这么讲线程池,彻底明白了
Posted 三分恶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这么讲线程池,彻底明白了相关的知识,希望对你有一定的参考价值。
大家好,我是老三,很高兴又和大家见面,最近降温,大家注意保暖。
这节分享Java线程池,接下来我们一步步把线程池扒个底朝天。
引言:老三取钱
有一个程序员,他的名字叫老三。
老三兜里没有钱,匆匆银行业务办。
这天起了一大早,银行姐姐说早安。
老三一看柜台空,卡里五毛都取完。
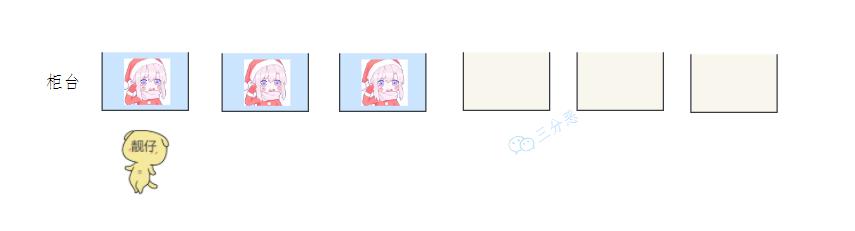
老三这天起的晚,营业窗口都排满。
只好进入排队区,摸出手机等空闲。
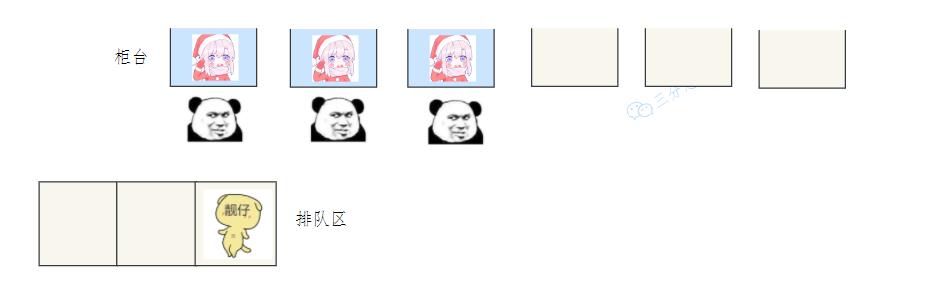
老三睡到上三杆,窗口排队都爆满。
经理一看开新口,排队同志赶紧办。
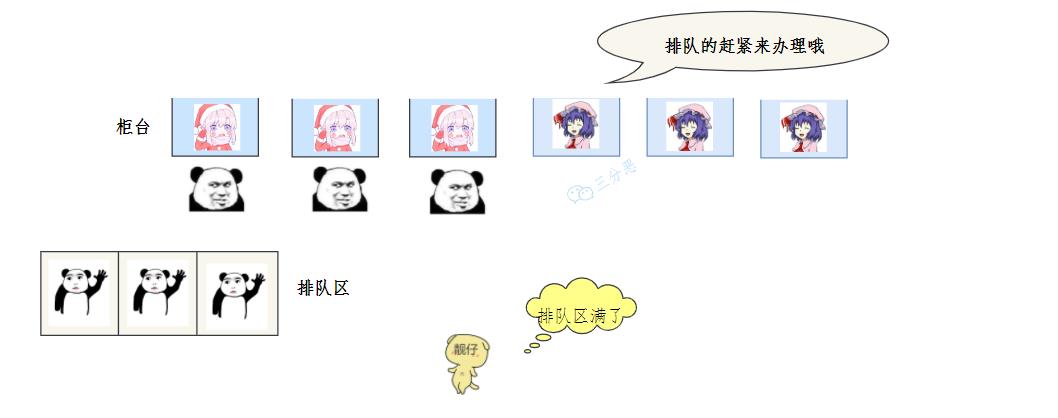
这天业务太火爆,柜台排队都用完。
老三一看急上火,经理你说怎么办。
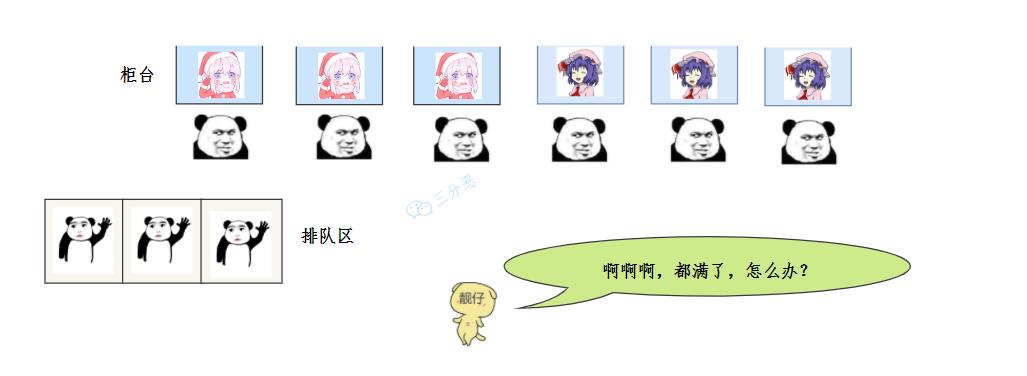
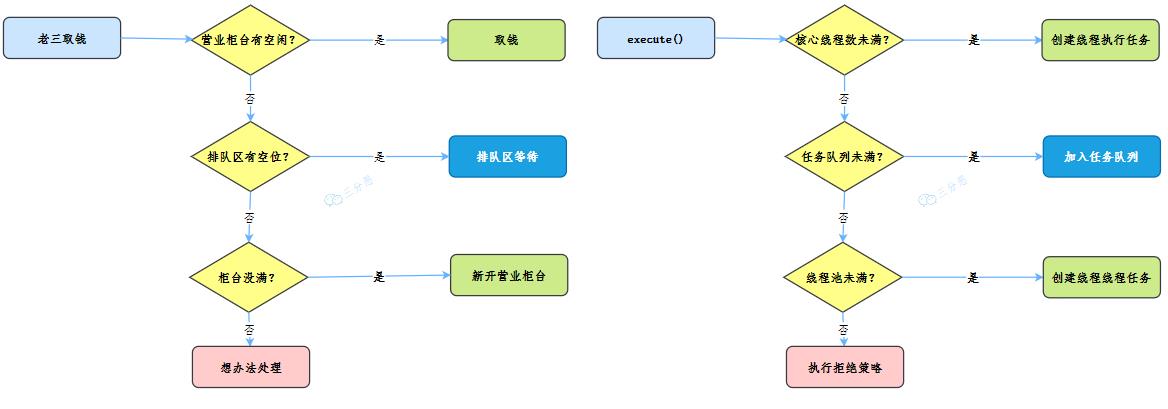
经理挥手一笑间,这种场面已见惯。四种办法来处理,你猜我会怎么办。
- 小小银行不堪负,陈旧系统已瘫痪。
- 我们庙小对不起,谁叫你来找谁办。
- 看你情况特别急,来去队里加个塞。
- 今天实在没办法,不行你看改一天。
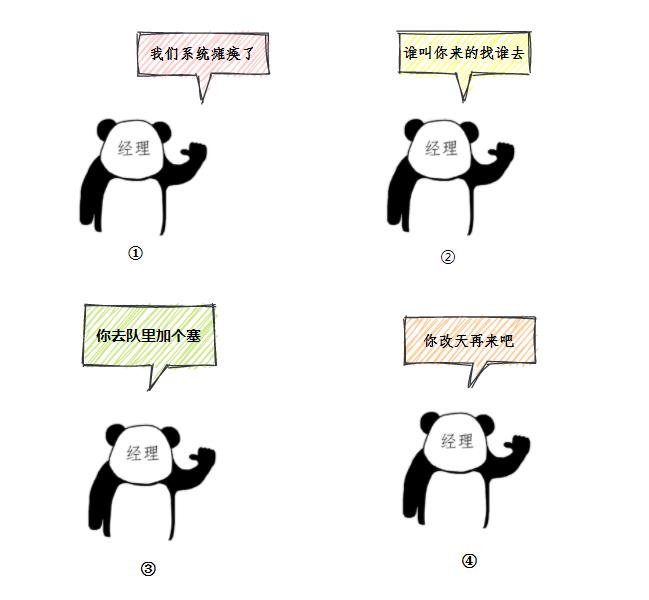
对,没错,其实这个流程就和JDK线程池ThreadPoolExecutor的工作流程类似,先卖个关子,后面结合线程池工作流程,保证你会豁然开朗。
实战:线程池管理数据处理线程
光说不练假把式,show you code,我们来一个结合业务场景的线程池实战。——很多同学面试的时候,线程池原理背的滚瓜烂熟,一问项目中怎么用的,歇菜。看完这个例子,赶紧琢磨琢磨,项目里有什么地方能套用的。
应用场景
应用场景非常简单,我们的项目是一个审核类的系统,每年到了核算的时候,需要向第三方的核算系统提供数据,以供核算。
这里存在一个问题,由于历史原因,核算系统提供的接口只支持单条推送,但是实际的数据量是三十万条,如果一条条推送,那么起码得一个星期。
所以就考虑使用多线程的方式来推送数据,那么,线程通过什么管理呢?线程池。
为什么要用线程池管理线程呢?当然是为了线程复用。
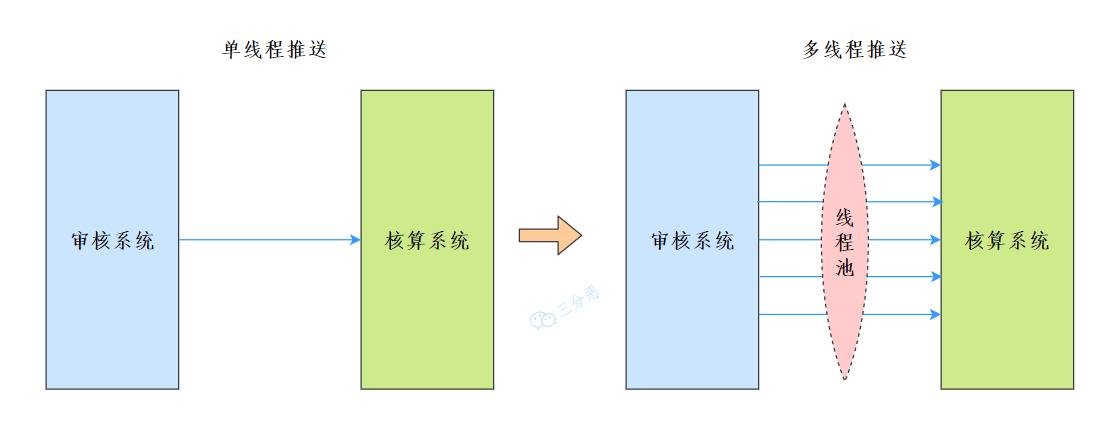
思路也很简单,开启若干个线程,每个线程从数据库中读取取(start,count]区间未推送的数据进行推送。
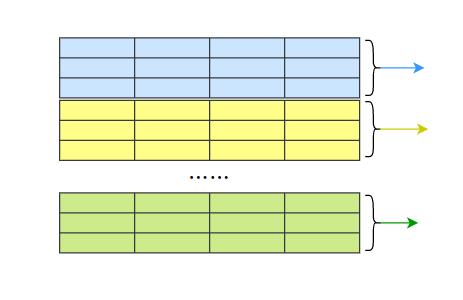
具体代码实现
我把这个场景提取了出来,主要代码:
代码比较长,所以用了carbon美化,代码看不清,没关系,可运行的代码我都上传到了远程仓库,仓库地址:https://gitee.com/fighter3/thread-demo.git ,这个例子比较简单,没有用过线程池的同学可以考虑你有没有什么数据处理、清洗的场景可以套用,不妨借鉴、演绎一下。
本文主题是线程池,所以我们重点关注线程池的代码:
线程池构造
//核心线程数:设置为操作系统CPU数乘以2
private static final Integer CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() * 2;
//最大线程数:设置为和核心线程数相同
private static final Integer MAXIMUM_POOl_SIZE = CORE_POOL_SIZE;
//创建线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOl_SIZE * 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
线程池直接采用ThreadPoolExecutor构造:
- 核心线程数设置为CPU数×2
- 因为需要分段数据,所以最大线程数设置为和核心线程数一样
- 阻塞队列使用
LinkedBlockingQueue - 拒绝策略使用默认
线程池提交任务
//提交线程,用数据起始位置标识线程
Future<Integer> future = pool.submit(new PushDataTask(start, LIMIT, start));
- 因为需要返回值,所以使用
submit()提交任务,如果使用execute()提交任务,没有返回值。
代码不负责,可以done下来跑一跑。
那么,线程池具体是怎么工作的呢?我们接着往下看。
原理:线程池实现原理
线程池工作流程
构造方法
我们在构造线程池的时候,使用了ThreadPoolExecutor的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
先来看看几个参数的含义:
-
corePoolSize: 核心线程数 -
maximumPoolSize:允许的最大线程数(核心线程数+非核心线程数) -
workQueue:线程池任务队列用来保存等待执行的任务的阻塞队列,常见阻塞队列有:
ArrayBlockingQueue:一个基于数组结构的有界阻塞队列LinkedBlockingQueue:基于链表结构的阻塞队列SynchronousQueue:不存储元素的阻塞队列PriorityBlockingQueue:具有优先级的无限阻塞队列
-
handler: 线程池饱和拒绝策略JDK线程池框架提供了四种策略:
AbortPolicy:直接抛出异常,默认策略。CallerRunsPolicy:用调用者所在线程来运行任务。DiscardOldestPolicy:丢弃任务队列里最老的任务DiscardPolicy:不处理,丢弃当前任务
也可以根据自己的应用场景,实现
RejectedExecutionHandler接口来自定义策略。
上面四个是和线程池工作流程息息相关的参数,我们再来看看剩下三个参数。
keepAliveTime:非核心线程闲置下来最多存活的时间unit:线程池中非核心线程保持存活的时间threadFactory:创建一个新线程时使用的工厂,可以用来设定线程名等
线程池工作流程
知道了几个参数,那么这几个参数是怎么应用的呢?
以execute()方法提交任务为例,我们来看线程池的工作流程:
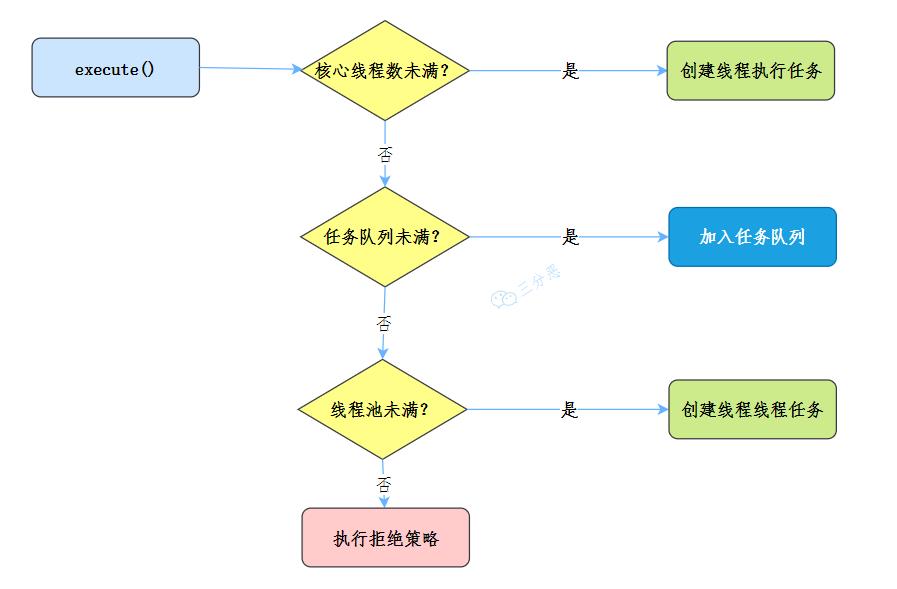
向线程池提交任务的时候:
- 如果当前运行的线程少于
核心线程数corePoolSize,则创建新线程来执行任务 - 如果运行的线程等于或多于
核心线程数corePoolSize,则将任务加入任务队列workQueue - 如果
任务队列workQueue已满,创建新的线程来处理任务 - 如果创建新线程使当前总线程数超过
最大线程数maximumPoolSize,任务将被拒绝,线程池拒绝策略handler执行
结合一下我们开头的生活事例,是不是就对上了:
线程池工作源码分析
上面的流程分析,让我们直观地了解了线程池的工作原理,我们再来通过源码看看细节。
提交线程(execute)
线程池执行任务的方法如下:
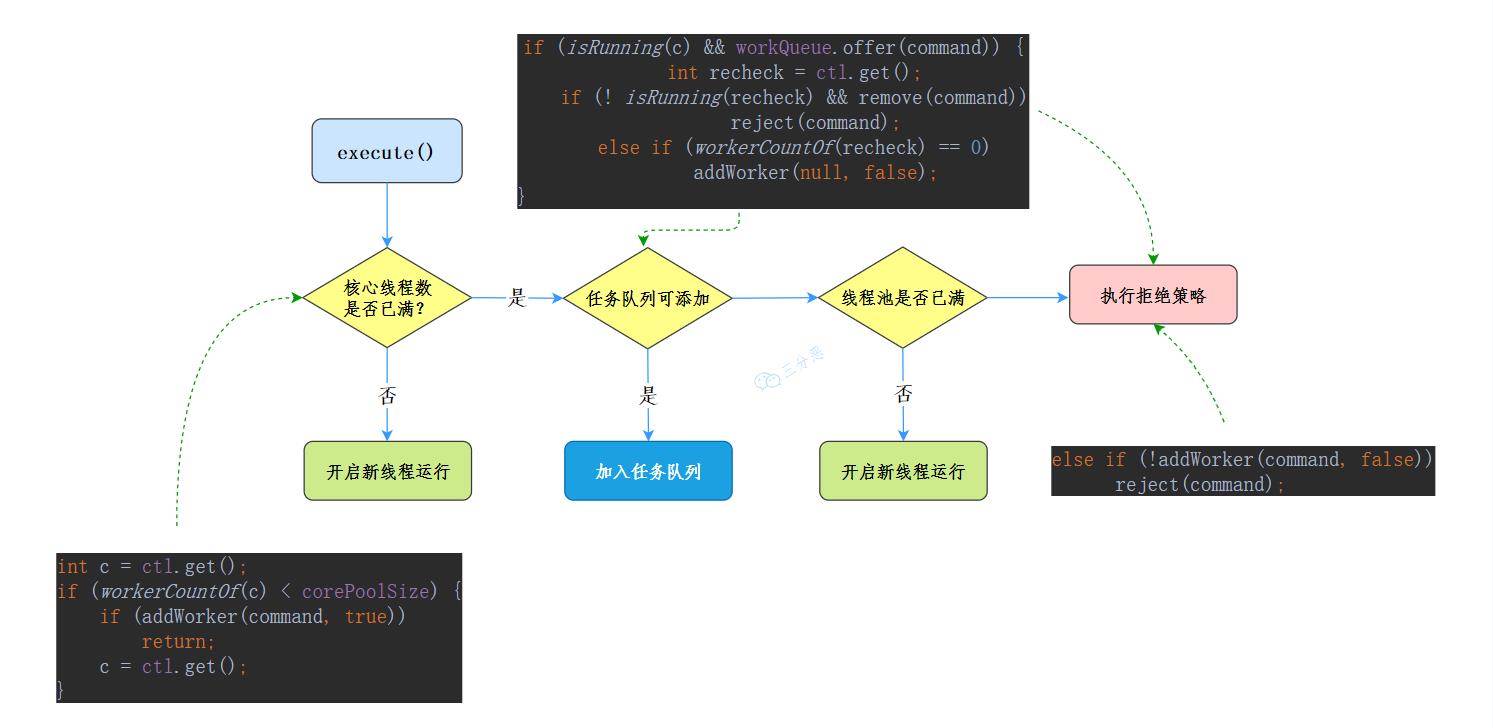
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//获取当前线程池的状态+线程个数变量的组合值
int c = ctl.get();
//1.如果正在运行线程数少于核心线程数
if (workerCountOf(c) < corePoolSize) {
//开启新线程运行
if (addWorker(command, true))
return;
c = ctl.get();
}
//2. 判断线程池是否处于运行状态,是则添加任务到阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
//二次检查
int recheck = ctl.get();
//如果当前线程池不是运行状态,则从队列中移除任务,并执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
//如若当前线程池为空,则添加一个新线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//最后尝试添加线程,如若添加失败,执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
我们来看一下execute()的详细流程图:
新增线程 (addWorker)
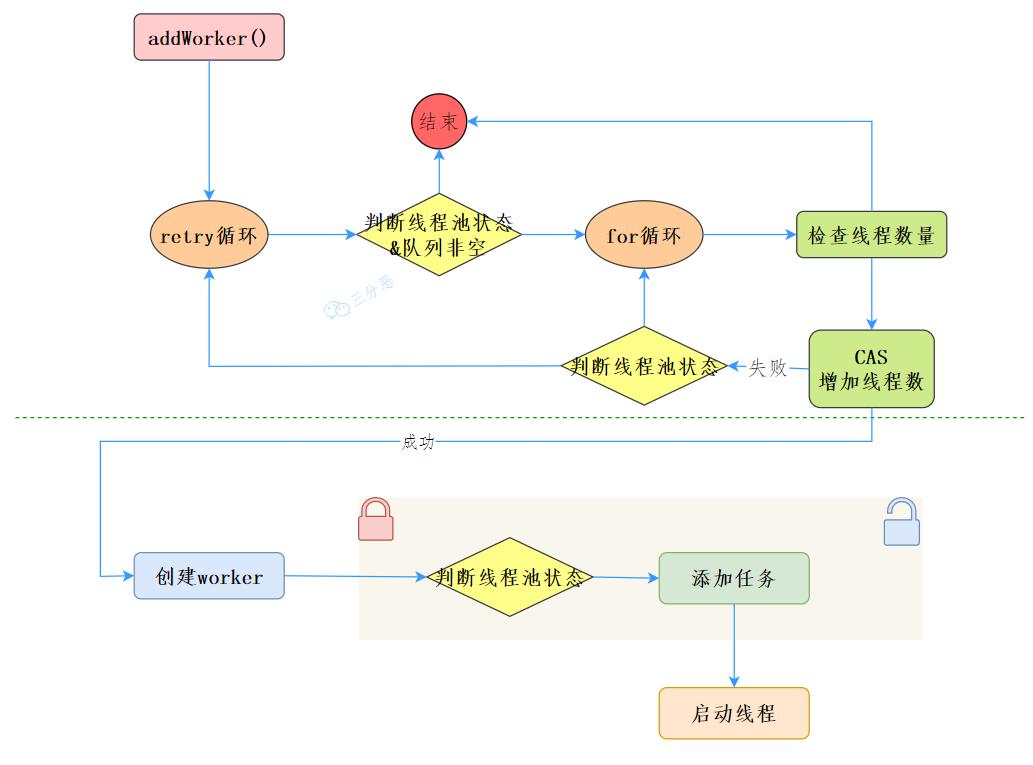
在execute方法代码里,有个关键的方法private boolean addWorker(Runnable firstTask, boolean core),这个方法主要完成两部分工作:增加线程数、添加任务,并执行。
- 我们先来看第一部分增加线程数:
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 1.检查队列是否只在必要时为空(判断线程状态,且队列不为空)
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//2.循环CAS增加线程个数
for (;;) {
int wc = workerCountOf(c);
//2.1 如果线程个数超限则返回 false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//2.2 CAS方式增加线程个数,同时只有一个线程成功,成功跳出循环
if (compareAndIncrementWorkerCount(c))
break retry;
//2.3 CAS失败,看线程池状态是否变化,变化则跳到外层,尝试重新获取线程池状态,否则内层重新CAS
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
}
}
//3. 到这说明CAS成功了
boolean workerStarted = false;
boolean workerAdded = false;
- 接着来看第二部分添加任务,并执行
Worker w = null;
try {
//4.创建worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//4.1、加独占锁 ,为了实现workers同步,因为可能多个线程调用了线程池的excute方法
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//4.2、重新检查线程池状态,以避免在获取锁前调用了shutdown接口
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//4.3添加任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//4.4、添加成功之后启动任务
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
我们来看一下整体的流程:
执行线程(runWorker)
用户线程提交到线程池之后,由Worker执行,Worker是线程池内部一个继承AQS、实现Runnable接口的自定义类,它是具体承载任务的对象。
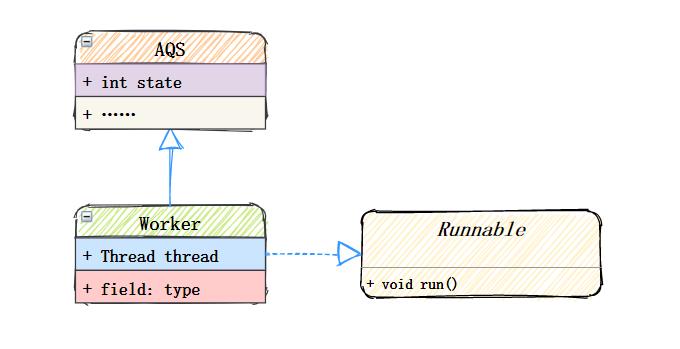
先看一下它的构造方法:
Worker(Runnable firstTask) {
setState(-1); // 在调用runWorker之前禁止中断
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //创建一个线程
}
- 在构造函数内 首先设置 state=-1,现了简单不可重入独占锁,state=0表示锁未被获取状态,state=1表示锁已被获取状态,设置状态大小为-1,是为了避免线程在运行runWorker()方法之前被中断
- firstTask记录该工作线程的第一个任务
- thread是具体执行任务的线程
它的run方法直接调用runWorker,真正地执行线程就是在我们的runWorker 方法里:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // 允许中断
boolean completedAbruptly = true;
try {
//获取当前任务,从队列中获取任务
while (task != null || (task = getTask()) != null) {
w.lock();
…………
try {
//执行任务前做一些类似统计之类的事情
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 执行任务完毕后干一些些事情
afterExecute(task, thrown);
}
} finally {
task = null;
// 统计当前Worker 完成了多少个任务
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//执行清理工作
processWorkerExit(w, completedAbruptly);
}
}
代码看着多,其实砍掉枝蔓,最核心的点就是task.run()让线程跑起来。
获取任务(getTask)
我们在上面的执行任务runWorker里看到,这么一句while (task != null || (task = getTask()) != null),执行的任务是要么当前传入的firstTask,或者还可以通过getTask()获取,这个getTask的核心目的就是从队列中获取任务。
private Runnable getTask() {
//poll()方法是否超时
boolean timedOut = false;
//循环获取
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 1.线程池未终止,且队列为空,返回null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
//工作线程数
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//2.判断工作线程数是否超过最大线程数 && 超时判断 && 工作线程数大于0或队列为空
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//从任务队列中获取线程
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
//获取成功
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
总结一下,Worker执行任务的模型如下[8]:
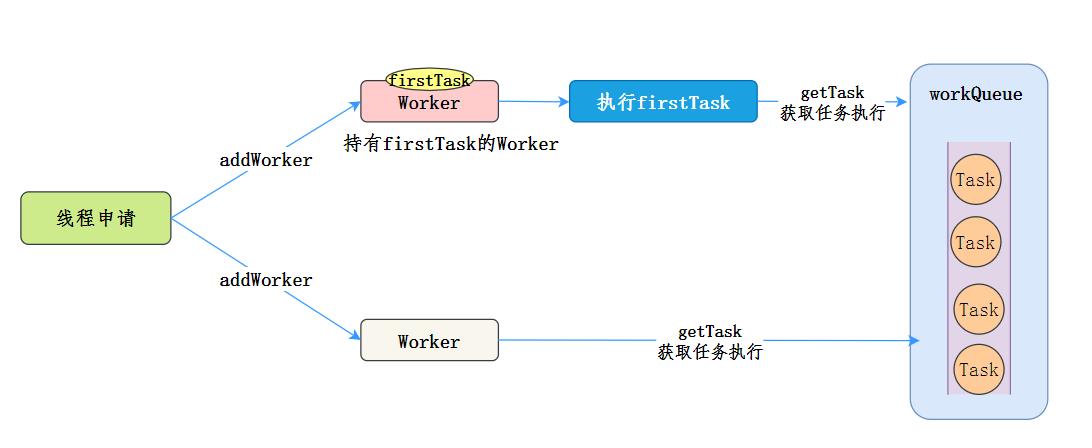
小结
到这,了解了execute和worker的一些流程,可以说其实ThreadPoolExecutor 的实现就是一个生产消费模型。
当用户添加任务到线程池时相当于生产者生产元素,workers 线程工作集中的线程直接执行任务或者从任务队列里面获取任务时则相当于消费者消费元素。
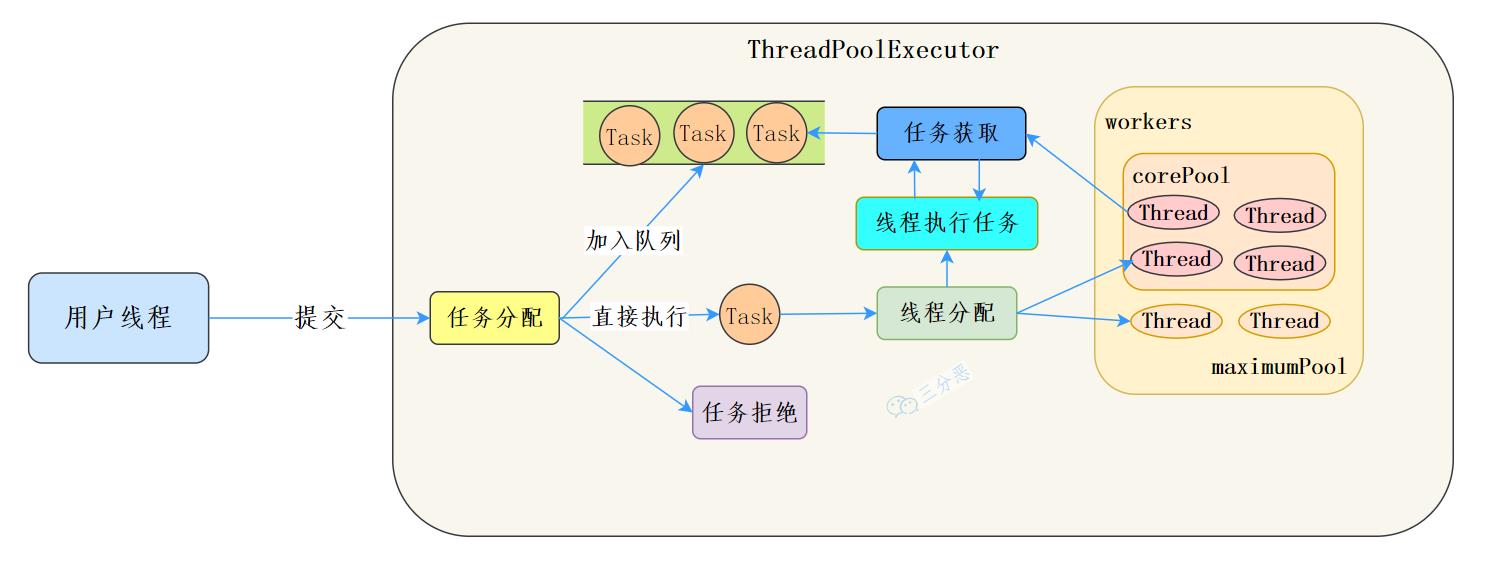
线程池生命周期
线程池状态表示
在ThreadPoolExecutor里定义了一些状态,同时利用高低位的方式,让ctl这个参数能够保存状态,又能保存线程数量,非常巧妙![6]
//记录线程池状态和线程数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//29
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池状态
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
高3位表示状态,低29位记录线程数量:
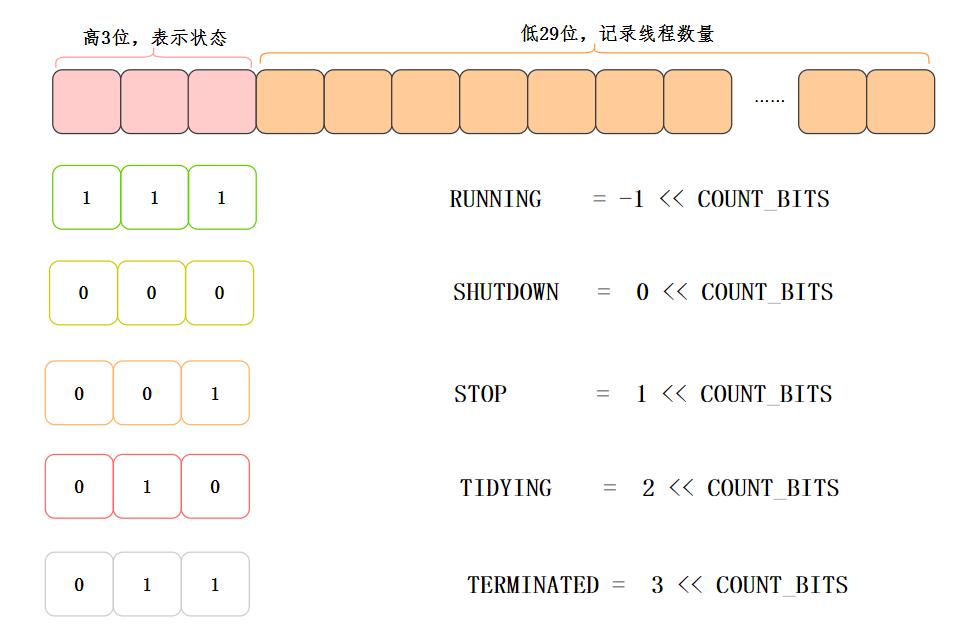
线程池状态流转
线程池一共定义了五种状态,来看看这些状态是怎么流转的[6]:
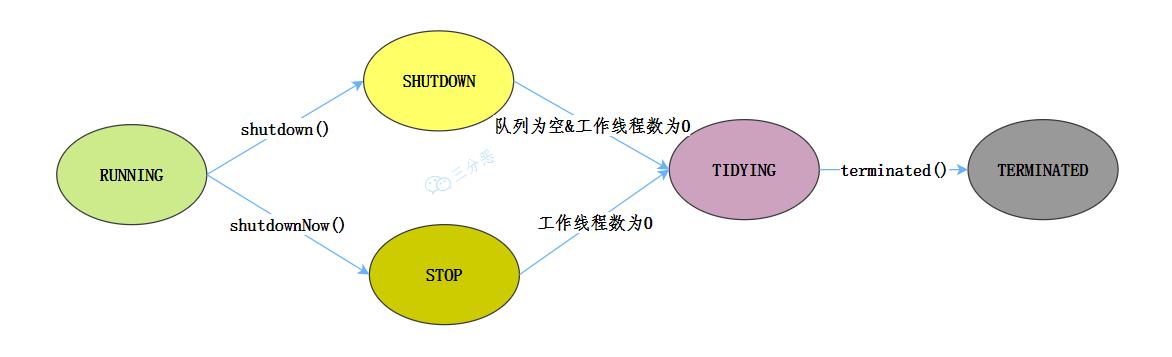
- RUNNING:运行状态,接受新的任务并且处理队列中的任务。
- SHUTDOWN:关闭状态(调用了 shutdown 方法)。不接受新任务,,但是要处理队列中的任务。
- STOP:停止状态(调用了 shutdownNow 方法)。不接受新任务,也不处理队列中的任务,并且要中断正在处理的任务。
- TIDYING:所有的任务都已终止了,workerCount 为 0,线程池进入该状态后会调terminated() 方法进入 TERMINATED 状态。
- TERMINATED:终止状态,terminated() 方法调用结束后的状态。
应用:打造健壮的线程池
合理地配置线程池
关于线程池的构造,我们需要注意两个配置,线程池的大小和任务队列。
线程池大小
关于线程池的大小,并没有一个需要严格遵守的“金规铁律”,按照任务性质,大概可以分为CPU密集型任务、IO密集型任务和混合型任务。
- CPU密集型任务:CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。
- IO密集型任务:IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。
- 混合型任务:混合型任务可以按需拆分成CPU密集型任务和IO密集型任务。
当然,这个只是建议,实际上具体怎么配置,还要结合事前评估和测试、事中监控来确定一个大致的线程线程池大小。线程池大小也可以不用写死,使用动态配置的方式,以便调整。
任务队列
任务队列一般建议使用有界队列,无界队列可能会出现队列里任务无限堆积,导致内存溢出的异常。
线程池监控
[1]如果在系统中大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题。
可以通过线程池提供的参数和方法来监控线程池:
- getActiveCount() :线程池中正在执行任务的线程数量
- getCompletedTaskCount() :线程池已完成的任务数量,该值小于等于 taskCount
- getCorePoolSize() :线程池的核心线程数量
- getLargestPoolSize():线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过,也就是达到了 maximumPoolSize
- getMaximumPoolSize():线程池的最大线程数量
- getPoolSize() :线程池当前的线程数量
- getTaskCount() :线程池已经执行的和未执行的任务总数
还可以通过扩展线程池来进行监控:
- 通过继承线程池来自定义线程池,重写线程池的beforeExecute、afterExecute和terminated方法,
- 也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。
End
这篇文章从一个生活场景入手,一步步从实战到原理来深入了解线程池。
但是你发现没有,我们平时常说的所谓四种线程池在文章里没有提及——当然是因为篇幅原因,下篇就安排线程池创建工具类Executors。
线程池也是面试的重点战区,面试又会问到哪些问题呢?
这些内容,都已经在路上。点赞、关注不迷路,下篇见!
参考:
[1]. 《Java并发编程的艺术》
[2]. 《Java发编程实战》
[3]. 讲真 这次绝对让你轻松学习线程池
[4]. 面试必备:Java线程池解析
[5]. 面试官问:“在项目中用过多线程吗?”你就把这个案例讲给他听!
[6]. 小傅哥 《Java面经手册》
[7]. 《Java并发编程之美》
以上是关于这么讲线程池,彻底明白了的主要内容,如果未能解决你的问题,请参考以下文章
newCacheThreadPool()newFixedThreadPool()newScheduledThreadPool()newSingleThreadExecutor()自定义线程池(代码片段