李宏毅——Optimization for Deep Learning
Posted ^_^|
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅——Optimization for Deep Learning相关的知识,希望对你有一定的参考价值。
What is Optimization about?
Find a θ \\theta θ to get the lowest L ( θ ) L(\\theta) L(θ) !!
What you have known before?
- SGD
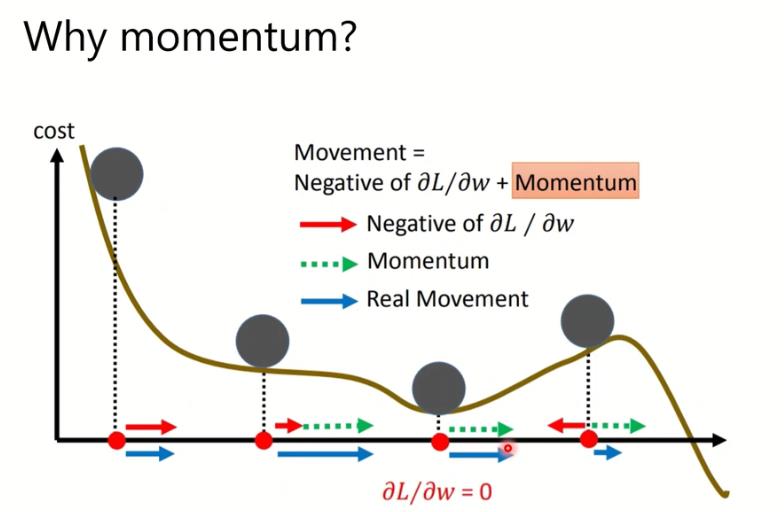
- SGD with momentum (SGDM)
Adaptive learning rate:
- Adagrad
- RMSProp
- Adam
SGD

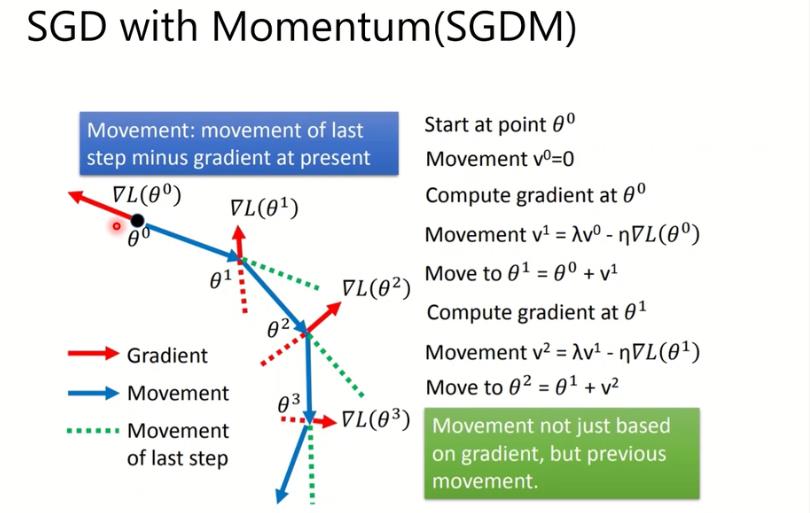
SGD with momentum (SGDM)
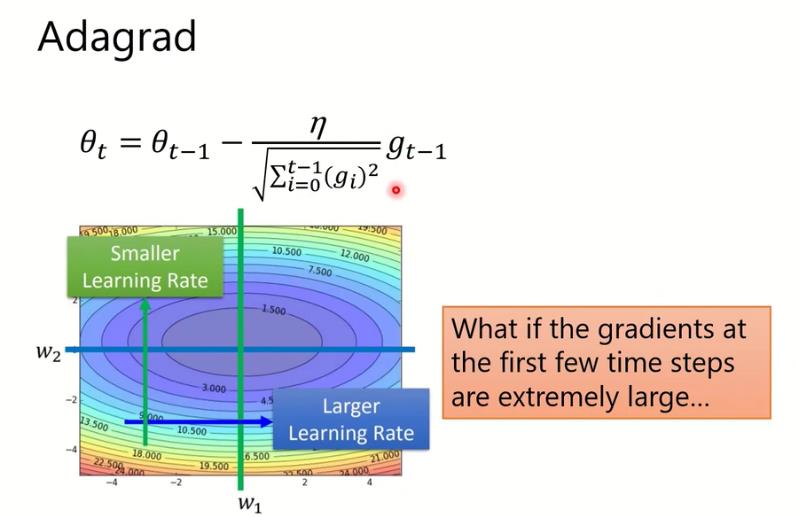
Adagrad
RMSProp
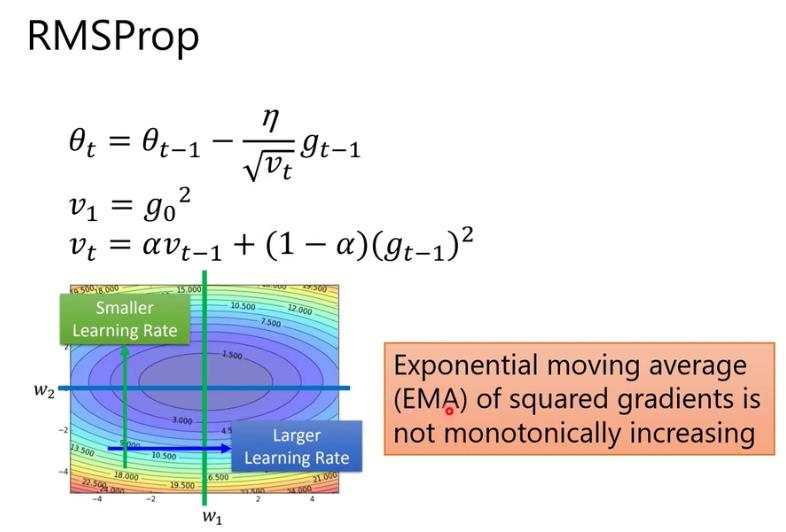
和之前的Adagrad主要在于分母部分表达不太一样,原本的Adagrad是直接将过去的gradient加起来,而现在则是将过去的累积gradient乘以
α
\\alpha
α而当前乘以
(
1
−
α
)
(1-\\alpha)
(1−α)。为什么要这样呢,在于Adagrad是一直累加之前的gradient,如果一开始的gradient就很大,那很可能你的learning rate一下子就会变得很小,这样会导致Adagrad没走几步就卡住了。RMSP这样的设计就可以保证分母部分不会永无止境的变大
但是RSMP并不能解决梯度下降中卡在梯度为0的位置
Adam
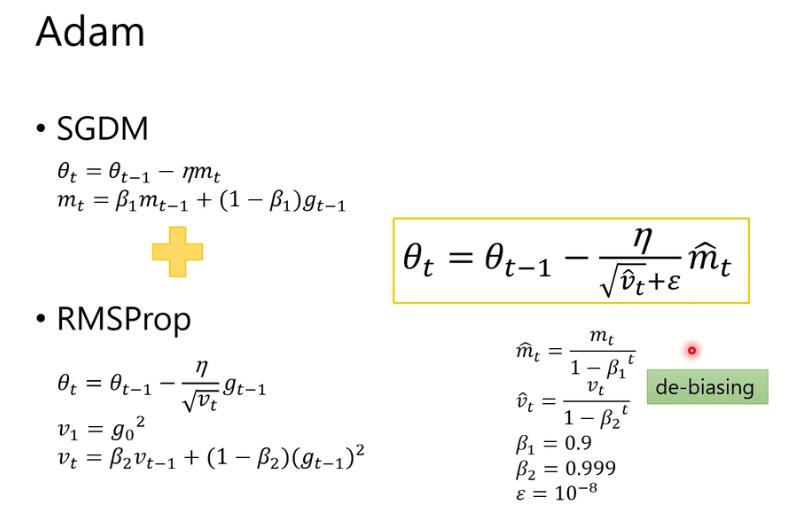
Adam将SBDM和RMSProp结合在一起。
m
t
^
\\hat{m_t}
mt^其实是momentum除上
1
−
β
1
t
1-\\beta_1^{t}
1−β1t,这其实是一个偏差修正项。对于偏差修正可以参考文章https://blog.csdn.net/yinyu19950811/article/details/90476956
ε
\\varepsilon
ε 是害怕一开始t=0的时候爆掉,出现无限大learning rate的情况
Learning Rate Scheduling
什么是learning rate scheduling?
我们刚才这边还有一项η,这个η是一个固定的值,learning rate scheduling的意思就是说,我们不要把η当一个常数,我们把它跟时间有关
Learning Rate Decay
最常见的策略叫做Learning Rate Decay,也就是说,随著时间的不断地进行,随著参数不断的update,我们这个η让它越来越小
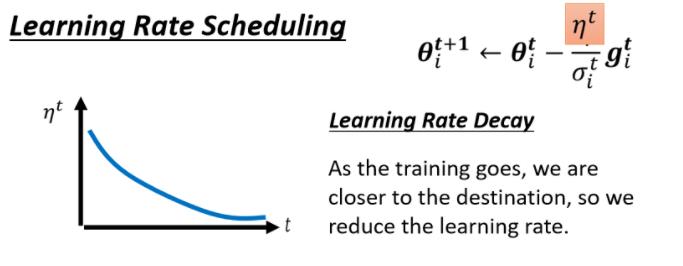
那这个也就合理了,因為一开始我们距离终点很远,随著参数不断update,我们距离终点越来越近,所以我们把learning rate减小,让我们参数的更新踩了一个煞车,让我们参数的更新能够慢慢地慢下来,所以刚才那个状况,如果加上Learning Rate Decay有办法解决
Warm Up
除了Learning Rate Decay以外,还有另外一个经典,常用的Learning Rate Scheduling的方式,叫做Warm Up
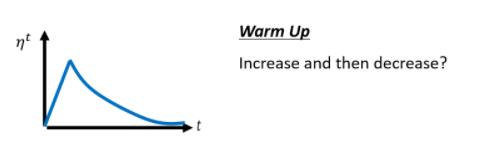
Warm Up这个方法,听起来有点匪夷所思,这Warm Up的方法是让learning rate,要先变大后变小,你会问说 变大要变到多大呢,变大速度要多快呢 ,小速度要多快呢,这个也是hyperparameter,你要自己用手调的,但是大方向的大策略就是,learning rate要先变大后变小
Optimizers: Real Application
BERT: ADAM
Transformer: ADAM
Tacotron: ADAM
YOLO: SGDM
Mask R-CNN: SGDM
ResNet: SGDM
Big-GAN: ADAM
最新的成果几乎还都是用ADAM或者SGDM训练出来的,表现了这两个Optimizers的优势。
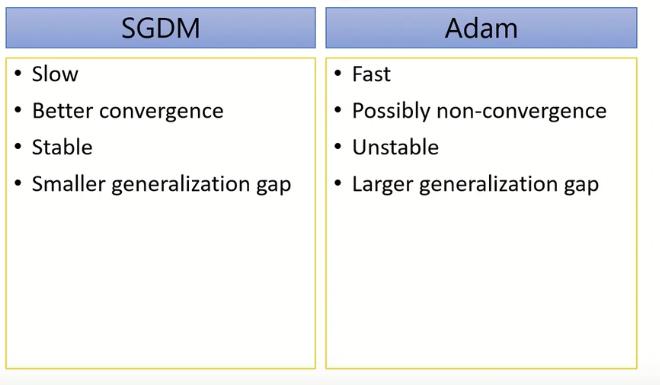
Adam vs SGDM
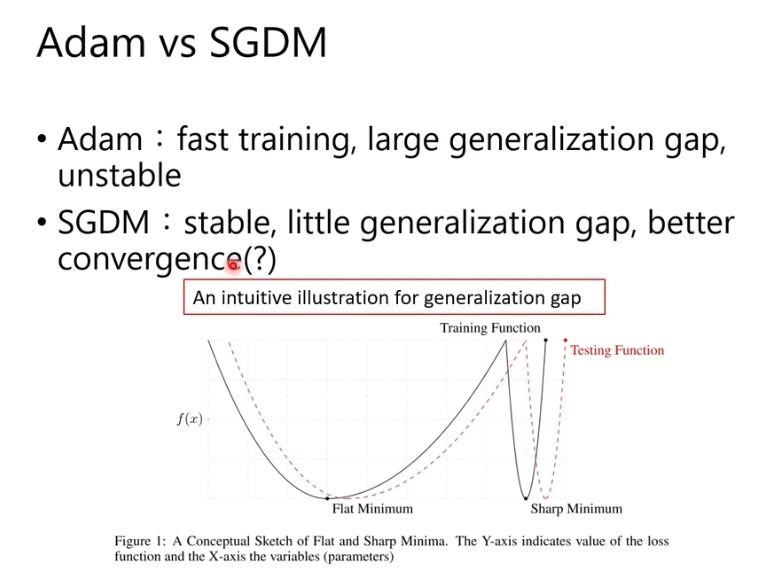
generalization 能力:也就是在validation set上面的表现的落差程度。Adam拥有large generalization gap表示它在validation set上的表现有比较大的误差,相对来说SGDM的落差会比较小,而且SGDM好像可以converge比较好。
解释一下为什么他们的generalization能力的差距。如上图所示,这里有两个minimum,他们值一样 。黑色的线是training时候的function,红色的线是testing时候的function。因为training和testing他的dataset有点分布上的差异,他的x是不一样的东西,所以他的Loss function长得有点像,但有差距。那么如果你是一个比较平坦的minimum的话,这两个Loss function都会比较平坦,所以这个generalization的差距就不会太大;那如果是一个比较sharp的Loss Function的话,这边的generalization的差距就会非常大。Adam和SGDM在generalization上的差距有一部分原因与此相关,也就是Adam可能更倾向于sharp的Minimum而SGDM则可能更倾向于Flat的Minimum。
综上, Adam比较快,SGDM比较稳而且他在训练最后更可能收敛到比较小的值。于是我们可能将目光放在直接结合这两个东西,使得又快又稳。
下面总结了一些有这样思想的算法

Advices

以上是关于李宏毅——Optimization for Deep Learning的主要内容,如果未能解决你的问题,请参考以下文章
李宏毅《机器学习》丨5. Tips for neural network design(神经网络设计技巧)