指标统计:基于流计算 Oceanus(Flink) 实现实时 UVPV 统计
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了指标统计:基于流计算 Oceanus(Flink) 实现实时 UVPV 统计相关的知识,希望对你有一定的参考价值。
作者:吴云涛,腾讯 CSIG 高级工程师
导语 | 最近梳理了一下如何用 Flink 来实现实时的 UV、PV 指标的统计,并和公司内微视部门的同事交流。然后针对该场景做了简化,并发现使用 Flink SQL 来 实现这些指标的统计会更加便捷。
一、解决方案描述
1.1 概述
本方案结合本地自建 Kafka 集群、腾讯云流计算 Oceanus(Flink)、云数据库 Redis 对博客、购物等网站 UV、PV 指标进行实时可视化分析。分析指标包含网站的独立访客数量(UV )、产品的点击量(PV)、转化率(转化率 = 成交次数 / 点击量)等。
相关概念介绍:UV(Unique Visitor):独立访客数量。访问您网站的一台客户端为一个访客,如用户对同一页面访问了 5 次,那么该页面的 UV 只加 1,因为 UV 统计的是去重后的用户数而不是访问次数。PV(Page View):点击量或页面浏览量。如用户对同一页面访问了 5 次,那么该页面的 PV 会加 5。
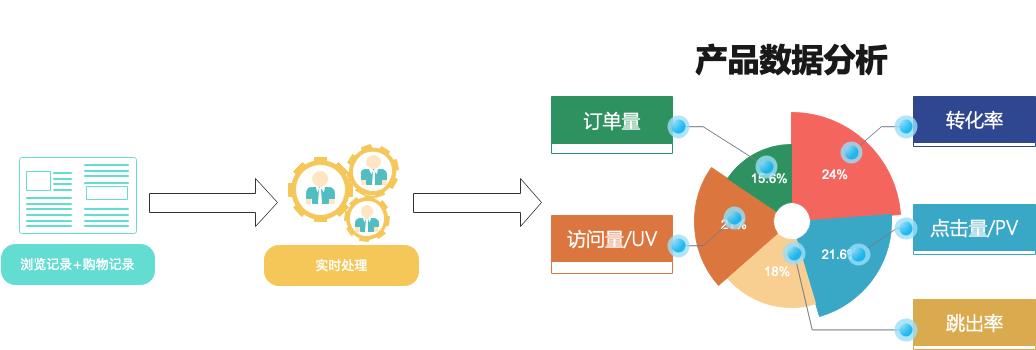
1.2 方案架构及优势
根据以上实时指标统计场景,设计了如下架构图:

涉及产品列表:
本地数据中心(IDC)的自建 Kafka 集群
私有网络 VPC
专线接入/云联网/VPN连接/对等连接
流计算 Oceanus (Flink)
云数据库 Redis
二、前置准备
购买所需的腾讯云资源,并打通网络。自建的 Kafka 集群需根据集群所在区域需采用 VPN 连接、专线连接或对等连接的方式来实现网络互通互联。
2.1 创建私有网络 VPC
私有网络(VPC)是一块在腾讯云上自定义的逻辑隔离网络空间,在构建 Oceanus 集群、Redis 组件等服务时选择的网络建议选择同一个 VPC,网络才能互通。否则需要使用对等连接、NAT 网关、VPN 等方式打通网络。私有网络创建步骤请参考帮助文档(https://cloud.tencent.com/document/product/215/36515)。
2.2 创建 Oceanus 集群
流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发、无缝连接、亚秒延时、低廉成本、安全稳定等特点的企业级实时大数据分析平台。流计算 Oceanus 以实现企业数据价值最大化为目标,加速企业实时化数字化的建设进程。
在 Oceanus 控制台的【集群管理】->【新建集群】页面创建集群,选择地域、可用区、VPC、日志、存储,设置初始密码等。VPC 及子网使用刚刚创建好的网络。创建完后 Flink 的集群如下:
2.3 创建 Redis 集群
在Redis 控制台(https://console.cloud.tencent.com/redis#/)的【新建实例】页面创建集群,选择与其他组件同一地域,同区域的同一私有网络 VPC,这里还选择同一子网。

2.4 配置自建 Kafka 集群
2.4.1 修改自建 Kafka 集群配置
自建 Kafka 集群连接时 bootstrap-servers 参数常常使用 hostname 而不是 ip 来连接。但用自建 Kafka 集群连接腾讯云上的 Oceanus 集群为全托管集群, Oceanus 集群的节点上无法解析自建集群的 hostname 与 ip 的映射关系,所以需要改监听器地址由 hostname 为 ip 地址连接的形式。
将 config/server.properties 配置文件中 advertised.listeners 参数配置为IP地址。示例:
# 0.10.X及以后版本
advertised.listeners=PLAINTEXT://10.1.0.10:9092
# 0.10.X之前版本
advertised.host.name=PLAINTEXT://10.1.0.10:9092修改后重启 Kafka 集群。
! 若在云上使用到自建的zookeeper地址,也需要将zk配置中的hostname修改IP地址形式。
2.4.2 模拟发送数据到topic
本案例使用topic为topic为 uvpv-demo。
1)Kafka 客户端
进入自建 Kafka 集群节点,启动 Kafka 客户端,模拟发送数据。
./bin/kafka-console-producer.sh --broker-list 10.1.0.10:9092 --topic uvpv-demo
>{"record_type":0, "user_id": 2, "client_ip": "100.0.0.2", "product_id": 101, "create_time": "2021-09-08 16:20:00"}
>{"record_type":0, "user_id": 3, "client_ip": "100.0.0.3", "product_id": 101, "create_time": "2021-09-08 16:20:00"}
>{"record_type":1, "user_id": 2, "client_ip": "100.0.0.1", "product_id": 101, "create_time": "2021-09-08 16:20:00"}2)使用脚本发送
脚本一:Java 代码参考:https://cloud.tencent.com/document/product/597/54834
脚本二:Python 脚本。参考之前案例中 python 脚本进行适当修改即可:
2.5 打通自建 IDC 集群到腾讯云网络通信
自建 Kafka 集群联通腾讯云网络,可通过以下前 3 种方式打通自建 IDC 到腾讯云的网络通信。
专线接入
https://cloud.tencent.com/document/product/216
适用于本地数据中心 IDC 与腾讯云网络打通。
云联网
https://cloud.tencent.com/document/product/877
适用于本地数据中心 IDC 与腾讯云网络打通,也可用于云上不同地域间私有网络 VPC 打通。
VPN连接
https://cloud.tencent.com/document/product/554
适用于本地数据中心 IDC 与腾讯云网络打通。
对等连接+ NAT网关
对等连接:https://cloud.tencent.com/document/product/553
NAT网关:https://cloud.tencent.com/document/product/552
适合云上不同地域间私有网络 VPC 打通,不适合本地 IDC 到腾讯云网络。
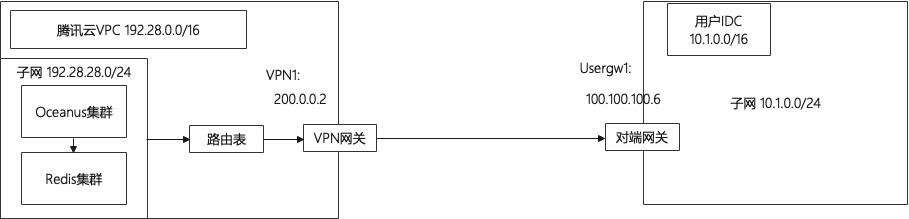
本方案中使用了 VPN 连接的方式,实现本地 IDC 和云上网络的通信。参考链接:
建立 VPC 到 IDC 的连接(路由表)(https://cloud.tencent.com/document/product/554/52854)
根据方案绘制了下面的网络架构图:
三 方案实现
3.1 业务目标
利用流计算 Oceanus 实现网站 UV、PV、转化率指标的实时统计,这里只列取以下3种统计指标:
网站的独立访客数量 UV。Oceanus 处理后在 Redis 中通过 set 类型存储独立访客数量,同时也达到了对同一访客的数据去重的目的。
网站商品页面的点击量 PV。Oceanus 处理后在 Redis 中使用 list 类型存储页面点击量。
转化率(转化率 = 成交次数 / 点击量)。Oceanus 处理后在 Redis 中用 String 存储即可。
3.2 源数据格式
Kafka topic:uvpv-demo(浏览记录)
| 字段 | 类型 | 含义 |
record_type | int | 客户号 |
user_id | varchar | 客户ip地址 |
client_ip | varchar | 房间号 |
product_id | Int | 进入房间时间 |
create_time | timestamp | 创建时间 |
Kafka 内部采用 json 格式存储,数据格式如下:
# 浏览记录
{
"record_type":0, # 0 表示浏览记录
"user_id": 6,
"client_ip": "100.0.0.6",
"product_id": 101,
"create_time": "2021-09-06 16:00:00"
}
# 购买记录
{
"record_type":1, # 1 表示购买记录
"user_id": 6,
"client_ip": "100.0.0.8",
"product_id": 101,
"create_time": "2021-09-08 18:00:00"
}3.3 编写 Flink SQL 作业
示例中实现了 UV、PV 和转化率3个指标的获取逻辑,并写入 Sink 端。
1、定义 Source
CREATE TABLE `input_web_record` (
`record_type` INT,
`user_id` INT,
`client_ip` VARCHAR,
`product_id` INT,
`create_time` TIMESTAMP,
`times` AS create_time,
WATERMARK FOR times AS times - INTERVAL '10' MINUTE
) WITH (
'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector
'topic' = 'uvpv-demo',
'scan.startup.mode' = 'earliest-offset',
--'properties.bootstrap.servers' = '82.157.27.147:9092',
'properties.bootstrap.servers' = '10.1.0.10:9092',
'properties.group.id' = 'WebRecordGroup', -- 必选参数, 一定要指定 Group ID
'format' = 'json',
'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常
'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null
);2、定义 Sink
-- UV sink
CREATE TABLE `output_uv` (
`userids` STRING,
`user_id` STRING
) WITH (
'connector' = 'redis',
'command' = 'sadd', -- 使用集合保存uv(支持命令:set、lpush、sadd、hset、zadd)
'nodes' = '192.28.28.217:6379', -- redis连接地址,集群模式多个节点使用'',''分隔。
-- 'additional-key' = '<key>', -- 用于指定hset和zadd的key。hset、zadd必须设置。
'password' = 'yourpassword'
);
-- PV sink
CREATE TABLE `output_pv` (
`pagevisits` STRING,
`product_id` STRING,
`hour_count` BIGINT
) WITH (
'connector' = 'redis',
'command' = 'lpush', -- 使用列表保存pv(支持命令:set、lpush、sadd、hset、zadd)
'nodes' = '192.28.28.217:6379', -- redis连接地址,集群模式多个节点使用'',''分隔。
-- 'additional-key' = '<key>', -- 用于指定hset和zadd的key。hset、zadd必须设置。
'password' = 'yourpassword'
);
-- 转化率 sink
CREATE TABLE `output_conversion_rate` (
`conversion_rate` STRING,
`rate` STRING
) WITH (
'connector' = 'redis',
'command' = 'set', -- 使用列表保存pv(支持命令:set、lpush、sadd、hset、zadd)
'nodes' = '192.28.28.217:6379', -- redis连接地址,集群模式多个节点使用'',''分隔。
-- 'additional-key' = '<key>', -- 用于指定hset和zadd的key。hset、zadd必须设置。
'password' = 'yourpassword'
);3、业务逻辑
-- 加工得到 UV 指标,统计所有时间内的 UV
INSERT INTO output_uv
SELECT
'userids' AS `userids`,
CAST(user_id AS string) AS user_id
FROM input_web_record ;
-- 加工并得到 PV 指标,统计每 10 分钟内的 PV
INSERT INTO output_pv
SELECT
'pagevisits' AS pagevisits,
CAST(product_id AS string) AS product_id,
SUM(product_id) AS hour_count
FROM input_web_record WHERE record_type = 0
GROUP BY
HOP(times, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE),
product_id,
user_id;
-- 加工并得到转化率指标,统计每 10 分钟内的转化率
INSERT INTO output_conversion_rate
SELECT
'conversion_rate' AS conversion_rate,
CAST( (((SELECT COUNT(1) FROM input_web_record WHERE record_type=0)*1.0)/SUM(a.product_id)) as string)
FROM (SELECT * FROM input_web_record where record_type = 1) AS a
GROUP BY
HOP(times, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE),
product_id;3.4 结果验证
通常情况,会通过 Web 网站来展示统计到的 UV、PV 指标,这里为了简单直接在Redis 控制台(https://console.cloud.tencent.com/redis#/)登录进行查询:
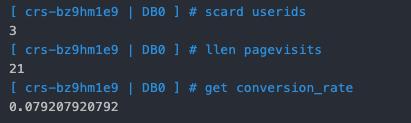
userids: 存储 UV
pagevisits: 存储 PV
conversion_rate: 存储转化率,即购买商品次数/总页面点击量。
四 总结
通过自建 Kafka 集群采集数据,在流计算 Oceanus (Flink) 中实时进行字段累加、窗口聚合等操作,将加工后的数据存储在云数据库Redis,统计到实时刷新的 UV、PV 等指标。这个方案在 Kafka json 格式设计时为了简便易懂做了简化处理,将浏览记录和产品购买记录都放在了同一个 topic 中,重点通过打通自建 IDC 和腾讯云产品间的网络来展现整个方案。针对超大规模的 UV 去重,微视的同事采用了 Redis hyperloglog 方式来实现 UV 统计。相比直接使用 set 类型方式有极小的内存空间占用的优点,详情见链接:https://cloud.tencent.com/developer/article/1889162。

点击文末「阅读原文」,了解腾讯云流计算 Oceanus 更多信息~
腾讯云大数据

长按二维码
关注我们
以上是关于指标统计:基于流计算 Oceanus(Flink) 实现实时 UVPV 统计的主要内容,如果未能解决你的问题,请参考以下文章
Flink 实践教程:入门:写入 Elasticsearch
流计算 Oceanus | 巧用 Flink 构建高性能 ClickHouse 实时数仓