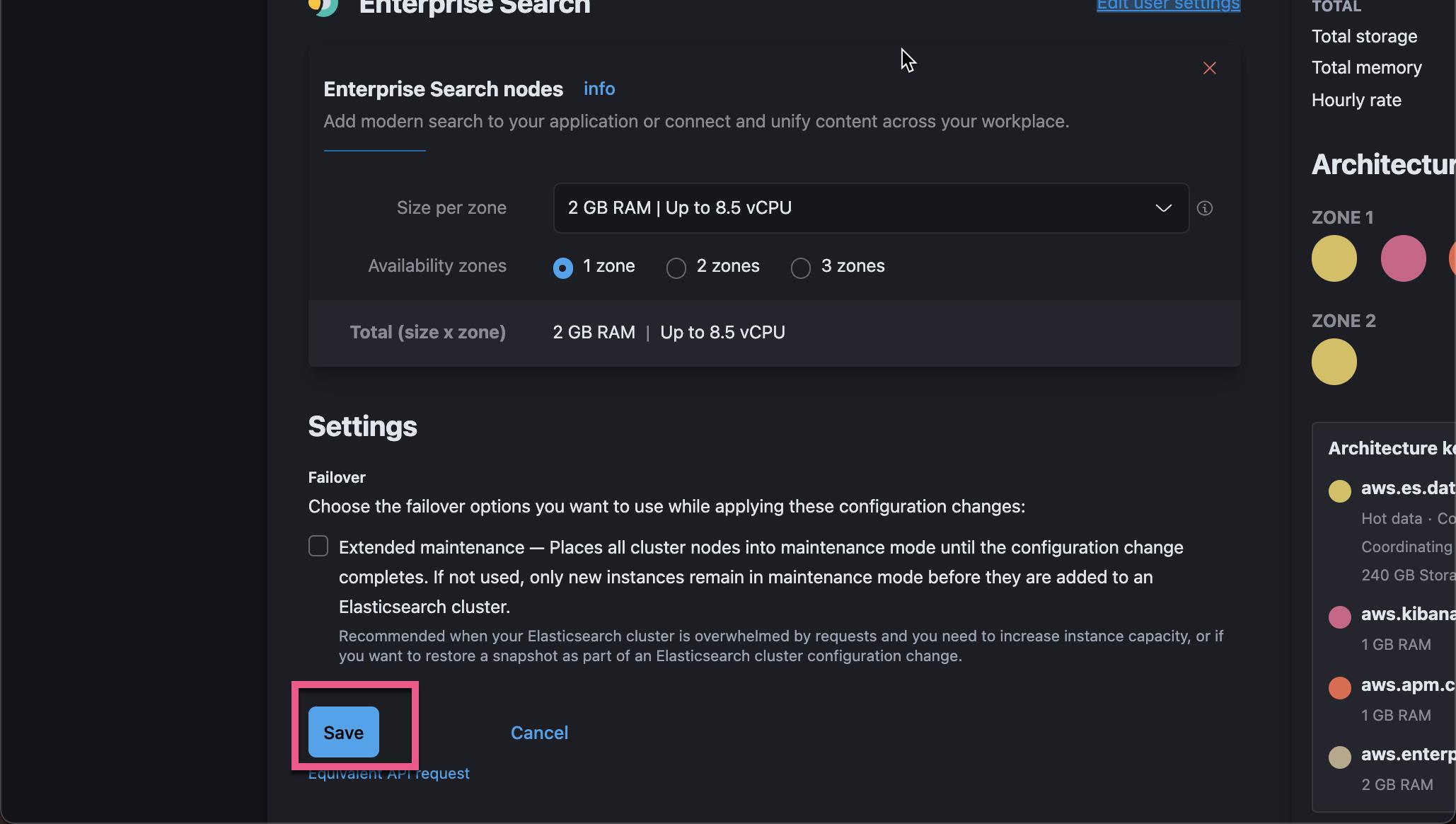
点击上面的 Save 按钮:
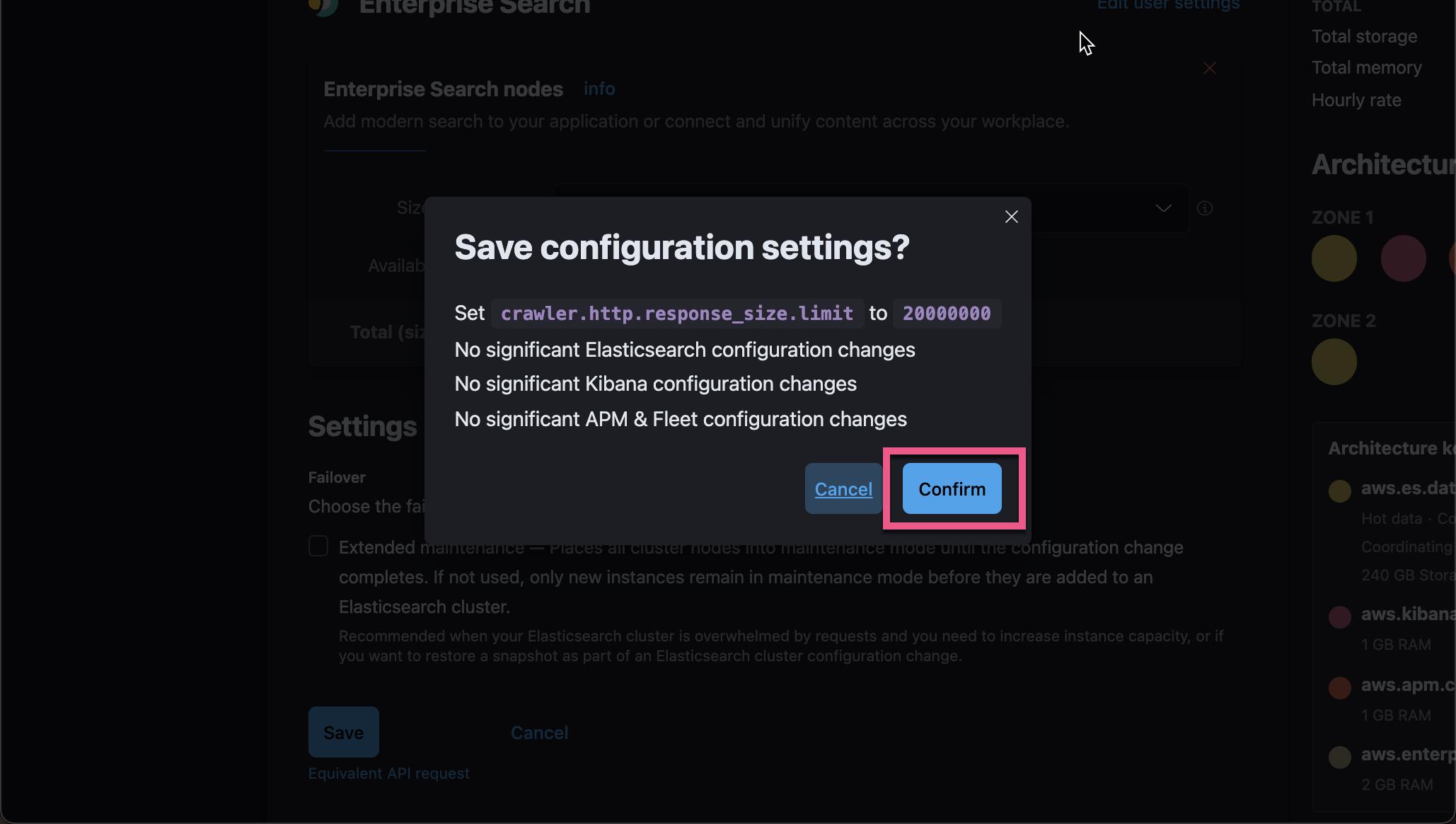
点击 Confirm 按钮。这样就保存了我们的设置。我们稍等片刻,等新的配置起作用后,我们再重新点击 Start a Crawl 按钮:
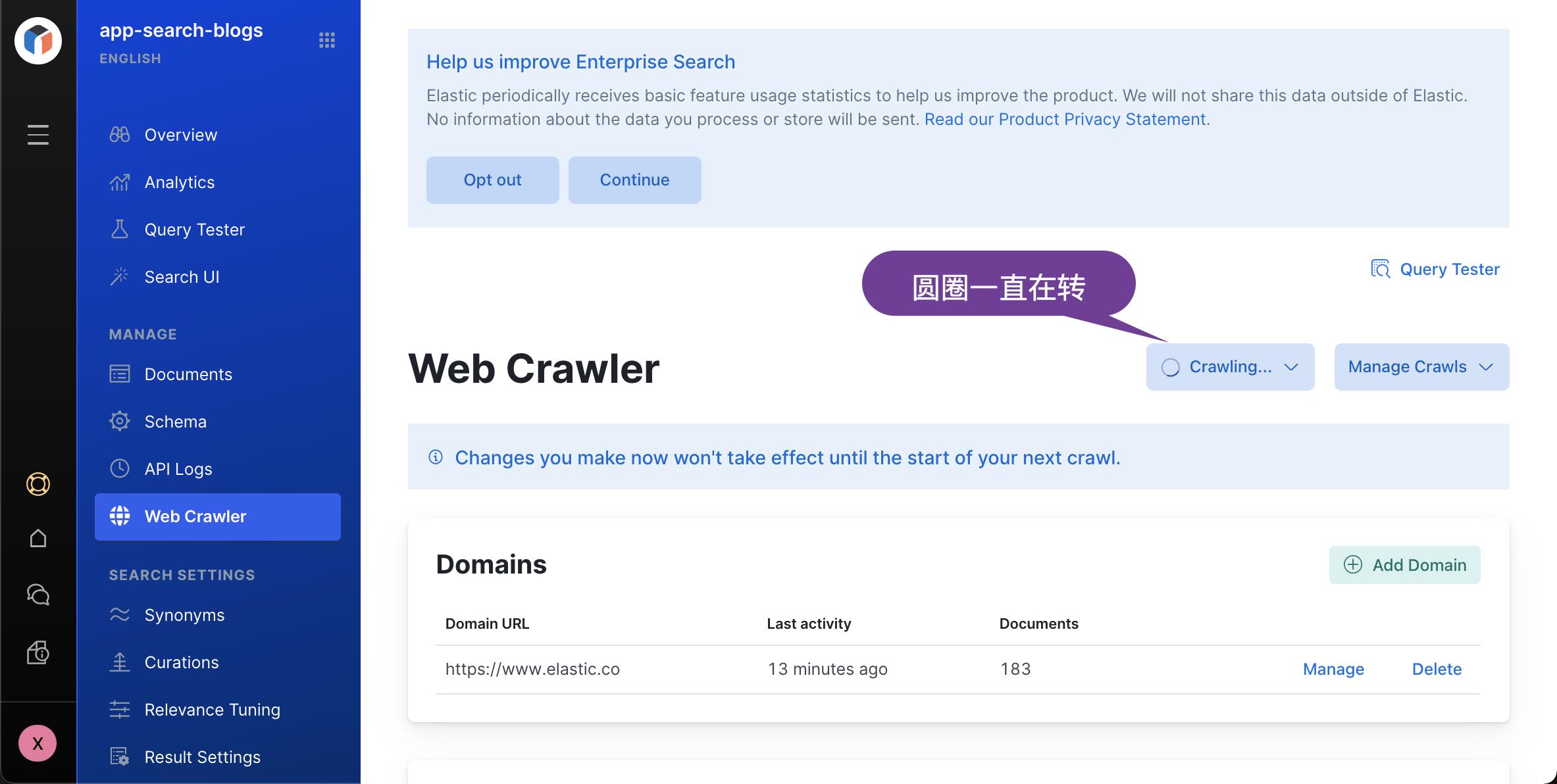
上面的圆圈一直在转,它表明我们的 Crawl 是一在进行中。我们重新进入到 Documents 窗口,我们可以看到新摄入的文档:
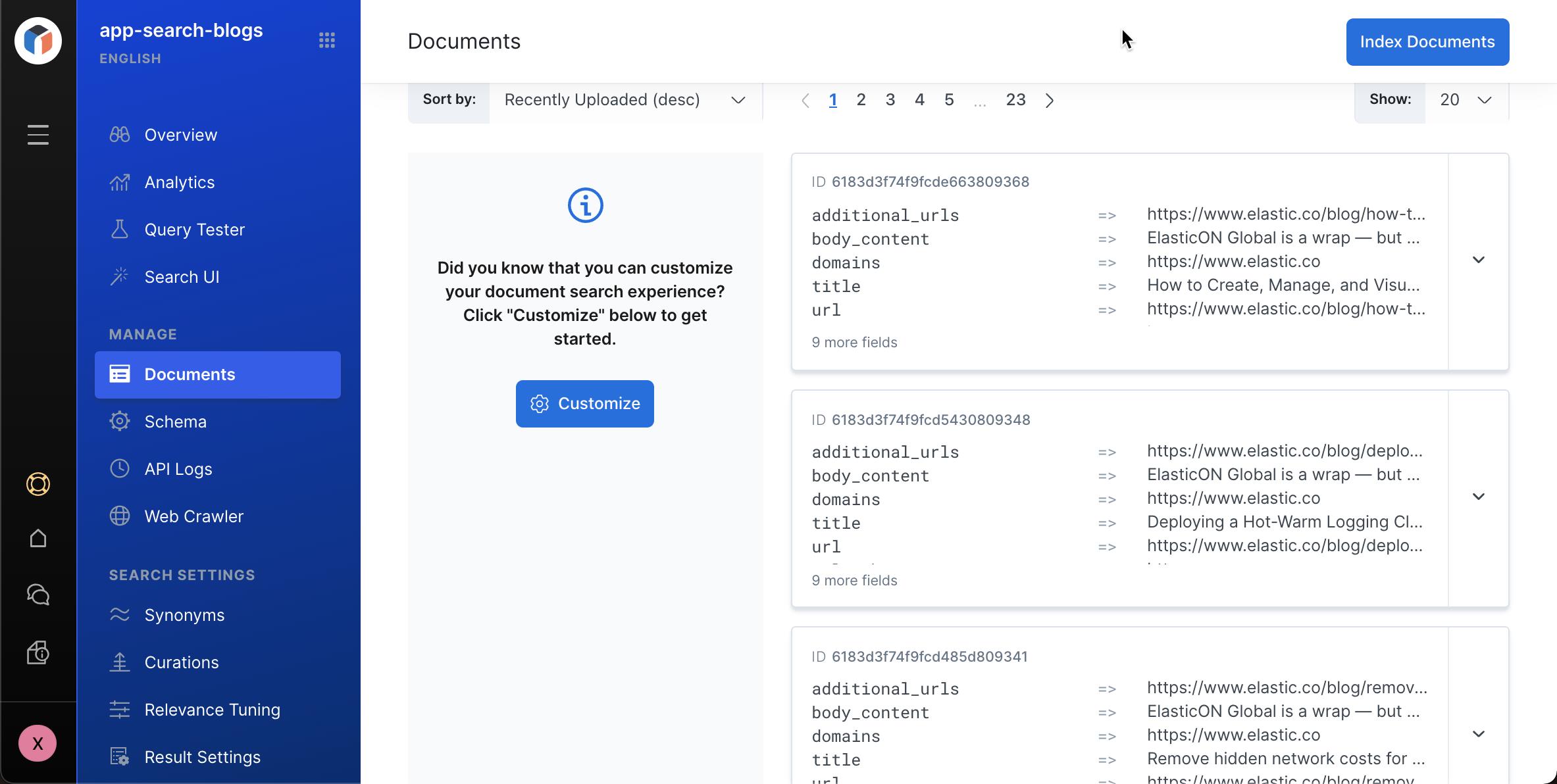
好了,我们已经知道如何把一个网站上的文档摄入到 Elasticsearch 了。我们需要等一段时间来完成 Crawl 的动作。
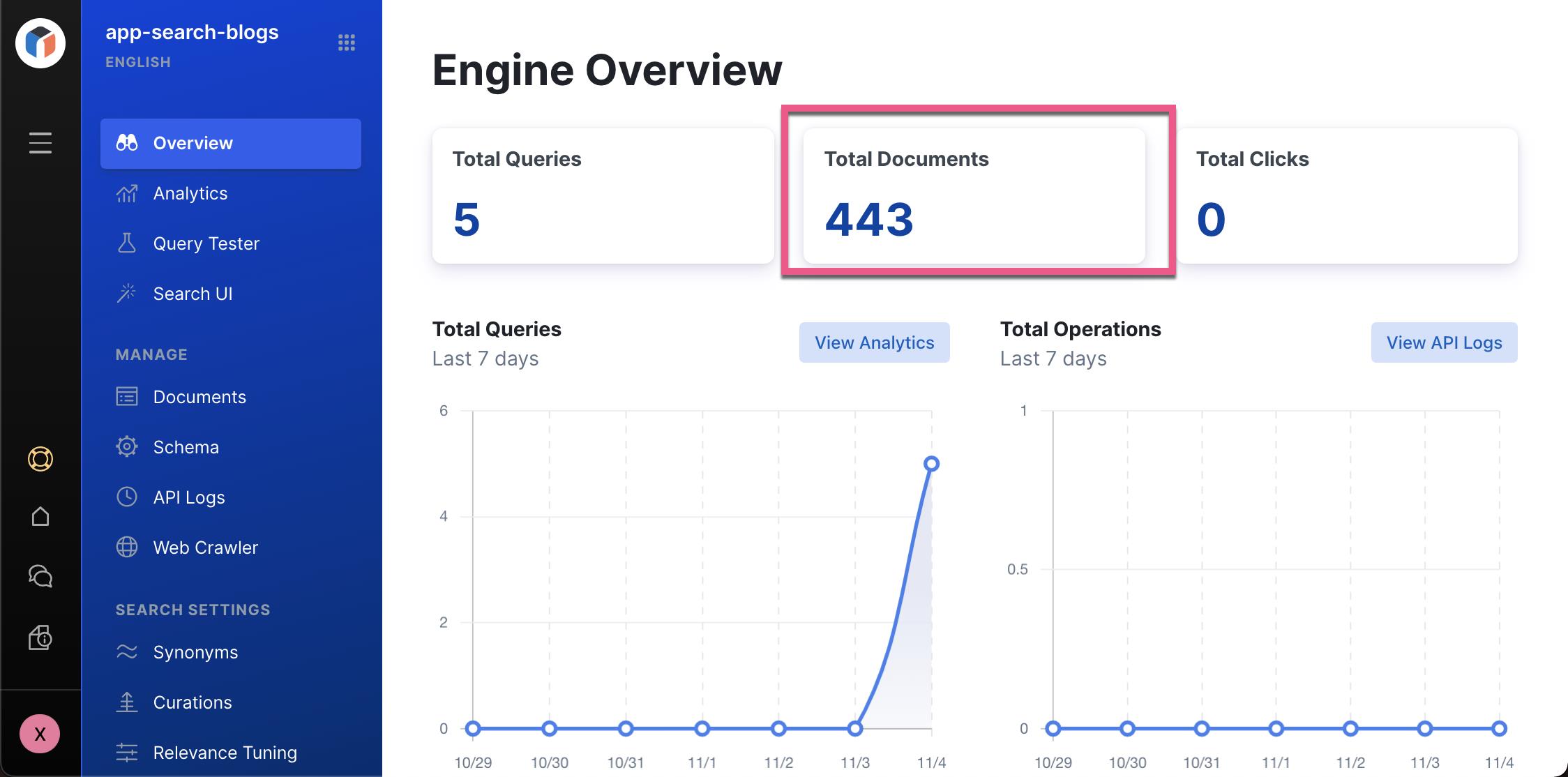
过一段时间后,我们可以在 Overview 中看到 443 个文档。
我们可以使用 Query Tester 来试一下查询 logstash 相关的文档:
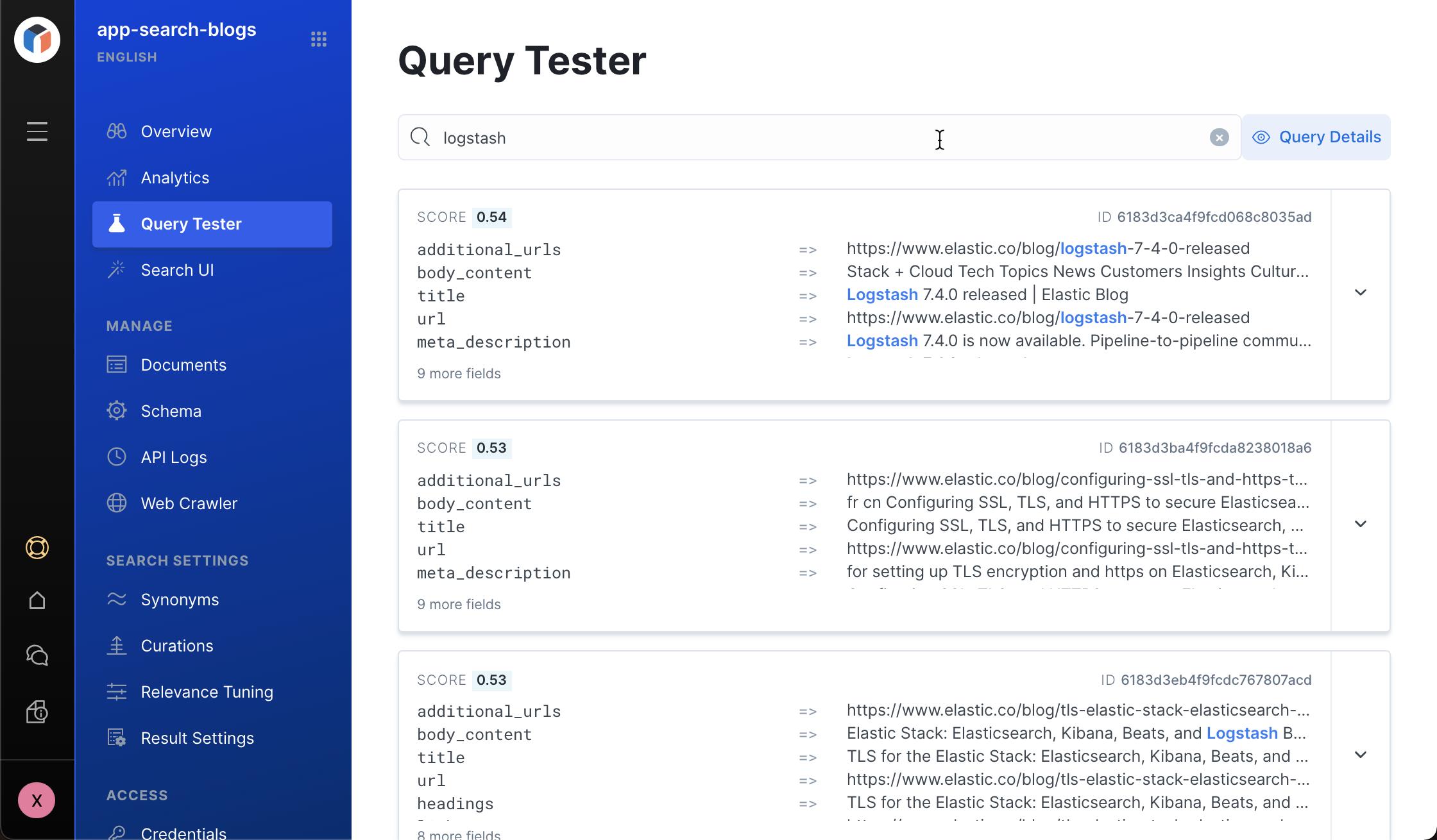
从上面的高亮词中,我们可以看到一些相关的 logstash 的文档。
在下面的章节中,我们将详述如何针对采集到的数据进行搜索及分析。
以上是关于Enterprise:Web Crawler 基础 的主要内容,如果未能解决你的问题,请参考以下文章