将 ICDAR 2015 的 Ground Truth 标注在图像数据上
Posted chenxp2311
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将 ICDAR 2015 的 Ground Truth 标注在图像数据上相关的知识,希望对你有一定的参考价值。
因为要标注数据,数据集是 ICDAR 2015 比赛中的 Challenge 4: Incidental Scene Text。
原图及标注的图像,还有给定的 ground truth 文件如下所示:

最左边是原图,中间是标注的图像,右边是 ground truth 文件内容,按顺时针顺序的坐标: x1,y1,x2,y2,x3,y3,x4,y4 ,最后是 words,但是如果是 ### 这种表示的,则表示不 care 文字的内容。
用 python 将 ground truth 框住文字,代码如下:
import os
import path
import glob
import Image, ImageDraw
# ground truth directory
gt_text_dir = "/home/chenxp/Documents/Hitachi/ICDAR_2015/ICDAR2015_ch4/ch4_training_localization_transcription_gt"
# original images directory
image_dir = "/home/chenxp/Documents/Hitachi/ICDAR_2015/ICDAR2015_ch4/*.jpg"
imgDirs = []
imgLists = glob.glob(image_dir)
# where to save the images with ground truth boxes
imgs_save_dir = "/home/chenxp/Documents/Hitachi/ICDAR_2015/ICDAR_with_GT"
for item in imgLists:
imgDirs.append(item)
for img_dir in imgDirs:
img = Image.open(img_dir)
dr = ImageDraw.Draw(img)
img_basename = os.path.basename(img_dir)
(img_name, temp2) = os.path.splitext(img_basename)
# open the ground truth text file
img_gt_text_name = "gt_" + img_name + ".txt"
print img_gt_text_name
bf = open(os.path.join(gt_text_dir, img_gt_text_name)).read().decode("utf-8-sig").encode("utf-8").splitlines()
for idx in bf:
rect = []
spt = idx.split(',')
rect.append(float(spt[0]))
rect.append(float(spt[1]))
rect.append(float(spt[2]))
rect.append(float(spt[3]))
rect.append(float(spt[4]))
rect.append(float(spt[5]))
rect.append(float(spt[6]))
rect.append(float(spt[7]))
# draw the polygon with (x_1, y_1, x_2, y_2, x_3, y_3, x_4, y_4)
dr.polygon((rect[0], rect[1], rect[2], rect[3], rect[4], rect[5], rect[6], rect[7]), outline="red")
img.save(os.path.join(imgs_save_dir, img_basename))上面代码中间有一句话:
bf = open(os.path.join(gt_text_dir, img_gt_text_name)).read().decode("utf-8-sig").encode("utf-8").splitlines()如果没有 decode("utf-8-sig").encode("utf-8") 这句话,那么在解析 ground truth 的 txt 文件时,会在首行多处下面的东西,如下所示:
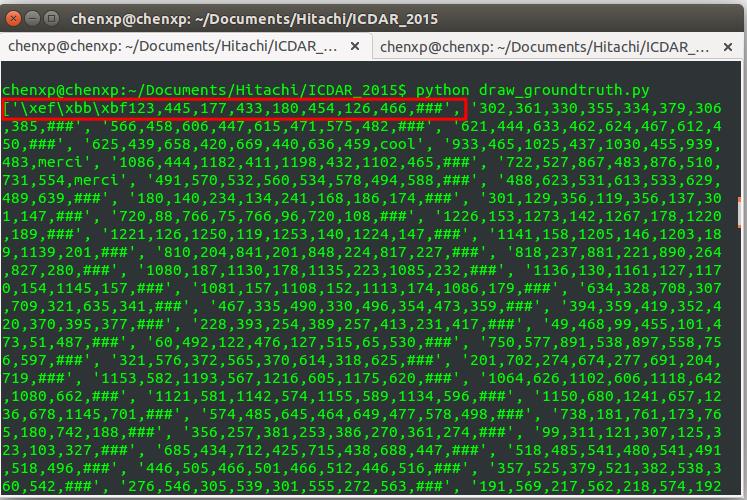
看到了吗?第一行 \\xef\\xbb\\xbf ,这是什么鬼?
Google 一下,在 stackoverflow 上有个问答:Split function add: \\xef\\xbb\\xbf…\\n to my list:

原来是 txt 文件编码包含了 UTF-8 BOM。
最后标注的结果如下:


以上是关于将 ICDAR 2015 的 Ground Truth 标注在图像数据上的主要内容,如果未能解决你的问题,请参考以下文章