canal+mysql+kafka安装配置
Posted 兔八哥杂谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了canal+mysql+kafka安装配置相关的知识,希望对你有一定的参考价值。
概述
简介
canal译意为水道/管道/沟渠,主要用途是基于 mysql 数据库增量日志解析,提供增量数据订阅和消费。
基于日志增量订阅和消费的业务包括:
1. 数据库镜像
2. 数据库实时备份
3. 索引构建和实时维护(拆分异构索引、倒排索引等)
4. 业务 cache 刷新
5. 带业务逻辑的增量数据处理
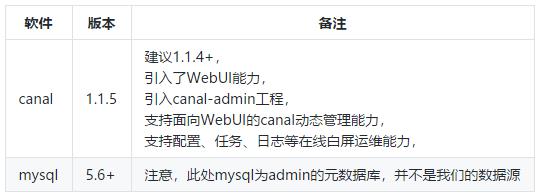
当前的 canal(1.1.5) 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
工作原理
MySQL主备复制原理
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
安装canal
版本信息
由于最近需要做mysql数据实时分析,经过比较决定选择canal作为同步工具。
安装过程步骤很简单,但是在具体使用过程中确存在一些问题,官网对此也没过多的解释,于是记录下安装过程。
下载canal
# 选定安装路径
cd /home
# 下载canal.admin
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.admin-1.1.5.tar.gz
# 解压canal-admin
mkdir canal-admin
tar -zxvf canal.admin-1.1.5.tar.gz -C canal-admin/
# 下载canal.deployer
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
# 解压canal-deployer
mkdir canal-deployer
tar -zxvf canal.deployer-1.1.5.tar.gz -C canal-deployer/
配置canal-admin
# 进入配置文件目录
cd canal-admin/conf/
# 修改配置文件
vim application.yml
# 加入以下内容
server:
port: 8189 # web端口,默认8089,但是我的端口已经被占用改为8189
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 10.0.x.x:3306 # 数据库ip、端口
database: canal_manager # 数据库名称,默认
username: canal #用户,默认
password: canal #密码,默认
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin #登陆webui 用户名
adminPasswd: 123456 #登陆密码,注意要1.1.5版本需要六位数以上密码,默认密码设置成admin登陆的时候会提示长度错误,默认的canal_manager.sql md5解密出来也是123456
生成admin元数据表
配置完application.yml,我们需要在元数据库生成元数据信息。
有两种方法:
canal-admin/conf/canal_manager.sql的语句
在数据库中逐条执行
canal-admin/conf/canal_manager.sql的语句在数据库中source canal_manager.sql
mysql> source /home/canal-admin/conf/canal_manager.sql
启动canal-admin
cd /home/canal-admin/bin
# 启动canal-admin
sh startup.sh
# 进入日志目录
cd /home/canal-admin/logs
# 查看日志
cat admin.log
日志如下即启动成功

登陆canal-admin
http://10.0.x.x:8189 # 账号密码为application.yml配置的admin 123456
登陆后页面如下

新建集群
新建集群

配置集群信息

载入模板
配置集群信息的时候我们可以通过载入模板,然后进行配置

修改内容
修改过的或建议修改的配置用中文标记,其余的默认
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip = 1 #每个canal server实例的唯一标识
# register ip to zookeeper
canal.register.ip =
canal.port = 11111 #canal server提供socket tcp服务的端口
canal.metrics.pull.port = 11112
# canal instance user/passwd
canal.user = canal
canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
canal.admin.manager = x-x-DATACENTER04:8189 #admin中配置的10.0.x.x:8189 因为我配置hosts 此处写x-x-DATACENTER04也可以
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers = x-x-datacenter08,x-x-datacenter09,x-x-datacenter10 #canal server链接zookeeper集群的链接信息
# flush data to zk
canal.zookeeper.flush.period = 1000 #canal持久化数据到zookeeper上的更新频率,单位毫秒
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir} #canal持久化数据到file上的目录
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384 #canal内存store中可缓存buffer记录数,需要为2的指数
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
#canal内存store中数据缓存模式
# 1. ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量
# 2. MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录的大小
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false #是否开启心跳检查
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1 #心跳检查sql
canal.instance.detecting.interval.time = 3 #心跳检查频率,单位秒
canal.instance.detecting.retry.threshold = 3 #心跳检查失败重试次数
#非常注意:interval.time * retry.threshold值,应该参考既往DBA同学对数据库的故障恢复时间,
#“太短”会导致集群运行态角色“多跳”;“太长”失去了活性检测的意义,导致集群的敏感度降低,Consumer断路可能性增加。
canal.instance.detecting.heartbeatHaEnable = false #心跳检查失败后,是否开启自动mysql自动切换
#说明:比如心跳检查失败超过阀值后,如果该配置为true,canal就会自动链到mysql备库获取binlog数据
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024 #支持最大事务大小,将超过事务大小的事务切成多个事务交付
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60 #canal发生mysql切换时,在新的mysql库上查找 binlog时需要往前查找的时间,单位秒
# 说明:mysql主备库可能存在解析延迟或者时钟不统一,需要回退一段时间,保证数据不丢
# network config
canal.instance.network.receiveBufferSize = 16384 #网络链接参数,SocketOptions.SO_RCVBUF
canal.instance.network.sendBufferSize = 16384 #网络链接参数,SocketOptions.SO_SNDBUF
canal.instance.network.soTimeout = 30 #网络链接参数,SocketOptions.SO_TIMEOUT
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = true #ddl语句是否隔离发送,开启隔离可保证每次只返回发送一条ddl数据,不和其他dml语句混合返回.(otter ddl同步使用)
canal.instance.filter.query.dml = true #是否忽略DML的query语句,比如insert/update/delete table.(mysql5.6的ROW模式可以包含statement模式的query记录)
canal.instance.filter.query.ddl = true #是否忽略DDL的query语句,比如create table/alater table/drop table/rename table/create index/drop index. (目前支持的ddl类型主要为table级别的操作,create databases/trigger/procedure暂时划分为dcl类型)
# 注意:上面三个参数默认都是false 如无必要建议设置为true,否则后面你过滤表的时候可能会出现不生效的情况
anal.instance.filter.table.error = true
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = true # 把事务头尾过滤
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
#canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info #关于时间序列版本
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
# 如果配置为true,canal.conf.dir目录下的instance配置变化会自动触发
# a. instance目录新增: 触发instance配置载入,lazy为true时则自动启动
# b. instance目录删除:卸载对应instance配置,如已启动则进行关闭
# c. instance.properties文件变化:reload instance配置,如已启动自动进行重启操作
canal.auto.scan = true #开启instance自动扫描
canal.auto.scan.interval = 5 #instance自动扫描的间隔时间,单位秒
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = manager
canal.instance.global.lazy = false #全局lazy模式
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml #此处建议设置为classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = x-x-datacenter03:6667,x-x-datacenter04:6667,x-x-datacenter05:6667 # kafka bootstrap 信息,可以不填所有的
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 50 #建议设为50
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
完成后点击保存配置
配置canal.deployer
在 x-x-DATACENTER04、x-x-DATACENTER07安装canal.deployer-1.1.5
这里我们准备使用集群模式,只需要关注canal_local.properties。
cd /home/canal-deployer/conf
修改配置
vim canal_local.properties
配置内容
########################加入以下内容#######################
# register ip
canal.register.ip = xx-xx-DATACENTER04 # 你主机的ip,避免多网卡带来的问题
# canal admin config
# canal admin的ip:port
canal.admin.manager = xx-xx-DATACENTER04:8189 # 与admin安装信息保持一致
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# admin auto register
canal.admin.register.auto = true
# 填入之前在admin中创建集群的集群名
canal.admin.register.cluster = wt_test # 填我们刚刚在web ui中新建的集群
canal.admin.register.name =
############################################################
启动canal.deployer
/home/canal-deployer/bin
sh startup.sh local
# 查看日志
cd /home/canal-deployer/logs/canal
cat canal.log
上述步骤在部署canal.deployer的服务器上执行(
x-x-DATACENTER04、x-x-DATACENTER07)
出现下面的日志即表示启动成功

admin界面查看会发现多了两个服务

说明:
server: 代表一个canal运行实例,对应于一个jvm
instance: 对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
eventStore (数据存储)
metaManager (增量订阅&消费信息管理器)
安装到这一步,安装的部分已经完成,下面就是如何通过web ui 配置一个同步任务。
创建实例
数据源mysql配置
前面的原理介绍说过,canal同步的原理是伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave
canal 再解析 binary log 对象(原始为 byte 流)
所以我们的数据源也必须开启了binlog并设置为主库才行。
数据源库开启binlog
mysql binlog参数配置应该如下
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
若不是该配置则需要开启binlog
# 编辑/etc/my.cnf
vim /etc/my.cnf
# 加入下面三行
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1
# 重启mysql
/usr/mysql/support-files/mysql.server stop
/usr/mysql/support-files/mysql.server start
# 查看binlog开启情况
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
创建实例
配置完数据源,我们就可以开始实例的配置了
instance 管理 -> 新建instance

实例名称->选择集群->载入模板

进行如下配置
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=1 #slaveId 注意不要与数据源库的id 一样
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=172.x.x.x:3306 # 数据源mysql的ip:port
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/wt_pre
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal # 数据源mysql的用户,根据实际设置
canal.instance.dbPassword=canal # 数据源mysql的密码,根据实际设置
canal.instance.connectionCharset = UTF-8
canal.instance.defaultDatabaseName = test_db # 默认数据库,但是好像设置了没啥用
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex = test_db\\..* # 需要同步的表,这里配置的意思是test_db下的所有表。
# 但是如果之前配置canal.instance.filter.query.dcl、canal.instance.filter.query.dml、canal.instance.filter.query.ddl 三个参数不设置为true 这个过滤可能失效
# 关于这点后面再稍微解释下
# table black regex
canal.instance.filter.black.regex= # 同上,只不过这里是黑名单,不同步的表
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # 需要同步的字段
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # 不需要同步的字段
# mq config
canal.mq.topic=tpc_all # 默认数据同步的主题,所有未被canal.instance.filter.regex匹配的表都会同步到主题tpc_all中
# dynamic topic route by schema or table regex
canal.mq.dynamicTopic=tpc_test:test_db\\..* #自己指定主题,test_db库中的所有表都会同步到tpc_test中
canal.mq.partition=0
# hash partition config
canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
保存配置,返回上一页面
启动实例
返回instance管理页面可以看到新建的实例。
操作->启动

查看日志
此时消费tpc_test即可看到test_db库各个表的变化情况
至此配置instance完成
遇到的问题
其实按照上面的步骤应该不会有什么问题了,毕竟该踩的坑我都踩了。
但是这里还有有一个问题想再做下说明。
关于表过滤失败的问题
按照官网,我们过滤表只需要进行表的黑白名单配置即可
canal.instance.filter.regex = test_db\\..*
canal.instance.filter.black.regex=
但是实际上在测试过程中发现,黑白名单过滤都没有生效。
网上一搜很多都说是API覆盖了这里的配置,但是实际上我们直接通过WEB UI配置压根不存在覆盖的问题。
关于这个问题官方FAQ中有两个问题与此相关
为什么INSERT/UPDATE/DELETE被解析为查询或DDL?
出现这类情况主要原因为收到的binlog就为Query事件,比如:
a. binlog格式为非row模式,通过show variables like 'binlog_format'可以查看. 针对statement/mixed模式,DML语句都会是以SQL语句存在
b. mysql5.6+之后,在binlog为row模式下,针对DML语句通过一个开关(binlog-rows-query-log-events=true, show variables里也可以看到该变量),记录DML的原始SQL,对应binlog事件为RowsQueryLogEvent,同时也有对应的row记录.
ps. canal可以通过properties设置来过滤:canal.instance.filter.query.dml=true
我为表设置了过滤器,但它不起作用。
官方给了五个排查步骤
首先看文档AdminGuide,了解canal.instance.filter.regex的书写格式
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表:canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
检查binlog格式,过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
检查下CanalConnector是否调用subscribe(filter)方法;有的话,filter需要和instance.properties的canal.instance.filter.regex一致,否则subscribe的filter会覆盖instance的配置,如果subscribe的filter是...,那么相当于你消费了所有的更新数据 【特别注意】
canal 1.1.3+版本之后,会在日志里记录最后使用的filter条件,可以对比使用的filter看看是否和自己期望的是一致,如果不一致检查一下第3步
c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter :
检查一下历史的issue列表,很有可能你的提问别人已经遇到过并解决了,比如表达式不对,特别是双斜杠的问题
好家伙还真在历史的issue找到解决办法,多久的问题了,官方心真大
按上面的说法走一遍流程,好像也没问题呀,官方拉垮
解决办法
后面看了一个issue才发现问题。
实际上我们过滤过滤生效了。
根据上面第一个问题,我们知道INSERT/UPDATE/DELETE被解析为Query或DDL语句,发生一条变更会发送两个entry过来。
一个entry是query ,一个是具体的更新(insert/update/delete)。
你没过滤的表会发两个entry过来 ,但是你过滤的表只会发一个entrytype是query的信息。
对于query类型好像无法准确提取tableName进行过滤,所以我们配置的黑白名单就失效了
。
猜测是这样,没深入研究,毕竟我即使何明.\.. 作为黑名单都失效了
最后是在把cannal.properties中的参数修改一下解决:
canal.instance.filter.transaction.entry = true
canal.instance.filter.query.dcl = true
canal.instance.filter.query.dml = true
canal.instance.filter.query.ddl = true
canal.instance.filter.table.error = true
参考资料:
Canal配置文件详解
关于canal.instance.filter.regex 设置的问题
FAQ
更多内容请关注【兔八哥杂谈】
以上是关于canal+mysql+kafka安装配置的主要内容,如果未能解决你的问题,请参考以下文章
Canal或maxwell实时采集MySQL数据到Kafka