TencentOCR 斩获 ICDAR 2021 三项冠军
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TencentOCR 斩获 ICDAR 2021 三项冠军相关的知识,希望对你有一定的参考价值。

作者:TencentOCR团队
全球 OCR 最顶级赛事,TencentOCR 以绝对领先优势斩获三冠,腾讯技术再扬威名!
一、竞赛背景
2021 年 9 月,两年一届的 ICDAR 竞赛落下帷幕,这是文字识别(OCR)领域全球最顶级赛事。TencentOCR 团队在本届比赛中参加了视频文字识别竞赛,并包揽该赛道全部 3 项冠军,成绩遥遥领先。这也是继 2017 年团队勇夺 4 项官方认证冠军[1]、2019 团队勇夺 7 项冠军后[2],再创佳绩,同时也标志着腾讯 OCR 技术稳居国际第一流水准。
国际文档分析与识别大会 ICDAR( International Conference on Document Analysis and Recognition)自 1991 年开始,每两年一届,今年为第十六届。自 2003 年大会开始设立技术竞赛,ICDAR 竞赛因其极高技术难度和强大实用性,一直是各大科研院校、科技公司的竞逐焦点。与赛后非正式刷榜不同,ICDAR 官方认证的正式竞赛采用全新数据集,且赛期内不公布参赛团队信息,限制提交时间和次数,属于高难度“盲打”,吸引国内外众多队伍参赛。
二、赛题介绍
ICDAR SVTS(场景视频文本定位)竞赛由海康威视、复旦大学和浙江大学联合出题,主办方提供了涵盖 21 个室内外真实场景的 129 段视频。SVTS 竞赛设置了 3 个任务:视频文本检测、视频文本跟踪、视频文本端到端识别。由于环境干扰(相机抖动、运动模糊、光照变化等),从视频帧中检测、跟踪、识别文本比静态图片 OCR 任务需要更高的鲁棒性,挑战性极高。

三、竞赛成绩
在 SVTS 竞赛的 3 个任务中,腾讯 OCR 以大幅度领先获得全部冠军。
任务 1 视频文本检测
任务 1 旨在获取视频帧中的文本框位置,每个文本框的 GT 由 4 个坐标点组成,评价指标是 F-score,团队以领先第二名 3.43%的成绩取得冠军。

任务 2 视频文本跟踪
任务 2 旨在跟踪视频中所有文本流,将帧与帧之间属于同一个文本的检测框聚合起来,评价指标是 ATA,我们以领先第二名 5.62%的成绩取得冠军。

任务 3 视频文本端到端识别
任务 3 旨在评估视频文本识别的端到端性能,任务要求在每一帧上正确检测文本,在视频帧上正确跟踪,并在序列级别正确识别,评价指标是 F-score,我们以领先第二名 5.53%的成绩取得冠军。

四、算法介绍
1. 文字检测
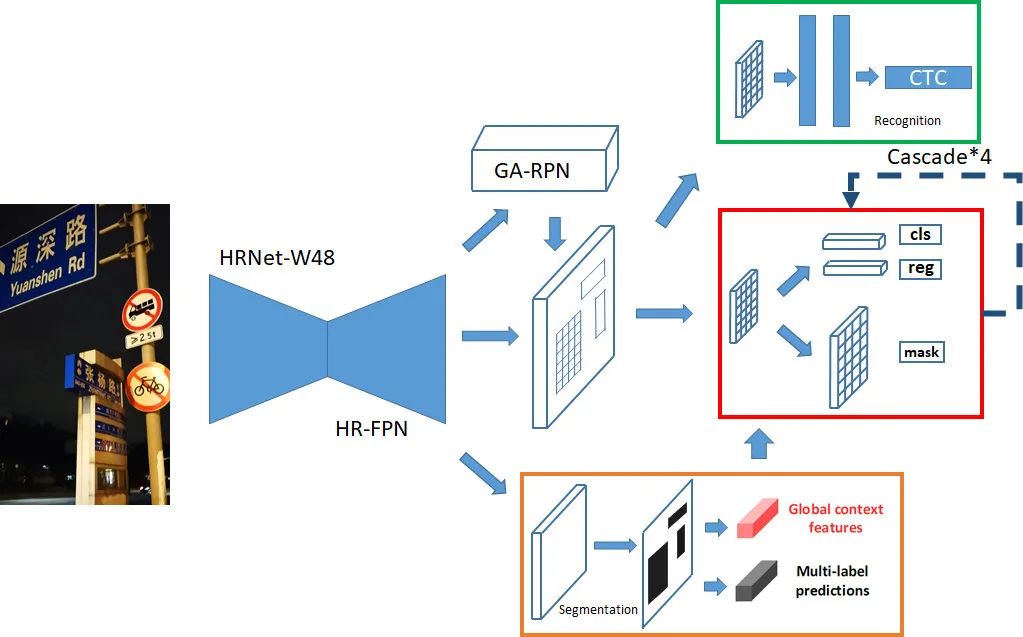
针对复杂自然场景下的视频文本检测任务,团队在 Cascade Mask R-CNN 算法的基础上设计了一种自顶向下实例分割的多方向文本的检测方法。在特征提取网络部分,我们训练多个主干网络,包括 HRNet-W48,Res2Net101,Resnet101 和 SENet101,并使用了 Syn-BN 和可变形卷积网络 DCN 等技术来增强特征。同时,经典的 RPN 网络替换成为 GA-RPN 的方法提升模型性能。为更好解决多尺度的问题,在模型 neck 部分我们尝试了 PAFPN、BiFPN 和 FPG 等一系列特征金字塔网络。在 R-CNN 部分,我们针对任务重新设计了 IoU 阈值和每个 stage 的权重,采用了 4 个级联的网络来精准预测文字位置。此外,借鉴 Double-Head R-CNN 的思想,我们把 R-CNN 网络的回归和分类两个网络分支解耦开。
为进一步增强模型的性能,我们引入更多的监督信息让网络去学习,首先增加了一个基于 CTC 的文字识别网络分支进行端到端的训练让模型更好地学习文字特征,其次引入一个全局的语义分割网络分支来强化特征的表示。最后,模型基于网络输出的 mask 分割结果采用多边形非极大抑制(Soft Polygon NMS)来输出文本区域框。在网络前向预测阶段,我们发现模型受视频的模糊程度影响很大,设计了一种多尺度+翻转+模糊增加的 TTA 策略,有效提升了测试的准召指标。同时,在将检测结果传给后续文字跟踪和端到端识别任务的同时,我们也使用这两个任务的输出结果设计了检测框筛选算法来提升最后的精度。
2. 文字跟踪
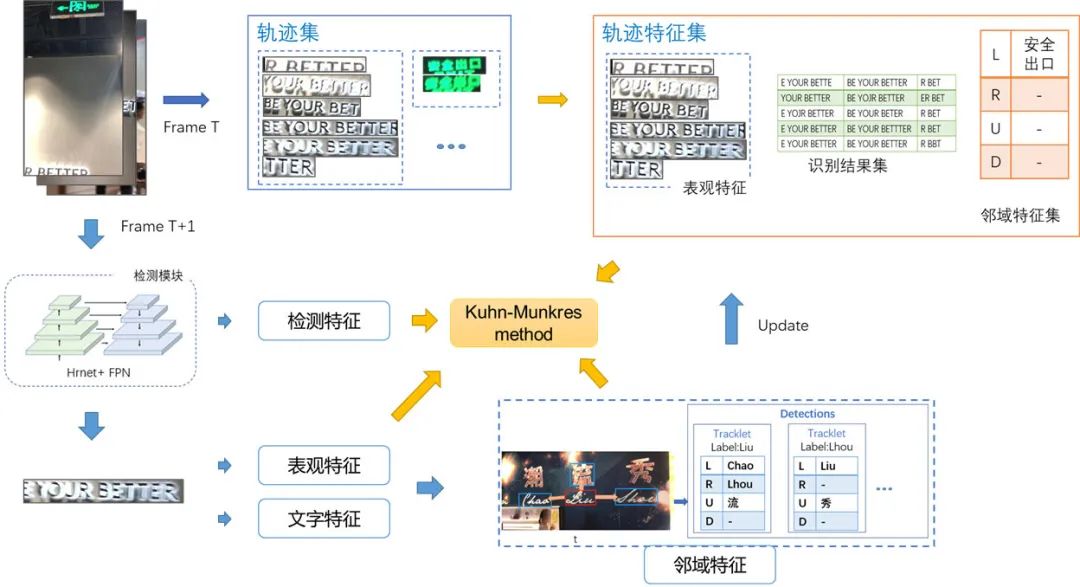
在文字跟踪方面,我们提出了一种基于 DeepSort 的多度量文本跟踪方法,使用 4 个不同的度量来计算每条轨迹与每个新检测框之间的匹配度,包括检测框匹配度,检测框表观相似度,文本相似度和一种新设计的检测框邻域相似度。这些度量被归一化加权求和用作当前检测框和已有轨迹之间的匹配损失函数,使用 Kuhn-Munkres 算法计算最优匹配。最后采用后处理和集成策略,通过替换邻近检测框,使得替换后轨迹文本稳定程度提升,来减少 ID-Switch 跟踪错误,最后自动移除低文本置信度的轨迹来提升精度。
3. 端到端文字识别
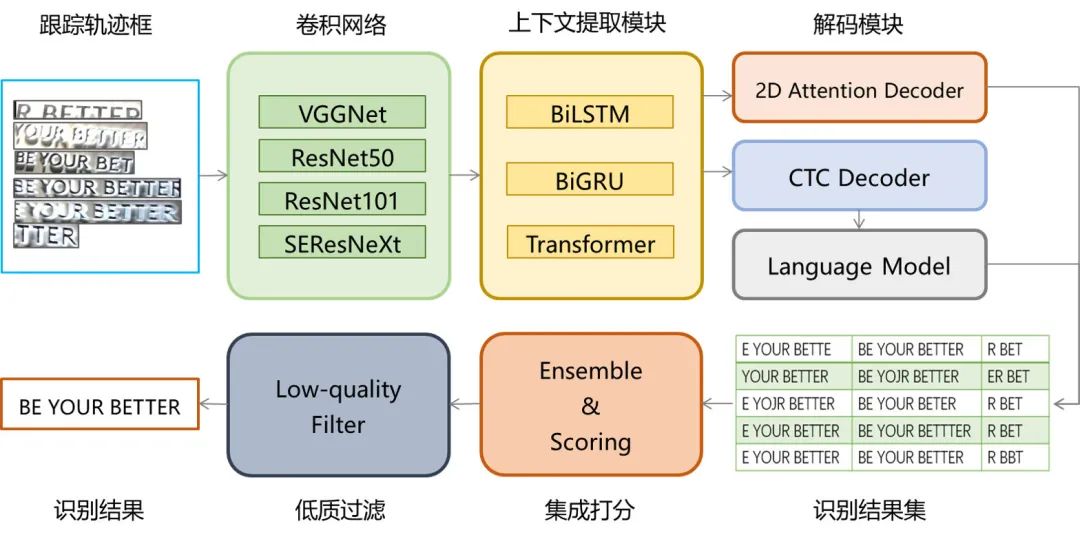
在文字识别方面,我们采用了基于 CTC 和基于 2D Attention 的混合模型。我们的编码网络由卷积网络和上下文提取模块组成,我们首先通过 VGGNet、ResNet50/101、SEResNeXt 等卷积网络提取视觉特征,然后通过 BiLSTM、BiGRU 和 Transformer 提取上下文信息。针对基于 CTC 的算法,我们还开发了可端到端训练的内嵌式语言模型。在端到端阶段,我们采用多类识别算法对输入跟踪轨迹的所有文本进行预测,然后使用基于文本置信度和长度的方法集成并计算结果得分,取分数最高的结果作为轨迹的文本结果。最后,我们移除低分和包含无关字符的轨迹以提高最终精度。
五、总结
TencentOCR 团队是腾讯内部专业研发 OCR 技术的团队,于 2021 年 TEG OCR 联合公司兄弟团队成立了 TencentOCR Oteam,团队在文本识别领域上已经深耕细作多年,自研的基于深度学习方法的文本检测与识别技术处于业界领先水平,已在全球最权威 ICDAR 竞赛中连续三届斩获共 14 项官方认证冠军。国际顶级竞赛是技术水平的试金石和腾讯技术影响力的证明,同样重要的还有技术应用与落地。腾讯 OCR 技术,凭借高精准度、高稳定性以及专业服务伙伴的理念,已支持公司内所有 BG 的数百个业务场景,如腾讯广告、微信、QQ、腾讯云、腾讯视频、腾讯信息流产品、腾讯会议等,并获得广泛好评。未来,团队将继续在 TencentOCR Oteam 的框架下,深度协同,保持腾讯 OCR 在业界的领先水平。

参考目录:
欢迎点击下方视频
关注腾讯程序员视频号
以上是关于TencentOCR 斩获 ICDAR 2021 三项冠军的主要内容,如果未能解决你的问题,请参考以下文章
将 ICDAR 2015 的 Ground Truth 标注在图像数据上
厉害了!阿里安全图灵实验室在ICDAR2017 MLT竞赛刷新世界最好成绩
论文阅读(Lukas Neuman——ICDAR2015Efficient Scene Text Localization and Recognition with Local Character