通过kafka,canal进行数据异构同步的一套技术方案
Posted 施小赞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过kafka,canal进行数据异构同步的一套技术方案相关的知识,希望对你有一定的参考价值。
业务背景说明:
本公司有一个业务场景是需要从A数据库异构同步至B数据库,在B数据库进行一些逻辑统计查询操作,大致如下图:
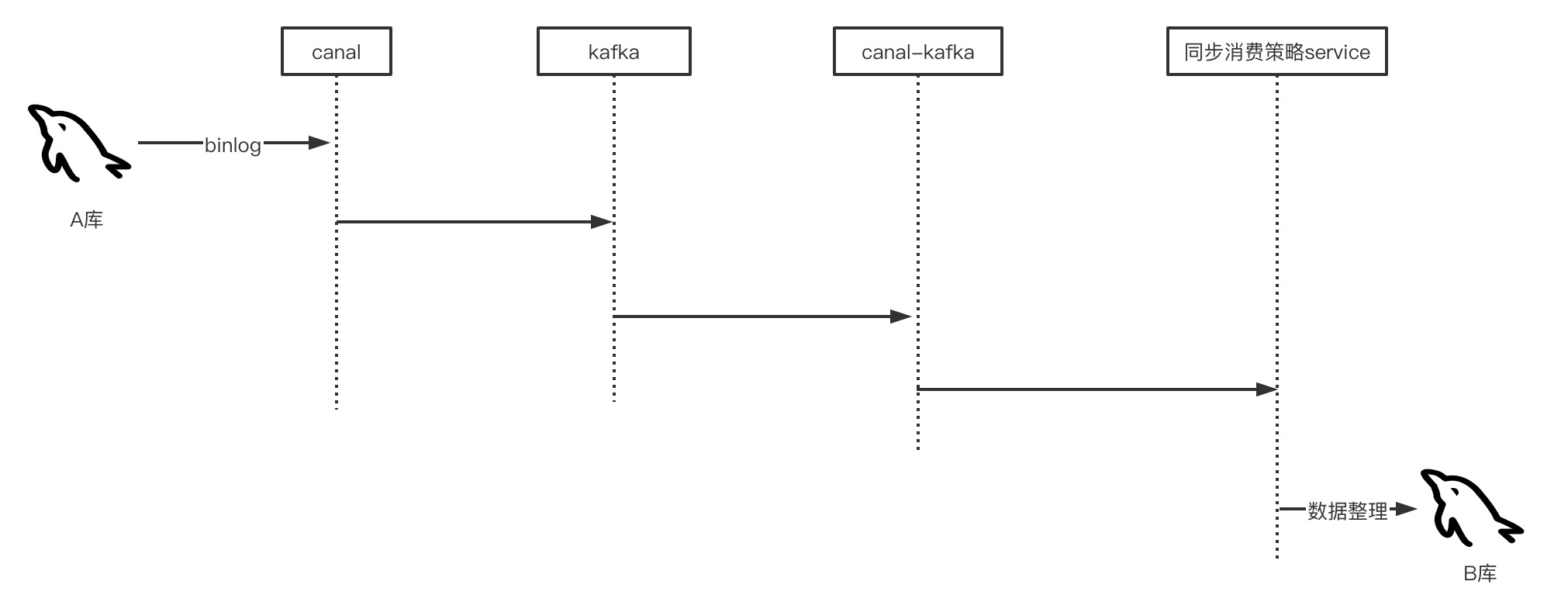
当时设计的技术架构如下:
第一步:通过canal监听A库的binlog日志,将binlog日志信息发送至kafka消息队列
第二步:部署消费者canal-kafka工程(纯java编写),消费kafka消息,异构原始数据,落B库,canal-kafka可以多节点分片部署
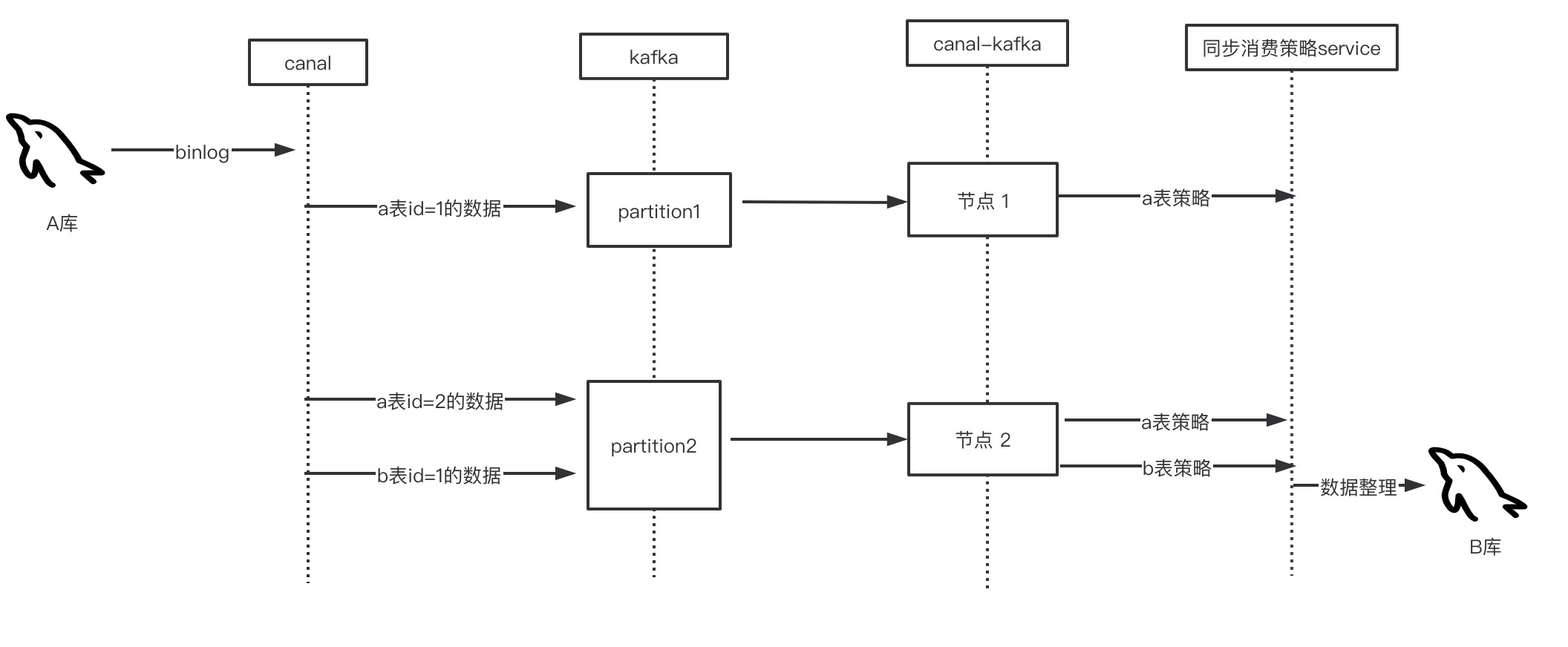
该方案咋一看可能存在一些问题,如同步性能如何,sql执行顺序问题如何保证,下面一一解答
biglog本身是有序的,写入kafka时可以保证有序,如果canal-kafka单节点部署,顺序消费那么,异构执行sql必定是有序的,但是这样会遇到性能瓶颈,同步数据量一大,必定造成大量消息阻塞,为了解决这一问题,canal-kafka必须得支持多节点分片部署。而kafka正好支持消息的分区功能,当一个消息投递至kafka时,可以选择这条消息至哪个分区,一个分区对应一个消费者,这样大幅提高了消费能力。消费能力提高了但是引进一个新问题,sql执行顺序问题,假设同一条数据的多个update语句,在不同的消费者执行,那么他们前后执行顺序问题如何保障?于是乎,必须确保同一条数据,从insert以及后面的各条update语句必须得是同一个消费者消费消息,有序执行。而canal拥有这一功能,参考文章链接:Canal Kafka RocketMQ QuickStart · alibaba/canal Wiki · GitHub ,可以查看 “mq顺序性问题” 这一小节。简单来说,每条数据在经过canal投递至kafka时 ,对其主键进行hash,选择其指定的kafka分区,这样之后这条数据修改均会投递至当初insert的的那个分区,这样消费时又是有序消费,从而保证了异构数据的有序性(A库单表数据对应B库单表数据的情况)。如下图:
当然,因为是异构,所以存在以下三种比较麻烦的情况:①A库的多表数据 对应 B库的单表数据,②A库的单表数据对应B的多表数据,③A库多表数据对应B库多表数据;第二种情况,在处理时比较简单,只要新增,修改时改造多条B库执行sql的语句,对于第一种跟第三种情况,就存在多个主键key都能造成某条B库数据的更新,为了保证数据的一致性,就需要通过业务代码来确保。举个例子:A的a1表,a2表,a3表均会更新B库的b1表数据,于是乎,当a1数据到达B时,需要回查a2,a3的数据,确定最后b1的执行sql,这样才确保了最终一致性。第三种情况也类似。如下图:
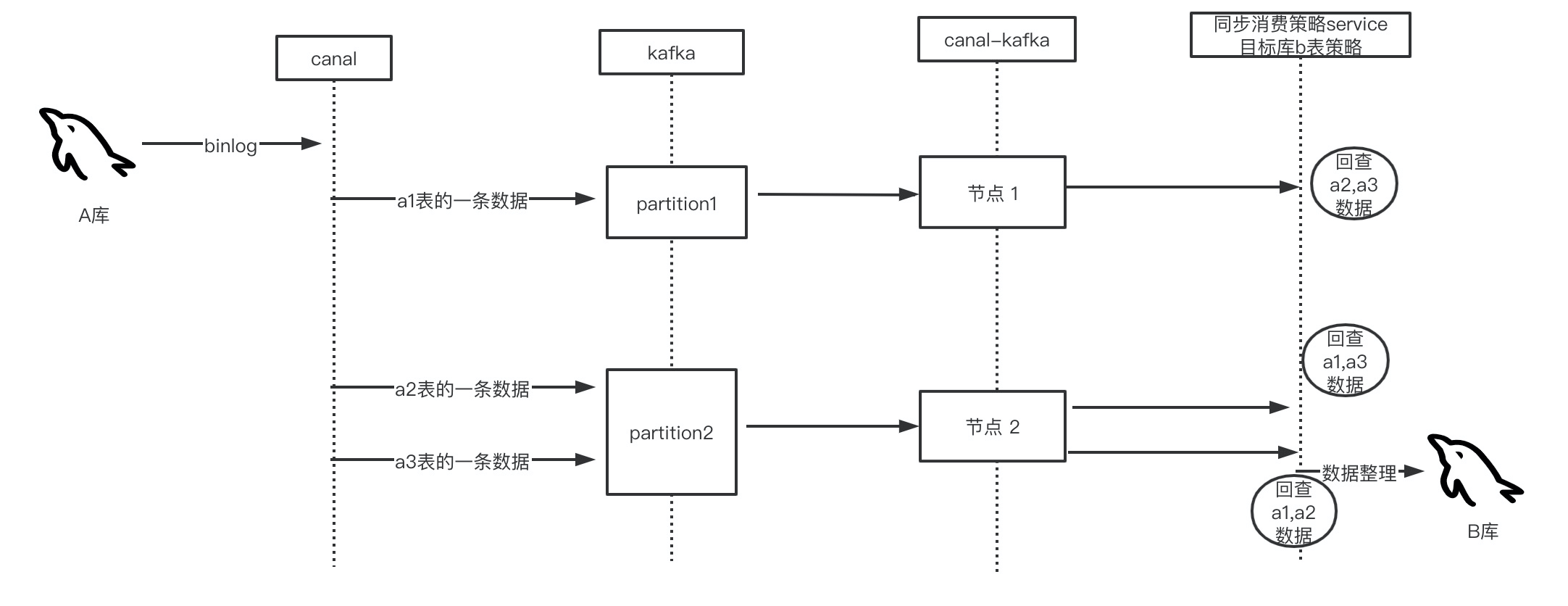
还有一种解决方案是设计合理的分区key,因为前面是将各张表的主键进行hash操作后分区,可能会导致顺序错乱,如果找到a1,a2,a3表的关联关系,如果他们的关联字段是同一个,进行hash消息分区后能保证有序,可以达到转化为单表对单表同步的效果,这样提高的性能不是一点点,当然在同步策略中需要考虑在a1,a2,a3数据到达时b1表的数据是否已经生成,这些都需要在业务逻辑中保障。当然出现万一a1,a2表的关联字段是 c1;a2,a3表的关联字段是c2,关联字段不是同一个,处理起来就不适用于此方法了,因为无论是对c1 hash分区还是c2 hash分区,都会对B库的b1表更新,又会产生顺序问题。
当然在数据一致性要求较低的情况下,可以在a1,a2,a3三张表中以更新频率最高的的表作为更新标记,在业务中只当某张表(a1,a2,a3中的一张)更新时才更新b1表数据,这样可以提高同步性能。
至此,将技术方案进行了简单说明,若有遗漏未考虑到bug情况望指教。
以上是关于通过kafka,canal进行数据异构同步的一套技术方案的主要内容,如果未能解决你的问题,请参考以下文章
用canal同步binlog到kafka,spark streaming消费kafka topic乱码问题