GaussDB (for Cassandra) 数据库治理:大key与热key问题的检测与解决
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GaussDB (for Cassandra) 数据库治理:大key与热key问题的检测与解决相关的知识,希望对你有一定的参考价值。
摘要:GaussDB(for Cassandra) 提供了大key和热key的实时检测,以帮助业务进行合理的schema设计,规避业务稳定性风险。
本文分享自华为云社区《GaussDB (for Cassandra) 数据库治理 -- 大key与热key问题的检测与解决》,作者:Cassandra官方 。
Cassandra数据库是一个高度可扩展的高性能分布式数据库,面向大数据场景,可用于管理大量的结构化数据。在业务使用的过程中,随着业务量和数据流量的持续增长,往往一些业务的设计弊端逐渐暴露出来,降低了集群的稳定性和可用性。比如主键设计不合理,单个分区的记录数或数据量过大,出现超大分区键,引起了节点负载不均,集群稳定性会下降,这一类问题称为大key问题。当某一热点key的请求在某一主机上的访问超过server极限时,会导致热点Key问题的产生。往往大key是造成热key问题的间接原因。
GaussDB(for Cassandra) 是一款基于华为自研的计算存储分离架构的分布式数据库,兼容Cassandra生态的云原生NoSQL数据库,支持类SQL语法CQL。在华为云高性能、高可用、高可靠、高安全、可弹性伸缩的基础上,提供了一键部署、快速备份恢复、计算存储独立扩容、监控告警等服务能力。针对以上问题,GaussDB(for Cassandra) 提供了大key和热key的实时检测,以帮助业务进行合理的schema设计,规避业务稳定性风险。
大key的分析与解决
大key的产生,最主要的原因是主键设计不合理,使得单个分区的记录数或数据量过大。一旦某一个分区出现极大时,对该分区的访问,会造成分区所在server的负载变高,甚至造成节点OOM等。
针对大key问题,一般采取两种修复手段,一种是增加缓存,优化表结构。一种是基于现有分区键,增加分区键散列。对数据进行打散,避免单个分区的记录过大。GaussDB(for Cassandra) 有如下整改事例,业务整改后负载平稳运行。
案例1:
XX集群的数据量过大,导致集群存在大分区键(排查数量大概为2000+),最大的分区键达到38G。当业务频繁访问这部分大的分区键时,会导致节点持续高负载,影响业务请求成功率。
表结构如下
CREATE TABLE movie (
movieid text,
appid int,
uid bigint,
accessstring text,
moviename text,
access_time timestamp,
PRIMARY KEY (movieid, appid, uid, accessstring, moviename)
)表设计分析
movie表保存了短视频的相关信息,分区键为movieid,并且保存了用户信息(uid),如果movieid是一个热门短视频,有几千万甚至上亿用户点赞此短视频,则该热门短视频所在的分区非常大(当前发现有38G)。
解决方法:
1. 优化表结构
创建新表保存热门短视频信息,只保留短视频公共信息,不包含用户信息,确保该表不会产生大的分区键。热门短视频信息写入该表中。
CREATE TABLE hotmovieaccess (
movieid text,
appid int,
accessstring text,
access_time timestamp,
PRIMARY KEY (movieid, appid)
)2. 增加缓存
增加缓存,业务应用先从缓存中读取热门文件信息,没有查询到,则从数据库中查询,减少数据库查询次数。
整个优化逻辑如下:
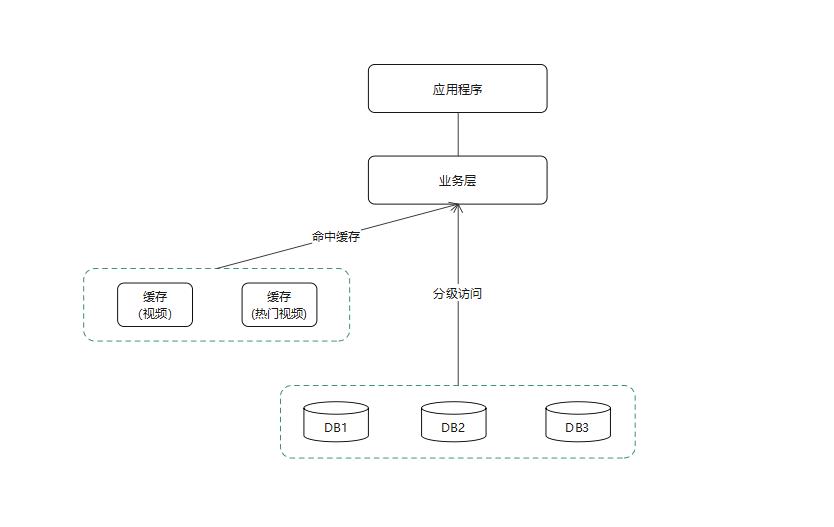
- 先查缓存,当缓存存在,直接返回结果。
- 当缓存不存在,查询热门视频缓存(缓存不存在,则查询hot表),当视频为为热门视频时,查询hotmovieaccess表。
- 当hotmovieaccess表存在结果时,直接返回,当hotmovieaccess表不存在记录时,查询movie表。
- 并缓存查询结果。
案例2:
movie_meta以月度建表,每个表只存当月的数据,初始的这种设计是可以减轻或规避分区键过大问题的。由于业务频繁写入,热门视频存储的记录非常多,还是形成了大的数据分区。
CREATE TABLE movie_meta202110 (
path text,
moviename text,
movieid text,
create_time timestamp,
modify_mtime timestamp,
PRIMARY KEY (path, moviename)
)解决办法:
新分区键增加一个随机数(0~999):将原来一个分区存储的信息随机离散存储到1000个分区中。
采用新的分区键之后,没有形成新超过100M的分区键,旧的超过100M的分区键数据,随着时间老化过期即可。
大key的定义与检测手段
通过长时间的业务观察,我们规定以下阈值,超过任何一个条件的阈值即为大key:
- 单个分区键的行数不能超过10万
- 单个分区的大小不超过100MB
GaussDB(for Cassandra) 支持了大key的检测与告警。在CES界面,可以配置实例的大key告警。当发生大key事件时,会第一时间通知。及时整改,可避免业务波动。

大key告警字段解释
[
{
"partition_size": "1008293497", //超大分区键的总大小
"timestamp": "2021-09-08 07:08:18,240", //大key产生时间
"partition_num": "676826", //超大分区键的总行数
"keyspace_name": "ssss", //keyspace名称
"table_name": "zzzz", //表名称
"table_id": "024a1070-0064-11eb-bdf3-d3fe5956183b", //表id
"partition_key": "{vin=TESTW3YWZD2021003}" //分区键
}
]热key的危害与解决
在日常生活中,经常会发生各种热门事件,应用中对该热点新闻进行上万次的点击浏览和评论时,会形成一个较大的请求量,这种情况下会造成短时间内对同一个key频繁操作,会导致key所在节点的CPU和load飙高,从而影响落在该节点的其他请求。导致业务成功率下降。诸如此类的还有热门商品促销,网红直播等场景,这些典型的读多写少的场景也会产生热点问题。
热key会造成以下危害:
- 流量集中,达到物理网卡上限。
- 请求过多,缓存分片服务被打垮。
- DB击穿,引起业务雪崩。
GaussDB(for Cassandra) 针对热key问题,常见的修复手段如下:
- 设计上需要考虑热key的问题,避免在数据库上产生热key
- 业务侧通过增加缓存来减少热key出现的情况下对数据库造成的冲击。考虑多级缓存解决热key问题(如Redis + 本地二级缓存)
- 屏蔽热点key, 比如在业务侧进行定制, 支持热key黑白名单能力,可以将热key临时屏蔽。
热key的检测
我们定义访问频率 大于 100000 次/min 的key为热key。热key事件分为两种类型,一种时WRITES事件,代表写热点,一种是READS事件,表示读热点。
GaussDB(for Cassandra) 也提供了热key的监测与告警。在CES界面,可以配置实例的热key告警。如下
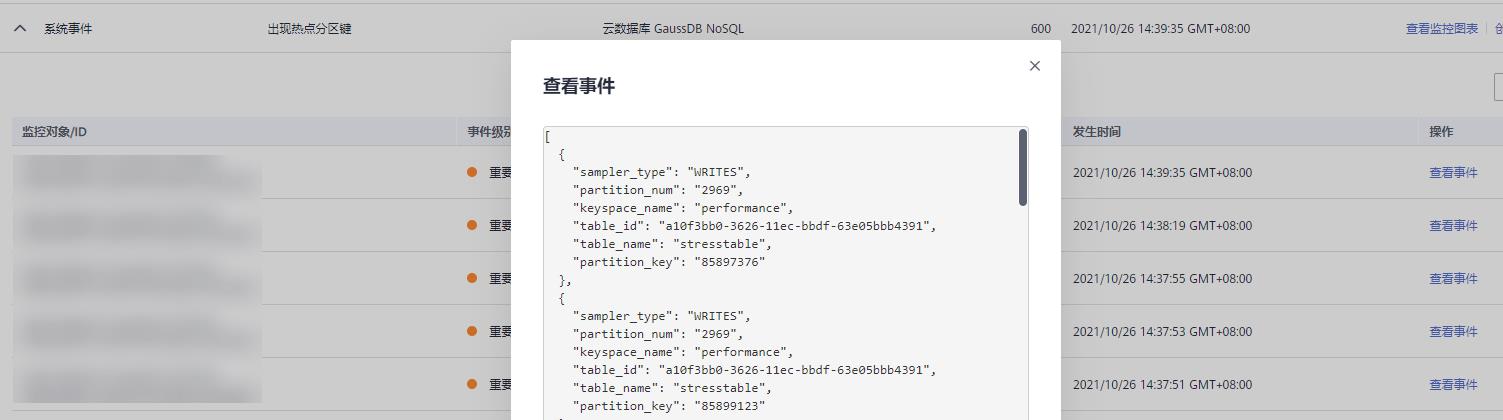
热key告警字段解释:
{
"sampler_type": "WRITES", // 采样类型。取值有WRITES, READS; WRITES代表写,READS代表读。
"partition_num": "2969", // 分区键的热点次数
"keyspace_name": "performance", // keyspace名称
"table_id": "a10f3bb0-3626-11ec-bbdf-63e05bbb4391", // 表id
"table_name": "stresstable", // 表名
"partition_key": "85897376" // 产生热点分区键的值
}GaussDB(for Cassandra) 提供了大key和热key的实时监控。确保第一时间感知业务风险。提供的大key和热key解决方案,在面对大数据量洪峰场景,增强了集群的稳定性与可用性。为客户业务持续稳定运行保驾护航。
综上,在线业务在使用Cassandra时,必须执行相关的开发规则和使用规范,在开发设计阶段就降低使用风险。一般按照 制定规范 --> 接入评审 --> 定期巡检 --> 优化规则 的治理流程进行。合理的设计一般会降低大部份风险发生的概率,对于应用来说,任何表的设计都要考虑是否会造成热key,大key的产生,是否会造成负载倾斜的问题;另外建立数据老化机制,表中的数据不能无限制的增长而不删除或者老化;针对读多写少的场景,要增加缓存机制,来应对读热点问题,并提升查询性能;对于每个PK以及每行Row的大小,要控制大小,否则将影响性能和稳定性。超出后要及时优化。
以上是关于GaussDB (for Cassandra) 数据库治理:大key与热key问题的检测与解决的主要内容,如果未能解决你的问题,请参考以下文章
华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历
复杂查询so easy ,GaussDB(for Cassandra)推Lucene引擎全新解决方案
GaussDB (for Cassandra) 数据库治理:大key与热key问题的检测与解决
华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历