腾讯实时计算团队向Flink 1.7.0贡献了36个PR
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯实时计算团队向Flink 1.7.0贡献了36个PR相关的知识,希望对你有一定的参考价值。
Flink 1.7.0已于近期(11月30日)发布,基于JIRA的统计数据,Oceanus团队在这个版本累计贡献了36个PR。Oceanus是腾讯TEG数据平台部实时计算团队围绕Flink打造的实时计算平台,这些PR足以说明在打造Oceanus的同时我们并不仅仅浮于表面只专注于上层能力建设,而是深度扩展、定制Flink的各大模块。接下来,我们将对这些PR对应的issue进行归类解读。
Kafka Connector与端到端测试
相关issue列表:
为Flink提供Kafka 2.0的connector(FLINK-9697)是Oceanus团队在Flink 1.7.0的主要贡献点,它也在1.7.0的发布声明中被列为一个显著的特性。这个connector在被官方接纳之前就已经在Oceanus中可用了,它相比原来的Kafka connector的一大优势是它不再区分具体的Kafka Client的版本,从此以后只需紧跟最新版本,一旦Kafka发布新版本的client,这个connector只需要更改相应的依赖版本号即可完成升级。近期Kafka已经发布了2.1.0,而升级Kafka依赖版本的PR已经被批准即将合并。
所有维护这个connector的issue都被归档到FLINK-10598这个umbrella issue下:
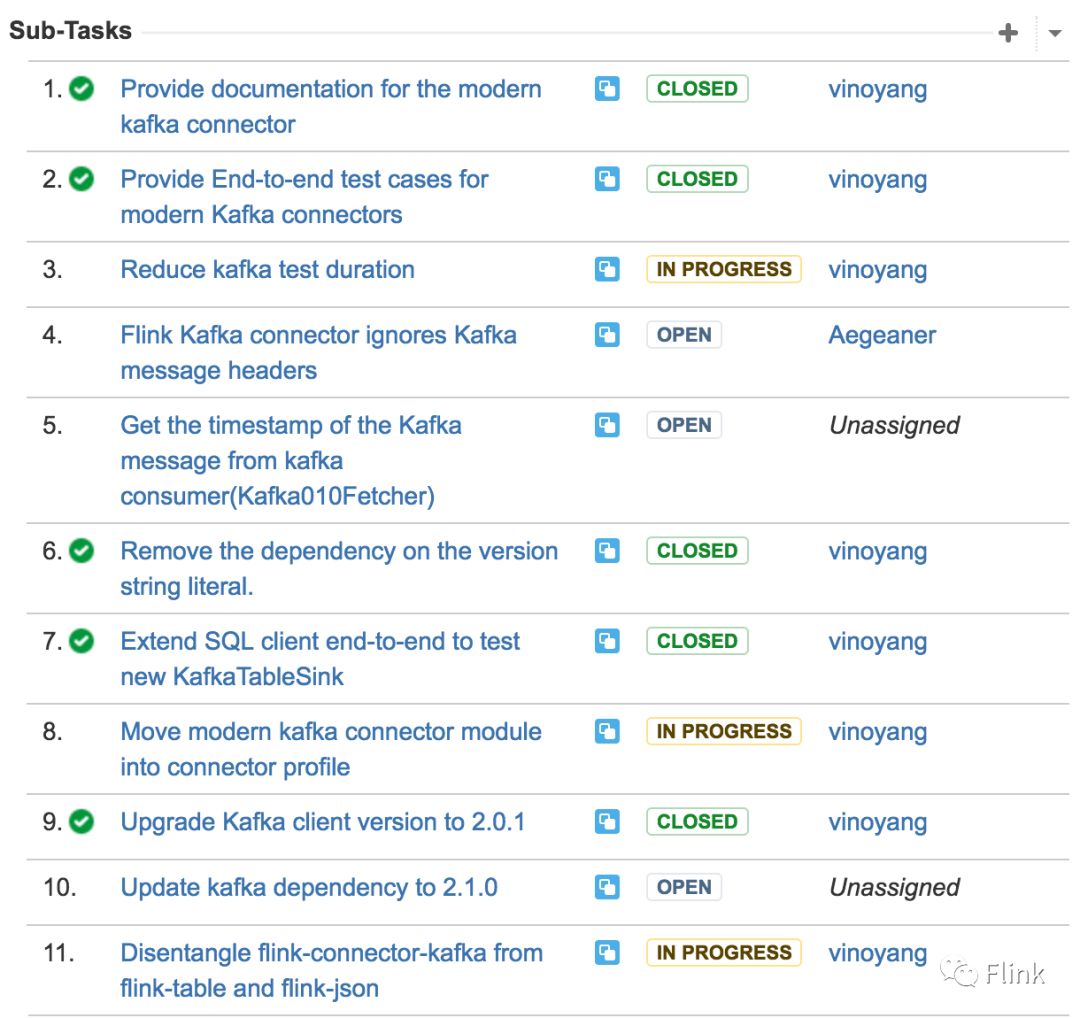
在这个connector被接受之后,我们为它添加了端到端的测试以及与SQL client端到端的集成测试。在这个过程中一并修复了Flink自身端到端测试代码的一些问题,并借此为Kafka 0.11 connector提供了端到端的测试。
Table/SQL
相关issue列表:
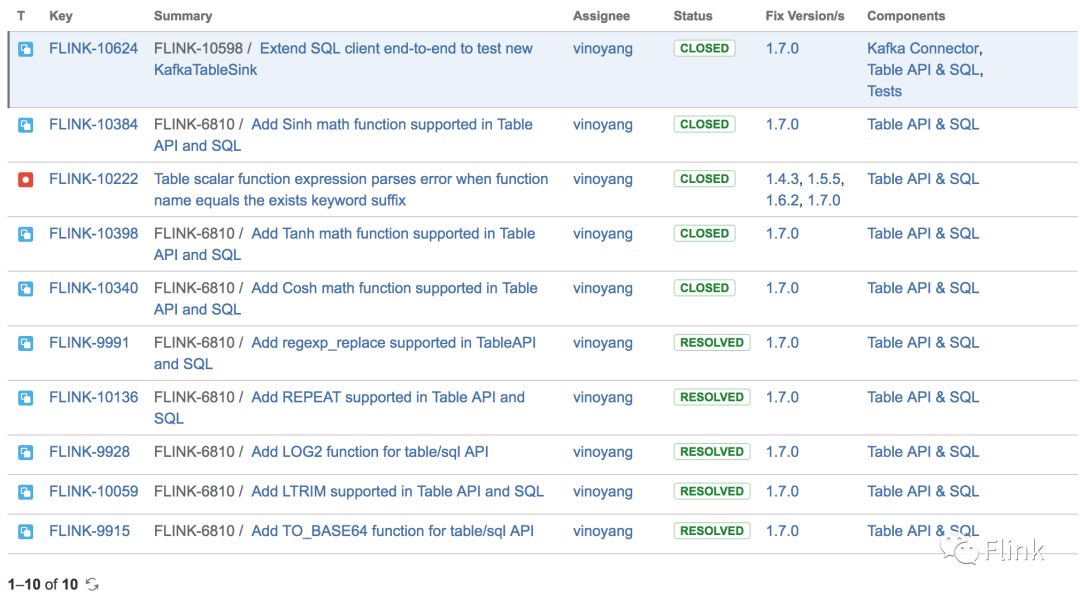
在Table/SQL模块,我们在扩充Oceanus函数能力的同时也将这些函数一并反馈给了社区。其中,来自Hive的 REGEXP_REPLACE以及 REGEXP_EXTRACT这两个UDF在文本处理的场景中经常被使用。另外,社区已经决定对table模块进行大规模的重构,包括重新组织代码结构,scala-free以及统一connector接口等等。我们以从Kafka中分离对flink-table的依赖为切入点,现已开始配合table模块的主要负责人Timo对这一模块进行重构同时去Scala化(FLINK-9461)。
运行时与分布式部署
相关issue列表:
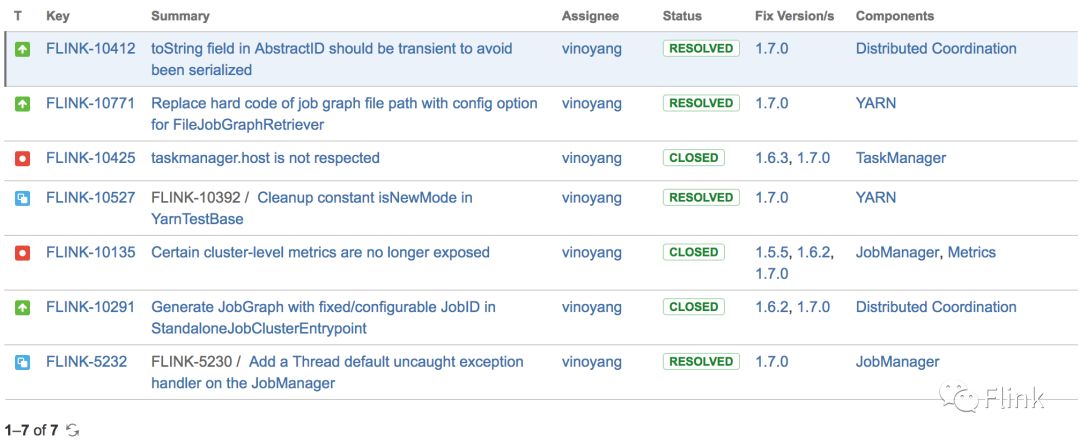
在runtime部分,Oceanus团队对发现的Flink Bug进行了修复并反馈给了社区,同时对一些功能进行了增强。值得一提的是FLINK-5232这个issue,众所周知,Flink的JobManager是一个Akka actor的实现。Actor system底层拥有自己的线程池,当JM遭遇未捕获的异常时,它将会进入不可控的状态,这个issue对JM的actor system进行了改进,引入了一个 RobustActorSystem,它对未捕获的异常提供了更优雅的实现,使得在这种情况下JM的JVM进程能够彻底地退出。
除此之外,我们在使用Flink的过程中发现它的Checkpoint Barrier alignment的逻辑存在一个Bug,它可能会导致Input Channel长时间处于Blocked状态而无法解除。这一点经过几番沟通,社区也认可了这个问题并打算在后续进行改进(FLINK-10966)。
指标、API、测试与文档
相关issue列表:
这是一些零散issue的归档。FLINK-9850为DataStream提供了一个允许指定标识符的 print API,这使得它对于多print(sink)的Job而言更有区分度,它提升了程序调试的便捷性同时保持了跟DataSet API的一致性。这里值得一提的是FLINK-10253,它有效地保证了Flink运行时组件的稳定性。因为MetricQueryService并不是一个独立的服务进程,而是以一个独立的actor system宿主在Flink runtime中与其他核心组件一起工作。这个时候如果它的线程池中的线程持续处于繁忙将会对其他核心组件的服务稳定性造成很大的影响(例如带来高延迟)。这个issue我们通过引入一个PriorityThreadsDispatcher替换了actor dispatcher的默认实现来让它以极低的线程优先级提供服务。
在API部分,基于我们所面对的“海量去重”的需求,我们期望推进诸如BloomFilter等近似计算算法以API的形式在社区尽快落地(FLINK-10993)。
总结
前我们在社区还有十几个PR处于review阶段,总PR数将近100个。oceanus团队将继续把海量实践过程中遇到的问题反馈给社区。
以上是关于腾讯实时计算团队向Flink 1.7.0贡献了36个PR的主要内容,如果未能解决你的问题,请参考以下文章
Flink 推动者莫问:扛过三年双 11,团队半年贡献 120 万行开源代码
Flink 实践教程:入门:写入 Elasticsearch
指标统计:基于流计算 Oceanus(Flink) 实现实时 UVPV 统计