推荐算法Model-Based 协同过滤算法
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法Model-Based 协同过滤算法相关的知识,希望对你有一定的参考价值。
基于模型的协同过滤推荐算法
Model-Based 协同过滤算法
随着机器学习技术的逐渐发展与完善,推荐系统也逐渐运用机器学习的思想来进行推荐。将机器学习应用到推荐系统中的方案真是不胜枚举。
以下对Model-Based CF算法做一个大致的分类:
- 基于分类算法、回归算法、聚类算法
- 基于矩阵分解的推荐
- 基于神经网络算法
- 基于图模型算法
接下来我们重点学习以下几种应用较多的方案:
- 基于K最近邻的协同过滤推荐
- 基于回归模型的协同过滤推荐
- 基于矩阵分解的协同过滤推荐
基于K最近邻的协同过滤推荐
基于K最近邻的协同过滤推荐其实本质上就是MemoryBased CF,只不过在选取近邻的时候,加上K最近邻的限制。
这里我们直接根据MemoryBased CF的代码实现
修改以下地方:
class CollaborativeFiltering(object):
based = None
def __init__(self, k=40, rules=None, use_cache=False, standard=None):
'''
:param k: 取K个最近邻来进行预测
:param rules: 过滤规则,四选一,否则将抛异常:"unhot", "rated", ["unhot","rated"], None
:param use_cache: 相似度计算结果是否开启缓存
:param standard: 评分标准化方法,None表示不使用、mean表示均值中心化、zscore表示Z-Score标准化
'''
self.k = 40
self.rules = rules
self.use_cache = use_cache
self.standard = standard
修改所有的选取近邻的地方的代码,根据相似度来选取K个最近邻
similar_users = self.similar[uid].drop([uid]).dropna().sort_values(ascending=False)[:self.k]
similar_items = self.similar[iid].drop([iid]).dropna().sort_values(ascending=False)[:self.k]
但由于我们的原始数据较少,这里我们的KNN方法的效果会比纯粹的MemoryBasedCF要差。
基于回归模型的协同过滤推荐
请参考: 基于回归模型的协同过滤推荐算法
基于矩阵分解的CF算法
矩阵分解发展史
Traditional SVD:
通常SVD矩阵分解指的是SVD(奇异值)分解技术,在这我们姑且将其命名为Traditional SVD(传统并经典着)其公式如下:
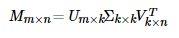
Traditional SVD分解的形式为3个矩阵相乘,中间矩阵为奇异值矩阵。如果想运用SVD分解的话,有一个前提是要求矩阵是稠密的,即矩阵里的元素要非空,否则就不能运用SVD分解。
很显然我们的数据其实绝大多数情况下都是稀疏的,因此如果要使用Traditional SVD,一般的做法是先用均值或者其他统计学方法来填充矩阵,然后再运用Traditional SVD分解降维,但这样做明显对数据的原始性造成一定影响。
FunkSVD(LFM)
刚才提到的Traditional SVD首先需要填充矩阵,然后再进行分解降维,同时存在计算复杂度高的问题,因为要分解成3个矩阵,所以后来提出了Funk SVD的方法,它不在将矩阵分解为3个矩阵,而是分解为2个用户-隐含特征,项目-隐含特征的矩阵,Funk SVD也被称为最原始的LFM模型
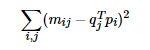
借鉴线性回归的思想,通过最小化观察数据的平方来寻求最优的用户和项目的隐含向量表示。同时为了避免过度拟合(Overfitting)观测数据,又提出了带有L2正则项的FunkSVD,上公式:
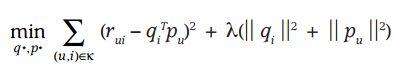
以上两种最优化函数都可以通过梯度下降或者随机梯度下降法来寻求最优解。
BiasSVD:
在FunkSVD提出来之后,出现了很多变形版本,其中一个相对成功的方法是BiasSVD,顾名思义,即带有偏置项的SVD分解:
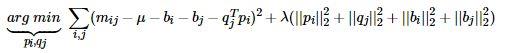
它基于的假设和Baseline基准预测是一样的,但这里将Baseline的偏置引入到了矩阵分解中
SVD++:
人们后来又提出了改进的BiasSVD,被称为SVD++,该算法是在BiasSVD的基础上添加了用户的隐式反馈信息:
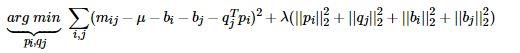
显示反馈指的用户的评分这样的行为,隐式反馈指用户的浏览记录、购买记录、收听记录等。
SVD++是基于这样的假设:在BiasSVD基础上,认为用户对于项目的历史浏览记录、购买记录、收听记录等可以从侧面反映用户的偏好。
具体实现:基于矩阵分解的协同过滤算法
加油!
感谢!
努力!
以上是关于推荐算法Model-Based 协同过滤算法的主要内容,如果未能解决你的问题,请参考以下文章
Python+Django+Mysql志愿者活动推荐系统 基于用户项目内容的协同过滤推荐算法 SimpleWebActivityCFRSPython python实现协同过滤推荐算法实现源代码下载